


IX. Configuration du réseau▲
Linux est un système d'exploitation fabriqué par l'Internet et pour l'Internet. Inutile de préciser que c'est l'un des meilleurs systèmes pour gérer et exploiter un réseau. Certains ne l'utilisent d'ailleurs que pour cela, et profitent de ses excellentes performances sur les petites machines afin de récupérer du matériel autrement voué à la casse. En fait, les fonctionnalités réseau de Linux sont si nombreuses que j'ai été obligé d'y consacrer un chapitre à part entière.
La configuration d'un réseau est une opération qui nécessite quelques connaissances théoriques sur le fonctionnement des réseaux TCP/IP. Ces informations sont assez techniques, mais indispensables pour bien configurer les services réseau de toute machine connectée, et pas seulement les machines fonctionnant sous Linux. Il n'est en effet pas rare de trouver des réseaux de machines fonctionnant sur des systèmes dont la configuration est supposée être plus simple, mais dont l'organisation est une hérésie absolue et qui risquent de nécessiter une remise à plat complète à chaque interconnexion.
Cette section va donc donner quelques explications sur les notions fondamentales des réseaux informatiques. Il traitera ensuite de la configuration des réseaux locaux, puis celle des connexions temporaires à Internet. Les services réseau évolués tels que le partage de connexion à Internet et la création d'un serveur de fichiers seront finalement traités en fin de chapitre.
IX-A. Notions de réseau TCP/IP▲
IX-A-1. Généralités sur les réseaux▲
Un réseau n'est en général rien d'autre qu'une interconnexion entre plusieurs machines qui leur permet d'échanger des informations. Il existe de nombreux moyens de réaliser cette interconnexion, qui utilisent parfois des supports physiques variés. Les techniques les plus utilisées sont la liaison radio et la liaison par câble. Cette dernière technique comprend diverses variantes, dont les réseaux Ethernet, TokenRing et simplement la liaison téléphonique.
Il est évident que la manière d'envoyer et de recevoir des informations est différente pour ces différents supports physiques, parce qu'elle dépend tout simplement des possibilités techniques offertes par la technologie sous-jacente utilisée. Cependant, il est très courant de découper les informations à échanger en paquets, qui sont ensuite transmis sur le réseau. Ces paquets peuvent être de tailles variées, et contenir des informations utiles à la gestion du réseau. L'information la plus importante est sans doute celle permettant de connaître la machine destinataire du paquet. On l'appelle l'adresse de la machine cible, il s'agit généralement d'un numéro permettant de l'identifier de manière unique sur le réseau. En général, les paquets contiennent également l'adresse de la machine source, afin qu'une réponse puisse lui être envoyée.
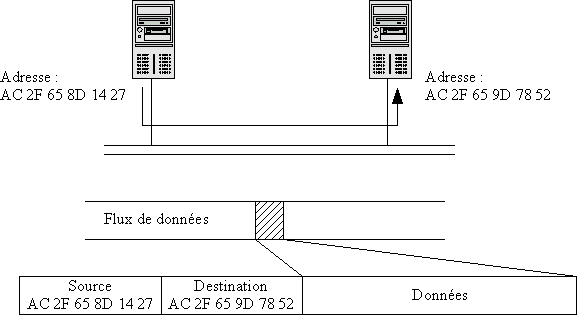
Du fait de la diversité des supports physiques de réseau, il n'est pas simple d'écrire une application réseau qui puisse travailler dans des environnements réseau hétérogènes. Cela supposerait de connaître les protocoles de communication pour chaque type de réseau, ce qui compliquerait à l'infini le moindre programme et le rendrait inutilisable avec les nouveaux réseaux. Par conséquent, cette tâche ingrate a été reléguée au plus profond des couches réseau spécifiques au support physique. Les applications quant à elles utilisent un protocole de communication plus évolué, dont le but est d'assurer l'interopérabilité des différents supports physiques. Ce protocole utilise toujours des paquets et une notion d'adresse, mais cette fois ces informations sont standardisées et utilisables par toutes les applications. Les paquets de ce protocole sont stockés dans les paquets des réseaux physiques et transmis tels quels. Ils peuvent éventuellement être découpés en sous-paquets dans le cas où la taille des paquets du réseau serait trop petite pour les contenir. Cette technique s'appelle l'encapsulation d'un protocole dans un autre protocole.

IX-A-2. Le protocole IP▲
Les machines Unix utilisent toutes le protocole de communication de bas niveau IP (« Internet Protocol »). Ce protocole a été inventé pour permettre l'interconnexion d'un grand nombre de réseaux physiques différents (le nom d'Internet provient d'ailleurs de cette caractéristique : « INTERconnected NETworks »). Il permet de transmettre des informations de manière uniforme sur tous ces réseaux physiques. Ainsi, les programmes qui utilisent IP ne voient pas les spécificités des différents réseaux physiques. Pour eux, il ne semble y avoir qu'un seul réseau physique, dont le protocole de communication de base est IP. Autrement dit, les applications qui utilisent le réseau se contentent d'utiliser le protocole IP, et n'ont plus à se soucier de la manière dont il faut formater et transmettre les informations sur chaque support physique du réseau. Ce genre de détail est laissé aux couches réseau de chaque machine et aux passerelles reliant les divers réseaux physiques.
Comme il l'a déjà été dit ci-dessus, le protocole IP utilise des adresses pour identifier les machines sur les réseaux. Les adresses IP sont codées sur quatre octets (nombres binaires à huit chiffres, permettant de représenter des valeurs allant de 0 à 255), chacun définissant une partie du réseau. Ces adresses sont utilisées un peu comme les numéros de téléphone : le premier octet définit le numéro d'un « super-réseau » dans lequel le correspondant se trouve (ces « super-réseaux » sont appelés les réseaux de classe A), le deuxième octet définit le numéro du sous-réseau dans le super-réseau (ces sous-réseaux sont appelés réseaux de classe B), le troisième octet définit encore un sous-sous-réseau (réseaux dits de classe C) et le quatrième octet donne le numéro de la machine dans ce sous-sous-réseau.
Cette numérotation permet d'affecter des adresses similaires pour les différentes machines d'un réseau, et de simplifier ainsi la gestion de ce dernier. Elle dispose en revanche d'un inconvénient majeur : beaucoup d'adresses sont gaspillées, car il n'y a pas suffisamment de réseaux de classe A d'une part, et qu'on ne peut pas mélanger les machines de deux sous-réseaux dans un même réseau de classe A d'autre part. Si l'on reprend la comparaison avec les numéros de téléphone, il y a énormément d'abonnés dont le numéro commence par 01, mais beaucoup moins dont le numéro commence par 02, et quasiment aucun dont le numéro commence par 08. Si l'on venait à manquer de place dans la liste des numéros commençant par 01, on ne pourrait pas pour autant utiliser les numéros commençant par 02 pour des raisons géographiques. C'est la même chose pour les adresses IP, sauf que les zones géographiques sont remplacées par des sous-réseaux. Le problème est que, malheureusement, on commence à manquer d'adresses disponibles (alors qu'il y en a plein de libres, mais inutilisables parce qu'elles se trouvent dans d'autres sous-réseaux !). Il va donc falloir effectuer une renumérotation d'ici peu, exactement comme il y en a déjà eu dans le monde de la téléphonie…
Note : Le protocole IPv6, qui remplacera le protocole IP classique (encore appelé IPv4), a pour but de résoudre les limitations du protocole IP utilisé actuellement. Les adresses du protocole IPv6 sont codées sur 16 octets, ce qui résoudra définitivement le problème du manque d'adresses. De plus, les services modernes que sont l'authentification de l'émetteur, ainsi que la qualité de service (c'est-à-dire la garantie du délai de transmission des données, garantie nécessaire pour transmettre de façon correcte les flux multimédias tels que le son et la vidéo en temps réel) sont fournis par IPv6. Bien entendu, Linux est déjà capable d'utiliser IPv6 (combien de systèmes peuvent aujourd'hui l'affirmer ?) ! Notez toutefois que pour cela, il faut recompiler le noyau et toutes les applications réseau du système, ce qui est tout de même très lourd. Par conséquent, il vaut mieux se contenter du protocole IP actuel. Malgré ses limitations, ce protocole reste sans doute le meilleur protocole réseau du monde, car il allie souplesse et fonctionnalité. Il est difficilement concevable de créer un réseau aussi grand qu'Internet avec les autres protocoles existant sur le marché…
Les adresses IP sont donc parfaitement définies à l'aide de leurs quatre nombres, que l'on note les uns à la suite des autres et en les séparant d'un point. Comme on l'a vu, les adresses IP sont classées en sous-réseaux, de classe A, B et C. Les adresses des réseaux de classe C ont leurs trois premiers nombres fixés, et seul le quatrième nombre change pour chaque machine du réseau. De la même manière, les réseaux de classe B ont leurs deux premiers nombres fixés, et seuls les deux derniers nombres permettent de distinguer les différentes machines du réseau. Enfin, les réseaux de classe A n'ont de fixé que leur première composante, les autres sont libres. Il est donc clair qu'il existe peu de réseaux de classe A, mais que ce sont de très gros réseaux (ils peuvent contenir jusqu'à 16 millions de machines !). En revanche, il existe beaucoup plus de réseaux de classe C, dont la taille est plus modeste (seulement 256 machines).
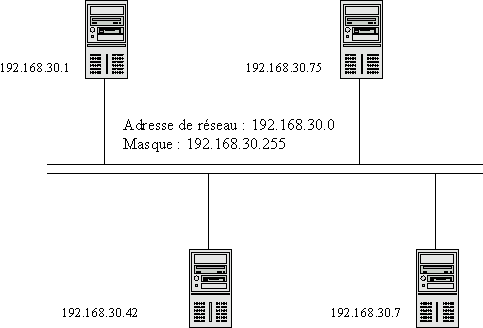
Pour un réseau donné, les adresses ont donc toutes la même forme. Les premiers octets des adresses du réseau sont toujours les mêmes (ce peut être le premier octet pour les réseaux de classe A, les deux premiers pour les réseaux de classe B ou les trois premiers pour les réseaux de classe C). On peut donc définir la notion d'adresse de réseau, qui est l'adresse IP d'une machine du réseau dont les parties variables ont pour valeur 0. Par exemple, si une machine d'un réseau de classe C a pour adresse 192.168.1.15, alors l'adresse de son sous-réseau est 192.168.1.0. Cela signifie que toutes les machines de ce réseau auront une adresse de la forme « 192.168.1.xxx ».
Un réseau n'appartient qu'à une et une seule classe. Les adresses IP sont réparties sur les différentes classes de réseaux, selon la valeur des bits de poids fort de leur premier octet. Par exemple, les réseaux de classe A sont identifiables au fait que le bit de poids fort de leur adresse est nul. Les adresses de réseau valides pour les réseaux de ce type sont donc les adresses comprises entre 0.0.0.0 et 127.0.0.0. Il n'existe donc que 128 réseaux de classes A en tout et pour tout. Les autres réseaux ont donc le bit de poids fort de leur adresse fixé à 1, et c'est le deuxième bit de poids fort qui est utilisé pour distinguer les réseaux de classe B des autres. Les réseaux de classe B utilisent toujours la valeur 0 pour ce bit, leurs adresses varient donc entre 128.0.0.0 et 191.255.0.0. De même, les réseaux de classe C utilisent la valeur 1 pour le deuxième bit de leur adresse, et ont nécessairement un troisième bit nul. Leurs adresses vont donc de 192.0.0.0 à 223.255.255.0. Les adresses pour lesquelles le troisième bit (en plus des deux premiers) est à 1 sont réservées (soit pour une utilisation ultérieure, soit pour s'adresser à des groupes d'ordinateurs en multicast) et ne doivent pas être utilisées. Il s'agit des adresses 224.0.0.0 à 255.255.255.255. Cette dernière adresse a une signification spéciale et permet de s'adresser à tous les ordinateurs d'un réseau.
Il est possible de déterminer l'adresse du réseau auquel une machine appartient en utilisant ce qu'on appelle le masque de sous-réseau. Le masque de sous-réseau est une série de quatre nombres ayant le même format que les autres adresses IP, mais dont les composantes ne peuvent prendre que la valeur 0 ou la valeur 255, les 255 devant nécessairement apparaître en premier. Les composantes des adresses IP qui correspondent à la valeur 255 dans le masque de sous-réseau font partie de l'adresse dudit sous-réseau. Les composantes qui correspondent à la valeur 0 dans le masque de sous-réseau n'en font pas partie, et varient pour chaque machine du réseau. Pour reprendre l'exemple précédent, si une machine a pour adresse IP 189.113.1.15 et que son masque de sous-réseau est 255.255.255.0, alors l'adresse de son réseau est 189.113.1.0. Si le masque de sous-réseau avait été 255.255.0.0 (typiquement le masque d'un réseau de classe B), l'adresse du réseau aurait été 189.113.0.0. Comme on le voit, le masque de sous-réseau est utilisé par le système pour déterminer rapidement l'adresse de sous-réseau d'une machine à partir de son adresse IP. On notera que certaines combinaisons d'adresses IP et de masques de sous-réseau sont invalides. Par exemple, les adresses affectées aux réseaux de classe C (comme 192.168.0.1 par exemple) ne peuvent pas avoir de masque de sous-réseau en 255.255.0.0, car cela impliquerait que cette adresse serait une adresse de réseau de classe B.
Les adresses IP ne sont pas attribuées aux machines au hasard. Il est évident que chaque machine doit avoir une adresse unique, et que son adresse doit appartenir à la plage d'adresses utilisée pour le sous-réseau dont elle fait partie. Pour cela, les classes de réseau, ainsi que les adresses qu'ils utilisent, sont attribuées par l'IANA, un organisme de gestion de l'Internet. Le rôle de l'IANA (abréviation de l'anglais « Internet Assigned Numbers Authority ») est essentiellement d'assurer l'unicité des adresses IP sur l'Internet. Cependant, certaines adresses sont librement utilisables pour les réseaux locaux qui ne sont pas connectés directement à l'Internet. Les paquets utilisant ces adresses sont assurés de ne pas être transmis sur Internet. Ces adresses peuvent donc être utilisées par quiconque. Les plages d'adresse réservées sont les suivantes :
Tableau 9-1. Plages d'adresses IP réservées pour un usage personnel
|
Classe de réseau |
Adresses de réseau réservées |
|
A |
10.0.0.0 |
|
B |
172.16.0.0 à 172.31.0.0 |
|
C |
192.168.0.0 à 192.168.255.0 |
Ainsi, un réseau de classe A (d'adresse 10.0.0.0), 16 réseaux de classe B (les réseaux 172.16.0.0 à 172.31.0.0) et 255 réseaux de classe C (d'adresses 192.168.0.0 à 192.168.255.0) sont disponibles. Vous pouvez donc les utiliser librement.
Il est également possible de configurer les machines pour qu'elles récupèrent leurs adresses IP auprès d'un serveur à l'aide du protocole DHCP (abréviation de l'anglais « Dynamic Host Configuration Protocol »). Cette technique est très intéressante quand on dispose d'un grand nombre de machines qui ne sont pas toujours toutes connectées à un réseau. Il est donc possible de redistribuer les adresses IP d'un stock d'adresses en fonction des machines qui se connectent, et d'économiser ainsi les précieuses adresses. En revanche, elle n'est pas appropriée pour les serveurs qui sont couramment accédés par des postes clients, et qui doivent donc avoir une adresse IP fixe.
Certaines adresses IP ont une signification particulière et ne peuvent pas être attribuées à une machine. Par exemple l'adresse 127.0.0.1 représente, pour une machine, elle-même. Cette adresse est souvent utilisée pour accéder à un programme réseau sur la machine locale. Elle fait partie du sous-réseau de classe A 127.0.0.0, qui ne comprend pas d'autres adresses. De plus, les adresses dont les derniers nombres (c'est-à-dire les nombres qui ne font pas partie de l'adresse du réseau) se terminent par 0 ou 255 sont réservées pour l'envoi des paquets à destination de tout le monde sur le réseau (émission dite « broadcast »). Par exemple, les adresses 192.168.1.0 et 192.168.1.255 ne peuvent pas être affectées à une machine. Ce sont typiquement ces adresses qui sont utilisées par le protocole DHCP pour émettre des requêtes sur le réseau alors que la machine n'a pas encore d'adresse fixe.
Il est important de savoir que, par défaut, une machine ne communiquera qu'avec les machines de son propre réseau. C'est-à-dire que si une machine utilise l'adresse IP 192.168.1.15 et que son masque de sous-réseau est 255.255.255.0, elle ne pourra contacter que des machines dont l'adresse est de la forme 192.168.1.xxx. Elle ne pourra donc pas voir par exemple une machine dont l'adresse IP est 192.168.0.2. Cela ne signifie pas que l'on doive toujours utiliser le masque 0.0.0.0 pour voir toutes les machines du monde, mais plutôt que la machine 192.168.0.2 ne fait pas partie, a priori, du même réseau physique que la machine 192.168.1.15. Il est donc inutile de chercher à la contacter (et mettre le masque de sous-réseau à 0.0.0.0 ne résoudrait évidemment pas le problème). Cependant, si deux réseaux physiques ont nécessairement deux adresses de réseau différentes, rien n'empêche de définir, sur un même réseau, plusieurs réseaux logiques. Ainsi, une même carte réseau peut avoir plusieurs adresses IP. La communication avec les machines des différents réseaux logiques se fait alors par l'intermédiaire de la même interface réseau.
Arrivé à ce stade des explications, je sens venir la question suivante : « ?! Euhhh… Mais alors, comment peut-on voir les machines sur Internet ? Je n'ai pas de réseau, et quand je me connecte à Internet, je peux y accéder ! Et même si j'avais un réseau, elles ne feraient certainement pas partie de mon réseau… ».
Explications :
- premièrement, vous avez un réseau, même si vous ne le savez pas. Toute machine appartient généralement au moins à son propre réseau virtuel, sur laquelle elle est la seule machine, et où elle a l'adresse 127.0.0.1 ;
- deuxièmement, effectivement, les machines qui se trouvent sur Internet n'appartiennent pas à votre réseau, que celui-ci existe effectivement ou soit virtuel ;
- troisièmement, toutes les informations que vous envoyez et recevez transitent par un seul ordinateur, celui de votre fournisseur d'accès à Internet. C'est cet ordinateur qui se charge de faire le transfert de ces informations vers les machines situées sur Internet.
C'est donc ici qu'intervient la notion de passerelle (« Gateway » en anglais).
Une passerelle est une machine qui appartient à deux réseaux physiques distincts, et qui fait le lien entre les machines de ces deux réseaux. Les ordinateurs des deux réseaux peuvent communiquer avec la passerelle de part et d'autre, puisqu'elle appartient aux deux réseaux. Les ordinateurs de chaque réseau transmettent à cette passerelle tous les paquets qui ne sont pas destinés à une machine de leur propre réseau. Celle-ci se charge simplement de transférer ces paquets aux machines de l'autre réseau.
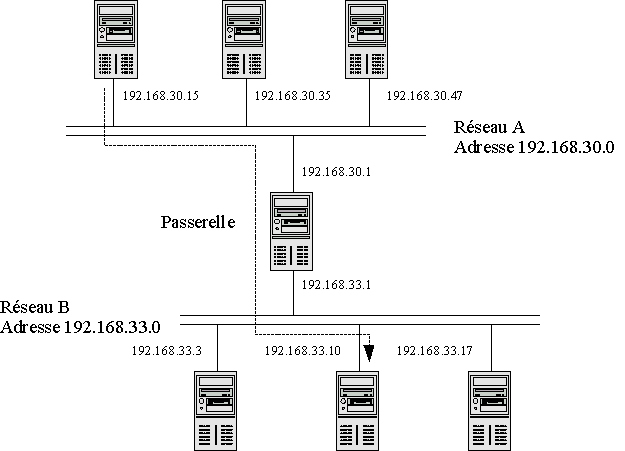
Lorsque vous vous connectez à Internet, vous ne faites rien d'autre que de créer un réseau (dont le support physique est la ligne téléphonique), et vous utilisez l'ordinateur que vous avez appelé comme passerelle par défaut. Tous les paquets destinés à un autre réseau que le vôtre (donc, en pratique, tous les paquets si vous n'avez pas de réseau local) sont donc envoyés sur le réseau constitué de votre connexion à Internet et arrivent donc chez votre fournisseur d'accès, qui se charge ensuite de les transmettre aux autres ordinateurs. Notez que celui-ci peut transmettre ces paquets à une autre passerelle à laquelle il a accès et ainsi de suite, jusqu'à ce que la destination soit atteinte.
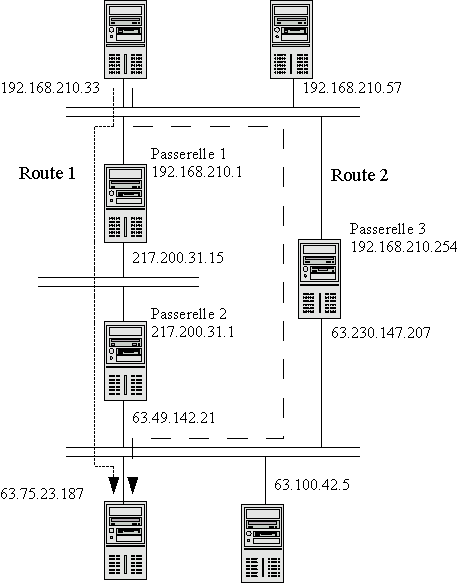
Dans le cas d'un particulier, le choix du réseau sur lequel les paquets doivent être transmis est très facile à faire puisqu'en général un paquet est soit à destination de la machine locale, soit à destination d'une machine sur Internet. Pour un paquet destiné à la machine locale, le réseau virtuel local est utilisé. Tous les autres paquets sont envoyés sur la connexion Internet. Cependant, il peut arriver qu'une machine ait le choix entre plusieurs passerelles différentes pour envoyer un paquet dont la destination n'est pas sur son propre réseau. Par exemple, les passerelles d'Internet peuvent être elles-mêmes connectées à différents autres réseaux, qui sont eux-mêmes connectés à d'autres réseaux. Un paquet peut donc être acheminé de plusieurs manières à sa destination, selon la topologie du réseau. L'ensemble des réseaux empruntés par un paquet dans son voyage constitue ce qu'on appelle sa route.
Chaque passerelle contribue donc à déterminer la route des paquets en choisissant, pour chaque paquet, l'interface réseau à utiliser pour transmettre ce paquet. Ce choix est fait en suivant un certain nombre de règles basées sur l'adresse destination des paquets. Par exemple, si une passerelle reçoit un paquet dont l'adresse destination est 129.46.10.15, et qu'elle est elle-même connectée à un réseau possédant cette machine, elle transmettra bien évidemment ce paquet sur ce réseau. Si en revanche elle ne peut localiser la machine cible sur l'un de ses réseaux, elle l'enverra à une autre passerelle à laquelle elle a accès. Le choix de cette passerelle est en général déterminé par des règles de la forme suivante : « Tous les paquets destinés au sous-réseau 129.46.0.0 doivent être envoyés vers la passerelle 193.49.20.1 du réseau 193.49.20.0 ». Notez qu'à chaque étape de la route, seules les passerelles de l'étape suivante peuvent être choisies comme relais.
Ainsi, si la passerelle est connectée à trois réseaux d'adresses respectives 192.168.1.0, 193.49.20.0 et 209.70.105.10, elle transférera le paquet à destination de 129.46.10.15 à la passerelle 193.49.20.1. La transmission effective du paquet à cette passerelle se fera ensuite selon le protocole réseau bas niveau utilisé sur le réseau 193.49.20.0. Autrement dit, une passerelle est une machine qui, contrairement aux machines classiques, accepte de recevoir des paquets qui ne lui sont pas directement adressés, et de les traiter en les réémettant vers leur destination ou vers une autre passerelle, selon les règles de routage qu'elle utilise.
Les règles utilisées par les passerelles sont stockées dans ce qu'on appelle des tables de routage. Les tables de routage peuvent être configurées statiquement dans la configuration des passerelles, c'est-à-dire initialisées dans les fichiers de configuration et ne jamais être modifiées. Cette technique convient parfaitement pour les petits réseaux. Elle se révèle cependant insuffisante sur les passerelles d'Internet. En effet, si les réseaux empruntés par une route sont saturés, voire hors service, il peut être intéressant d'utiliser une autre route. Ces passerelles utilisent donc des tables de routage dynamiques, qui sont automatiquement mises à jour en fonction de l'état du réseau. Bien que Linux puisse parfaitement effectuer ce type de routage, c'est une configuration réservée à un usage spécifique de Linux. Ce document ne traitera donc pas du routage dynamique.
Le problème des adresses IP est qu'elles ne sont pas très parlantes pour les êtres humains : que peut donc signifier 192.147.23.2 ? Pas grand-chose… C'est pour cela qu'on affecte des noms de machines plus humains, par exemple krypton.andromede.galaxie. Ces noms suivent une convention de nommage bien précise. En général, le premier nom est le nom de la machine elle-même, et la suite du nom constitue ce qu'on appelle le domaine dans laquelle la machine se trouve. Ainsi, dans l'exemple précédent, krypton est le nom d'une machine, et andromede.galaxie est le nom de son domaine. En général, il existe plusieurs machines dans un même domaine, on pourrait donc également avoir altair.andromede.galaxie par exemple (malheureusement pour mon exemple, l'étoile Altaïr ne se trouve pas dans la galaxie d'Andromède, mais bon…). Souvent, les noms de domaines sont des noms de sociétés. La dernière partie du nom de domaine permet également de déterminer la nature du domaine, ou sa localisation. Par exemple, l'extension .com indique clairement que le domaine est de nature commerciale (de surcroît, il s'agit sans doute d'une société américaine, l'extension .com étant réservée aux États-Unis). De même, l'extension .gov est utilisée pour les organismes gouvernementaux américains, et l'extension .edu pour les universités ou les écoles américaines. L'extension .org est utilisée pour les organisations non commerciales. Enfin, les noms de domaines des autres pays que les États-Unis utilisent quasiment systématiquement une extension indiquant leurs pays d'origine. Ainsi, .fr représente la France, .uk les Royaumes-Unis, etc. Notez que la notion de domaine est a priori distincte de la notion de réseau.
La question technique qui se pose avec ces conventions de nommage « humaines » est de savoir comment déterminer, à partir d'un nom littéral, l'adresse IP de la machine correspondante. Cette opération n'est pas simple, et en fait elle est effectuée de deux manières :
- soit la machine locale demande à une autre machine qu'elle connaît d'effectuer la recherche de l'adresse du correspondant ;
- soit elle dispose d'une liste de noms et d'adresses lui permettant de déterminer directement les adresses de ses interlocuteurs.
La première solution utilise ce qu'on appelle un serveur de noms (« DNS » en anglais, abréviation de « Domain Name Service »), qui connaît toutes les machines du réseau soit directement, soit indirectement (donc via un autre DNS). L'opération qui consiste à retrouver l'adresse IP d'une machine à partir de son nom s'appelle la résolution de nom de domaine. Il est évident que si le serveur de noms ne peut être contacté, il sera impossible d'utiliser les noms de machines. En revanche, il sera toujours possible d'utiliser leurs adresses IP directement, si on les connaît. La deuxième solution ne souffre pas de ce défaut, elle nécessite cependant de mettre à jour la liste des noms sur tous les postes régulièrement, ce qui est beaucoup plus complexe que la gestion centralisée d'un DNS. On ne l'utilisera donc que pour les petits réseaux.
IX-A-3. Le protocole TCP▲
Nous avons vu que le protocole IP fournit les briques de base de toute la communication réseau sous Unix (et Internet). Ses principales fonctionnalités sont le découpage des informations en paquets de taille suffisamment petite pour pouvoir transiter sur tous les types de réseaux physiques, la gestion des destinations des paquets à l'aide des adresses IP, et le choix de la route permettant d'acheminer les paquets à destination. En revanche, il est incapable d'assurer les services plus évolués comme la gestion de l'ordre d'arrivée des paquets et la gestion de la fiabilité du transfert des informations. C'est donc à des protocoles plus évolués, eux-mêmes encapsulés dans IP, d'effectuer ces tâches. L'un des protocoles les plus importants est le protocole TCP (abréviation de l'anglais « Transfer Control Protocol »). Ce protocole se charge d'établir les connexions entre deux ordinateurs, et assure la fiabilité des informations transmises et l'arrivée des informations dans leur ordre d'envoi. Il existe d'autres protocoles, moins connus que TCP, mais tout aussi importants. On retiendra en particulier les deux protocoles suivants :
- UDP (abréviation de l'anglais « User Datagram Protocol »), qui permet d'émettre des datagrammes sur le réseau, qui sont de simples paquets de données (c'est un protocole semblable à IP, destiné aux applications) ;
- ICMP (abréviation de « Internet Control Message Protocol »), qui est utilisé essentiellement pour transmettre des messages de contrôle du fonctionnement des autres protocoles (il est donc vital).
Les services réseau des machines sont organisés en couches logicielles, qui s'appuient chacune sur la couche inférieure. Ainsi, TCP utilise IP, qui lui-même utilise le pilote qui gère l'interface réseau. Du fait que ces couches s'appuient les unes sur les autres, on appelle souvent l'ensemble de ces couches une pile (« stack » en anglais). Vous avez peut-être déjà entendu parler de la pile TCP/IP. Lorsqu'un service réseau d'une machine n'est plus accessible, il se peut que ce service réseau ait planté. Si tout un ensemble de services réseau ne fonctionne plus, c'est certainement une des couches logicielles qui est plantée. Par exemple, une machine peut répondre à la commande ping (classiquement utilisée pour tester les connexions réseau) et ne plus accepter la plupart des connexions réseau. Cela signifie simplement que la couche TCP ne fonctionne plus, et que la couche ICMP (utilisée par ping) est toujours valide. Évidemment, si la couche IP tombe en panne, la machine ne sera plus accessible du tout, sauf éventuellement avec d'autres protocoles réseau complètement différents (IPX, Appletalk, etc.).
Seuls les mécanismes du protocole TCP seront détaillés dans la suite de ce document. Le protocole TCP est en effet utilisé par un grand nombre de services, ce qui en fait certainement le plus connu.
Le protocole TCP utilise la notion de connexion. Une connexion est un canal de communication établi entre deux processus par TCP. Comme les processus sont susceptibles d'utiliser plusieurs connexions simultanément, TCP fournit la possibilité de les identifier par un numéro unique sur la machine, compris entre 0 et 65535. Chaque numéro identifie ce qu'on appelle un port TCP. Quand un processus désire établir une connexion avec un autre, il utilise un de ses ports et essaie de se connecter sur le port du deuxième processus.
Il faut bien comprendre que les deux numéros de ports utilisés ne sont a priori pas les mêmes pour les deux processus. Évidemment, il est nécessaire que les processus clients connaissent les numéros de port des processus serveurs auxquels ils se connectent. Les numéros de ports sont donc affectés à des services bien définis, et les serveurs qui fournissent ces services doivent bien entendu utiliser ces numéros de ports. Ainsi, il est possible de déterminer de manière unique un programme serveur sur un réseau avec l'adresse IP de la machine sur laquelle il fonctionne et le numéro de port qu'il écoute pour les connexions extérieures. Les clients qui se connectent savent donc parfaitement à quel service ils accèdent lorsqu'ils choisissent le numéro de port destination. Leur propre numéro de port est en général choisi par le système, afin d'éviter tout conflit avec un autre processus de la même machine.
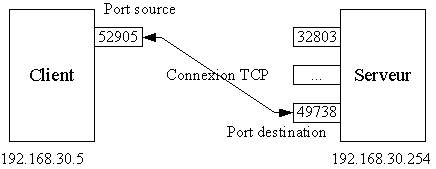
Une fois établie, une connexion TCP permet d'effectuer des communications bidirectionnelles. Cela signifie que le client et le serveur peuvent tous deux utiliser cette connexion pour envoyer des données à l'autre. Le client envoie ses données sur le port destination du serveur, et le serveur peut renvoyer les résultats au client en utilisant le port de celui-ci. Les paquets TCP disposent donc toujours d'un port source (c'est-à-dire le port TCP de l'émetteur), et d'un port destination (le port du récepteur). Ainsi, le récepteur peut renvoyer sa réponse en utilisant le port source comme port de destination du paquet renvoyé, et inversement.
Comme il l'a déjà été dit, le protocole TCP s'assure que les informations transmises arrivent à bon port (c'est le cas de le dire !). Pour cela, il utilise un mécanisme d'accusés réception, qui indiquent à l'émetteur si le destinataire a bien reçu chaque paquet envoyé. Si l'accusé réception n'est pas reçu dans un temps fixé, le paquet est réémis. Un paquet reçu en double à cause d'un retard dans la communication de l'accusé réception est tout simplement ignoré. La fiabilité des informations est également assurée. Cette fiabilité est réalisée par un mécanisme de sommes de contrôle. Si le récepteur constate que la somme de contrôle des données reçues n'est pas celle que l'émetteur a calculée, il rejette le paquet parce qu'il sait que les informations ont été corrompues pendant la transmission. Enfin, TCP s'assure que les informations émises en plusieurs passes sont bien reçues dans leur ordre d'émission. Cette réorganisation se fait grâce à une numérotation des paquets (cette numérotation sert également à détecter les paquets reçus en double). Elle peut paraître inutile, mais la vitesse d'arrivée des paquets est hautement dépendante de la route IP qu'ils prennent pour parvenir à destination. Les paquets qui arrivent en avance sont donc mémorisés jusqu'à ce que tous les paquets qui les précèdent soient reçus.
IX-A-4. Les protocoles de haut niveau▲
TCP fournit donc les fonctionnalités requises pour la plupart des services réseau existant. Il est logique que ceux-ci s'appuient sur lui pour effectuer leur travail. Cependant, il ne se charge que de communiquer les informations, rien de plus. Des protocoles de plus haut niveau ont donc été créés. Leur valeur ajoutée provient souvent du formatage et de la structuration des flux de données échangés.
La plupart des services réseau définissent donc un protocole qui leur est propre. Il est d'ailleurs assez courant de confondre le service et le protocole, tellement ils sont intrinsèquement liés. Ainsi, le service FTP utilise le protocole FTP (« File Transfer Protocol », protocole de transfert de fichiers), les serveurs Internet utilisent essentiellement le protocole HTTP (« Hyper Text Transfer Protocol », protocole de transfert d'hypertexte), le service de courrier électronique utilise les protocoles POP (« Post Office Protocol ») pour la réception des courriers et SMTP (« Simple Mail Transfer Protocol ») pour leur envoi. Cette liste de protocoles n'est pas exhaustive, et de nouveaux services apparaissent régulièrement. Les protocoles de haut niveau ne seront donc pas décrits dans ce document.
Les protocoles de haut niveau transmettent, en général, toutes leurs données en clair sur le réseau. Cela comprend non seulement les données applicatives, mais également les noms d'utilisateurs et les mots de passe. Toute personne ayant physiquement accès au réseau ou à une machine par laquelle les paquets passent peut donc, s'il le désire, récupérer tous les mots de passe avec une simplicité extrême (il existe même des programmes spécialisés pour cela). Il est donc inconcevable d'utiliser tous ces protocoles sans prendre de précautions particulières. Heureusement, il est possible d'encapsuler les protocoles dans un réseau virtuel qui, lui, transmet les données sous forme chiffrée. L'outil le plus utilisé de nos jours est ssh (abréviation de l'anglais « Secure SHell »), qui permet de se connecter sur une machine et de travailler à distance en toute sécurité. Il en existe plusieurs implémentations, dont au moins une libre : OpenSSH. Nous verrons comment configurer et utiliser OpenSSH pour améliorer la sécurité du réseau dans la Section 9.5.2.2.
IX-B. Configuration du réseau sous Linux▲
La configuration du réseau nécessite donc la configuration du protocole IP et des services TCP, UDP et ICMP (entre autres). Cette opération se fait en définissant l'adresse IP le masque de sous-réseau et les routes à utiliser. Vient ensuite la configuration du nom de la machine locale, de son domaine, des noms de machines qu'elle peut résoudre elle-même et des serveurs de DNS qu'elle doit utiliser pour les autres noms.
Il est quasiment certain que votre distribution dispose d'un outil permettant d'effectuer la configuration du réseau simplement. Connaissant à présent la signification des termes utilisés dans les réseaux TCP/IP, vous devriez pouvoir parvenir à une configuration valide relativement simplement. Il est fortement recommandé de consulter la documentation de votre distribution. Les commandes de configuration du réseau sont souvent appelées dans les scripts de démarrage de la machine, ou dans les scripts de changement de niveau d'exécution. Toutefois, il peut être utile de connaître ces commandes, ne serait-ce que pour comprendre comment votre système fonctionne. Cette section a donc pour but de vous présenter ces commandes, ainsi que les principaux fichiers de configuration du réseau utilisés sous Linux.
IX-B-1. Configuration statique des interfaces réseau▲
La principale commande permettant de configurer le réseau est la commande ifconfig. Comme son nom l'indique (« InterFace CONFiguration »), elle permet de configurer les interfaces réseau de la machine. Il faut savoir qu'il existe plusieurs types d'interfaces réseau. Les plus courants sont les trois types d'interfaces suivants :
- l'interface loopback, qui représente le réseau virtuel de la machine, et qui permet aux applications réseau d'une même machine de communiquer entre elles même si l'on ne dispose pas de carte réseau ;
- les interfaces des cartes réseau (que ce soient des cartes Ethernet, TokenRing ou autres) ;
- les interfaces ppp, plip ou slip, qui sont des interfaces permettant d'utiliser les connexions sérielles, parallèles ou téléphoniques comme des réseaux.
La configuration d'une interface comprend l'initialisation des pilotes nécessaires à son fonctionnement et l'affectation d'une adresse IP à cette interface. La syntaxe générale que vous devrez utiliser est la suivante :
ifconfig interface adresse netmask masque upoù interface est le nom de l'interface réseau que vous voulez configurer, adresse est l'adresse IP que cette interface gérera, et masque est le masque de sous-réseau que vous utilisez. Les interfaces que vous aurez à configurer seront certainement des interfaces Ethernet, auquel cas vous devrez utiliser les noms eth0, eth1, etc. dans la commande ifconfig. Si vous désirez configurer l'interface loopback, vous devrez utiliser le nom d'interface lo.
Le paramètre up donné à ifconfig lui indique que l'interface doit être activée. Cela signifie que dès que la commande ifconfig s'achèvera, votre interface réseau sera active et fonctionnelle. On ne peut faire plus simple… Bien entendu, il existe le paramètre inverse : down. Ce paramètre s'utilise tout simplement dans la commande ifconfig avec la syntaxe suivante :
ifconfig interface downoù interface est toujours le nom de l'interface.
Un exemple de configuration très classique est le suivant :
ifconfig eth0 192.168.0.1 netmask 255.255.255.0 upNote : Prenez bien garde, lorsque vous écrivez vos adresses IP, à ne pas rajouter de 0 supplémentaire devant les nombres qui la constituent. En effet, il existe une convention en informatique qui dit que les nombres préfixés d'un 0 sont codés en octal, c'est-à-dire en base 8. Il va de soi qu'une adresse IP codée en octal n'utilise pas les mêmes nombres que lorsqu'elle est exprimée en décimal, aussi éprouveriez-vous quelques difficultés pour diagnostiquer le non-fonctionnement de votre réseau si vous faisiez cette erreur !
Le noyau utilisera par défaut le nombre 255 pour les adresses de broadcast dans les composantes de l'adresse IP qui ne fait pas partie de l'adresse de sous-réseau. Si vous désirez utiliser une autre adresse (en général, l'alternative est de prendre l'adresse du sous-réseau), vous devrez utiliser l'option broadcast adresse dans la commande ifconfig. Cependant, le comportement par défaut convient à la plupart des réseaux. La commande de configuration donnée en exemple ci-dessus sera alors :
ifconfig eth0 192.168.0.1 netmask 255.255.255.0 broadcast 192.168.0.0 upEnfin, il est possible d'affecter plusieurs adresses IP à certaines interfaces réseau. C'est en particulier le cas pour toutes les interfaces réseau classiques, mais bien entendu cela n'est pas réalisable avec les interfaces de type point à point comme les interfaces des connexions ppp. Lorsqu'une interface dispose de plusieurs adresses, la première est considérée comme l'adresse principale de l'interface, et les suivantes comme des alias. Ces alias utilisent comme nom le nom de l'interface réseau principale et le numéro de l'alias, séparés par un deux-points (caractère ':'). Par exemple, si l'interface eth0 dispose d'un alias, celui-ci sera nommé eth0:0. Ainsi, pour fixer l'adresse d'un alias d'une interface réseau, on utilisera la syntaxe suivante :
ifconfig interface:numéro add adresse netmask masqueoù interface est toujours le nom de l'interface, numéro est le numéro de l'alias, adresse est l'adresse IP à attribuer à cet alias, et masque est le masque de sous-réseau de cette adresse.
La commande ifconfig est en général appelée dans les scripts d'initialisation du système, qui ont été générés par l'utilitaire de configuration réseau de votre distribution. Si vous effectuez un grep sur « ifconfig » dans le répertoire /etc/rc.d/ (ou /sbin/init.d/, selon votre distribution), vous trouverez la commande de démarrage du réseau. Il se peut qu'une variable d'environnement soit utilisée à la place de l'adresse IP que vous avez choisie. Quoi qu'il en soit, vous devez sans aucun doute avoir les lignes suivantes, qui permettent l'initialisation de l'interface loopback :
ifconfig lo 127.0.0.1 netmask 255.0.0.0 upIX-B-2. Définition des règles de routage▲
La deuxième étape dans la configuration du réseau est la définition des règles de routage. Il est possible de définir plusieurs règles de routage actives simultanément. L'ensemble de ces règles constitue ce qu'on appelle la table de routage. La règle utilisée est sélectionnée par le noyau en fonction de l'adresse destination du paquet à router. Chaque règle indique donc un critère de sélection sur les adresses, et l'interface vers laquelle doivent être transférés les paquets dont l'adresse destination vérifie cette règle.
La commande utilisée pour définir une route est, chose surprenante, la commande système route. Sa syntaxe est donnée ci-dessous :
route opération [-net | -host] adresse netmask masque interfaceoù opération est l'opération à effectuer sur la table de routage. L'opération la plus courante est simplement l'ajout d'une règle de routage, auquel cas add doit être utilisé. L'option suivante permet d'indiquer si le critère de sélection des paquets se fait sur l'adresse du réseau destination ou plus restrictivement sur l'adresse de la machine destination. En général, il est courant d'utiliser la sélection de toutes les adresses d'un même réseau et de les router vers une même interface. Dans tous les cas, adresse est l'adresse IP de la destination, que celle-ci soit un réseau ou une machine. Si la destination est un réseau, il faut indiquer le masque de sous-réseau masque à l'aide de l'option netmask. Enfin, interface est l'interface réseau vers laquelle doivent être envoyés les paquets qui vérifient les critères de sélection de cette règle.
Par exemple, la règle de routage à utiliser pour l'interface loopback est la suivante :
route add -net 127.0.0.0 netmask 255.0.0.0 loCette règle signifie que tous les paquets dont l'adresse de destination appartient au sous-réseau de classe A 127.0.0.0 doivent être transférés vers l'interface loopback. Cela implique en particulier que les paquets à destination de la machine d'adresse IP 127.0.0.1 (c'est-à-dire la machine locale) seront envoyés vers l'interface loopback (ils reviendront donc sur la machine locale).
Une autre règle de routage classique est la suivante :
route add -net 192.168.0.0 netmask 255.255.255.0 eth0Elle permet d'envoyer tous les paquets à destination du réseau de classe C 192.168.0.0 vers la première interface Ethernet. C'est typiquement ce genre de règle qu'il faut utiliser pour faire fonctionner un réseau local.
Il n'est normalement pas nécessaire d'ajouter les règles de routage pour les réseaux auxquels la machine est connectée. En effet, la configuration d'une carte réseau à l'aide de la commande ifconfig ajoute automatiquement à la table de routage une règle pour envoyer les paquets à destination de ce réseau par l'interface réseau qui y est connectée. Cependant, la commande route devient réellement nécessaire lorsqu'il faut définir les passerelles à utiliser pour l'envoi des paquets destinés à une machine à laquelle la machine locale ne peut accéder directement. Les règles de routage faisant intervenir une passerelle sont semblables aux règles de routage vues ci-dessus, à ceci près que l'adresse IP de la passerelle à utiliser doit être fournie. Pour cela, on utilise l'option gw (abréviation de l'anglais « Gateway »). La syntaxe utilisée est donc la suivante :
route add [-net | -host] adresse netmask masque gw passerelle interfaceoù passerelle est l'adresse IP de la passerelle à utiliser pour router les paquets qui vérifient les critères de cette règle. Les autres paramètres sont les mêmes que pour les règles de routage classique.
Par exemple, supposons qu'une machine soit connectée à un réseau d'adresse 192.168.0.0, et que sur ce réseau se trouve une passerelle d'adresse 192.168.0.1 permettant d'atteindre un autre réseau, dont l'adresse est 192.168.1.0. Une machine du réseau 192.168.0.0 aura typiquement les règles de routage suivantes :
route add -net 192.168.0.0 netmask 255.255.255.0 eth0
route add -net 192.168.1.0 netmask 255.255.255.0 gw 192.168.0.1 eth0La première règle permet, comme on l'a déjà vu, de communiquer avec toutes les machines du réseau local. La deuxième règle permet d'envoyer à la passerelle 192.168.0.1 tous les paquets à destination du réseau 192.168.1.0.
Inversement, si la passerelle utilise l'adresse 192.168.1.15 sur le réseau 192.168.1.0, les machines de ce réseau qui voudront accéder au réseau 192.168.0.0 devront spécifier la règle de routage suivante :
route add -net 192.168.0.0 netmask 255.255.255.0 gw 192.168.1.15 eth0Bien entendu, il est nécessaire que toutes les machines des deux réseaux utilisent ces règles de routage pour que la communication entre les deux réseaux se fasse dans les deux sens.
Le problème de ces règles de routage est qu'elles spécifient l'adresse du réseau destination. Il est évidemment hors de question d'utiliser une règle de routage différente pour toutes les adresses de réseaux possibles. Il est donc possible de définir ce qu'on appelle une passerelle par défaut, qui n'est rien d'autre que la passerelle vers laquelle doivent être envoyés tous les paquets qui n'ont pas vérifié les critères des autres règles de routage. La syntaxe à utiliser pour définir la passerelle par défaut est plus simple, puisqu'il n'est plus nécessaire de préciser les critères de sélection :
route add default gw passerelle interfaceoù la signification des paramètres passerelle et interface est inchangée.
Ainsi, pour reprendre l'exemple précédent, supposons que la machine 192.168.0.47 dispose d'une connexion à Internet et soit configurée pour partager cette connexion avec les machines du réseau local. Pour que toutes les machines du réseau local puissent profiter de cette connexion, il suffit de demander à ce que tous les paquets qui ne vérifient aucune autre règle de routage soient envoyés à la passerelle 192.168.0.47. Cela se fait avec la règle de routage suivante :
route add default gw 192.168.0.47 eth0IX-B-3. Définition du nom de la machine▲
La configuration du nom d'un ordinateur n'est pas à proprement parler une opération indispensable, mais elle permet de le nommer de manière plus conviviale qu'en utilisant son adresse IP. La commande de base permettant de manipuler le nom de la machine locale est la commande hostname. Appelée telle quelle, elle renvoie le nom actuel de la machine :
hostnameCette commande permet également de modifier ce nom, simplement avec la syntaxe suivante :
hostname nomoù nom est le nom à utiliser. Il est d'usage de n'utiliser que le nom de la machine, sans son domaine. Le nom de domaine est déterminé automatiquement par le système à partir des informations issues de la configuration de la résolution des noms de domaine. Nous verrons cela dans le paragraphe suivant.
Cette commande est donc très simple à utiliser, et elle est en général appelée dans les scripts de démarrage du système. La plupart des distributions utilisent le fichier /etc/HOSTNAME pour stocker le nom de la machine. Vous êtes bien entendu libre de choisir le nom que vous voulez pour votre ordinateur, mais vous devez vous assurer que ce nom est unique dans votre domaine !
IX-B-4. Résolution des noms de domaine▲
La commande hostname ne permet de fixer que le nom de la machine locale. Pour les autres machines du réseau, il faut mettre en place les mécanismes de résolution de noms de domaine. Comme il l'a déjà été indiqué au début de ce chapitre, il existe deux solutions pour trouver l'adresse IP d'une machine à partir de son nom : la consultation d'une liste de noms stockée en local, soit l'interrogation d'un serveur de noms de domaine.
Le fichier /etc/host.conf permet de définir le comportement du système lors de la résolution d'un nom. Sa structure est très simple, puisqu'il y a une option de recherche par ligne. Dans la plupart des cas, les lignes suivantes sont suffisantes :
order hosts,bind
multi onElles permettent d'indiquer que la recherche des noms pour leur résolution doit se faire d'abord localement, puis par appel aux DNS si la recherche précédente a échoué. C'est en général le comportement désiré. La deuxième ligne permet de faire en sorte que toutes les adresses correspondant à une machine soient renvoyées. Si l'on avait utilisé l'option multi off, seule la première adresse IP trouvée aurait été renvoyée.
La liste de noms locale est stockée dans le fichier /etc/hosts (cela explique le nom hosts utilisé pour l'option order dans le fichier /etc/host.conf). Votre ordinateur connaîtra directement l'adresse IP de toutes les machines référencées dans ce fichier. Il est bon de placer ici une entrée pour les ordinateurs les plus couramment utilisés sur le réseau. Chaque entrée commence par une adresse IP, et est suivie de la liste des noms de la machine possédant cette adresse, séparés par des espaces. Pour ceux qui ne disposent pas de réseau local, ce fichier doit être relativement simple : seule la ligne affectant l'adresse 127.0.0.1 à la machine locale (appelée « localhost ») doit s'y trouver.
127.0.0.1 localhostDe la même manière, le fichier /etc/networks contient les adresses des réseaux. Ce fichier est utilisé par la commande route pour donner un nom aux différents réseaux. Chaque entrée est constituée du nom du réseau, suivi de son adresse IP. Encore une fois, ce fichier se réduit à sa plus simple expression pour ceux qui n'ont pas de réseau local, puisqu'il ne contiendra tout au plus qu'une entrée pour le réseau « loopback », sur lequel se trouve l'adresse de retour 127.0.0.1. Cette entrée aura donc la forme suivante :
loopback 127.0.0.0La configuration des serveurs de noms est en revanche une opération nécessaire si l'on désire accéder à des machines dont on ne connaît que le nom. Le fichier de configuration utilisé est cette fois le fichier /etc/resolv.conf. Sa structure est encore une fois très simple, avec une option par ligne, chaque option étant introduite par un mot clé.
Le mot clé domain permet d'indiquer le nom du domaine dont fait partie votre machine. Par exemple, si votre nom de domaine est « andromede.galaxie », vous devrez utiliser la ligne suivante :
domain andromede.galaxieLe mot clé search permet quant à lui de spécifier une liste de noms de domaines à ajouter par défaut aux noms de machines non complètement qualifiés. Les éléments de cette liste doivent être séparés par des espaces. La recherche d'une machine dont le nom ne comprend pas la partie de nom de domaine s'effectue en ajoutant au nom de la machine les noms des domaines indiqués ici, jusqu'à ce que la résolution du nom en adresse IP réussisse. Cette recherche commence bien entendu par le nom de domaine local, s'il a été défini. Il est donc recommandé d'indiquer votre nom de domaine dans cette liste de noms de domaines. Par exemple, si votre machine fait partie du domaine « andromede.galaxie », vous devrez utiliser la ligne suivante :
search andromede.galaxieAinsi, si vous recherchez l'adresse de la machine « krypton », la requête au DNS se fera avec le nom complètement qualifié « krypton.andromede.galaxie ». Vous êtes bien entendu libre d'ajouter d'autres noms de domaines pour le cas où la résolution de nom échouerait sur ce domaine.
Enfin, l'option nameserver est essentielle, puisqu'elle permet de donner les adresses IP des serveurs de DNS auxquels doivent être adressées les requêtes de résolution de noms. Par exemple, si vous disposez de deux serveurs DNS, un primaire, d'adresse 192.168.0.10, et un secondaire, d'adresse 192.168.0.15, vous utiliserez la ligne suivante :
nameserver 192.168.0.10 192.168.0.15Cette ligne est évidemment obligatoire, faute de quoi la résolution des noms de machines en adresse IP échouera pour toute machine qui ne se trouve pas dans votre fichier /etc/hosts.
IX-B-5. Utilisation des protocoles DHCP et BOOTP▲
Généralement, la gestion des adresses IP des machines devient rapidement une tâche difficile sur les grands réseaux, pour trois raisons. Premièrement, il faut toujours s'assurer que chaque machine dispose bien d'une adresse qui lui est propre, ce qui peut être difficile si l'on ne s'organise pas en conséquence. Deuxièmement, il faut que les fichiers /etc/hosts de toutes les machines soient à jour, ce qui nécessite un travail proportionnel au nombre de machines administrées. Enfin, le nombre d'adresses IP disponibles peut se réduire, ce qui peut devenir gênant à terme.
Afin de résoudre ces problèmes de configuration réseau, le protocole DHCP (abréviation de l'anglais « Dynamic Host Configuration Protocol ») a été défini. Il s'agit d'un protocole qui permet aux machines connectées sur un réseau d'interroger un « serveur d'adresses » du réseau capable de gérer une liste d'adresses et de les affecter dynamiquement aux machines du réseau. En fait, ce protocole permet de fournir plus d'informations que les simples adresses IP, par exemple la route par défaut que les machines doivent utiliser, ainsi que les adresses des serveurs de noms du réseau.
Un autre protocole semblable à DHCP a également été développé dans le but de permettre la configuration réseau des machines dès leur démarrage : le protocole BOOTP (abréviation de l'anglais « BOOTstrap Protocol »). Ce protocole est évidemment plus léger que DHCP, mais permet aux machines d'obtenir dynamiquement leur configuration réseau dès leur démarrage, avant même que ne soient montés les systèmes de fichiers. Ce protocole est donc particulièrement utile pour faire démarrer des machines sans disque, pour lesquelles le système de fichiers racine est monté en NFS.
La manière la plus simple de configurer les protocoles DHCP et BOOTP sur un poste client est d'utiliser les fonctionnalités d'autoconfiguration du noyau. Cependant, il est également possible d'effectuer cette configuration au niveau utilisateur à l'aide de programmes complémentaires. Les deux sections suivantes décrivent ces deux techniques.
IX-B-5-a. Autoconfiguration des clients DHCP et BOOTP▲
La configuration des protocoles DHCP et BOOTP ne comporte aucune difficulté particulière lorsque l'on utilise les fonctionnalités d'autoconfiguration du noyau. Ces fonctionnalités étant prises en charge au niveau du noyau, il va vous falloir recompiler un nouveau noyau pour en bénéficier. Cette opération en revanche est relativement technique, et doit être faite avec soin. La manière de procéder a été décrite en détail dans la Section 7.3.
L'option à activer pour permettre l'utilisation du protocole BOOTP est l'option « IP: kernel level autoconfiguration » du menu « Networking options ». Cette option vous permettra de sélectionner le protocole d'autoconfiguration réseau que le noyau devra utiliser lors de son amorçage. Vous devrez alors choisir l'option « IP: DHCP support (NEW) » ou l'option « IP: BOOTP support (NEW) » pour activer respectivement les protocoles DHCP et BOOTP.
Note : Vous remarquerez qu'il existe également un autre protocole d'autoconfiguration du réseau au démarrage : le protocole RARP. Ce protocole fournit les mêmes services que le protocole BOOTP, mais est plus ancien. Il n'est donc plus conseillé de l'utiliser, sauf vous vous trouvez sur un réseau pour lequel seul le protocole RARP est disponible.
Une fois ces options sélectionnées, vous pourrez recompiler votre noyau, l'installer et redémarrer la machine. Lors du démarrage, le noyau doit chercher un serveur DHCP ou un serveur BOOTP sur le réseau local pour effectuer la configuration réseau de votre carte réseau.
Note : Vous devrez peut-être également activer les options « NFS file system support » et « Root file system on NFS » du menu « Network File Systems » si vous désirez faire démarrer votre machine sur un système de fichiers racine monté en NFS lors du démarrage.
IX-B-5-b. Configuration d'un client DHCP au niveau utilisateur▲
Il est également possible de configurer les clients DHCP au niveau utilisateur, à l'aide de programmes complémentaires. Comme sur la plupart des machines Unix, le programme à utiliser est le programme dhclient. Ce programme est généralement lancé dans les scripts de démarrage des machines, et envoie des paquets de demandes de configuration sur le réseau à l'adresse de diffusion générale 255.255.255.255. Ces paquets sont donc susceptibles d'être captés par toutes les machines du réseau, mais seuls les serveurs DHCP y répondent. Les réponses obtenues sont alors analysées par dhclient, qui configure en conséquence l'interface réseau et passe ensuite en arrière-plan.
Les informations envoyées par les serveurs DHCP peuvent être plus ou moins complètes, la base étant bien sûr l'adresse IP de la machine et son masque de sous-réseau. Il est toutefois possible de donner plus d'informations, par exemple les adresses des serveurs de noms, des routes par défaut et des passerelles à utiliser.
Les adresses IP attribuées aux clients ne sont pas permanentes, car le protocole DHCP est avant tout destiné à la configuration automatique des postes itinérants ou susceptibles de redémarrer souvent. Par conséquent, ces adresses sont fournies dans le cadre d'un bail, dont la durée maximum est fixée par le serveur. Dès que le bail obtenu par un client expire, celui-ci doit chercher à le renouveler. C'est encore le programme dhclient qui s'en charge. C'est la raison pour laquelle celui-ci passe en arrière-plan après avoir configuré l'interface pour la première fois : il attend la fin des baux de la machine sur laquelle il tourne et cherche à les renouveler. Si un client ne renouvelle pas ce bail (parce qu'il est arrêté par exemple), le serveur DHCP peut réutiliser son adresse IP et l'affecter à une autre machine. Bien que les serveurs DHCP s'efforcent généralement de conserver les adresses IP des clients à chaque bail, un client configuré par DHCP ne peut donc pas considérer que son adresse IP restera toujours la même. C'est la contrepartie de la flexibilité.
Si aucun serveur DHCP ne peut être contacté lors du démarrage, dhclient abandonne temporairement et réessaie au bout d'un temps aléatoire. Au bout d'un certain nombre d'essais non fructueux, il peut décider de configurer les interfaces réseau avec les adresses IP des anciens baux obtenus par la machine. Pour cela, il mémorise dans le fichier de configuration /var/db/dhclient.lease les adresses IP de ces anciens baux. Ce fichier est périodiquement réécrit avec la liste des adresses des baux valides afin d'éviter qu'il ne se remplisse ad vitam eternam.
Bien entendu, les postes clients ne peuvent pas choisir leurs adresses IP sans vérification d'unicité. Dans le cas de l'absence de serveur DHCP (et donc d'autorité centrale), les clients qui démarrent interrogent les machines déjà présentes sur le réseau pour déterminer si l'adresse qu'ils envisagent de prendre est bien libre. Dans le cas contraire, une autre adresse est essayée, et ainsi de suite. Ainsi, même en cas de panne de tous les serveurs DHCP d'un réseau, les postes clients peuvent toujours travailler ensemble sans conflit d'adresses IP.
Comme vous pouvez le constater, le comportement de dhclient est relativement complexe et dépend de nombre de paramètres. Tous ces paramètres peuvent être définis dans le fichier de configuration /etc/dhclient.conf. Ce fichier contient en particulier les différentes durées intervenant dans le choix des adresses IP, par exemple la durée minimale d'un bail, les durées entre chaque tentative de configuration, les informations qui doivent être récupérées des serveurs DHCP, ainsi que les valeurs par défaut pour ces informations lorsque les serveurs ne les fournissent pas. Le fichier de configuration dhclient.conf est donc relativement complexe. Heureusement, dhclient utilise des options par défaut qui conviennent dans la plupart des cas, aussi est-il fortement probable que votre fichier dhclient.conf soit vide. Si toutefois vous désirez en savoir plus, vous pouvez consulter la page de manuel dhclient.conf.
La configuration DHCP pour les postes clients se réduit donc à l'essentiel : le lancement de dhclient. Celui-ci s'utilise avec la syntaxe suivante :
dhclient interface0 [interface1 […]]où interface0, interface1, etc., sont les interfaces réseau qui doivent être configurées par DHCP. On ne peut donc pas faire plus simple…
Note : Sous Linux, le programme dhclient utilise les fonctionnalités d'accès direct aux cartes réseau et de filtrage des paquets. Ces deux fonctionnalités peuvent être activées dans la configuration du noyau à l'aide des options « Packet socket », « Packet socket: mmapped IO » et « Socket Filtering » du menu « Networking options ». L'option « IP: multicasting » de la liste des options du protocole IP devra également être activée. Le détail de la configuration et de la compilation du noyau a été vu dans la Section 7.3.
Le programme dhclient est assez facétieux depuis quelques versions. S'il refuse obstinément de fonctionner, vous devrez sans doute vous rabattre vers le programme dhcpcd, beaucoup plus simple, mais également beaucoup plus fiable. La plupart des distributions utilisent de dernier en lieu et place de dhclient. Consultez la documentation de votre distribution pour déterminer la solution qu'elle utilise.
IX-B-6. Définition des protocoles de haut niveau▲
Comme nous l'avons vu plus haut, le protocole IP fournit les mécanismes de base pour la transmission des paquets. Plusieurs protocoles de plus haut niveau ont été définis pour fournir des services à valeur ajoutée, qui satisfont donc plus aux besoins des applications. Tous ces protocoles sont encapsulés dans le protocole IP, ce qui signifie que leurs informations sont transmises en tant que données dans les paquets IP.
En réalité, les paquets du protocole IP contiennent un champ permettant de signaler le type de protocole de haut niveau dont ils transportent les informations. À chaque protocole est donc attribué un identificateur numérique qui lui est propre, et qui permet aux services réseau d'interpréter les données des paquets.
Tout comme les adresses IP, ces numéros identifiant les protocoles ne sont pas très intéressants pour les humains, qui leur préfèrent évidemment le nom du protocole. Certains programmes réseau utilisent donc ces noms pour identifier les protocoles. Pour leur permettre de faire l'association entre ces noms et les identificateurs numériques, le fichier /etc/protocols est utilisé.
Le format de ce fichier est très simple. Il contient une ligne pour chaque protocole, constituée du nom du protocole, de la valeur de son identificateur, et des autres noms que ce protocole peut avoir (c'est-à-dire ses alias). Parmi ces protocoles, les plus importants sont les suivants :
|
Nom |
Numéro |
Alias |
|
ip |
0 |
IP |
|
icmp |
1 |
ICMP |
|
tcp |
6 |
TCP |
|
udp |
17 |
UDP |
Comme on le voit, le protocole IP dispose lui-même d'un identificateur de protocole (qui vaut 0 en l'occurrence). Cet identificateur est un identificateur de « pseudo protocole », parce qu'IP est en fait le protocole de base. ICMP est identifié par le numéro 1, TCP par le numéro 6 et UDP par le numéro 17. Il existe beaucoup d'autres protocoles, qui ne seront pas décrits ici. Bien entendu, le fichier /etc/protocols fourni avec votre distribution doit déjà contenir la définition de la plupart des protocoles.
De la même manière, la plupart des ports TCP et UDP sont affectés à des services bien définis, et certains programmes réseau peuvent chercher à faire la correspondance entre les noms de ces services et les numéros de ports. Cette correspondance est stockée dans le fichier de configuration /etc/services.
Les informations concernant les services sont données à raison d'une ligne par service. Chaque ligne suit la syntaxe suivante :
nom port/protocole aliasoù nom est le nom du service décrit par cette ligne, port est le numéro du port utilisé par ce service, protocole est le nom du protocole utilisé par ce service (ce peut être « tcp » ou « udp »), et alias la liste des autres noms sous lesquels ce service est également connu.
Vous trouverez les principaux services dans l'extrait donné ci-dessous :
|
Service |
Port/Protocole |
|
ftp |
21/tcp |
|
telnet |
23/tcp |
|
smtp |
25/tcp |
|
pop3 |
110/tcp |
|
irc |
194/tcp |
|
irc |
194/udp |
Comme vous pouvez le constater, ces services n'ont pas d'alias. Ces informations sont données uniquement à titre d'exemple. Il va de soi que le fichier /etc/services fourni avec votre distribution contient la définition d'un grand nombre de services, et vous n'aurez en général pas à y toucher.
IX-B-7. Les super-démons inetd et xinetd▲
La plupart des services réseau sont gérés par des programmes qui s'exécutent en permanence et qui attendent des connexions sur un port TCP ou UDP. Ces programmes consomment relativement peu de ressources, car ils passent la plupart de leur temps à attendre ces connexions. Ils ne se réveillent que lorsqu'un client se connecte effectivement et leur envoie une requête.
Cependant, ils peuvent être relativement nombreux, et si tous les services sont lancés simultanément, ils peuvent finir par consommer une part non négligeable des ressources système. C'est pour cette raison que les super-démons inetd (de l'anglais « InterNET Daemon ») et xinetd (de l'anglais « eXtended INETD ») ont été créés. Ces démons sont à l'écoute des demandes de connexion des clients pour les autres services réseau, et ne lancent ceux-ci que lorsqu'un client se connecte sur leurs ports. Une fois lancés, les véritables démons reprennent la main et communiquent directement avec leurs clients. Ainsi, inetd et xinetd écoutent les ports pour tout le monde, et sont la plupart du temps les seuls à fonctionner. Les ressources système sont donc économisées et les services réseau sont démarrés et arrêtés à la demande.
Le super-démon xinetd est appelé à remplacer inetd, qui lui est beaucoup plus ancien et nettement moins souple. En pratique, un seul de ces super-démons doit être démarré sur une machine (il est inutile de les lancer tous les deux, car les clients ne peuvent se connecter qu'à un seul d'entre eux de toute manière). Les deux sections suivantes décrivent la configuration de ces super-démons.
IX-B-7-a. Le super-démon inetd▲
Le super-démon inetd laisse de plus en plus la main au nouveau super-démon xinetd qui est beaucoup plus puissant, mais reste toutefois très utilisé sur de nombreuses machines. Sa description n'est donc pas inutile, car toutes les distributions n'utilisent pas encore xinetd.
Le super-démon inetd utilise le fichier de configuration /etc/inetd.conf pour déterminer les ports sur lesquels il doit attendre des connexions de la part des clients, et pour trouver le service réseau qu'il doit lancer lorsqu'une telle connexion arrive. Ce fichier est structuré en lignes, dont chacune décrit un des services que le démon inetd prend en charge. Les informations données sur ces lignes sont les suivantes :
- le nom du service (tel qu'il est défini dans la première colonne du fichier /etc/services) dont inetd doit surveiller les requêtes ;
- le type de canal de communication réseau utilisé, en général « stream » (pour les communications en mode connecté, donc en général celles qui utilisent le protocole TCP) ou « dgram » (pour les communications basées sur les datagrammes, donc typiquement les communications utilisant le protocole UDP) ;
- le protocole réseau utilisé (« tcp » ou «udp ») par ce service ;
- l'un des mots clés wait ou nowait, qui permettent d'indiquer si inetd doit attendre la fin de l'exécution du démon gérant le service ou s'il peut attendre de nouvelles requêtes de la part des clients ;
- le nom de l'utilisateur au nom duquel le démon gérant ce service doit fonctionner (en général, c'est l'utilisateur root) ;
- le chemin sur le fichier exécutable de ce démon ;
- les éventuels paramètres en ligne de commande pour ce démon, en commençant par l'argument 0, qui doit toujours être le nom du fichier exécutable du programme lui-même.
Par exemple, la ligne suivante permet de lancer le démon telnetd sur toute requête via le protocole TCP pour le service telnet :
telnet stream tcp nowait root /usr/sbin/in.telnetd in.telnetdIl est supposé ici que le démon en charge de ce service peut être lancé avec le programme /usr/sbin/in.telnetd.
Le démon inetd est capable de fournir lui-même un certain nombre de services de base, et il n'est pas nécessaire de fournir un démon pour ces services. Dans ce cas, il faut utiliser le mot clé internal à la place du nom du fichier exécutable du démon de ce service. Les paramètres doivent également être remplacés par le mot clé internal.
En fait, il est fort peu probable que votre fichier de configuration /etc/inetd.conf définisse les services comme indiqué dans cette section. En effet, un programme intermédiaire en charge d'assurer des contrôles de sécurité est souvent intercalé entre inetd et les démons gérant les services. Nous verrons ce que fait exactement ce programme dans une prochaine section.
IX-B-7-b. Le super-démon xinetd▲
Le super-démon xinetd utilise un autre fichier de configuration que celui du super-démon inetd. Pour xinetd, la définition des services mis à disposition des clients se fait dans le fichier de configuration /etc/xinetd.conf. Toutefois, contrairement au fichier inetd.conf, le fichier xinetd.conf peut inclure d'autres fichiers de configuration et référencer des répertoires contenant les fichiers de configuration spécifiques aux services. Ainsi, la configuration des services est beaucoup plus modulaire et se fait plus facilement.
En pratique, il est d'usage de définir les options par défaut pour tous les services dans le fichier de configuration /etc/xinetd.conf, et de décrire les différents services dans des fichiers complémentaires stockés dans le répertoire /etc/xinetd.d/. Ce répertoire est alors inclus directement dans le fichier xinetd.conf à l'aide de la directive includedir dédiée à cet usage.
Les fichiers de configuration de xinetd sont constitués de sections permettant de décrire les services pris en charge, ou tout simplement les options par défaut applicables à tous les services. La forme générale de ces sections est la suivante :
service
{
option opérateur valeur [valeur […]]
option opérateur valeur [valeur […]]
…
}où service est le nom du service (ou defaults pour les options par défaut), option est un mot-clé identifiant une des options de ce service, et opérateur est l'un des opérateurs '=' (pour la définition de la valeur d'une option ou l'écrasement de sa valeur précédente), '+=' (pour compléter la liste de valeurs d'une option) ou '-= (pour supprimer une valeur de la liste de valeurs d'une option). Les valeurs des options peuvent être multiples, et leur nature dépend des options utilisées.
Les principales options utilisables dans ces sections sont les suivantes :
|
Option |
Signification |
|
id |
Identificateur du service, pour le cas où plusieurs sections devraient être définies pour un même service. Cette possibilité est utilisée lorsque l'on désire fournir des options différentes pour un même service. L'entrée choisie (et donc le jeu d'options choisi) dépend dans ce cas de critères définis par exemple sur l'interface réseau ou sur les adresses des clients. |
|
type |
Permet d'indiquer la nature du service décrit par cette section. Généralement, cette option n'a pas à être donnée, sauf lorsque l'on veut forcer la méthode d'implémentation d'un service. Par exemple, il est possible de donner la valeur INTERNAL à cette option pour utiliser l'un des services implémentés par xinetd en interne. |
|
server |
Permet de donner le chemin sur l'exécutable du démon prenant en charge le service décrit. |
|
server_args |
Permet de donner les paramètres en ligne de commande du démon prenant en charge le service. Notez que, contrairement à ce qui se fait avec inetd, il ne faut généralement pas donner le nom de l'exécutable en premier argument dans cette option. Cette règle peut toutefois être rendue fausse en ajoutant la valeur NAMEINARGS dans l'option flags décrite ci-dessous. |
|
socket_type |
Le type de canal de communication utilisé (« stream » ou « dgram », comme pour inetd). |
|
protocol |
Le protocole réseau utilisé par le service (« tcp » ou « udp », comme pour inetd). |
|
port |
Le port sur lequel le service peut être trouvé. Cette option est facultative. Si elle n'est pas indiquée, le numéro de port utilisé sera celui indiqué dans le fichier de configuration /etc/services pour le service en cours de configuration. |
|
wait |
L'indicateur de capacité du démon a géré plusieurs connexions simultanément. Les valeurs que l'on peut donner à cette option sont « yes » et « no », respectivement pour indiquer que le démon peut gérer plusieurs connexions simultanément ou non. Dans ce dernier cas, le démon xinetd lancera plusieurs instances du démon gérant le service si plusieurs clients cherchent à se connecter simultanément. Le nombre maximum d'instances peut toutefois être contrôlé à l'aide des options instances et per_source décrites ci-dessous. |
|
flags |
Les paramètres permettant de contrôler différents aspects du service. Les options les plus courantes sont « IDONLY », qui permet de n'autoriser que les connexions provenant de machines disposant d'un serveur d'identification des clients, « NORETRY », qui permet d'éviter de réessayer de lancer le démon du service si le lancement précédent a échoué, et « NAMEINARGS», qui permet d'indiquer que le nom de l'exécutable doit être spécifié en premier paramètre dans l'option server_args. |
|
user |
Le compte utilisateur dans lequel le démon prenant en charge le service doit être lancé. Cette option ne peut bien entendu pas être utilisée pour les services gérés en interne par xinetd. |
|
interface |
L'interface à laquelle le service est attaché. Cette option permet de définir plusieurs configurations pour un même service et d'affecter ces différentes configurations à des interfaces réseau distinctes. Pour l'heure, seule l'adresse IP de l'interface réseau peut être spécifiée grâce à cette option, ce qui impose d'avoir des adresses IP fixes. |
|
only_from |
La liste des adresses des machines autorisées à se connecter. Il est possible de spécifier les adresses IP explicitement ou à l'aide d'une adresse et d'un masque de sous-réseau. Les noms de domaines peuvent également être utilisés. Dans ce cas, le nom n'est pas transformé en adresse IP. Au contraire, c'est l'adresse du client qui est retransformée en nom de machine pour vérifier s'il a le droit de se connecter. Notez que l'absence de ce champ indique que, par défaut, l'accès est accordé à toutes les machines (sauf celles explicitement interdites de connexion par l'option no_access décrite ci-dessous). En revanche, la présence de ce champ, mais sans valeur permet d'interdire l'accès à toutes les machines. |
|
no_access |
La liste des adresses des machines qui n'ont pas le droit de se connecter. Les adresses peuvent être spécifiées de la même manière que pour l'option only_from. Si une adresse vérifie les critères des deux options only_from et no_access, c'est l'option dont le critère est le plus précis qui est choisie. |
|
access_times |
La période pendant laquelle le service est accessible. Cette période peut être exprimée sous la forme d'une liste d'intervalles « heure:minute-heure:minute ». |
|
instances |
Permet d'indiquer le nombre maximum d'instances d'un même démon que xinetd peut lancer. Cette option permet donc de spécifier un nombre de connexions maximum pour chaque service. |
|
per_source |
Permet d'indiquer le nombre maximum d'instances d'un même démon que xinetd peut lancer pour un même client (identifié par son adresse IP). Cette option permet donc de limiter le nombre de connexions d'un client, de manière indépendante du nombre de connexions total donné par l'option instances. |
|
cps |
Permet de limiter dans le temps le nombre de connexions entrantes pour un service, afin d'éviter les attaques par déni de service. Cette option prend deux paramètres, le premier étant le nombre maximum de demandes de connexion par seconde que xinetd peut accepter. Si ce nombre est dépassé, le service est désactivé pendant le nombre de secondes indiqué par le deuxième paramètre. |
|
disabled |
Permet de désactiver globalement des services, en indiquant leurs noms en paramètre. Par défaut, aucun service n'est désactivé. Cette option ne peut être utilisée que dans la section defaults, car elle permet de désactiver globalement et rapidement un ensemble de services. |
|
enabled |
Permet de donner la liste des services pris en charge. Cette option fonctionne de manière similaire à l'option disabled, à ceci près qu'elle fonctionne en logique inverse. L'absence de cette option implique l'activation de tous les services, sauf ceux qui sont listés dans l'option disabled. En revanche, dès que cette option est définie, seuls les services listés sont démarrés. Tout comme l'option disabled, cette option ne peut être utilisée que dans la section globale defaults. |
|
disable |
Permet de désactiver les services de manière unitaire. Cette option est utilisée dans les sections des services, afin d'indiquer de manière plus fine qu'avec les options enabled et disabled s'ils doivent être activés ou non. Cette option peut prendre deux valeurs : « yes » ou « no ». La première permet de désactiver le service et la deuxième de le garder fonctionnel. Notez que les options enabled et disabled ont priorité l'option disable. Ainsi, un service désactivé par l'une de ces options ne peut pas être réactivé en attribuant la valeur no à l'option disable. |
|
log_type |
Méthode d'enregistrement des événements du démon xinetd. Il est possible d'utiliser le démon syslog pour enregistrer les événements de connexion et de déconnexion des utilisateurs, ou directement un fichier texte. Dans le premier cas, il faut utiliser la valeur SYSLOG suivie de la classe d'enregistrement (généralement daemon) et du niveau de trace (généralement info). Dans le deuxième cas, il faut spécifier la valeur FILE et indiquer les limites basse et haute de la taille du fichier au-delà desquelles un avertissement est généré, puis les traces sont arrêtées. |
|
log_on_success |
Informations enregistrées lors de l'acceptation d'une connexion. xinetd peut enregistrer différentes informations lorsqu'une nouvelle connexion est acceptée. Ces informations sont indiquées grâce à la liste des mots-clés spécifiés par cette option. Les mots-clés utilisables sont « PID », pour enregistrer l'identifiant de processus du démon qui traitera la requête, « HOST », pour enregistrer le nom de la machine cliente, « USERID », pour enregistrer le nom de l'utilisateur (si celui-ci peut être obtenu par le service d'identification de sa machine), « EXIT », pour enregistrer la terminaison du démon qui traite la requête, et « DURATION », pour enregistrer la durée de la connexion. |
|
log_on_failure |
Informations enregistrées lors d'un refus de connexion. Les informations enregistrées lors d'un refus de connexion peuvent être spécifiées à l'aide de cette option, de la même manière que les informations de connexion peuvent être enregistrées à l'aide de l'option log_on_success. Les mots-clés utilisables avec cette option sont « ATTEMPT », pour signaler simplement que la tentative a échoué, « HOST », pour enregistrer le nom de la machine depuis laquelle la tentative a été effectuée, et « USERID », pour enregistrer le nom de l'utilisateur tel qu'indiqué par le service d'identification de sa machine. |
Toutes les options disponibles ne sont pas décrites dans le tableau précédent. Vous pourrez obtenir de plus amples renseignements en consultant la page de manuel xinetd.conf.
La section « defaults » permet de définir les options par défaut applicables à tous les services. Les options qui y sont définies peuvent toutefois être redéfinies ou précisées à l'aide des opérateurs =, += et -= dans les sections des différents services. Les options utilisables dans la section defaults et que l'on a vu ci-dessus sont les options bind, log_type, log_on_success, log_on_failure, instances, per_source, only_from, no_access, disabled et enabled.
Généralement, le fichier /etc/xinetd.conf ne contient que la section default et une ligne d'inclusion du répertoire /etc/xinetd.d/, dans lequel se trouvent les fichiers de configuration des différents services. L'exemple suivant présente donc un fichier xinetd.conf typique :
# Définition des options par défaut :
defaults
{
# On interdit la connexion à tout le monde par défaut :
only_from =
# On désactive les services internes :
disabled = echo time daytime chargen discard
# On désactive les services d'administration de xinetd :
disabled += servers services xadmin
# On limite le nombre d'instances total des services :
instances = 15
# On définit les règles de suivi des connexions :
log_type = FILE /var/log/servicelog
log_on_success = HOST PID USERID DURATION EXIT
log_on_failure = HOST USERID RECORD
}
# Inclusion des fichiers de configuration des services :
includedir /etc/xinetd.dL'exemple suivant présente la définition du service telnet située dans le fichier de configuration /etc/xinetd.d/telnet :
service telnet
{
socket_type = stream
# Le numéro de port et le protocole utilisés peuvent être omis
#, car ils sont déjà définis dans /etc/services.
server = /usr/sbin/in.telnetd
user = root
wait = no
only_from = localhost
disable = no
}Note : xinetd n'inclue pas les fichiers contenant un point (caractère '.') ni ceux finissant par un tilde (caractère '~'). En particulier, on évitera de mettre une extension aux fichiers de configuration des services, puisque dans ce cas ils contiendraient un point et ne seraient pas lus.
IX-C. Configuration de la connexion à Internet▲
Les connexions à Internet font partie des connexions réseau temporaires permettant de relier deux machines. La machine locale se connecte en effet au serveur du fournisseur d'accès à Internet via la ligne téléphonique. Bien entendu, ce serveur est considéré comme la passerelle par défaut pour tous les paquets à destination d'Internet. Ce type de connexion a de particulier que les adresses IP des deux machines sont, en général, déterminées dynamiquement, lors de l'établissement de la connexion. La configuration réseau des connexions à Internet se fait donc légèrement différemment de la configuration d'un réseau local normal. Heureusement, tous les détails de la configuration réseau sont pris en charge automatiquement.
IX-C-1. Le protocole PPP▲
Les connexions à Internet utilisent le protocole PPP (abréviation de l'anglais « Point to Point Protocol »), qui permet à deux ordinateurs d'échanger des paquets TCP/IP au travers d'un canal de communication simple (donc, en particulier, au travers d'une ligne téléphonique en utilisant un modem). Ce protocole est géré par le noyau et par le démon pppd. Il permet d'effectuer la négociation initiale entre les deux machines, ce qui comprend notamment l'identification, l'authentification et l'attribution des adresses IP.
Le démon pppd ne gère pas le modem directement, car il est supposé être utilisable sur d'autres types de lignes que les lignes téléphoniques. La gestion du modem est donc relayée à un autre programme, qui se nomme chat (il tient son nom du fait qu'il permet de dialoguer directement avec le modem). Le programme chat ne connaît pas les différents types de modems qui existent sur le marché, il se contente d'exécuter des scripts qui décrivent les informations à envoyer au modem et les réponses attendues en retour. Cela permet de reporter la configuration spécifique aux modems dans des scripts de connexion. L'écriture de ces scripts nécessite bien entendu de connaître les commandes que votre modem est capable de comprendre. Notez également qu'il est indispensable ici que votre modem soit un vrai modem (qu'il soit interne ou externe), et non pas un modem logiciel (ces modems sont des modèles bas de gamme qui nécessitent un support logiciel pour interpréter les informations analogiques reçues sur la ligne téléphonique). Renseignez-vous donc bien sur la nature du modem que vous achetez, si vous voulez ne pas avoir de problèmes sous Linux…
La séquence des opérations lors d'une connexion est donc l'initialisation du modem et l'établissement de l'appel téléphonique par le programme chat, puis le démarrage du démon pppd. Celui-ci effectue la connexion sur le serveur du fournisseur d'accès et détermine l'adresse IP, les adresses des DNS, la passerelle et la route à utiliser pour cette connexion. Une fois cela réalisé, toutes les fonctionnalités réseau peuvent être utilisées via Internet, et votre ordinateur fait alors partie du réseau mondial.
L'identification et l'authentification peuvent se faire de différentes manières selon le fournisseur d'accès à Internet utilisé. Un certain nombre de fournisseurs exige l'authentification lors de l'appel téléphonique, avec un mécanisme de login classique. Pour ces fournisseurs, l'authentification est faite par le programme chat, auquel il faut communiquer le nom d'utilisateur et le mot de passe. D'autres fournisseurs utilisent un protocole d'authentification spécifique. Pour ceux-ci, l'authentification est réalisée directement par le démon pppd, une fois que la ligne a été établie. Les deux principaux protocoles d'authentification sont PAP (abréviation de l'anglais « Password Authentification Protocol ») et CHAP (abréviation de « Challenge Handshake Authentification Protocol »). PAP réalise l'authentification comme le mécanisme de login classique : le client envoie son nom et le mot de passe correspondant en clair au serveur. CHAP utilise en revanche la notion de défi. Le serveur envoie une requête contenant son nom, et le client doit s'identifier et authentifier son identité en lui renvoyant une réponse contenant son propre nom et une valeur calculée à partir du mot de passe correspondant. Les deux méthodes seront présentées ci-dessous. Si vous ne parvenez pas à vous connecter à Internet avec la première de ces méthodes, tentez votre chance avec PAP ou CHAP. Sachez que pour utiliser ces protocoles il est nécessaire de connaître, en plus de votre login et de votre mot de passe, le nom du serveur utilisé. Cette information doit vous être communiquée par votre fournisseur d'accès à Internet. Si vous avez le choix, utilisez de préférence le protocole CHAP, car il n'envoie jamais de mot de passe en clair sur la ligne téléphonique.
La configuration de l'accès à Internet pour un fournisseur d'accès requiert donc la configuration du réseau, la configuration de ppp, la configuration de chat et l'écriture des scripts de connexion. Ces étapes seront détaillées ci-dessous. Nous supposerons dans la suite que vos paramètres de connexion sont les suivants :
|
Paramètre |
Valeur |
|
Fournisseur d'accès Internet |
www.monfai.fr |
|
Nom de domaine |
monfai.fr |
|
Adresse du DNS |
192.205.43.1 |
|
Numéro de téléphone |
08 36 76 30 18 |
|
Nom de login |
jdupont |
|
Mot de passe |
gh25k;f |
|
Nom de serveur (pour PAP et CHAP) |
serveurfai |
Note : Les informations données dans le tableau ci-dessus sont fictives et ne servent qu'à donner un exemple. Vous devez bien entendu les remplacer par les valeurs vous concernant en chaque endroit où elles apparaissent dans la suite de ce document. Si par hasard une de ces informations correspondait à un numéro de téléphone, un nom ou une adresse IP valide, ce serait une pure coïncidence.
Certains fournisseurs d'accès refuseront de vous donner toutes ces informations, sous prétexte qu'ils vous fournissent un kit de connexion pour Windows. Ce n'est pas trop grave, car il est possible de leur extorquer ces informations malgré eux. Les seules informations réellement indispensables sont le numéro de téléphone, le nom de login, le mot de passe et le nom de domaine. Les adresses de DNS peuvent être déterminées automatiquement dans le cadre du protocole PPP, et le nom de serveur est arbitraire et ne sert qu'à identifier la connexion.
IX-C-2. Création d'une connexion à Internet▲
La première étape dans la création d'une connexion à Internet est avant tout l'ajout des serveurs DNS du fournisseur d'accès à votre configuration réseau. Cela n'est pas toujours nécessaire, car il est possible de configurer le démon pppd pour qu'il demande au fournisseur d'accès les adresses IP des DNS de celui-ci lors de l'établissement de la connexion. Cependant, il est plus facile d'utiliser le mécanisme de connexion à la demande si l'on indique les adresses des DNS du fournisseur d'accès dans la configuration réseau.
Pour l'exemple de connexion utilisé ici, vous devez simplement ajouter les lignes suivantes dans le fichier /etc/resolv.conf :
search monfai.fr
nameserver 192.205.43.1Si vous ne connaissez pas les adresses de DNS de votre fournisseur d'accès, vous pourrez l'obtenir en regardant dans les traces du noyau lors de l'établissement d'une connexion. Nous verrons cela en détail plus loin.
La deuxième étape est d'écrire un script de numérotation pour le programme chat. Ce script pourra être placé dans le répertoire /etc/ppp/peers/, et pourra être nommé monfai.chat par exemple. Son contenu sera le suivant :
REPORT CONNECT
ABORT ERROR
ABORT BUSY
ABORT VOICE
ABORT "NO CARRIER"
ABORT "NO DIALTONE"
"" ATZ
OK AT&F1
OK ATM0L0DT0836763018
CONNECT ""Ce script contient le programme que chat doit exécuter pour appeler le fournisseur d'accès à Internet. Il indique toutes les erreurs possibles susceptibles de faire échouer l'opération, puis il envoie les commandes d'initialisation et de numérotation au modem. Vous devrez remplacer le numéro de téléphone utilisé dans la commande DT<numéro> par le numéro de téléphone de votre fournisseur d'accès à Internet.
Note : Dans les scripts pour chat, il est possible d'utiliser indifféremment l'apostrophe simple, l'apostrophe double ou aucune apostrophe si la chaîne attendue de la part du modem ou à lui envoyer ne contient aucun espace.
Si d'aventure ce script ne fonctionne pas, vous serez sans doute obligé de demander au programme chat d'afficher tous les messages envoyés et reçus par le modem. Cela se fait normalement avec les options -v et -s. Vous verrez alors les messages en provenance du modem, ce qui vous permettra de déterminer comment modifier ce script.
Si votre fournisseur d'accès à Internet utilise un mécanisme de login classique, vous devez faire l'identification directement dans le script chat. En général, le serveur du fournisseur d'accès envoie la demande de login dès que la connexion a été établie. Pour cela, il utilise une chaîne de caractères telle que « login: », à laquelle le script chat doit répondre par votre nom d'utilisateur. Le serveur demande alors le mot de passe avec une chaîne telle que « password: », demande à la suite de laquelle le script chat doit envoyer votre mot de passe. Ce n'est que lorsque ces deux informations auront été fournies que la connexion sera réellement établie. Vous pouvez compléter le script chat pour répondre à ces deux questions avec les deux lignes suivantes :
ogin: jdupont
ssword: gh25k;fVous devrez bien entendu remplacer le nom du login et le mot de passe par vos propres données dans ce script. Notez qu'il n'est pas nécessaire (ni recommandé) de demander la réception de la chaîne complète « login: », car une erreur de transmission sur la ligne peut encore arriver à ce stade et provoquer la perte des premiers caractères envoyés par l'ordinateur distant. De plus, il se peut que la première lettre soit en majuscule ou en minuscule, selon le fournisseur d'accès à Internet que vous utilisez. Il en va de même pour la demande de mot de passe (« password: »).
Si, en revanche, votre fournisseur d'accès utilise le mécanisme d'authentification PAP ou CHAP, vous ne devez pas ajouter ces lignes, car le serveur n'enverra pas la chaîne de caractères « login: ». Il tentera de communiquer directement avec votre démon pppd pour réaliser l'authentification. Bien entendu, les défis lancés par le serveur sont simplement constitués de la demande du login et de la demande du mot de passe correspondant à ce login. Le démon pppd utilisera alors les « secrets » stockés dans le fichier /etc/ppp/pap-secrets ou le fichier /etc/ppp/chap-secrets pour répondre à ces défis, selon que le protocole utilisé par le serveur du fournisseur d'accès est PAP ou CHAP. C'est donc dans ces fichiers que vous devrez enregistrer votre login et votre mot de passe. Le format de ces fichiers est très simple. Les deux fichiers utilisent la même syntaxe pour les secrets. Vous devez simplement y ajouter une ligne telle que celle-ci :
# Secrets for authentification using PAP/CHAP
# client server secret IP addresses
jdupont serveurfai gh25k;fpour que l'identification et l'authentification se fasse correctement. Comme on le voit, le nom du serveur est indiqué dans ce fichier : il permet de déterminer quel login et quel mot de passe doivent être utilisés pour les protocoles PAP et CHAP.
Note : En fait, le protocole PPP ne permet pas d'identifier des utilisateurs, mais des machines. Cependant, pour votre fournisseur, votre machine est identifiée par votre login, et il faut donc indiquer ce nom comme nom de machine cliente dans les fichiers pap-secrets et chap-secrets.
Le nom de serveur n'est pas utilisé pour la connexion. Il ne sert qu'à déterminer quel secret doit être utilisé pour une connexion donnée. Comme la plupart des gens n'ont qu'un seul fournisseur d'accès à Internet, ce nom est purement et simplement facultatif. Dans ce cas, on peut parfaitement remplacer le nom du serveur par une étoile. Ce caractère générique indique simplement que le même secret doit être utilisé pour toutes les connexions.
Pour les connexions à Internet, il est souvent impossible de connaître a priori l'adresse IP que le serveur donnera au client. On peut donc laisser vide la colonne contenant les adresses IP utilisables par les clients.
Lorsque vous aurez écrit le script chat et éventuellement complété les fichiers de secrets de PAP ou de CHAP, vous pourrez écrire le script de connexion à Internet. Ce script est très simple :
#!/bin/sh
# Script de connexion à Internet
# Effectue le ménage :
rm -f /var/spool/uucp/LCK* /var/lock/LCK* /var/run/ppp*.pid
# Établit la connexion :
/usr/sbin/pppd /dev/modem 115200 connect "/usr/sbin/chat -v \
-f /etc/ppp/peers/monfai.chat" defaultroute usepeerdns \
ipcp-accept-remote ipcp-accept-localPrenez garde à écrire la ligne exécutant pppd et la ligne des options en une seule ligne, sans saut de ligne. Notez que le caractère '\' placé en fin de ligne permet d'indiquer que la commande se poursuit sur la ligne suivante. Ce script commence par faire le ménage sur les fichiers éventuellement laissés par les anciennes connexions, et appelle pppd en lui demandant d'utiliser la connexion établie par le programme chat avec la vitesse maximale de connexion indiquée. Lorsque la connexion est établie, le serveur du fournisseur d'accès est enregistré comme passerelle par défaut dans la table de routage du noyau. L'envoi et la réception des paquets IP en direction de l'Internet se feront donc en passant par cette passerelle. Les adresses de DNS du fournisseur d'accès sont également récupérées et ajoutées dans le fichier /etc/ppp/resolv.conf. Vous pourrez les déterminer simplement en consultant les fichiers de log de votre distribution dans le répertoire /var/log/. Les deux dernières options permettent d'autoriser le serveur du fournisseur d'accès à fixer les adresses IP locales et distantes.
Dans ce script de connexion, le programme chat est appelé avec le script de numérotation pour chat que l'on a déjà écrit. Si l'on désire voir exactement ce qui se passe, on peut ajouter l'option -s à la commande d'exécution de chat :
/usr/sbin/chat -v -s -f /etc/ppp/peers/monfai.chatdans le script de connexion vu ci-dessus. Cela vous permettra de déboguer votre script de numérotation.
Vous remarquerez que le programme pppd utilise le fichier spécial de périphérique /dev/modem pour la communication. Il va de soi que si ce fichier spécial n'existe pas, vous devrez le créer. La solution la plus simple est de faire un lien symbolique vers /dev/ttS0 ou /dev/ttS1, selon que votre modem est connecté sur le premier ou le deuxième port série de votre ordinateur.
La commande de lancement donnée ci-dessus suppose que le script de connexion /etc/ppp/peers/monfai.chat réalise l'identification et l'authentification. Si vous utilisez l'un des protocoles PAP ou CHAP, il faut demander à pppd d'effectuer ces deux opérations lui-même. Pour cela, il faut ajouter des options dans la ligne de commande utilisée pour le lancer dans le script de connexion, afin de préciser le nom du serveur et le nom d'utilisateur pour l'identification. La ligne complète à utiliser pour PAP ou CHAP doit donc être celle-ci :
# Établit la connexion :
/usr/sbin/pppd /dev/modem 115200 connect "/usr/sbin/chat -v \
-f /etc/ppp/peers/monfai.chat" defaultroute usepeerdns \
ipcp-accept-remote ipcp-accept-local noauth \
remotename serveurfai user jdupontEncore une fois, cette commande doit être écrite sur une seule ligne, ou sur plusieurs lignes séparées par le caractère '\'. L'option noauth signale qu'il n'est pas nécessaire que le serveur du fournisseur d'accès s'authentifie en tant que tel (ce n'est pas nécessaire, car les fournisseurs d'accès ne jouent pas vraiment aux pirates du web), et les deux options suivantes permettent respectivement d'indiquer le nom de ce serveur ainsi que le nom d'utilisateur à utiliser pour le login. Lors de l'authentification, le démon pppd lira le fichier de secret du protocole choisi par le fournisseur d'accès pour trouver le mot de passe à utiliser. Notez encore une fois qu'il est facultatif de préciser le nom du serveur du fournisseur d'accès si vous avez utilisé le caractère générique '*' dans les fichiers de secrets pour PAP et CHAP.
Il est possible de faire en sorte que la connexion à Internet s'établisse automatiquement dès qu'un programme cherche à utiliser une adresse devant passer par la route par défaut. Toute demande à destination d'une machine dont l'adresse est inconnue localement provoque dans ce cas l'établissement de la connexion à Internet. Pour cela, il suffit simplement :
- d'ajouter l'option demand à la ligne de commande de pppd dans le script de connexion ;
- de lancer ce script en arrière-plan dans un des scripts de démarrage du système.
Si vous désirez utiliser cette fonctionnalité, il est recommandé d'activer également la déconnexion automatique, faute de quoi vous risqueriez de rester connecté involontairement. Cela se fait simplement en ajoutant l'option idle n dans la ligne de commande de pppd, où n est le nombre de secondes pendant lequel le lien PPP doit rester inactif avant que la connexion ne se coupe automatiquement. Un choix judicieux est par exemple 600 (ce qui correspond à dix minutes).
Note : L'interface réseau est automatiquement créée lorsqu'on lance le démon pppd avec l'option demand. Par conséquent, le démon pppd définira automatiquement une adresse IP locale pour cette interface et une adresse IP distante pour la passerelle par défaut. Malheureusement, ces adresses peuvent changer d'une connexion à une autre. En effet, la plupart des fournisseurs attribuent les adresses IP en fonction du modem qui répond au client qui appelle et, en général, la connexion ne se fait pas toujours sur le même modem (il peut y avoir plusieurs modems pour un même numéro de téléphone). C'est pour cela qu'il faut ajouter les options ipcp-accept-remote et ipcp-accept-local pour indiquer à pppd de modifier ces adresses lorsqu'il établira la connexion. Le problème, c'est que les connexions TCP/IP utilisant ces adresses seront systématiquement cassées à la suite de ce changement. C'est en particulier le cas pour le programme qui a initié l'établissement de la liaison PPP. C'est pour cette raison qu'il est recommandé de demander une adresse IP fixe à son fournisseur d'accès lorsqu'on veut utiliser la connexion à la demande. Hélas, ce service peut faire l'office d'une facturation supplémentaire.
Même si l'on utilise l'option usepeerdns dans la ligne de commande de PPP, il est recommandé de rajouter les adresses des DNS dans le fichier /etc/resolv.conf. En effet, en l'absence de DNS, les noms de domaine ne seront pas résolus et aucune requête vers l'extérieur ne se fera. Par conséquent, la route par défaut ne sera pas utilisée, et pppd n'établira donc pas la connexion automatiquement. Notez que si vous définissez les DNS dans le fichier /etc/resolv.conf, vous pouvez vous passer de l'option usepeerdns dans la ligne de commande de pppd. Si vous désirez procéder de cette manière, vous devrez vous assurer que l'ordre spécifié pour la résolution des noms dans le fichier /etc/host.conf est bien le fichier /etc/hosts (option hosts) avant le DNS (option bind), faute de quoi votre ordinateur se connectera systématiquement à Internet dès que vous utiliserez un nom de machine local.
La plupart des options passées en ligne de commande peuvent être spécifiées dans le fichier d'options /etc/ppp/options du démon pppd. Cela peut permettre de simplifier les scripts de connexion.
Si l'on n'utilise pas les mécanismes de connexion / déconnexion automatiques, on devra se déconnecter manuellement. Pour cela, rien de plus simple : il suffit de détruire le démon pppd. Cela peut être réalisé automatiquement avec le script suivant :
#!/bin/sh
# Script de terminaison de la connexion PPP
#
# Détermine la connexion à fermer (fournie sur la ligne de commande,
# ppp0 par défaut) :
if [ "$1" = "" ]; then
DEVICE=ppp0
else
DEVICE=$1
fi
# Teste si la connexion indiquée est active :
if [ -r /var/run/$DEVICE.pid ]; then
# Détruit le processus ppp correspondant (son PID est stocké
# dans /var/run/) :
kill -INT `cat /var/run/$DEVICE.pid`
# Effectue le ménage :
if [ ! "$?" = "0" ]; then
rm -f /var/run/$DEVICE.pid
echo "ERREUR: Un fichier de PID résiduel \
a dû être effacé manuellement"
exit 1
fi
rm -f /var/spool/uucp/LCK* /var/lock/LCK*
echo "La connexion PPP sur $DEVICE a été fermée correctement…"
echo
# Termine le script :
exit 0
fi
# La connexion indiquée n'est pas active :
echo "ERREUR: Il n'y a pas de connexion PPP sur $DEVICE"
exit 1IX-C-3. Connexion à l'ADSL▲
Les connexions ADSL ne requièrent pas d'appel téléphonique vers un modem du fournisseur d'accès. Elles s'établissent donc d'une manière différente, généralement bien plus simple. Toutefois, la manière de procéder dépend des fournisseurs d'accès et de la nature de votre modem ADSL. Il est donc difficile de décrire de manière générique la manière dont une connexion ADSL se met en place sous Linux. Seules les grandes lignes seront donc indiquées dans ce paragraphe.
Sachez pour commencer qu'il existe trois types de modems ADSL : les modems USB, les modems Ethernet simples, et les modems routeurs. Les premiers sont connectés à votre ordinateur via un câble USB. Les deuxièmes utilisent plutôt un câble réseau Ethernet classique. Les modems routeurs quant à eux sont des modems ADSL couplés d'un switch et, de plus en plus souvent, d'un point d'accès sans fil Wi-Fi. Ces modems sont intéressants, car ils permettent de connecter plusieurs ordinateurs à Internet via la même ligne, et ces ordinateurs peuvent être mis en réseau directement en les câblant au modem routeur à l'aide de câbles Ethernet, et via un réseau sans fil Wi-Fi pour les modems avec point d'accès.
En général, les modems USB requièrent des pilotes de périphériques spécifiques à chaque type de modem. Ce n'est pas le cas des modems Ethernet et des modems routeurs, puisqu'ils se connectent directement à votre carte Ethernet par un câble Ethernet (droit ou croisé selon votre modem). Par conséquent, si votre carte réseau est prise en charge par Linux (ce qui est fort probable), vous n'aurez absolument aucun problème pour vous connecter à Internet avec un modem Ethernet, alors que les pilotes USB pour Linux sont rarement développés avec sérieux par les fabricants de modems (ayant essuyé les plâtres avec le modem Sagem Fast800 fourni par Free à ses clients et participé au débogage de celui-ci, je suis bien placé pour le savoir). De plus, les modems USB ne permettent pas de partager la connexion Internet entre plusieurs ordinateurs, fonctionnalité très intéressante dans le cadre d'un petit réseau familial ou si vous disposez d'un ordinateur fixe et d'un portable. Enfin, les modems Ethernet sont alimentés, alors que les modems USB utilisent l'alimentation du port USB, ce qui dans 50% des cas provoque des instabilités de la connexion Internet, si ce n'est de l'ordinateur lui-même.
Il est donc vivement conseillé de choisir un modem routeur ou, à défaut, un modem Ethernet si vous en achetez un ou si votre fournisseur d'accès à Internet vous en propose. La plupart des modems évolués des offres multiples (téléphone + Internet et éventuellement TV) distribués de nos jours sont généralement des modems routeurs, et disposent souvent d'une possibilité de point d'accès Wi-Fi.
Note : Même si, comme nous le verrons plus loin, Linux est parfaitement capable de réaliser un partage de connexion à Internet, l'achat d'un routeur domestique ou, pour simplifier l'installation, d'un modem routeur prenant tout en charge, reste intéressant. En effet, ces appareils, prenant totalement en charge la connexion à Internet, rendent la configuration de l'accès à Internet triviale au niveau de l'ordinateur. De plus, ils peuvent fournir des services complémentaires, tels que la configuration dynamique des ordinateurs clients par le protocole DHCP, ou encore le relai de serveur de nom avec un mini serveur DNS, accélérant ainsi de manière non négligeable le temps de réponse lors de la navigation.
De plus, et c'est sans doute l'un des plus gros avantages, les modems routeurs peuvent jouer le rôle d'un pare-feu « naturel » dès lors que la fonction de partage de connexion à Internet est activée. En effet, même si un seul ordinateur est connecté au modem routeur, celui-ci doit utiliser un jeu d'adresses IP privées pour votre réseau local, car votre fournisseur ne vous attribuera qu'une seule adresse IP lors de la connexion. Or, les adresses privées utilisées de ce type ne sont pas, par définition, routables sur Internet. Par conséquent, du point de vue d'Internet, seul le modem routeur est visible : aucun de vos ordinateurs n'est accessible ! Il est donc quasiment impossible à un pirate et encore moins à un virus de passer au travers de cet appareil, sauf à le pirater en premier lieu. Dans tous les cas, cela complique sérieusement les choses, et le type de protection fourni par ces appareils est donc extrêmement fiable. Ne serait-ce que pour cet aspect des choses, je vous recommande vivement l'utilisation de ce type d'appareil (surtout si vous avez un ordinateur qui fonctionne sous Windows).
Même si vous utilisez un modem USB, il apparaîtra généralement comme une interface Ethernet dans le système. L'installation des pilotes pour les modems USB étant extrêmement spécifique, cette étape ne sera pas décrite plus en avant ici. La suite du document suppose donc que vous disposiez d'un modem Ethernet, ou que votre modem soit accessible par l'intermédiaire d'une interface Ethernet simulée par le pilote du modem.
Lorsque vous aurez branché votre modem et que vous pourrez y accéder via son interface Ethernet, vous devrez établir la connexion avec votre fournisseur d'accès. Cela dépend encore une fois du fournisseur d'accès, et parfois même, pour un même fournisseur, de la région dans laquelle vous vous trouvez. Généralement, deux méthodes sont utilisées pour établir la connexion :
- soit les communications se font de manière totalement transparente via l'interface Ethernet du modem, auquel cas la connexion s'établit aussi facilement que si vous vous connectiez à un réseau Ethernet classique ;
- soit les communications sont encapsulées dans le protocole de communication PPP, via un protocole du type PPPoE (« PPP over Ethernet ») ou PPPoA (« PPP over ATM »), auquel cas vous devrez utiliser le démon pppd pour établir la connexion.
Dans le premier cas, la configuration est simpliste. Il suffit d'utiliser l'interface Ethernet du modem comme interface de sortie dans la route par défaut, et éventuellement de mettre un client DHCP à l'écoute sur cette interface si le fournisseur d'accès utilise ce protocole pour attribuer les adresses IP de ses clients. La manière de procéder est décrite dans la section traitant de DHCP. Cette technique est celle utilisée par le fournisseur d'accès Free en France en zone dégroupée. Pour ce fournisseur, les adresses IP fournies étant fixes en zone dégroupée, la connexion à Internet se résume donc aux deux commandes suivantes :
ifconfig eth0 adresse up
route add default eth0où adresse est l'adresse IP que votre fournisseur d'accès vous a attribuée. La connexion à Internet se fait donc dans ce cas comme la configuration d'une simple carte réseau.
Dans le deuxième cas, le plus simple est d'utiliser le protocole d'encapsulation PPPoE. Comme son nom l'indique, ce protocole permet d'encapsuler les paquets de la liaison PPP avec votre fournisseur Ethernet directement dans des trames Ethernet, qui peuvent ensuite être envoyées via l'interface Ethernet du modem. Cette solution peut être mise en place avec l'outil rp-pppoe de la société Roaring Penguin, ou directement avec un gestionnaire PPPoE au niveau du noyau.
La mise en place d'une connexion avec rp-pppoe est réellement très simple. En effet, un fichier d'options pour PPP nommé pppoe.conf et des scripts de connexion et déconnexion adsl-start et adsl-stop, permettant de lancer le démon pppd avec les bonnes options et dans le bon contexte pour établir la connexion, sont fournis. Les seules opérations à faire sont dans ce cas de s'assurer que les identifiants de connexion (login et mot de passe) fournis par votre fournisseur d'accès sont bien enregistrés dans les fichiers pap-secrets et chap-secrets, et que le fichier pppoe.conf y fait bien référence (au niveau de l'option USER). La manière de procéder ayant déjà été décrite ci-dessus, elle ne sera pas détaillée outre mesure.
L'utilisation du gestionnaire PPPoE du noyau est encore plus directe, car il suffit dans ce cas de lancer le démon pppd en lui demandant de travailler avec l'interface réseau du modem. Pour utiliser ce gestionnaire, vous devez activer, outre le support de PPP, l'option « PPP over Ethernet (EXPERIMENTAL) » dans les options de configuration du noyau. Une fois les identifiants de connexion écrits dans les fichiers pap-secrets ou chap-secrets, la connexion à Internet se fera simplement avec la commande suivante :
pppd interfaceoù interface est le nom de l'interface réseau du modem.
Note : Il est recommandé de limiter la taille des paquets en réception et en émission à 1492 octets, afin de prendre en compte les frais dus à l'encapsulation PPPoE. Pour cela, il suffit de placer les options suivantes dans le fichier d'options de pppd :
mtu 1492
mru 1492Il est impératif de mettre en place un pare-feu si vous disposez d'une connexion ADSL. La manière de procéder est décrite dans la Section 9.4.
IX-C-4. Les autres outils de connexion▲
Vous en savez suffisamment à présent pour vous connecter à Internet avec Linux. Les opérations qui ont été décrites ici sont légèrement compliquées, et vous les trouvez sans doute un peu lourdes. Cela est naturel, car elles le sont effectivement. En fait, les opérations décrites ici vous montrent comment vous connecter manuellement, mais elles ne constituent pas la manière de faire la plus facile. En effet, si vous installez XWindow, vous pourrez utiliser des programmes graphiques permettant de vous connecter à Internet, d'envoyer et recevoir des courriers électroniques (« mails »), de naviguer (« surfer ») et de lire les groupes de discussions (« news »). Cependant, l'utilisation de ces outils ne sera pas décrite ici, car il en existe trop pour que l'on puisse tous les présenter. Heureusement, ces outils sont prévus pour être très simples d'emploi et leur configuration ne pose réellement aucun problème.
IX-C-5. Configuration d'un cache de DNS▲
La résolution des noms de domaines est une opération dont le coût est loin d'être négligeable au niveau du temps de connexion aux serveurs, si ce n'est au niveau de la bande passante utilisée. En effet, il est relativement courant qu'une page Web fasse de multiples références à des machines inconnues et dont les adresses doivent être résolues. De ce fait, la résolution des noms de domaines peut parfois se mesurer en secondes, surtout si les serveurs de noms des fournisseurs d'accès sont surchargés, ce qui arrive très couramment, même pour les clients des offres ADSL à 20 Mbits/s.
De plus, il est courant qu'un internaute reste toujours sur le même site pendant qu'il navigue sur Internet. Il peut donc être très intéressant de disposer d'un cache local pour les requêtes DNS. Un tel cache permet de mémoriser les interrogations faites par les programmes clients (essentiellement les navigateurs Web) et surtout les réponses renvoyées par le serveur de nom du fournisseur d'accès. Ainsi, lorsqu'un client effectue une requête sur un nom de domaine pour lequel il a déjà fait une requête auparavant (par exemple lors de l'accès à la page précédente), la réponse de cette requête set accessible immédiatement, puisqu'elle se trouve dans le cache local. Ce mécanisme permet donc de réduire sensiblement les temps de connexions aux machines situées sur Internet : seule la première connexion prend le temps habituel, et toutes les autres sont accélérées.
Note : Les mécanismes de « caches » sont très souvent utilisés en informatique pour permettre d'obtenir rapidement des informations habituellement difficiles à obtenir, mais qui varient très peu. Du fait de leur quasi-constance, il est en effet possible de les copier dans une mémoire locale. Par exemple, les caches sont utilisés au niveau des disques durs, dans les processeurs pour accéder aux données en mémoire, et au niveau du réseau. Ils permettent d'augmenter considérablement les performances, au détriment d'une plus grande complexité des opérations d'écriture des données, puisque celles-ci invalident les données des caches et doivent forcer leur mise à jour.
En pratique, la mise en place d'un cache de DNS consiste à installer un petit serveur de nom local sur la machine, qui répond à toutes les requêtes des applications clientes. Ce petit serveur est lui-même client des serveurs de noms effectifs qui se trouvent sur Internet. L'idéal est dans ce cas simplement de s'adresser aux serveurs de noms du fournisseur d'accès à Internet, afin de bénéficier de son propre cache et de sa bande passante pour les requêtes intermédiaires. C'est exactement ce que se propose de faire le programme DNSmasq.
La configuration de DNSmasq se fait essentiellement au niveau du fichier de configuration /etc/dnsmasq.conf. Ce fichier est constitué d'une série d'options auxquelles une valeur est affectée, les lignes commençant par un signe dièse étant des commentaires. Le fichier suivant peut vous servir d'exemple, sachant que les options sont toutes commentées dans le fichier fourni par défaut :
# Exemple de fichier de cache de DNS :
# Fichier de définition des serveurs de noms en amont :
# Si on utilise ppp pour se connecter :
#resolv-file=/etc/ppp/resolv.conf
# Si on utilise DHCP directement :
resolv-file=/var/dhcp/resolv.conf
# Adresses des serveurs utilisés par les sociétés et les fournisseurs d'accès
# tordus qui ont mis en place une entrée par défaut pour capter toutes les requêtes
# sur les noms de domaines incorrects et qui redirigent leurs clients vers des sites
# publicitaire au lieu de renvoyer une erreur comme la nétiquette l'impose :
# Verisign (ils se sont calmés récemment) :
bogus-nxdomain=64.94.110.11
# Mon fournisseur débile :
# bogus-nxdomain=adresse.du.site.publicitaireCe fichier d'exemple ne montre que les options réellement nécessaires. L'option resolv-file permet d'indiquer au démon dnsmasq où trouver les adresses des serveurs DNS amont (c'est-à-dire ceux du fournisseur d'accès en pratique). Il faut indiquer ici un fichier qui contient les lignes nameserver donnant les adresses de ces serveurs. Comme nous allons le voir ci-dessus, il ne faut pas spécifier ici le fichier /etc/resolv.conf du système, car nous allons le modifier. Au contraire, il faut indiquer un fichier dans lequel les outils de connexion réseau (client DHCP ou démon pppd par exemple) enregistrent les adresses des serveurs de noms du fournisseur d'accès.
Par exemple, lorsqu'une connexion est établie avec le démon ppp, celui-ci enregistre les serveurs DNS primaires et secondaires du fournisseur d'accès dans le fichier /etc/ppp/resolv.conf. Il suffit donc de référencer ce fichier dans l'option resolv-file.
En revanche, si la connexion s'établit directement grâce au protocole DHCP, il faut configurer le client DHCP du système pour qu'il enregistre les adresses des serveurs DNS dans un fichier autre que le fichier /etc/resolv.conf du système. Ici, nous utilisons le fichier /var/dhcp/resolv.conf. Par exemple, si votre distribution utilise le client DHCP dhcpcd, il suffit de lui ajouter l'option -e /var/dhcp pour que ce fichier soit créé dans le répertoire /var/dhcp/ au lieu du répertoire /etc/.
L'option bogus-nxdomain est un palliatif à une tentative de détournement des requêtes DNS que certaines sociétés effectuent pour obtenir un profit publicitaire direct ou des statistiques comportementales sur les internautes. Ces sociétés redirigent en effet toutes les requêtes mal formées ou mal orthographiées vers un de leur serveur Web, ce qui leur permet d'obtenir des informations sur les sites accédés, d'afficher une page de publicité, ou encore faire une redirection directe vers un site supposé intéresser l'internaute.
Bien entendu, ce comportement est pour le moins cavalier, car l'internaute ne comprend pas forcément pourquoi il tombe sur un site inconnu alors qu'il demandait l'adresse d'un autre site. D'autre part, ces redirections perturbent le bon fonctionnement de certains outils qui s'attendent explicitement à trouver une erreur en cas d'échec de résolution de nom.
Il n'y a malheureusement pas grand-chose à faire pour faire revenir à la raison ces sociétés (à part porter plainte, passer à la concurrence, ou plus méchamment bombarder leurs serveurs DNS de requêtes invalides avec un programme, ce que je vous déconseille de faire vivement…). En revanche, dnsmasq peut détecter ces redirections et générer une erreur de résolution de nom classique. Pour cela, il suffit d'identifier l'adresse IP du serveur cible de la redirection, et de l'indiquer à dnsmasq à l'aide de l'option bogus-nxdomain. Ainsi, lorsque dnsmasq reçoit une réponse référençant ces serveurs, il renvoie directement une erreur aux programmes clients.
Une fois que vous aurez configuré et lancé le démon dnsmasq, vous devrez encore indiquer au système qu'il devra interroger ce démon pour effectuer les résolutions des noms de domaines. Comme il l'a déjà été indiqué dans les sections précédentes, cela se fait simplement en ajoutant une ligne nameserver référençant la machine locale dans le fichier de configuration /etc/resolv.conf :
nameserver 127.0.0.1Note : Le démon dnsmasq ne permet de cacher que les résultats des requêtes DNS. Or, de nombreux fichiers qui ne changent quasiment jamais, comme les images de fond, les logos et les pages statiques, sont récupérés de multiples fois lorsqu'un internaute navigue sur des pages Web. Il est donc très intéressant de mettre également ces fichiers en cache. Nous verrons comment réaliser cela dans la section suivante.
IX-C-6. Installation d'un proxy HTTP▲
Lors d'une connexion à Internet, bon nombre d'informations sont échangées entre le serveur et le client. En particulier, lorsqu'on navigue, un certain nombre d'images et d'informations plus ou moins lentes à télécharger transitent systématiquement. Or la plupart des gens visitent régulièrement les mêmes sites, dont seulement quelques pages sont modifiées entre deux visites successives. Par conséquent, on peut se demander pourquoi les pages complètes devraient être rechargées à chaque visite, si seulement quelques informations ont été modifiées.
Cette question prend encore plus de sens lorsqu'on réalise un partage de connexion à Internet. Il est tout à fait concevable que plusieurs clients du même réseau demandent plusieurs fois les mêmes informations, ce qui provoque l'engorgement du lien partagé inutilement. C'est pour résoudre ce genre de problème que les programmes que l'on nomme « proxies » ont été développés.
Un proxy n'est rien d'autre qu'un programme qui s'intercale entre des clients et un serveur. Il a pour principale fonction de mémoriser les réponses les plus courantes renvoyées par le serveur, afin de répondre à la fois plus rapidement aux clients et d'éviter de surcharger le serveur. Il existe différents types de proxy, mais nous allons nous intéresser uniquement aux proxies Web, qui permettent donc de stocker des pages Web en local afin de soulager une liaison trop faible.
Le principe de fonctionnement d'un proxy est le suivant. Les navigateurs utilisés par les clients se connectent, en temps normal, directement sur le port 80 des serveurs Web. Leur configuration doit être modifiée pour utiliser le proxy à la place. De leur point de vue, le proxy se comporte comme un serveur Web capable de répondre aux requêtes des clients. Lorsqu'il peut le faire, il renvoie les données qu'il a stockées dans son cache. Sinon, il va les chercher directement sur Internet à la place du client. Le cache est maintenu de telle manière que les données obsolètes ou les données les moins utilisées sont supprimées, afin de laisser la place aux données qui sont le plus souvent demandées et qui changent le moins. Pour utiliser un proxy, il faut donc modifier la configuration des navigateurs des clients, afin de donner l'adresse de la machine sur laquelle le proxy fonctionne, ainsi que le port sur lequel il peut être contacté (généralement, c'est le port 8080).
Note : Il est également possible d'utiliser les mécanismes de translation d'adresse du noyau pour rendre l'utilisation du proxy transparente aux clients. La manière de procéder sera décrite dans la section traitant des mécanismes de filtrage du noyau.
Il existe plusieurs proxies sur le marché, mais le plus utilisé sous Linux est sans doute squid. C'est un logiciel performant, puissant et libre, fourni avec la plupart des distributions modernes. Sa configuration peut être relativement technique, mais nous n'allons pas entrer dans tous les détails. Il s'agit simplement ici de donner un aperçu des fonctionnalités disponibles.
squid utilise le fichier de configuration /etc/squid.conf pour lire ses options de fonctionnement. Ce fichier contient en particulier les informations concernant le réseau, une liste de règles indiquant qui a le droit de lui demander des pages Web, et l'emplacement du cache dans lequel les données du cache seront enregistrées.
L'option la plus importante dans ce fichier de configuration est sans doute cache_dir, qui indique l'emplacement du cache ainsi que sa taille et sa structure. La syntaxe de cette option est la suivante :
cache_dir répertoire taille n moù répertoire est le répertoire dans lequel le cache sera stocké (usuellement /var/squid/cache/), taille est la taille de ce cache en mégaoctets, et n et m deux nombres donnant la structure de l'arborescence du cache. La signification de ces deux nombres doit être expliquée un peu plus en détail.
Par défaut, squid essaie de répartir tous les objets qu'il place dans le cache de manière uniforme dans plusieurs répertoires, afin d'accélérer les temps de recherche sur ces objets lorsqu'un client les demande. Il utilise à cette fin une fonction de répartition (les programmeurs disent souvent une fonction de hash) qui indique dans quel répertoire se trouve un objet. La recherche dans ce répertoire se fait donc plus rapidement, car, si la fonction de répartition est bien faite (et c'est le cas), les objets sont répartis de manière équilibrée dans tous les répertoires du cache, qui sont donc tous relativement peu peuplés. En fait, squid peut stocker tellement d'objets que le nombre de répertoires peut lui-même devenir très grand. Il utilise donc un découpage à deux niveaux, les répertoires du deuxième niveau étant répartis dans les répertoires du premier niveau. Le premier nombre spécifié dans l'option cache_dir indique le nombre de répertoires du premier niveau, et le deuxième nombre indique le nombre de sous-répertoires dans chacun de ces répertoires. En général, on utilise respectivement les valeurs 16 et 256 :
cache_dir /var/squid/cache 100 16 256Cette ligne permet de cacher 100 Mo, en répartissant les objets dans 4096 répertoires répartis en 16 groupes de 256 répertoires.
Les options suivantes spécifient les paramètres réseau du cache :
- l'option http_port indique le port TCP que les clients doivent utiliser pour accéder au proxy ;
- l'option ftp_user permet de donner l'adresse email à utiliser comme mot de passe dans les connexions FTP anonymes ;
-
l'option cache_peer permet d'intégrer le proxy local dans une hiérarchie de proxies.
Les proxies peuvent en effet être organisés dans une structure arborescente. Lorsqu'un proxy d'un niveau ne dispose pas d'une donnée demandée par un client, il peut contacter ses frères pour le cas où ceux-ci auraient cette donnée dans leurs caches, ou demander à son proxy père de récupérer cette donnée pour lui. Les proxies communiquent entre eux en utilisant un protocole dédié, le protocole ICP (abréviation de l'anglais « Inter Cache Protocol »).
En général, les petits réseaux ne disposent que d'un seul proxy, l'option cache_peer est donc souvent utilisée de la manière suivante :Sélectionnezcache_peer père parent port port_icp options -
L'option prefer_direct permet d'indiquer au proxy s'il doit chercher avant tout à récupérer lui-même les données qui lui manquent (valeur on) ou s'il doit contacter d'abord son proxy père (valeur off). Si l'on a spécifié un proxy père à l'aide de l'option cache_peer, on aura intérêt à utiliser la valeur off ;
- L'option dns_children permet de donner le nombre de processus en charge de cacher les requêtes sur les DNS. squid peut en effet lancer des serveurs de cache de DNS permettant d'optimiser les temps d'accès aux pages Web. Plus le réseau local est important, plus il faudra de tels processus, afin que tous les clients puissent obtenir les adresses IP des machines à partir de leur nom. La valeur par défaut est de 5 processus, ce qui devrait convenir dans la plupart des cas.
Les valeurs données par défaut à toutes ces options conviennent dans la plupart des cas. Elles sont parfaitement documentées dans le fichier de configuration squid.conf.
Par défaut, squid n'autorise personne à accéder au cache. Il est donc nécessaire de donner les droits nécessaires pour permettre aux machines de votre réseau d'accéder au cache. La gestion de la sécurité se fait par l'intermédiaire de ce que l'on appelle des ACL (abréviation de l'anglais « Access Control List »).
Une ACL est simplement un critère permettant de classifier les requêtes que le proxy reçoit. Ces critères sont définis à l'aide du mot clé acl, suivi du nom de la liste, suivi lui-même d'un critère que toutes les requêtes concernées par cette ACL devront vérifier. Les critères sont eux-mêmes exprimés à l'aide d'un mot clé qui indique sur quoi porte le critère et des options de ce critère. Les principaux mots clés que vous pourrez utiliser sont les suivants :
- src, qui permet de filtrer les requêtes par les adresses des machines qui les ont émises, en indiquant l'adresse de leur réseau, donnée sous la forme adresse/masque ;
- dst, qui permet de filtrer les requêtes par leurs adresses destination ;
- port, qui permet de sélectionner les requêtes s'adressant sur les ports fournis en paramètres ;
- proto, qui permet de spécifier la liste des protocoles utilisés par les requêtes ;
- method, qui permet de sélectionner les requêtes HTTP par la méthode utilisée dans la requête.
Ce tableau n'est pas exhaustif, mais il permet d'avoir une idée des capacités de filtrage des requêtes dont dispose squid. Vous trouverez ci-dessous quelques exemples pratiques de définitions d'ACL :
# ACL caractérisant toutes les machines :
acl all src 0.0.0.0/0.0.0.0
# ACL définissant la machine locale :
acl localhost src 127.0.0.1/255.255.255.255
# ACL définissant les machines d'un réseau privé local :
acl localnet src 192.168.0.0/255.255.255.0
# ACL caractérisant le proxy lui-même :
acl manager proto cache_object
# ACL spécifiant les ports acceptés par le proxy :
acl safe_ports port 80 21 443 563 70 210 1025-65535
# ACL définissant les requêtes de connexion :
acl connect method CONNECTLa définition des règles de sécurité utilise les ACL de manière séquentielle. Les règles doivent être données les unes après les autres, suivant le format suivant :
ressource politique ACLoù ressource est un mot clé indiquant la ressource sur laquelle la règle de sécurité porte, politique est l'action prise pour les requêtes vérifiant cette règle, et ACL une liste d'ACL permettant de spécifier les requêtes concernées par cette règle. La ressource la plus utilisée est sans doute le protocole HTTP, que l'on peut spécifier à l'aide du mot clé http_access. Les actions peuvent être l'acceptation (mot clé allow) ou le refus (mot clé deny) de la requête. Enfin, les requêtes concernées par une règle sont celles qui appartiennent à toutes les ACL de la liste d'ACL indiquée.
Vous trouverez ci-dessous quelques exemples de règles de sécurité courantes :
# Autorise les accès au gestionnaire de cache local :
http_access allow manager localhost
# Interdit les accès aux gestionnaires de cache étrangers :
http_access deny manager
# Interdit les accès pour toutes les requêtes provenant de ports non autorisés :
http_access deny !safe_ports
http_access deny connect !safe_ports
# Autorise les accès aux clients de la machine locale :
http_access allow localhost
# Autorise les accès aux machines du réseau local :
http_access allow localnet
# Politique par défaut :
http_access deny allNotez que si une requête ne correspond à aucune règle, la politique par défaut utilisée par squid est de prendre l'action opposée à la dernière règle spécifiée. En pratique, il est plus sage de toujours indiquer une politique par défaut pour toutes les requêtes restantes, par exemple en utilisant l'ACL all définie ci-dessus.
L'exemple de jeu de règles de sécurité donné ci-dessous convient pour un réseau local d'adresses 192.168.0.0. Vous pouvez bien entendu modifier les options de sécurité comme bon vous semble. Encore une fois, rappelons que le fichier de configuration de squid est très bien documenté et que sa lecture est relativement facile. Je ne saurais que trop vous recommander de le consulter si vous désirez en savoir plus.
IX-D. Pare-feu et partages de connexion à Internet▲
Supposons qu'une machine située sur un réseau local ait accès à Internet. Il peut être intéressant de faire en sorte que les autres machines du réseau puissent également y accéder, en utilisant cette machine comme passerelle. Cela est parfaitement réalisable et ne pose aucun autre problème que la définition des règles de routage si toutes les machines ont une adresse IP attribuée par l'IANA. Cependant, cela est rarement le cas, car les réseaux locaux utilisent normalement les adresses réservées à cet usage, qui ne sont pas routables sur Internet. Dans ce cas, il est évident que les machines du réseau local ne pourront pas envoyer de paquets sur Internet, et qu'a fortiori elles ne recevront jamais de paquets provenant d'Internet. Heureusement, il existe une technique nommée masquerading, basée sur un mécanisme de translation d'adresse (« NAT » en anglais, abréviation de « Network Address Translation »), qui permet de modifier les paquets émis à destination d'Internet à la volée afin de pouvoir partager une connexion Internet même avec des ordinateurs qui utilisent des adresses locales. Comme nous allons le voir, partager une connexion à Internet avec d'autres ordinateurs d'un réseau local est un jeu d'enfant sous Linux grâce à cette technique.
Il faut toutefois bien se rendre compte que le fait de fournir un accès à Internet à un réseau local pose des problèmes de sécurité majeurs. Pour des réseaux locaux familiaux, les risques de piratages sont bien entendu mineurs, mais lorsque la connexion à Internet est permanente ou lorsque les données circulant sur le réseau local sont sensibles, il faut tenir compte des risques d'intrusion. Lorsqu'on utilise des adresses IP dynamiques, il est relativement difficile d'accéder à des machines du réseau local, sauf si la passerelle expose des services internes au reste du réseau. En revanche, si les adresses utilisées sont fixes et valides sur Internet, le risque devient très important. Par ailleurs, une machine Linux connectée sur Internet ouvre toujours des ports indésirés, même si elle est bien configurée. Par exemple, il est impossible d'empêcher le serveur X d'écouter les demandes de connexion provenant d'Internet, même s'il est configuré pour toutes les refuser. La configuration d'un ordinateur connecté à Internet doit donc se faire avec soin dans tous les cas, et l'installation d'un pare-feu est plus que recommandée (un « pare-feu », ou « firewall » en anglais, est un dispositif qui consiste à protéger un réseau local du « feu de l'enfer » d'Internet, sur lequel tous les crackers sont supposés grouiller).
Les paragraphes suivants exposent les mécanismes de filtrage de paquets réseau de Linux, qui sont utilisés tant pour définir les règles de protection contre les intrusions indésirables sur un réseau par l'intermédiaire d'une passerelle que pour effectuer des traitements sur les paquets. Cependant, de tous ces traitements, nous ne verrons que la translation d'adresse, car c'est sans doute celui que la plupart des gens cherchent à utiliser.
IX-D-1. Mécanismes de filtrage du noyau▲
Linux est capable de filtrer les paquets circulant sur le réseau et d'effectuer des translations d'adresses depuis la version 2.0. Cependant, les techniques utilisées ont été profondément remaniées dans la version 2.4.0 du noyau, et une architecture extensible a été mise en place et semble répondre à tous les besoins de manière simple : Netfilter.
Netfilter est simplement une série de points d'entrée dans les couches réseau du noyau au niveau desquels des modules peuvent s'enregistrer afin d'effectuer des contrôles ou des traitements particuliers sur les paquets. Il existe une entrée en chaque point clé du trajet suivi par les paquets dans les couches réseau du noyau, ce qui permet d'intervenir de manière souple et à n'importe quel niveau. Un certain nombre de modules permettant d'effectuer les traitements les plus courants sont fournis directement dans le noyau, mais l'architecture Netfilter est suffisamment souple pour permettre le développement et l'ajout des modules complémentaires qui pourraient être développés par la suite.
Les fonctionnalités fournies par ces modules sont regroupées par domaines fonctionnels. Ainsi, les modules permettant de réaliser des pare-feu se chargent spécifiquement de donner les moyens de filtrer les paquets selon des critères bien définis, et les modules permettant d'effectuer des translations d'adresses ne prennent en charge que la modification des adresses source et destination des paquets à la volée. Afin de bien les identifier, ces fonctionnalités sont regroupées dans ce que l'on appelle des tables. Une table n'est en fait rien d'autre qu'un ensemble cohérent de règles permettant de manipuler les paquets circulant dans les couches réseau du noyau pour obtenir une fonctionnalité bien précise. Les tables les plus couramment utilisées sont les tables « filter », « mangle » et « nat », qui permettent respectivement de réaliser des pare-feu, de marquer les paquets pour leur appliquer un traitement ultérieur, et d'effectuer des translations d'adresses.
Les différentes tables de NetFilter s'abonnent chacune aux points d'entrée qui sont nécessaires pour implémenter leur fonctionnalité, et les paquets qui passent au travers de ces points d'entrée doivent traverser les règles définies dans ces tables. Afin de faciliter la définition des règles stockées dans les tables, les règles sont regroupées dans des listes de règles que l'on appelle communément des chaînes. Chaque table dispose donc toujours d'une chaîne de règles prédéfinie pour chacun des points d'entrée de Netfilter qu'elle utilise. L'utilisateur peut bien entendu définir de nouvelles chaînes et les utiliser dans les chaînes prédéfinies, ces chaînes apparaissent alors simplement comme des sous-programmes des chaînes prédéfinies.
Les règles des tables de Netfilter permettent de spécifier les paquets qui les vérifient, selon des critères précis, par exemple leur adresse source ou le type de protocole qu'ils transportent. Les règles indiquent également les traitements qui seront appliqués à ces paquets. Par exemple, il est possible de détruire purement et simplement tous les paquets provenant d'une machine considérée comme non sûre si l'on veut faire un pare-feu. On pourra aussi envoyer ces paquets dans une autre chaîne, qui peuvent indiquer d'autres règles et d'autres traitements.
Les critères de sélection de paquets des règles de filtrage se basent sur les informations de l'en-tête de ces paquets. Rappelez-vous que chaque paquet de données émis sur le réseau transporte avec lui des informations nécessaires au fonctionnement du dit réseau, entre autres les adresses source et destination du paquet. Ce sont sur ces informations que la sélection des paquets est effectuée dans Netfilter. Dans le cas d'un protocole encapsulé dans un autre protocole, par exemple un paquet TCP dans un paquet IP, les informations du protocole encapsulé peuvent également être utilisées, si l'on a chargé des modules complémentaires dans NetFilter. Par exemple, le numéro de port TCP peut faire partie des critères de sélection d'une règle et donc de différencier le trafic des différents services réseau.
Les traitements que l'on peut appliquer à un paquet sont également fournis par des modules de Netfilter. Les traitements les plus simples sont bien entendu fournis en standard avec le noyau. En général, on peut chercher à réaliser les opérations suivantes sur un paquet :
- l'enregistrer, pour analyse ultérieure ;
- le rediriger vers un port local, pour traitement par un programme dédié (par exemple, par un serveur proxy) ;
- l'accepter, l'abandonner ou le rejeter directement (le rejet se distingue de l'abandon par l'émission d'une notification « hôte inaccessible » à la machine ayant émis le paquet) ;
- le modifier et, en particulier, effectuer une translation d'adresse ou le marquer pour le reconnaître dans un traitement ultérieur ;
- l'envoyer dans une autre chaîne pour effectuer des vérifications complémentaires ;
- le faire sortir immédiatement de la chaîne courante.
De plus, les statistiques tenues par le noyau pour la règle ainsi vérifiée sont mises à jour. Ces statistiques comprennent le nombre de paquets qui ont vérifié cette règle ainsi que le nombre d'octets que ces paquets contenaient.
Lorsqu'un paquet arrive à la fin d'une chaîne (soit parce qu'il n'a pas été rejeté ou détruit par une règle de filtrage de pare-feu, soit parce qu'il ne correspond aux critères d'aucune règle, ou soit parce qu'il est arrivé à ce stade après avoir subi des modifications), le noyau revient dans la chaîne appelante et poursuit le traitement du paquet. Si la chaîne au bout de laquelle le paquet arrive est une chaîne prédéfinie, il n'y a plus de chaîne appelante, et le sort du paquet est déterminé par ce qu'on appelle la politique de la chaîne prédéfinie. La politique (« policy » en anglais) des chaînes prédéfinies indique donc ce que l'on doit faire avec les paquets qui arrivent en fin de chaîne. En général, on utilise une politique relativement stricte lorsqu'on réalise un pare-feu, qui rejette par défaut tous les paquets qui n'ont pas été acceptés explicitement par une règle de la chaîne.
Note : Certains paquets peuvent être découpés en plusieurs paquets plus petits lors de la traversée d'un réseau. Par exemple, un paquet TCP un peu trop gros et initialement encapsulé dans un seul paquet IP peut se voir éclater en plusieurs paquets IP. Cela peut poser quelques problèmes aux règles de filtrage, puisque dans ce cas les données spécifiques à TCP (par exemple les numéros de ports) ne sont disponibles que sur le premier paquet IP reçu, pas sur les suivants. C'est pour cette raison que le noyau peut effectuer une « défragmentation » des paquets lorsque cela est nécessaire, et que les paquets transmis par la passerelle ne sont pas toujours strictement identitiques aux paquets qu'elle reçoit.
IX-D-2. Translations d'adresses et masquerading▲
Nous avons vu que grâce aux mécanismes de filtrage du noyau, il est possible de modifier les paquets à la volée. Il peut être intéressant de modifier un paquet pour diverses raisons, les trois plus intéressantes étant sans doute de le marquer à l'aide d'un champ spécial dans son en-tête afin de le reconnaître ultérieurement, de modifier sa priorité pour permettre un traitement privilégié ou au contraire placer en arrière plan ce type de paquet (libérant ainsi les ressources réseau pour d'autres types de connexion), et de modifier ses adresses source et destination, pour effectuer une translation d'adresse. Nous allons nous intéresser plus particulièrement aux différentes formes de translations d'adresses dans la suite de cette section.
Une translation d'adresse n'est en fait rien d'autre qu'un remplacement contrôlé des adresses source ou destination de tous les paquets d'une connexion. En général, cela permet de détourner les connexions réseau ou de simuler une provenance unique pour plusieurs connexions. Par exemple, les connexions à Internet peuvent être détournées vers un proxy fonctionnant sur la passerelle de manière transparente, en modifiant les adresses destination des paquets émis par les clients. De même, il est possible de simuler un seul serveur en remplaçant à la volée les adresses source des paquets que la passerelle envoie sur Internet.
On distingue donc deux principaux types de translations d'adresses : les translations d'adresse source et les translations d'adresse destination. Parmi les translations d'adresse source se trouve un cas particulier particulièrement intéressant : le « masquerading ». Cette technique permet de remplacer toutes les adresses source des paquets provenant des machines d'un réseau local par l'adresse de l'interface de la passerelle connectée à Internet, tout en conservant une trace des connexions réseau afin d'acheminer vers leur véritable destinataire les paquets de réponses. Ainsi, une seule connexion à Internet peut être utilisée par plusieurs machines distinctes, même si elles ne disposent pas d'adresses IP fournies par l'IANA.
Lorsqu'une machine du réseau local envoie un paquet à destination d'Internet, ce paquet est acheminé vers la passerelle, qui est la route par défaut. Celle-ci commence par modifier l'adresse source de ce paquet et mettre sa propre adresse à la place, puis le transfère vers la machine du fournisseur d'accès. Tous les paquets émis par les machines du réseau local semblent donc provenir de cette passerelle, et seront acheminés normalement à destination. En fait, la complication provient des paquets de réponses, puisque les machines situées sur Internet croient que la machine avec laquelle elles communiquent est la passerelle. Ces paquets sont donc tous envoyés à la passerelle directement, et celle-ci doit retrouver la machine du réseau local à laquelle ils sont destinés. Cette opération est réalisée de différentes manières selon les protocoles utilisés, et elle suppose que la passerelle conserve en permanence une trace des connexions réseau effectuées par les machines du réseau local.
Pour TCP, ce suivi de connexion est réalisé en modifiant également le port source des paquets provenant des machines locales. La passerelle utilise un port unique pour chaque connexion, qui va lui permettre de retrouver la machine à laquelle un paquet est destiné lorsqu'elle en reçoit un provenant d'Internet. Par exemple, si une machine locale fait une connexion à Internet, la passerelle alloue un nouveau numéro de port pour cette connexion et modifie tous les paquets sortants comme ayant été émis par la passerelle elle-même, sur ce port. Lorsque l'autre machine prenant part à la connexion, située sur Internet, envoie un paquet de réponses, celui-ci sera à destination de la passerelle, avec comme port destination le port alloué à cette connexion. La passerelle peut donc retrouver, à partir de ce port, l'adresse de la machine destination réelle, ainsi que le port source que cette machine utilisait initialement. La passerelle modifie donc ces deux champs du paquet, et le renvoie sur le réseau local. Finalement, la machine destination reçoit le paquet sur son port, et ce paquet semble provenir directement d'Internet, comme si la connexion avait été directe. Notez bien que la passerelle ne modifie pas les adresses source des paquets provenant d'Internet, elle ne fait que les réacheminer vers la bonne destination.
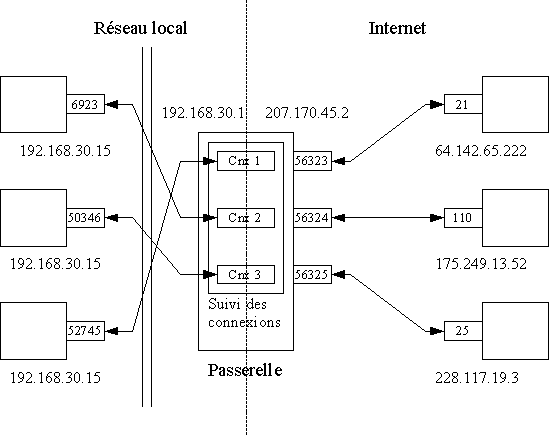
Ainsi, le masquerading est un mécanisme complètement transparent pour les machines du réseau local. En revanche, pour les machines de l'Internet, il ne semble y avoir qu'un seul interlocuteur : la passerelle. Celle-ci utilise des numéros de ports variés, mais cela ne les regarde pas. Les machines du réseau local sont donc complètement « masquées » par la passerelle, d'où le nom de masquerading.
Tout ce travail effectué par la passerelle nécessite un traitement spécifique sur chaque paquet qu'elle achemine, et consomme bien entendu des ressources système. Cependant, les débits utilisés pour les connexions à Internet, même les plus rapides, sont très loin de mettre à genoux une passerelle sous Linux, même sur les plus petites machines (386 et 486). Vous voilà rassurés, et peut-être aurez-vous trouvé d'ici peu une utilité à l'un de ces dinosaures qui traînent encore dans votre garage…
IX-D-3. Trajet des paquets dans le code de Netfilter▲
Il existe cinq points d'entrée au total pour les modules de Netfilter dans le code des couches réseau IP de Linux. À chacun de ces points d'entrée, les paquets sont soumis aux différentes chaînes des tables qui s'y intéressent. Comme on l'a déjà dit plus haut, chaque table dispose d'une chaîne prédéfinie pour chacun des points d'entrée auxquels elle s'intéresse. Le nom de ces chaînes prédéfinies est le nom du point d'entrée au niveau duquel elles sont appelées. Les paragraphes suivants décrivent ces cinq points d'entrée, ainsi que l'ordre dans lequel les chaînes des différentes tables sont traversées par les paquets.
Les paquets réseau provenant de l'extérieur sont d'abord contrôlés par le noyau afin de détecter les erreurs les plus simples. Les paquets mal formés ou corrompus sont systématiquement éliminés à ce niveau, avant même d'atteindre le code de Netfilter. Les autres paquets commencent alors leur trajet dans les couches de plus haut niveau. C'est à ce moment-là qu'ils rencontrent le point d'entrée PREROUTING. Les règles des chaînes PREROUTING des tables mangle et nat sont appliquées à ce moment. Ces chaînes précèdent le code de routage, qui est en charge de déterminer le trajet que le paquet devra suivre par la suite à partir de l'adresse destination des paquets. C'est donc dans ces chaînes que l'on pourra entre autres modifier l'adresse destination des paquets, si l'on veut faire une translation d'adresse destination. Cette opération se fait typiquement dans la table nat.
Les paquets qui passent le point d'entrée PREROUTING sont ensuite orientés par le code de routage de Linux. S'ils sont à destination de la machine locale, ils rencontrent un autre point d'entrée : le point d'entrée INPUT. Les règles des chaînes INPUT des tables mangle et filter sont exécutées à ce moment. C'est donc à ce niveau que l'on peut empêcher un paquet d'entrer dans le système, ce qui se fait naturellement dans la table filter.
Les autres paquets doivent être transférés vers une autre machine, souvent par une autre interface réseau. Ils atteignent donc le point d'entrée FORWARD. Ce point d'entrée permet de contrôler les paquets qui transitent au travers d'une passerelle. Les paquets y traversent les chaînes FORWARD des tables mangle et filter, cette dernière étant justement dédiée au filtrage des paquets qui transitent par la passerelle.
Les paquets qui sont acceptés par les chaînes FORWARD retournent ensuite dans le code de routage du noyau, afin de déterminer l'interface réseau par laquelle ils doivent être réémis. Une fois cela réalisé, ils sont prêts à être réémis, mais ils doivent auparavant traverser les chaînes des tables abonnées au point d'entrée POSTROUTING. Il s'agit bien sûr des chaînes POSTROUTING des tables mangle et nat. C'est dans cette dernière chaîne que se font les translations d'adresse source.
Enfin, les paquets émis par la machine locale à destination de l'extérieur doivent impérativement passer par le point d'entrée OUTPUT, qui exécute les chaînes OUTPUT des tables mangle, nat et filter. C'est donc à ce niveau que l'on pourra modifier les adresses destination des paquets de la machine locale avant leur routage et effectuer le filtrage des paquets sortants, dans les chaînes OUTPUT des tables nat et filter. Les paquets qui se révèlent avoir le droit de sortir traversent alors de code de routage, puis, tout comme les paquets qui ont été transférés, passent par le point d'entrée POSTROUTING.
IX-D-4. Configuration du noyau et installation des outils▲
Les fonctionnalités de Netfilter sont toutes fournies par le noyau lui-même, aussi leur configuration doit-elle se faire au niveau du noyau. La manière de procéder pour configurer le noyau a été indiquée dans le paragraphe traitant de la compilation du noyau. Les options à activer pour mettre en place les fonctionnalités de filtrage des paquets et de translation d'adresse sont les suivantes :
- « Network packet filtering (replace ipchains) », pour activer les fonctionnalités de filtrage des paquets en général ;
- « Network packet filtering debugging », pour obtenir les messages de débogage du noyau. Ces messages peuvent être très utiles pour mettre au point les règles de filtrage ;
- « Connection tracking (required for masq/NAT) » (menu « IP: Netfilter Configuration »), pour permettre le suivi des connexions auxquelles appartiennent les paquets IP reçus par la passerelle. Cette option est nécessaire pour réaliser un partage de connexion à Internet ;
- « FTP protocol support », pour permettre la gestion des connexions FTP, qui exigent un traitement particulier pour les translations d'adresses ;
- « IP tables support (required for filtering/masq/NAT) », pour permettre la gestion des tables de Netfilter ;
- « Packet filtering », pour inclure le support de la table « filter ». Cette option est nécessaire pour réaliser un pare-feu ;
- « REJECT target support », pour permettre le rejet des paquets (par défaut, seul l'abandon des paquets est fourni dans le code de filtrage) ;
- « Full NAT », pour inclure la table « nat » de Netfilter. Cette option est nécessaire pour réaliser un partage de connexion à Internet ;
- « MASQUERADE target support », pour permettre le masquerading afin de réaliser un partage de connexion à Internet.
Vous devrez ensuite compiler le noyau et les modules, et les installer comme indiqué dans la partie traitant de la compilation du noyau.
Note : Le noyau de Linux dispose d'un paramètre global permettant de contrôler le routage des paquets IP d'une interface réseau à une autre. Par défaut, ce paramètre est à 0, ce qui implique que la transmission des paquets ne sera pas autorisée. Il faut donc activer ce paramètre à chaque démarrage afin de pouvoir utiliser votre passerelle Linux. Cela peut être réalisé en écrivant la valeur 1 dans le fichier /proc/sys/net/ipv4/ip_forward du système de fichiers virtuel /proc/ :
echo "1" > /proc/sys/net/ipv4/ip_forwardLa manipulation des chaînes et la manipulation des règles de Netfilter se fait grâce à l'outil iptables. Cette commande doit normalement avoir été installée par votre distribution. Toutefois, si ce n'est pas le cas, vous pouvez la compiler manuellement. Pour cela, il vous faudra récupérer l'archive des sources d'iptables. Cette archive peut être trouvée sur Internet. La version courante est la 1.2.9, aussi l'archive se nomme-t-elle iptables-1.2.6a.tar.bz2.
L'installation d'iptables ne pose pas de problème particulier en soi. Vous devrez d'abord décompresser l'archive avec les deux commandes suivantes :
bunzip2 iptables-1.2.9.tar.bz2
tar xf iptables-1.2.9.tarpuis modifier le fichier Makefile pour définir les répertoires d'installation dans les variables LIBDIR, BINDIR et MANDIR. En général, les répertoires utilisés seront respectivement les répertoires /usr/lib/, /usr/bin/ et /usr/man/. Une fois cela fait, il ne restera plus qu'à compiler le tout avec la commande make et à faire l'installation avec la commande make install.
IX-D-5. Utilisation d'iptables▲
Il est possible, grâce à iptables, d'effectuer toutes les opérations d'administration désirées sur les chaînes des tables de Netfilter. Vous pourrez donc créer des nouvelles chaînes, les détruire, définir les politiques par défaut, ainsi que manipuler les règles de ces chaînes (en ajouter, en supprimer ou en remplacer une). En fait, iptables dispose d'un grand nombre d'options, et seules les options les plus importantes seront présentées ici. Vous pouvez lire la page de manuel iptables si vous désirez plus de renseignements sur la manipulation des chaînes et des règles de filtrage du noyau.
IX-D-5-a. Manipulation des chaînes▲
Toutes les options peuvent être utilisées avec toutes les tables gérées par le noyau. La table sur laquelle une commande s'applique peut être précisée à l'aide de l'option -t. Si cette option n'est pas fournie, la table utilisée par défaut sera la table filter, qui est celle qui est normalement utilisée pour définir des règles de filtrage des paquets dans un pare-feu.
La création d'une nouvelle chaîne se fait simplement avec l'option -N :
iptables [-t table] -N chaîneoù chaîne est le nom de la chaîne à créer. Il est interdit d'utiliser un des mots clés réservés par iptables. En pratique, il est recommandé d'utiliser des noms de chaînes en minuscules, car les chaînes prédéfinies sont en majuscules.
Une chaîne peut être détruite avec l'option -X :
iptables [-t table] -X chaîneUne chaîne ne peut être détruite que lorsqu'elle ne contient plus de règle. De plus, il est impossible de détruire les chaînes prédéfinies d'une table.
Vous pouvez lister l'ensemble des règles d'une chaîne avec l'option -L :
iptables [-t table] -L chaîneEnfin, il est possible de supprimer toutes les règles d'une chaîne avec l'option -F :
iptables [-t table] -F chaîneoù chaîne est le nom de la chaîne dont on veut supprimer les règles.
IX-D-5-b. Manipulation des règles▲
La syntaxe générale pour ajouter une règle dans une chaîne est la suivante :
iptables [-t table] -A chaîne [-s source] [-d destination] [-p protocole]
[-i itfsource] [-o itfdest] [-j cible]où :
- table est la table dans laquelle se trouve la chaîne manipulée (par défaut, il s'agit de la table filter) ;
- chaîne est le nom de la chaîne à laquelle la règle doit être ajoutée ;
- source est l'adresse source du paquet ;
- destination est l'adresse destination du paquet ;
- protocole est le protocole du paquet (spécifié avec son numéro de port ou par le nom du protocole tel qu'il est déclaré dans le fichier /etc/services) ;
- itfsource est le nom de l'interface réseau source par laquelle le paquet doit arriver ;
- itfdest est le nom de l'interface destination par laquelle le paquet doit sortir ;
- et cible est la cible des paquets qui vérifient les critères de sélection de la règle.
Chacun des paramètres placés entre crochets dans la syntaxe est facultatif, mais il faut au moins qu'un critère de sélection soit donné (sur les adresses source ou destination, ou sur le port ou l'interface).
Les adresses source et destination peuvent être indiquées directement par le nom des machines (comme par exemple « www.monrezo.com ») ou par leurs adresses IP. Vous pouvez spécifier directement toutes les adresses d'un réseau avec la syntaxe « réseau/masque ». Il est également possible d'utiliser la syntaxe « réseau/n », où « n » est le nombre de bits mis à 1 dans le masque de sous-réseau. Ainsi, réseau/24 est équivalent à réseau/255.255.255.0, réseau/16 à réseau/255.255.0.0, etc. Par extension, « réseau/0 » peut être utilisé pour spécifier toutes les adresses possibles (dans ce cas, l'adresse donnée pour le réseau n'est pas prise en compte).
La cible détermine les opérations qui seront appliquées à ces paquets. Les cibles autorisées dépendent de la chaîne dans laquelle la règle est ajoutée, ainsi que des modules de Netfilter qui ont été compilés. Les principales cibles sont les suivantes :
- ACCEPT, pour accepter le paquet qui vérifie le critère de sélection de la règle ;
- DROP, pour éliminer purement et simplement le paquet ;
- REJECT, pour rejeter le paquet (en signalant l'erreur à la machine émettrice). Cette cible n'est utilisable que dans les chaînes INPUT, FORWARD et OUTPUT, ainsi que dans les chaînes utilisateurs appelées à partir de ces chaînes ;
- QUEUE, pour envoyer le paquet à un programme utilisateur capable de communiquer avec NetFilter ;
- RETURN, pour sortir de la chaîne immédiatement, ou appliquer la règle de la politique par défaut pour les chaînes prédéfinies ;
- REDIRECT, pour rediriger le paquet sur une autre machine, souvent la machine locale. Cette cible n'est utilisable qu'avec la table nat, car il s'agit d'une translation d'adresse. On ne peut l'utiliser que dans les chaînes PREROUTING et OUTPUT et les chaînes utilisateur appelées à partir de ces chaînes ;
- SNAT, pour permettre la modification de l'adresse source du paquet. Cette cible n'est bien entendu accessible qu'au niveau de la table nat. Comme la modification de l'adresse source n'a de signification que pour les paquets devant sortir de la passerelle, cette cible ne peut être utilisée que dans la chaîne POSTROUTING et les chaînes utilisateur appelées à partir de cette chaîne ;
- DNAT, pour effectuer la modification de l'adresse destination du paquet, afin par exemple de le détourner vers une autre machine que celle vers laquelle il devait aller. Cette cible n'est accessible que dans la table nat, et n'est utilisable que dans les chaînes PREROUTING et OUTPUT ainsi que dans les chaînes utilisateur appelées à partir de ces chaînes ;
- MASQUERADE, pour effectuer une translation d'adresse sur ce paquet, dans le but de réaliser un partage de connexion à Internet. Cette cible n'est accessible que dans la chaîne POSTROUTING de la table nat, ainsi que dans les chaînes utilisateur appelées à partir de cette chaîne.
Toute autre spécification de destination doit être le nom d'une chaîne utilisateur, avec les règles de laquelle le paquet devra être testé. Si aucune cible n'est spécifiée, aucune action n'est prise et la règle suivante est traitée. Cependant, les statistiques de la règle sont toujours mises à jour.
La suppression d'une règle d'une chaîne se fait avec la commande suivante :
iptables -D chaîne numérooù chaîne est la chaîne dont on veut supprimer la règle, et numéro est le numéro de la règle à supprimer dans cette chaîne. Il est également possible d'utiliser l'option -D avec les mêmes options que celles qui ont été utilisées lors de l'ajout de la règle, si l'on trouve cela plus pratique.
Enfin, la politique d'une chaîne, c'est-à-dire la cible par défaut, peut être fixée avec l'option -P :
iptables -P chaîne cibleoù chaîne est l'une des chaînes prédéfinies, et cible est l'une des cibles ACCEPT ou DROP. Remarquez que l'on ne peut pas définir de politique pour les chaînes créées par l'utilisateur, puisque les paquets sont vérifiés avec les règles restantes de la chaîne appelante lorsqu'ils sortent de la chaîne appelée.
IX-D-6. Exemple de règles▲
Ce paragraphe a pour but de présenter quelques-unes des règles les plus classiques. Le but est ici de présenter les principales fonctionnalités d'iptables et de réaliser un pare-feu simpliste.
IX-D-6-a. Exemple de règles de filtrage▲
Les règles de filtrage peuvent être utilisées pour mettre en place un pare-feu afin de protéger votre réseau. La définition des règles de filtrage constitue bien souvent l'essentiel du problème, et nécessite bien entendu de parfaitement savoir ce que l'on veut faire. De manière générale, la règle d'or en matière de sécurité informatique est de tout interdire par défaut, puis de donner les droits au compte-goutte. C'est exactement ce que permet de faire la politique des chaînes. On définira donc toujours la politique par défaut des chaînes pour utiliser la cible DROP. Cela peut être réalisé simplement avec les trois commandes suivantes :
# Définition de la politique de base :
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT DROP
# Suppression des règles existantes :
iptables -F INPUT
iptables -F FORWARD
iptables -F OUTPUTCes règles commencent par définir les politiques de base pour toutes les tables en blindant la machine pour qu'elle ne laisse rien entrer, ne rien passer et ne rien sortir. Toutes les règles des tables sont ensuite détruites. Dans ce cas, on ne craint plus rien, mais on ne peut plus rien faire non plus (pas même en local). Aussi faut-il redonner les droits nécessaires pour permettre l'utilisation normale de votre système. Le minimum est d'autoriser la machine à communiquer avec elle-même, ce qui implique d'autoriser les paquets provenant de l'interface loopback à entrer et à sortir :
# Communications locales :
iptables -A INPUT -d 127.0.0.0/8 -i lo -j ACCEPT
iptables -A OUTPUT -s 127.0.0.0/8 -o lo -j ACCEPTSi l'on dispose d'un réseau local, il peut également être utile d'autoriser toutes les connexions avec les machines de ce réseau :
# Connexions au réseau local :
iptables -A INPUT -s 192.168.0.0/24 -i eth0 -j ACCEPT
iptables -A OUTPUT -s 192.168.0.1 -o eth0 -j ACCEPTComme vous pouvez le constater, ces règles ne permettent l'entrée des paquets prétendant provenir du réseau local (c'est-à-dire les paquets ayant comme adresse source une adresse de la forme 192.168.0.0/24) que par l'interface réseau connectée au réseau local (dans notre exemple, il s'agit de l'interface réseau eth0). De même, seule la machine locale (à laquelle l'adresse 192.168.0.1 est supposée être affectée) peut émettre des paquets sur le réseau local.
Notez que ces règles sont beaucoup trop restrictives pour permettre un accès à Internet (et, a fortiori une intrusion provenant d'Internet…). Il est donc nécessaire d'autoriser les connexions vers les principaux services Internet. Pour cela, il faut ajouter les lignes suivantes :
# Autorise les communications sortantes
# pour DNS, HTTP, HTTPS, FTP, POP, SMTP, SSH et IPSec :
iptables -A OUTPUT -o ppp0 -p UDP --dport domain -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport domain -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport http -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport https -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport ftp -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport pop3 -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport smtp -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --dport ssh -j ACCEPT
iptables -A OUTPUT -o ppp0 -p AH -j ACCEPT
iptables -A OUTPUT -o ppp0 -p ESP -j ACCEPTIl est supposé ici que la connexion Internet se fait via le démon pppd, et que l'interface réseau que celui-ci a créée se nomme ppp0.
Vous pouvez constater que les règles présentées jusqu'ici se basaient uniquement sur les adresses source et destination des paquets, ainsi que sur les interfaces réseau par lesquelles ils entraient et ressortaient. Vous voyez à présent que l'on peut réaliser des règles beaucoup plus fines, qui se basent également sur les protocoles réseau utilisés (que l'on peut sélectionner avec l'option -p) et, pour chaque protocole, sur des critères spécifiques à ces protocoles (comme les ports source et destination, que l'on peut sélectionner respectivement avec les options --sport et --dport). Vous pouvez consulter la page de manuel d'iptables pour plus de détails à ce sujet.
Certains protocoles requièrent plusieurs connexions TCP/IP pour fonctionner correctement. La connexion est amorcée avec une première connexion, puis une deuxième connexion est établie après négociation. C'est en particulier le cas pour le protocole FTP, qui utilise une connexion de contrôle et une connexion pour le transfert des données. De plus, le protocole FTP peut fonctionner dans deux modes distincts (respectivement le mode dit « actif » et le mode dit « passif »), selon que c'est le serveur contacté qui établit la connexion de données ou que c'est le client qui l'établit vers le serveur. Ces connexions additionnelles ne doivent bien entendu pas être filtrées, pour autant, on ne sait pas avec précision le port qui sera choisi pour elles, car ce port fait partie de la négociation lors de l'établissement de la connexion. Heureusement, Netfilter dispose d'un mécanisme de suivi de connexions capable d'analyser les données protocolaires (si le protocole n'est pas chiffré, bien entendu). La solution est donc de lui indiquer qu'il doit laisser les paquets relatifs aux connexions établies au niveau protocolaire. La règle à utiliser est la suivante :
# Autorise l'établissement des connexions protocolaires additionnelles :
iptables -A OUTPUT -o ppp0 -m state --state ESTABLISHED,RELATED -j ACCEPTVous découvrez ici l'option --match, qui permet de sélectionner des paquets selon certains critères. Le critère choisi ici est bien entendu l'état des connexions. Des options complémentaires peuvent être fournies à ce critère à l'aide de l'option --state. Dans le cas présent, nous acceptons tous les paquets sortants qui appartiennent à une connexion établie (paramètre « :ESTABLISHED ») ou qui a été amorcée à partir d'une autre connexion déjà établie (paramètre « RELATED »).
Les règles précédentes permettent à la machine locale de se connecter à Internet, mais la connexion ne s'établira malgré tout pas, car aucun paquet réponse n'a le droit d'entrer. Il est donc nécessaire d'autoriser l'entrée des paquets réponse provenant des serveurs auxquels on se connecte. Toutefois, il ne faut pas tout autoriser. Seuls les paquets relatifs aux connexions dont la machine locale est initiatrice doivent être autorisés. Cela est réalisable encore une fois grâce au mécanisme de suivi de connexions de Netfilter. Pour notre exemple, la simple règle suivante suffit :
# Autorise les paquets entrants pour les connexions
# que l'on a établies :
iptables -A INPUT -i ppp0 --match state --state ESTABLISHED,RELATED -j ACCEPTElle dit que les paquets entrants des connexions établies et des connexions relatives aux autres connexions sont autorisés. Tous les autres paquets seront refusés.
Si vous désirez laisser un service ouvert vers Internet, vous devrez ajouter des règles complémentaires qui autorisent les paquets entrant et sortant à destination du port de ce service. Par exemple, si vous voulez laisser un accès SSH ouvert, vous devrez ajouter les deux règles suivantes :
# Autorise les connexions SSH entrantes :
iptables -A INPUT -i ppp0 -p TCP --dport ssh -j ACCEPT
iptables -A OUTPUT -o ppp0 -p TCP --sport ssh -j ACCEPTEnfin, il peut être utile d'accepter certains paquets du protocole ICMP, qui permet de contrôler l'état des liaisons. En particulier, il faut pouvoir recevoir les paquets indiquant qu'une machine n'est pas accessible, faute de quoi certaines connexions impossibles risqueraient d'être très longues à détecter. De plus, il peut être intéressant de pouvoir envoyer des demandes de réponse aux machines pour vérifier leur présence. Les règles suivantes pourront donc être ajoutées :
# Autorise les paquets ICMP intéressants :
iptables -A OUTPUT -p ICMP --icmp-type echo-reply -j ACCEPT
iptables -A INPUT -p ICMP --icmp-type echo-request -j ACCEPT
iptables -A OUTPUT -p ICMP --icmp-type echo-request -j ACCEPT
iptables -A INPUT -p ICMP --icmp-type echo-reply -j ACCEPT
iptables -A INPUT -p ICMP --icmp-type destination-unreachable -j ACCEPTNotez qu'il n'est théoriquement pas nécessaire de répondre aux paquets echo-request. Je vous ai toutefois laissé les deux règles pour le cas où le fournisseur d'accès utiliserait ces requêtes pour déterminer si la liaison reste correcte.
IX-D-6-b. Exemple de partage de connexion à Internet▲
Le masquerading est un cas particulier de translation d'adresse source. En effet, celle-ci est couplée à un suivi des connexions afin d'effectuer la translation d'adresse destination des paquets de réponses renvoyés par les serveurs sur Internet pour les acheminer vers la machine du réseau local qui a initié la connexion.
En pratique, seule la chaîne POSTROUTING de la table nat sera utilisée pour le masquerading, parce que c'est à ce niveau que la translation d'adresse est effectuée. La mise en œuvre du masquerading se fait extrêmement simplement, puisqu'il suffit de spécifier que tous les paquets du réseau local sortant de l'interface réseau connectée sur Internet doivent subir le masquerading. En général, l'interface de la connexion à Internet est une interface PPP, aussi la règle à utiliser est-elle simplement la suivante :
# Effectue la translation d'adresses :
iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o ppp0 -j MASQUERADECette règle permet de réaliser la translation des adresses des machines du réseau local et à destination d'Internet. Remarquez que les paquets provenant de la machine locale ne subissent pas le masquerading, car c'est complètement inutile.
Il faut ensuite autoriser les paquets provenant des machines du réseau local à traverser la passerelle. Cela se fait avec des règles similaires à celles vues dans la section précédente, mais adaptées pour être utilisées dans la chaîne FORWARD de la table filter :
# Autorise le trafic DNS, HTTP, HTTPS,
# FTP, POP, SMTP et SSH au travers de la passerelle :
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p UDP --dport domain -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport domain -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport http -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport https -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport ftp -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport pop3 -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport smtp -j ACCEPT
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o ppp0 -p TCP --dport ssh -j ACCEPT
# Autorise l'établissement des connexions protocolaires additionnelles :
iptables -A FORWARD -s 192.168.0.0/24 -i eth0 -o eth0 --match state \
--state ESTABLISHED,RELATED -j ACCEPT
# Autorise le trafic en retour pour les connexions établies par les clients :
iptables -A FORWARD -i ppp0 -d 192.168.0.0/24 --match state \
--state ESTABLISHED,RELATED -j ACCEPT
# Autorise le trafic ICMP :
iptables -A FORWARD -p ICMP --icmp-type echo-request -j ACCEPT
iptables -A FORWARD -p ICMP --icmp-type echo-reply -j ACCEPT
iptables -A FORWARD -p ICMP --icmp-type destination-unreachable -j ACCEPTEnfin, le routage des paquets étant, par défaut, désactivé sous Linux, il faut le réactiver. Si votre distribution ne le fait pas, vous aurez donc également à ajouter une ligne telle que celle-ci :
# Activation du routage :
echo "1" > /proc/sys/net/ipv4/ip_forwarddans vos scripts de démarrage de votre système.
Certains routeurs et certaines passerelles d'Internet sont bogués et ne répondent pas correctement aux messages ICMP. Cela a pour conséquence, entre autres, que la taille maximum des paquets transmis via la passerelle peut ne pas être déterminée correctement. En effet, les clients de la passerelle utiliseront généralement la taille maximum utilisable pour communiquer avec la passerelle, et cette taille peut malheureusement être supérieure à la taille maximum des paquets pour atteindre certains sites Web. Les messages d'erreurs ICMP étant filtrés, personne ne peut s'en apercevoir, et certaines connexions peuvent rester bloquées ad vitam eternam. Pratiquement parlant, cela se traduit par l'impossibilité, pour certains clients bénéficiant du partage de connexion à Internet, d'accéder à certains sites Web ou à certains gros fichiers d'une page (images par exemple).
Pour pallier ce problème, Linux propose une technique approximative, dont le but est de fixer une option des paquets TCP d'établissements de connexion, afin de limiter la taille des paquets suivants de la connexion à la taille maximum déterminée pour la route vers les ordinateurs cibles. Ainsi, les clients se limitent d'eux-mêmes, pourvu que la taille maximum des paquets de la route soit correctement déterminée, bien entendu. Il est recommandé d'activer cette fonctionnalité, ce qui se fait à l'aide de la commande suivante :
# Restreint la taille des paquets des connexions TCP
# lors de leur établissement :
iptables -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS -o ppp0 \
--clamp-mss-to-pmtuCette règle un peu compliquée permet de modifier le champ MSS (« Maximum Segment Size ») des paquets d'établissements des connexions TCP (paquets disposant des flags TCP SYN ou RST) qui traversent la passerelle, et de forcer ce champ à la valeur de la taille maximum des paquets sur le chemin (« Path Maximum Transmission Unit » dans l'option --clamp-mss-to-pmtu).
Note : Les chaînes et leurs règles ne sont pas enregistrées de manière permanente dans le système. Elles sont perdues à chaque redémarrage de la machine, aussi faut-il les redéfinir systématiquement. Cela peut être réalisé dans les scripts de démarrage de votre système. Vous pouvez également utiliser les commandes iptables-save et iptables-restore pour sauvegarder toutes les chaînes et leurs règles dans un fichier et les restaurer au démarrage.
N'oubliez pas que votre passerelle doit définir une route par défaut pour que tous les paquets qui ne sont pas destinés au réseau local soient envoyés par l'interface réseau connectée à Internet. Cette route par défaut est établie automatiquement lorsque vous vous connectez à Internet à l'aide de PPP. Dans les autres cas, vous aurez à la définir manuellement.
IX-D-7. Configuration des clients▲
La configuration des autres machines du réseau est très simple. Vous devrez tout d'abord définir la machine possédant la connexion à Internet comme passerelle par défaut de tous vos postes clients. Cette opération peut se réaliser de différentes manières selon le système d'exploitation utilisé par ces machines. Sous Linux, il suffit d'utiliser la commande suivante :
route add default gw passerelle eth0où passerelle est l'adresse de votre passerelle vers Internet sur le réseau local. Cette commande suppose que l'adaptateur réseau utilisé est eth0
La deuxième étape est ensuite de donner accès aux postes clients au DNS de votre fournisseur d'accès. Cela permettra en effet d'utiliser les noms de machines autres que ceux de votre réseau local. Encore une fois, la manière de procéder dépend du système utilisé. Sous Linux, il suffit d'ajouter les adresses IP des serveurs de noms de domaine de votre fournisseur d'accès dans le fichier de configuration /etc/resolv.conf.
Si les clients ont des difficultés à accéder à certaines pages Web, c'est que le MTU (« Maximum Transmission Unit », taille maximum des paquets réseau) est trop élevé. Ceci se corrige généralement tel qu'on l'a indiqué dans la définition des règles de la passerelle. Toutefois, si les ordinateurs qui bénéficient du partage de connexion à Internet continuent d'avoir des problèmes, c'est que le MTU de la route permettant d'accéder aux sites Web posant problème n'a pas pu être déterminé correctement. Dans ce cas, il faut le trouver soi-même, et le fixer dans la configuration réseau des clients. Pour cela, le plus simple est d'utiliser la commande ping avec son option -s sur les clients, avec plusieurs tailles de paquets possible. La taille maximum est de 1500 octets sur Ethernet. En général, une taille de 1400 octets convient :
ping -s 1400 adresseUne fois le MTU correctement déterminé, il suffit de fixer cette valeur lors de la configuration des interfaces réseau des clients :
ifconfig interface mtu tailleinterface représente ici l'interface à configurer, et taille la taille maximum trouvée à l'aide de ping.
Note : La taille effective du MTU est en réalité la taille fournie à la commande ping plus vingt-huit octets, car les paquets utilisés contiennent toujours l'en-tête ICMP en plus des données générées par ping.
IX-E. Configuration de la sécurité du réseau▲
La sécurité d'un réseau n'est pas quelque chose à prendre à la légère, surtout lorsqu'on commence à transmettre des données personnelles sur le réseau. Internet n'est absolument pas sûr, car nombre de personnes curieuses, peu discrètes ou franchement mal intentionnées ont un accès privilégié aux machines qui s'y trouvent. Il est donc essentiel de prendre les problèmes sécuritaires très au sérieux, d'autant plus que Linux est un système disposant d'un grand nombre de fonctionnalités serveur.
Bien qu'il soit impossible de réaliser un système sûr à 100%, la situation actuelle est franchement catastrophique et si cela continue comme cela, la seule chose de sûre, c'est qu'on va aller droit dans le mur. Entre ne rien faire du tout et se fixer un niveau de sécurité raisonnable permettant de limiter les dégâts, il y a un grand pas. Cette section n'a donc pas pour but de vous transformer en expert en sécurité (n'en étant pas un moi-même, je serais bien incapable d'en écrire une ayant cet objectif), mais de vous présenter les principes de base et le minimum requis pour laisser les mauvaises surprises aux autres.
L'un des principes de base de la sécurité est de ne faire confiance à personne. Ce n'est pas un comportement paranoïaque, mais simplement du bon sens : la plupart des surprises désagréables dans le monde environnant proviennent du mauvais jugement des personnes. De plus, même des personnes de bonne foi peuvent être manipulées par un tiers sans qu'elles s'en rendent compte.
Partant de se constat, et quand bien même on serait capable de garantir la fiabilité d'un système à 100%, il est nécessaire de limiter et de cloisonner les services fournis, et d'en restreindre l'accès aux personnes habilitées. Cela est d'autant plus important que la plupart des démons ont besoin d'avoir les privilèges du compte root pour s'exécuter. Cela peut être dramatique si d'aventure une personne mal intentionnée découvrait le moyen de les détourner de leur fonction initiale et de leur faire accomplir des tâches au nom de l'administrateur. Bien entendu, les démons sont des programmes très bien écrits, qui vérifient généralement toutes les requêtes demandées par les clients avant de les satisfaire. Cependant, tout programme peut comporter des failles et laisser ainsi un accès indésiré au sein du système. Autant éliminer directement le problème en ne lançant que les services réellement nécessaires sur votre machine.
De plus, il va de soi que lorsqu'il y a un loup dans la bergerie, tout peut aller très mal très vite. La sécurité doit donc être mise en place en profondeur, c'est-à-dire que l'on ne doit pas négliger la sécurisation d'un réseau local sous prétexte qu'il est protégé par des dispositifs en amont. En effet, ces dispositifs peuvent très bien être défaillants, et dans ce cas, l'intrus se retrouve directement en terrain conquis. C'est pour cela qu'il faut prévoir plusieurs remparts pour se protéger.
En outre, rien n'est jamais figé dans le domaine de la sécurité. De nouvelles attaques sont développées régulièrement, et de nouvelles failles sont découvertes dans les logiciels quasiment quotidiennement. Il est donc nécessaire de réaliser un tant soit peu de veille et de mettre à jour les systèmes régulièrement.
Enfin, la sécurité ne peut se concevoir que dans un contexte global, en prenant compte l'environnement dans lequel on se trouve. Il est tout à fait inutile d'utiliser des systèmes d'authentification par analyse de code génétique pour protéger des documents ultra-sensibles, si ces documents peuvent être sortis simplement par les poubelles.
En résumé, les principes fondamentaux de la sécurité sont les suivants :
- il faut limiter le nombre des services lancés au strict minimum ;
- il faut en restreindre l'accès aux seules personnes autorisées ;
- il faut être proactif, se tenir au courant et mettre à jour les logiciels dès l'apparition des correctifs de sécurité ;
- il faut prévoir plusieurs systèmes de sécurité ;
- il faut prendre en compte les problèmes de sécurité de manière globale.
De tous ces points, nous ne traiterons ici que ceux qui concernent un système de particulier. La mise à jour des logiciels et des antivirus reste bien entendu extrêmement importante (surtout si des machines Windows sont placées sur le réseau), mais n'appelle pas beaucoup de commentaires. La description de la réalisation d'un pare-feu a également déjà été faite dans la section précédente. Nous ne présenterons donc que la manière de limiter les services lancés et l'accès à ces services. Cela n'est toutefois pas suffisant pour dormir tranquille, car, et c'est sans doute là l'un des plus gros problèmes, la plupart des protocoles réseau ne chiffrent pas leurs données et laissent passer toutes les informations en clair sur le réseau, y compris les mots de passe ! Nous verrons donc également les principales techniques de cryptographie existantes afin de rendre les communications plus sûres.
IX-E-1. Limitation des services et des accès▲
IX-E-1-a. Réduction du nombre des services▲
Les services réseau d'un système Linux sont nombreux, mais la plupart du temps inutiles pour l'emploi que l'on veut faire de son ordinateur. Par conséquent, il vaut mieux tout simplement ne pas les proposer au monde extérieur, simplement en ne lançant pas les démons correspondants. Pour cela, il suffit de commenter les lignes des services inutiles dans le fichier /etc/inetd.conf ou d'ajouter une ligne « disable = true » dans les fichiers de configuration des services inutiles du répertoire /etc/xinetd.d/ si votre distribution utilise le super-démon xinetd. Faire le ménage dans ces fichiers et dans les fichiers d'initialisation du réseau réduit donc de 90% les risques d'une intrusion dans votre système.
IX-E-1-b. Définition de règles de contrôle d'accès▲
Restreindre le nombre de services accessibles n'est toutefois pas suffisant, il faut également restreindre le nombre des personnes et des machines auxquels les services réseau restants sont proposés. Sur une machine de particulier, l'équation est souvent simple : personne ne doit pouvoir s'y connecter par le réseau, pour quelque service que ce soit ! Bien entendu, certains particuliers possèdent un réseau privé et devront donc affiner cette règle pour ne permettre les connexions que sur le réseau local. Il faut donc être capable d'empêcher les accès provenant de certaines machines, considérées comme peu fiables. La règle est encore une fois très simple : doit être considérée comme dangereuse tout machine étrangère au réseau local.
La manière de procéder dépend du super-démon utilisé. En effet, alors que xinetd permet de définir les adresses des machines autorisées à se connecter de manière précise, inetd ne permet pas de le faire lui-même et requiert l'aide d'un autre démon, le démon tcpd.
IX-E-1-b-i. Restrictions d'accès avec tcpd▲
Le principe de fonctionnement du démon tcpd est le suivant : il s'intercale entre le super-démon inetd et les démons que celui-ci est supposé lancer lorsqu'un client le demande. Ainsi, il lui est possible d'effectuer des vérifications de sécurité primaires, principalement basées sur les adresses IP des clients.
Comme vous pouvez sans doute le constater dans le fichier /etc/inetd.conf de votre système, tcpd est lancé par inetd pour quasiment tous les services, et reçoit en paramètres de la ligne de commande le nom du démon à lancer si la machine cliente en a l'autorisation, ainsi que les paramètres à communiquer à ce démon. L'accès à quasiment tous les services est donc contrôlé par tcpd.
tcpd utilise les deux fichiers de configuration /etc/hosts.allow et /etc/hosts.deny pour déterminer si une machine a le droit d'accéder à un service donné. Le premier de ces fichiers indique quelles sont les machines autorisées à utiliser certains services locaux. Le deuxième fichier indique au contraire les machines qui ne sont pas considérées comme sûres et qui doivent se voir refuser toute demande de connexion sur les services locaux.
Le format de ces deux fichiers est identique. Il est constitué de lignes permettant de définir les règles d'accès pour certains démons. Chaque ligne utilise la syntaxe suivante :
démons : machines [: commande]où démons est une liste de noms de démons, séparés par des virgules, et machines est une liste de noms de machines ou d'adresses IP, également séparés par des virgules. commande est un paramètre optionnel permettant de faire exécuter une action à tcpd lorsque la règle indiquée par cette ligne est prise en compte.
Une règle définie par une de ces lignes est utilisée dès qu'une des machines indiquées dans la liste des machines tente une connexion à l'un des services de la liste des services. Si la règle se trouve dans le fichier /etc/hosts.allow, la connexion est autorisée et le service est lancé par tcpd. Si elle se trouve dans le fichier /etc/hosts.deny, la connexion est systématiquement refusée. Si aucune règle n'est utilisée, la connexion est acceptée par défaut.
Les listes de machines peuvent contenir des noms de machines partiels, et utiliser des caractères génériques. Il est également possible d'interdire la connexion à toutes les machines d'un domaine en ne donnant que le nom de domaine (précédé d'un point). Enfin, des mots clés spéciaux permettent de représenter des ensembles de machines. Par exemple, le mot clé ALL représente toutes les machines et LOCAL représente toutes les machines du réseau local. Le mot clé ALL permet également de représenter l'ensemble des démons dans la liste des démons.
Par exemple, le fichier /etc/hosts.deny devrait contenir la ligne suivante :
# Exemple de fichier /etc/hosts.deny :
ALL : ALLCela permet de garantir que, par défaut, aucune demande de connexion n'est acceptée, ce qui est un comportement sain. Les machines ayant le droit de se connecter doivent être spécifiées au cas par cas dans le fichier /etc/hosts.allow, comme dans l'exemple suivant :
# Exemple de fichier /etc/hosts.allow :
telnetd, ftpd : LOCALCela permet d'autoriser les connexions telnet et ftp pour toutes les machines du réseau local uniquement.
Vous trouverez de plus amples renseignements sur le fonctionnement de tcpd dans la page de manuel hosts_access(5).
Note : Comme vous pouvez le constater si vous comparez les lignes du fichier de configuration /etc/inetd.conf utilisant tcpd et celles qui ne l'utilisent pas, la liste des paramètres passés à tcpd par inetd est différente de celle utilisée pour les démons lancés directement. En effet, elle ne comprend pas le nom de tcpd lui-même, alors que pour les démons, elle contient le nom du démon en premier paramètre. Cette différence provient du fait que le premier argument passé en ligne de commande est le nom du programme lui-même, sauf pour tcpd. En effet, tcpd suppose que ce paramètre contient le nom du démon dont il contrôle l'accès, et non son propre nom.
La sécurité basée sur tcpd suppose que les adresses IP source des paquets reçus sont effectivement les adresses IP des machines qui les ont envoyés. Malheureusement, cette hypothèse ne peut pas être vérifiée pour les adresses autres que les adresses des réseaux considérés comme sûrs (par exemple le réseau local), car le protocole IP n'inclut aucun mécanisme d'authentification. Par conséquent, n'importe qui peut tenter de communiquer avec votre machine au nom d'une autre machine (technique nommée « IP spoofing » en anglais), qu'il aura au préalable mis hors d'état de se manifester (par exemple par une attaque de type DoS, « Denial of Service » en anglais). tcpd tente par défaut de contrôler ce genre de pratique en vérifiant que le nom indiqué par la machine qui se connecte correspond bien à l'adresse IP qu'elle utilise. Ainsi, pour passer cette protection, il faut d'abord infecter un DNS. Cependant, ce genre d'attaque (dite d'interposition) reste courant, surtout sur les réseaux dont les DNS sont insuffisamment protégés (une étude récente a montré que c'était le cas de trois DNS sur quatre en France). Par conséquent, vous ne devez pas vous reposer uniquement sur tcpd et les techniques de pare-feu si vous devez créer un site réellement sûr. En particulier, vous devriez vous intéresser aux réseaux virtuels et au chiffrement des données, choses que l'on décrira dans la Section 9.5.2.2. Le protocole Ipv6 intégrera des mécanismes d'authentification et sera donc nettement plus sûr. Bien entendu, cela dépasse le cadre de ce document.
Le démon tcpd peut également être utilisé avec le démon xinetd. Toutefois, une telle utilisation est superflue, étant donné que xinetd permet de définir ses propres règles de contrôle d'accès.
IX-E-1-b-ii. Restrictions d'accès avec xinetd▲
Le super-démon xinetd intègre d'office un mécanisme de contrôle d'accès similaire à celui utilisé par tcpd. Grâce aux options only_from et no_access, il est possible de spécifier pour chaque service les machines qui sont autorisées à l'utiliser, ou inversement les machines qui doivent être explicitement rejetées.
Il faut toutefois prendre garde au fait que, comme pour tcpd, ne rien dire signifie accepter les connexions provenant de toutes les machines. La règle d'or est donc, encore une fois, de tout interdire par défaut et d'autoriser au compte-goutte les accès aux services ouverts. Pour cela, il suffit d'ajouter la ligne suivante :
only_from =dans la section de définition des options par défaut de xinetd. Avec cette ligne, contrairement à ce qui se passe si rien n'est spécifié, les accès ne sont autorisés qu'à partir d'aucune machine. Autrement dit, ils sont toujours interdits.
Il faut ensuite redonner les droits sur les machines autorisées service par service. Ainsi, les connexions par telnet peuvent être autorisées sur le réseau local (supposé sûr) grâce à la ligne suivante :
only_from += 192.168.0.0/24 127.0.0.1dans la section décrivant le service telnet de la configuration de xinetd.
On prendra garde également au fait que xinetd implémente quelques services internes permettant de l'administrer par le réseau. Il est évident que ces services doivent être désactivés. Ces services sont respectivement les services servers, sercices et xadmin. Leur désactivation se fait classiquement en ajoutant la ligne suivante :
disabled = servers services xadmindans la section defaults du fichier de configuration /etc/xinetd.conf.
IX-E-1-c. Contrôle des utilisateurs au niveau des services▲
Certains services ne peuvent pas être supprimés complètement, tout simplement parce que l'on peut en avoir besoin. Dans ce cas, il faut au moins s'assurer que l'accès à ces services n'est autorisé que pour les utilisateurs qui en ont réellement besoin. La règle est cette fois que l'utilisateur root ne doit pas avoir accès aux services réseau par une connexion non locale. En effet, un pirate attaque toujours par le réseau et, même s'il arrive à trouver le mot de passe d'un utilisateur normal, il lui restera encore pas mal de boulot pour trouver le mot de passe de l'utilisateur root (attention cependant, si vous êtes dans cette situation, il vaut mieux réagir très très vite).
Le service le plus sensible est bien entendu le service de login. Il est possible de fournir le service de login aux connexions extérieures, et il est évident que cela constitue déjà un point d'entrée pour qui peut trouver un mot de passe valide. Il est impératif ici d'interdire une telle connexion à l'utilisateur root. Il reste toutefois concevable que cet utilisateur puisse se connecter sur la console locale (c'est-à-dire, avec votre clavier et votre écran…). Il est donc nécessaire de choisir les terminaux à partir desquels l'utilisateur root pourra se connecter. Ces informations sont stockées dans le fichier de configuration /etc/securetty.
Le format de ce fichier est très simple, puisqu'il est constitué de la liste des terminaux à partir desquels l'utilisateur root peut se connecter, à raison d'un terminal par ligne. Un fichier de configuration /etc/securetty typique contient donc la liste des terminaux virtuels de la machine :
# Exemple de fichier /etc/securetty
tty1
tty2
tty3
tty4
tty5
tty6Il est fortement déconseillé de placer dans ce fichier les autres terminaux (en particulier, les terminaux série ttyS0 et suivants).
Un autre service sensible est le service de téléchargement de fichiers. Il est recommandé d'interdire aux utilisateurs privilégiés les transferts de fichiers par FTP. En effet, si une personne parvient à accéder au système de fichiers, il peut supprimer tous les mécanismes de sécurité. De la même manière que l'on a interdit à l'utilisateur root de se connecter sur les terminaux distants, il faut lui interdire (ainsi qu'aux autres comptes sensibles) les connexions par FTP.
Cette opération peut être réalisée en ajoutant le nom de chaque utilisateur sensible dans le fichier de configuration /etc/ftpusers. Ce fichier a la même structure que le fichier securetty, puisqu'il faut donner un nom d'utilisateur par ligne :
# Exemple de fichier /etc/ftpusers
root
uucp
mailBien entendu, la liste des utilisateurs privilégiés de votre système dépend de la distribution que vous avez installée. Le fichier /etc/ftpusers fourni avec cette distribution est donc, en général, approprié.
IX-E-2. Chiffrement des communications▲
Les protocoles réseau de haut niveau ne garantissent en général pas la confidentialité des données qu'ils transmettent sur le réseau, ce qui signifie qu'elles peuvent être lues par tout le monde. Ils n'en garantissent pas non plus l'intégrité, chacun pouvant les modifier à volonté et fausser ainsi la communication. Ces défauts sont incurables, car ils sont en réalité inhérents au protocole IP lui-même. En effet, ce protocole a été conçu initialement pour assurer l'acheminement des informations, et les protocoles de haut niveau basés sur lui se contentent généralement de la garantie de livraison.
Note : La confidentialité des données est le fait que seules les personnes autorisées peuvent y accéder. L'intégrité des données est le fait que les données n'ont pas été altérées ou modifiées de manière non autorisée. Enfin, l'authenticité des données est le fait que les données sont certifiées comme provenant bien de celui qui prétend en être l'émetteur.
Généralement, le moyen le plus sûr pour garantir la confidentialité des données est de les chiffrer de telle sorte que seuls les destinataires autorisés puissent les déchiffrer et donc y accéder. C'est pour cette raison que la cryptographie, ou science du chiffrement est souvent utilisée pour résoudre les problèmes de sécurité informatique. Mais la cryptographie fournit également les techniques nécessaires pour assurer l'intégrité des données, généralement en calculant une empreinte ou condensé cryptographique des données. En effet, les algorithmes de calcul des empreintes sont conçus pour fournir des résultats très différents même si les données ne sont modifiées que très légèrement. Ainsi, si une personne mal intentionnée modifie un tant soit peu les données, le recalcul de l'empreinte associée indiquera tout de suite la supercherie. Enfin, l'authenticité des données peut être assurée en faisant en sorte que leur émetteur puisse prouver son identité. Cela se fait généralement en exigeant qu'il puisse répondre à une question dont on sait que lui seul connaît la réponse. Toute la difficulté est alors de trouver un système d'authentification où celui qui pose la question ne doit lui-même pas en connaître la réponse (faute de quoi celui qui pose la question pourrait se faire passer pour celui qui doit répondre !).
Note : Il est évident que pour garantir la confidentialité et l'authenticité des données, il faut garantir l'authenticité des interlocuteurs. En effet, sans cela, une tierce personne pourrait s'intercaler entre deux interlocuteurs et faire croire à chacun qu'il est l'autre. Même dans un canal de communication chiffré, cette personne serait en mesure de déchiffrer les messages dans les deux sens, voire même de les modifier et d'en recalculer les empreintes. Cette technique d'interposition s'appelle l'attaque du « man in the middle » (« l'homme du milieu » en Français)
Il est donc nécessaire, du fait des faiblesses des protocoles réseau standards, de recourir à des solutions cryptographiques pour fournir les services de confidentialité, d'authenticité et d'intégrité des données. Parmi ces solutions, les plus utilisées sont sans doute le protocole SSH (abréviation de l'anglais « Secure SHell ») et l'extension IPSec au protocole IP. Cette extension a initialement été développée pour le successeur du protocole IP, à savoir le protocole IPv6, mais a également été adaptée pour fonctionner avec l'implémentation actuelle d'IP.
IX-E-2-a. Principes de base de cryptographie▲
Tout d'abord, commençons par quelques définitions, beaucoup d'articles disponibles actuellement utilisant un vocabulaire imprécis. Le chiffrement (également appelé à tord cryptage), est l'opération qui consiste à transformer une information en clair en une information codée afin d'éviter qu'elle ne puisse être utilisée par une personne non autorisée. Le déchiffrement est l'opération inverse du chiffrement, qui permet donc de retrouver l'information initiale à partir de l'information codée. Le décryptage est l'opération qui consiste à déchiffrer une information sans y être autorisé. La cryptographie est la science qui se charge d'étudier la manière de chiffrer les informations. La cryptoanalyse est l'étude des moyens de décryptage. Cette science va de pair avec la cryptographie, puisqu'elle permet de déterminer la fiabilité des techniques mises en œuvre pour le chiffrement. Enfin, un pirate (également appelé « cracker ») est une personne désirant s'introduire de manière illicite dans un système, ou désirant détourner une application de son contexte d'utilisation normal. Il ne faut pas confondre les crackers avec les hackers, qui sont des personnes extrêmement compétentes en informatique et qui ne font rien de mal (par exemple, les développeurs du noyau Linux sont souvent des hackers).
Il existe un grand nombre de techniques de cryptographie, qui sont plus ou moins efficaces. La première technique, qui est aussi la plus simple et la moins sûre, est celle qui consiste à utiliser un algorithme de chiffrement réversible (ou une paire d'algorithmes ayant un effet inverse l'un de l'autre) pour chiffrer une information. Dans ce cas, la sécurité des données est assujettie au maintien au secret de l'algorithme utilisé. Il est évident que ce type de technique n'est pas utilisable avec les logiciels dont les sources sont diffusées (comme Linux), puisque l'algorithme est alors connu de tout le monde. C'est également la technique la moins sûre, parce qu'il est en général très facile de déterminer cet algorithme. Un exemple d'un tel algorithme est le codage classique qui consiste à décaler toutes les lettres de l'alphabet (A devient B, B devient C, etc.).
Une autre technique se base sur un algorithme connu de tout le monde, mais dont l'effet est paramétré par une clef tenue secrète. Le déchiffrement des informations ne peut se faire que si l'on connaît cette clef. Les algorithmes de ce type sont souvent qualifiés de « symétriques », en raison du fait que la clef utilisée pour le déchiffrement est la même que celle utilisée pour le chiffrement. Cette technique n'est satisfaisante que dans la mesure où les personnes qui communiquent peuvent s'échanger cette clef de manière sûre. La clef utilisée ne devant être connue que des personnes autorisées à participer à la communication, cet échange doit se faire soit de visu, soit dans un canal déjà chiffré (mais dans ce cas, il faut échanger la clef de déchiffrement du canal, et on se retrouve devant le problème de l'œuf et de la poule), soit à l'aide d'un protocole d'échange de clef sûr. Les algorithmes de ce type sont également connus sous le nom d'algorithmes à clef secrète en raison de cette particularité. Il existe un grand nombre d'algorithmes à clef secrète, les plus connus étant DES, AES et IDEA.
La technique la plus sûre actuellement, et aussi la plus rusée, est d'utiliser un algorithme de chiffrement asymétrique. À la différence des algorithmes symétriques, les algorithmes asymétriques utilisent deux clefs différentes et duales pour le chiffrement et le déchiffrement. Ces algorithmes se basent sur des fonctions mathématiques dont la fonction inverse est extrêmement difficile à déterminer sans une information également difficile à calculer. Cette information fait office de clef permettant de retrouver l'information en clair. Toute la ruse ici est que la clef servant au déchiffrement peut ne plus être échangée du tout, ce qui supprime la nécessité de réaliser un échange de clefs généralement risqué. En fait, seule la clef de chiffrement doit (et peut sans crainte) être publiée. C'est en raison de cette propriété que les algorithmes asymétriques sont également appelés algorithmes à clef publique.
Le principe des algorithmes asymétriques est le suivant. Une clef publique, utilisée pour chiffrer les informations, est fournie à tout le monde, et seul celui qui dispose de la clef privée associée à cette clef publique peut déchiffrer le texte. Toute personne qui désire communiquer avec le propriétaire de la clef publique utilise celle-ci pour chiffrer les informations qu'il doit lui transférer. Ainsi, du fait que seul le destinataire dispose de la clef de déchiffrement (sa clef privée), il est le seul à pouvoir récupérer ces informations. Il est donc possible d'échanger des informations de manière sûre avec tous les intervenants en utilisant simplement leurs clefs publiques respectives. Aucun échange d'information sensible n'est effectué en clair. Les algorithmes à clef publique les plus connus sont RSA et DSA.
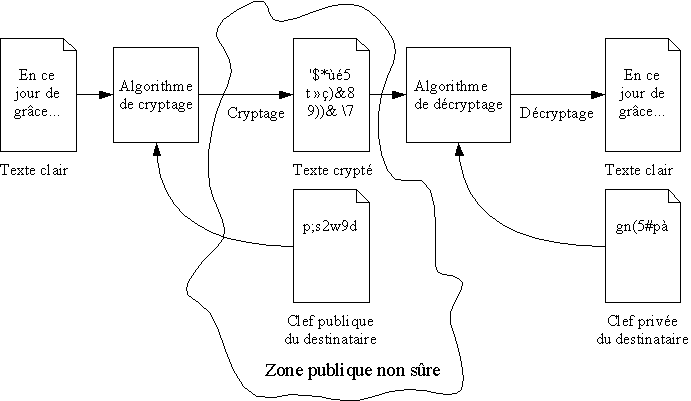
La gestion des clefs des algorithmes à clef publique est techniquement laborieuse, de même que les calculs mis en œuvre par les algorithmes utilisés. Il est donc courant d'amorcer une communication avec un algorithme à clef publique, comme RSA par exemple, puis de l'utiliser pour échanger une clef secrète permettant de poursuivre la communication avec un algorithme symétrique. Il existe également des algorithmes spécialisés dans les échanges de clefs dans un canal non sûr, par exemple l'algorithme Diffie Hellman.
Enfin, il existe des algorithmes de chiffrement à sens unique qui ne permettent pas de retrouver l'information initiale, mais qui sont utilisés pour calculer une empreinte des informations à transférer. Cela permet d'identifier l'information de manière unique. Ces algorithmes sont donc souvent utilisés pour garantir l'intégrité des données diffusées dans un environnement peu sûr. Pour cela, celui qui réalise la diffusion chiffre un condensé des informations diffusées avec sa clef privée. Tout le monde peut donc déchiffrer ce condensé avec la clef publique de cette personne, et vérifier que le message qu'ils reçoivent a bien la même empreinte. Chacun a donc la certitude que le message provient bien de son auteur, car toute modification du message changerait son empreinte d'une part, et il est impossible de chiffrer cette nouvelle empreinte sans connaître la clef privée de l'expéditeur. Les algorithmes de calcul d'empreinte les plus connus sont MD5 et SHA.
Note : Notez que les algorithmes de chiffrement à clef publique nécessitent toujours que l'on soit sûr que l'on utilise la bonne clef publique pour s'adresser à une personne. Or, rien ne nous garantit que la clef publique d'une personne diffusée sur le réseau provienne bien de cette personne ! Il est donc toujours nécessaire d'échanger les clefs publiques de main à main, avec vérification de l'identité de la personne avec qui l'échange se fait. Il est également possible de recourir à une tierce personne digne de confiance et dont on connaît déjà la clef publique pour garantir que la clef que l'on reçoit est bien celle de la personne qui prétend en être le propriétaire. On peut ainsi construire ce qu'on appelle un « réseau de confiance », dans lequel chacun sait que quelqu'un en qui il a confiance, directement ou indirectement, a authentifié ses interlocuteurs.
Bien entendu, tout cela est contraignant. Mais, contrairement aux algorithmes de chiffrement à clef secrète, il n'est pas grave de perdre les clefs échangées avec les algorithmes asymétriques, puisque ces clefs sont destinées à être publiques…
IX-E-2-b. Utilisation de SSH▲
SSH est en réalité un protocole de communication réseau chiffré couplé d'une suite d'outils permettant de l'utiliser. SSH a été initialement développé par une société commerciale, qui diffusait les outils en Open Source et gratuitement pour les particuliers. Ces outils n'étaient toutefois absolument pas libres. Une implémentation libre a donc été développée pour le système FreeBSD, puis portée pour les autres systèmes d'exploitation, dont Linux. Cette implémentation est celle qui est utilisée par la plupart des distributions actuellement, il s'agit de « OpenSSH ». Nous ne décrirons ici que l'utilisation d'OpenSSH.
Pour garantir la confidentialité des données, SSH utilise des techniques de cryptographie avancées. Ces techniques permettent de s'assurer que personne ne peut lire les informations qui circulent sur le réseau d'une part, et de garantir l'authentification des machines auxquelles on se connecte d'autre part. De plus, SSH permet de rediriger les protocoles réseau non chiffrés dans son propre canal de communication, et résout donc la plupart des problèmes de sécurité. SSH a donc pour but premier de remplacer les applications non sûres permettant de se connecter à distance sur une machine ou d'y exécuter des commandes. Les applications ainsi rendues obsolètes sont, entre autres, telnet, rlogin et rsh. Enfin, SSH est également utilisable pour chiffrer automatiquement les connexions X11, ce qui permet d'utiliser l'environnement graphique X Window à distance en toute sécurité.
Note : Officiellement, il est interdit d'utiliser en France des techniques de chiffrement aussi poussées que celles mises en œuvre par SSH, sauf à demander une dérogation. Il y a de fortes pressions pour permettre la légalisation de ces techniques, mais elles n'ont pas encore abouti. Plus précisément, le gouvernement a pris position pour une libéralisation de l'usage de la cryptographie, mais la loi n'a pas encore été votée. Les sinistres événements du 11 novembre 2001 risquent fort de retarder encore, si ce n'est de compromettre, cette libéralisation. En effet, l'argument principal des opposants à cette légalisation est qu'elle permettrait aux truands de chiffrer leurs communications. L'argument est bien entendu fallacieux : comme s'ils attendaient d'en avoir le droit pour le faire…
En fait, il existe une implémentation gratuite (mais non libre) de SSH qui a été déclarée et qui peut donc être utilisée en France. Il s'agit de la version de Bernard Perrot, nommée « SSF », que l'on pourra trouver à l'adresse http://perso.univ-rennes1.fr/bernard.perrot/SSF/index.html. Si vous désirez absolument être sans reproche vis-à-vis de la loi actuellement en vigueur en France, vous devriez remplacer la version d'OpenSSH fournie avec votre distribution (dont l'usage est donc illégal) par SSF. Sachez cependant que SSF restreint la taille des clefs de sessions à 128 bits seulement d'une part (condition sine qua non pour qu'on puisse l'utiliser), qu'il n'est pas utilisable commercialement, et qu'il est susceptible de ne pas être à jour en ce qui concerne les correctifs de bogues et les failles de sécurité que l'on a pu trouver récemment dans SSH ou OpenSSH. La sécurité apportée par SSF est donc très relative, mais c'est mieux que rien du tout.
Il existe deux versions du protocole réseau SSH, qui ont toutes deux été adoptées en tant que standards. La première version souffrait d'un trou de sécurité majeur, qui depuis a largement pu être utilisé. Il ne faut donc surtout pas utiliser cette version et se rabattre systématiquement sur le protocole SSHv2. Ce protocole permet de garantir l'authentification des machines et des utilisateurs et est nettement plus fiable. Aucune attaque n'a permis de le casser à ce jour, sachez toutefois qu'il existe encore des points douteux dans ce protocole qui permettraient, en théorie, de parvenir à s'immiscer dans une communication ou d'en décrypter une partie.
Sachez également que les différentes implémentations de SSH, aussi bien libres que commerciales, sont soumises au même régime que les autres programmes : elles peuvent avoir des bogues et des trous de sécurité qu'un attaquant peut utiliser. De nombreuses attaques ont été découvertes ces derniers temps, aussi est-il recommandé de s'assurer que l'on dispose de la dernière version d'OpenSSH. La dernière version stable est la 3.7.1p1 (les versions antérieures doivent être évitées à tout prix). Cela dit, mener une attaque contre SSH relève le niveau de difficulté nettement au-dessus de ce qui est nécessaire pour pénétrer un système qui ne l'utilise pas.
IX-E-2-b-i. Principes de base de l'authentification SSH▲
La grande difficulté dans les mécanismes d'authentification est d'être capable de prouver son identité sans fournir suffisamment d'information pour que quelqu'un d'autre puisse se faire passer pour soi par la suite. La technique du mot de passe utilisée par les systèmes Unix est absolument insuffisante pour des communications réseau, car elle requiert justement de fournir ce mot de passe. Même si les mots de passe ne sont pas stockés en clair sur la machine (ce qui est la moindre des choses), il est possible de se faire passer pour une tierce personne. En effet, les mécanismes d'authentification comparent souvent une empreinte du mot de passe avec l'empreinte stockée dans les fichiers de définition des mots de passe, mais rien n'empêche un intrus de capter cette empreinte et de l'utiliser directement pour s'authentifier si l'on utilise la même technique en réseau. Il n'a même pas besoin de connaître le mot de passe en clair (cette technique est connue sous le nom d'attaque par « rejeu », car l'attaquant se contente dans ce cas de rejouer la séquence d'authentification). Une solution contre le rejeu est de demander à la personne que l'on cherche à authentifier de chiffrer un message aléatoire avec son mot de passe ou son empreinte, et de vérifier que le résultat qu'il renvoie est bien celui attendu, en chiffrant le même message de son côté. Cette technique est toutefois toujours vulnérable à l'attaque de l'homme du milieu, et elle souffre de l'énorme défaut que l'on doit stocker l'empreinte de son mot de passe sur tous les ordinateurs auxquels on désire se connecter. Cela multiplie d'autant les points de faiblesse : si un pirate s'introduit sur une seule machine, il obtient toutes les empreintes des mots de passe et peut donc se faire passer pour tout le monde !
SSH ne transmet donc ni les mots de passe ni leurs condensés, en clair sur le réseau. Il établit d'abord un canal de communication chiffré à l'aide d'un des algorithmes d'échange de clef (la technique utilisée dépend de la version utilisée du protocole SSH). Une fois le canal chiffré établi, la machine serveur est authentifiée à l'aide de sa clef publique. Pour que cela fonctionne, il faut bien entendu que la clef publique de la machine serveur soit connue du client et ait été authentifiée comme étant bien celle de ce serveur. Inversement, le client peut être authentifié par le serveur. SSH fournit plusieurs possibilités pour cela, les deux plus courantes étant l'authentification par mot de passe et l'authentification par un algorithme à clef publique.
L'authentification par mot de passe est strictement la même que celle utilisée pour le login Unix classique, à la différence près que les informations du mot de passe sont transmises dans le canal chiffré, vers un serveur authentifié. La sécurité de ce mot de passe est donc garantie, et l'attaque de l'homme du milieu ne fonctionne plus. Ce type d'authentification permet donc d'utiliser SSH exactement comme les commandes classiques rsh ou telnet. L'utilisation de SSH est donc complètement transparente pour les utilisateurs.
Cela dit, il est possible de faciliter encore plus l'authentification des clients tout en augmentant le niveau de sécurité, en utilisant également l'authentification par clef publique pour les utilisateurs. Dans ce mode d'authentification, chaque utilisateur dispose également d'un couple de clefs privée et publique. Les clefs publiques de ces utilisateurs sont diffusées dans les comptes des utilisateurs au niveau du serveur. Ainsi, il n'est plus nécessaire de fournir un mot de passe, car le serveur peut authentifier l'utilisateur du seul fait qu'il est le seul à connaître sa clef privée. La connexion est donc automatique (une fois le serveur correctement configuré, bien entendu) et aucun échange d'information sensible comme le mot de passe n'est réalisé (même si le fait que cet échange était réalisé dans un canal chiffré par SSH était déjà une bonne garantie).
Les clefs privées et publiques sont bien entendu stockées sur disque, dans les fichiers de configuration des serveurs et des clients. Il va de soi que si les clefs publiques peuvent être lues, il est impératif que les clefs privées ne soient lisibles que par leurs propriétaires. Les droits d'accès sur les fichiers de configuration doivent donc être fixés de manière correcte pour garantir la sécurité du système. En fait, le point faible du mécanisme d'authentification des clients est toujours au niveau des utilisateurs, qui peuvent perdre leur clef privée ou la communiquer à d'autres sans même savoir qu'ils font une erreur fondamentale (de la même manière qu'ils peuvent choisir un mot de passe trop facile à trouver ou simplement le communiquer à une tierce personne). C'est pour cela qu'il est possible de chiffrer les clefs privées avec un algorithme de chiffrement symétrique. L'utilisateur doit, dans ce cas, fournir une phrase clef à chaque fois qu'il désire réaliser une connexion SSH.
IX-E-2-b-ii. Compilation et installation d'OpentSSH▲
Comme nous l'avons dit plus haut, il est recommandé d'utiliser la dernière version d'OpenSSH, à savoir la version 3.7.1.p1. Il est probable que votre distribution fournisse une mise à jour sur son site, et il est recommandé d'utiliser ces mises à jour.
Si, toutefois, vous désirez effectuer l'installation à partir des fichiers sources, vous pourrez procéder comme suit. Il vous faudra récupérer l'archive des fichiers sources en premier lieu sur le site OpenSSH. Pour Linux, il faut prendre l'archive 3.7.1p1, le 'p' signifiant ici qu'il s'agit d'un portage des sources pour Linux. Une fois cela fait, vous pourrez exécuter la commande suivante dans le répertoire des sources :
./configure --prefix=/usr --sysconfdir=/etc/ssh --with-tcp-wrappers --with-pamCette commande permet de configurer OpenSSH pour qu'il remplace la version existante dans votre système. Elle indique également que le support du démon tcpd doit être activé, ainsi que celui des modules d'authentification PAM (options « --with-tcp-wrapppers » et « --with-pam »). Bien entendu, si votre distribution n'utilise pas ces fonctionnalités, vous devez supprimer ces options.
La compilation et l'installation en soi ne posent pas de problème particulier. Pour les réaliser, il vous suffira d'exécuter les deux commandes suivantes :
make
make installVous constaterez que le programme d'installation génère automatiquement des fichiers de clefs publiques et privées pour votre machine. Nous verrons dans les sections suivantes comment ces clefs peuvent être utilisées.
Note : Vous devrez créer un compte utilisateur « sshd » non privilégié avant d'installer SSH. Ce compte est en effet utilisé par le démon sshd pour réaliser les communications réseau une fois la phase d'authentification réalisée. Cela permet de garantir que, même en cas d'exploitation d'une éventuelle faille de sécurité du démon sshd, l'accès à la machine sera extrêmement limité.
IX-E-2-b-iii. Configuration d'OpenSSH côté serveur▲
OpenSSH utilise un démon nommé sshd pour prendre en charge les requêtes de connexion de la part des clients. Ce démon est à l'écoute des demandes de connexion et effectue les opérations d'authentification du serveur auprès des clients. Il vérifie également les droits du client avant de le laisser utiliser la connexion chiffrée.
Le démon sshd utilise un fichier de configuration général /etc/sshd_config et plusieurs fichiers contenant les clefs publiques et privées de la machine pour les différents protocoles cryptographiques utilisés par les clients. Les protocoles disponibles sont le protocole RSA pour la version 1 du protocole SSH, et les protocoles RSA et DSA pour la version 2. Comme il existe deux fichiers pour les clefs du serveur (un premier fichier lisible par tous les utilisateurs, pour la clef publique, et un fichier lisible uniquement par l'utilisateur root, pour la clef privée), il peut exister au total six fichiers de clefs. Ces fichiers sont nommés respectivement /etc/ssh_host_key et /etc/ssh_host_key.pub pour les clefs privées et publiques du protocole de version 1, et /etc/ssh_host_rsa_key, /etc/ssh_host_rsa_key.pub, /etc/ssh_host_dsa_key et /etc/ssh_host_dsa_key.pub respectivement pour les algorithmes RSA et DSA du protocole SSH de version 2.
Normalement, les fichiers de clefs du serveur ont été créés automatiquement lors de l'installation de SSH. Cependant, si vous installez SSH à partir d'une archive de distribution, ils peuvent ne pas être présents, et vous devrez générer ces clefs vous-même. Pour cela, il faut utiliser la commande ssh-keygen, dont la syntaxe est la suivante :
ssh-keygen [-t type]où type est le type de clef à générer pour le protocole de version 2. Les types disponibles sont rsa et dsa. Pour le protocole de version 1, il ne faut pas utiliser l'option -t, les clefs générées étant forcément des clefs RSA.
Lorsque l'on invoque la commande ssh-keygen, celui-ci demande le chemin du fichier dans lequel la clef privée doit être écrite. Le fichier contenant la clef publique aura le même nom, mais portera l'extension .pub. Vous devez donc saisir le chemin du fichier correspondant au type de clef généré. ssh-keygen demande ensuite le mot de passe à utiliser pour le chiffrement de la clef privée. Dans le cas d'un serveur, il ne faut pas utiliser de mot de passe, car dans ce cas le démon sshd ne pourrait pas accéder à la clef privée de la machine. Il faut donc, dans ce cas, valider simplement sans rien taper.
Une fois les fichiers de clefs du serveur générés, vous pouvez vous intéresser au fichier de configuration sshd_config. Ce fichier de configuration contient un certain nombre d'options qui indiquent les paramètres que le démon doit utiliser. Vous trouverez ci-dessous un exemple de fichier de configuration :
# Paramètres de connexion :
Port 22
ListenAddress 0.0.0.0
KeepAlive yes
# Protocoles utilisables :
Protocol 2
# Chemin sur les fichiers de clefs :
HostKey /etc/ssh_host_rsa_key
HostKey /etc/ssh_host_dsa_key
# Paramètres des messages de traces :
SyslogFacility AUTH
LogLevel INFO
# On définit les modes d'authentification utilisables :
# Authentification par clef publique :
RSAAuthentication no
PubkeyAuthentication yes
IgnoreRhosts yes
RhostsRSAAuthentication no
HostbasedAuthentication no
# Authentification par mot de passe :
PasswordAuthentication no
PermitEmptyPasswords no
# Options générales :
# L'utilisateur root ne doit pouvoir se loguer qu'en local :
PermitRootLogin no
# Utilise le compte non privilégié sshd
# pour les communications réseau :
UsePrivilegeSeparation yes
# On n'autorise la connexion que pour les utilisateurs dont
# les fichiers de configuration sont correctement protégés :
StrictModes yes
# Encapsulation automatique du protocole X :
X11Forwarding yes
X11DisplayOffset 10
# Affichage des informations habituelles au login :
PrintMotd no
PrintLastLog yesComme vous pouvez le constater, un grand nombre d'options sont disponibles. Les options Port et ListenAddress permettent de définir l'adresse IP sur laquelle le démon sshd se mettra en attente de demandes de connexion, ainsi que le port TCP utilisé pour cela. L'adresse 0.0.0.0 signifie ici qu'il doit se mettre en attente sur toutes les adresses de la machine. L'option KeepAlive permet de demander au démon de vérifier régulièrement que la liaison est toujours valide, afin de fermer les connexions automatiquement en cas d'arrêt du client. L'option Protocol permet de spécifier les versions utilisables du protocole SSH. La version 1 étant obsolète, on spécifiera systématiquement la valeur 2 ici. L'option HostKey permet, comme son nom l'indique, de donner les noms des fichiers contenant les clefs pour les différents protocoles d'authentification. Les options SyslogFacility et LogLevel permettent d'indiquer le type et le niveau des messages de traces générés par le démon sshd dans le fichier de traces du système.
Viennent ensuite les options spécifiques aux différents modes d'authentification. Les options RSAAuthentication et PubkeyAuthentication permettent d'activer et de désactiver l'authentification par clef publique des clients, respectivement pour les protocoles SSH de version 1 et 2. Les options IgnoreRhosts, RhostsRSAAuthentication et HostbasedAuthentication permettent de contrôler un protocole d'authentification basé sur l'identité des machines. Ce type d'authentification n'a pas été présenté, car il est extrêmement peu sûr, et il faut impérativement désactiver ces fonctionnalités. Enfin, les options PasswordAuthentication et PermitEmptyPasswords permettent d'activer ou de désactiver l'authentification par mot de passe. Vous êtes libre d'utiliser ou non ces fonctionnalités.
Le fichier de configuration peut également contenir des options complémentaires. Les plus importantes pour la sécurité sont sans doute PermitRootLogin et StrictModes, qui permettent d'interdire la connexion par le réseau à l'utilisateur root d'une part, et d'interdire la connexion aux utilisateurs qui n'ont pas bien fixé les droits d'accès sur leurs fichiers de configuration personnels dans leur compte local (il est donc impossible de garantir que ces fichiers n'ont pas été trafiqués par d'autres utilisateurs pour accéder à leur compte). L'option UsePrivilegeSeparation permet de demander au démon sshd de n'effectuer les communications réseau que dans le compte spécial sshd, compte auquel on n'affectera que le minimum de droits. Cette technique permet de protéger le système contre l'exploitation d'une éventuelle faille de sécurité dans le démon sshd. L'option X11Forwarding permet d'activer l'encapsulation automatique du protocole X et peut être relativement pratique. Le numéro de display auquel les utilisateurs devront connecter leurs applications sera alors décalé du nombre indiqué par l'option X11DisplayOffset. Cette option est utile pour éviter les conflits avec les serveurs X locaux. Vous trouverez de plus amples informations sur le protocole X11 et l'environnement graphique dans le Chapitre 10. Enfin, les options PrintMotd et PrintLastLog permettent de spécifier les informations affichées par le démon sshd lorsque la connexion des clients est acceptée. Il existe bien d'autres options, vous pourrez obtenir de plus amples renseignements dans la page de manuel du démon sshd.
IX-E-2-b-iv. Utilisation d'OpenSSH côté client▲
Les clients peuvent se connecter à un serveur SSH à l'aide de la commande ssh. Cette commande s'utilise exactement de la même manière que les commandes rsh ou rlogin. La syntaxe de la commande ssh est la suivante :
ssh [-l nom] machine [commande]ou :
ssh nom@machine [commande]où nom est ici le nom d'utilisateur à utiliser pour la connexion, et machine la machine distante. Si aucun nom d'utilisateur n'est spécifié, le nom de l'utilisateur sur la machine local est pris par défaut. Il est possible d'exécuter une commande sur la machine distante en la spécifiant après le nom de la machine. Si aucune commande n'est spécifiée, un shell interactif est lancé.
Selon le mode d'authentification du client choisi par le serveur, il peut être nécessaire ou non de définir des clefs pour le client. Tout comme pour les clefs publiques et privées d'un serveur, la génération de ces clefs se fait à l'aide de la commande ssh-keygen. Cependant, contrairement à ce qui se passait pour le serveur, les chemins par défaut proposés pour stocker les clefs sont ici corrects, et il est vivement recommandé de saisir un mot de passe pour chiffrer la clef privée. Les fichiers de clefs générés par ssh-keygen sont les fichiers identity et identity.pub pour le protocole d'authentification RSA de la version 1 du protocole SSH, et les fichiers id_rsa, id_rsa.pub, id_dsa et id_dsa.pub respectivement pour les protocoles RSA et DSA de la version 2 du protocole SSH. Tous ces fichiers sont stockés dans le répertoire .ssh/ du répertoire personnel de l'utilisateur qui les génère. Il va de soi que les fichiers des clefs privées ne doivent pas être lisibles pour les autres utilisateurs, et que les fichiers des clefs publiques ne doivent pas pouvoir être écrits si l'on veut éviter qu'un usurpateur prenne notre place sur notre propre machine.
Afin de bénéficier de l'authentification des serveurs auxquels on se connecte, il faut placer les clefs publiques de ces derniers dans le fichier .ssh/known_hosts. Si, lors d'une connexion à un serveur, la clef publique de celui-ci n'est pas connue, ssh vous le signalera. Il indiquera un message d'erreur indiquant que le serveur auquel on se connecte n'est pas forcément celui qu'il prétend être, et affiche un condensé de sa clef publique. Vous devrez vous assurer que ce condensé est bien celui de la clef publique du serveur auquel vous vous connectez, et ce par un moyen sûr (déplacement physique et connexion en local par exemple). Si vous acceptez cette clef, ssh la placera pour vous dans votre fichier known_hosts, ce qui vous permettra de vous connecter par la suite en toute quiétude. Attention, le fichier known_hosts ne doit pas être accessible en écriture aux autres utilisateurs, car dans ce cas un pirate pourrait capter toutes vos communications !
Si le mode d'authentification utilisé est le mot de passe, ssh vous demandera de saisir le mot de passe du compte distant. Dans ce cas, ssh se comporte exactement comme rsh, à ceci près que votre mot de passe ne circulera pas en clair sur le réseau (quel progrès !).
Si, en revanche, le mode d'authentification utilisé est une authentification par clef publique, alors vous devrez avoir défini vos clefs privées et publiques. Pour que le démon sshd de la machine distante accepte la connexion, vous devrez placer vos clefs publiques dans le fichier authorized_keys du répertoire ./ssh/ du répertoire du compte distant. Cela permettra au démon sshd de s'assurer que c'est bien vous qui vous connectez. Attention, le fichier authorized_keys ne doit pas être accessible en écriture, faute de quoi un autre utilisateur de la machine distante pourrait se connecter en votre nom. Il est également impératif de réaliser l'écriture soi-même dans ce fichier par un moyen sûr (déplacement physique). En aucun cas la communication de votre clef publique à l'administrateur distant ne pourra être considérée comme un moyen sûr pour écrire cette clef : en effet, un pirate pourrait tout aussi bien lui demander d'écrire sa propre clef dans votre fichier !
Vous constaterez qu'un certain nombre de précautions doivent être prises pour les manipulations de clefs. Comme il l'a déjà été indiqué plus haut, le point faible est bel et bien l'authentification des clients. Cela concerne en premier lieu le client bien entendu, dont le compte peut être piraté, mais c'est aussi un trou de sécurité énorme pour le serveur, car une fois le loup dans la bergerie, il peut faire beaucoup de dégâts et chercher à accroître ses droits (jusqu'à devenir root) par d'autres techniques.
IX-E-2-b-v. Création d'un tunnel SSH▲
L'un des principaux avantages de SSH est qu'il est possible de l'utiliser pour encapsuler n'importe quel protocole réseau TCP dans le canal de communication d'une connexion sécurisée. Un tel canal est communément appelé un « tunnel », en raison du fait qu'il est utilisé par les informations sensibles pour traverser un réseau non sûr. Grâce aux tunnels SSH, il est possible d'utiliser tous les protocoles classiques sans avoir à s'inquiéter de la confidentialité des informations transmises. SSH permet même de réaliser cette opération automatiquement pour le protocole X du système de fenêtrage X Window, ce qui est très commode si l'on désire afficher localement les fenêtres graphiques des programmes lancés sur le serveur.
Encapsuler le protocole X dans SSH est donc extrêmement aisé. En effet, il suffit de donner la valeur « yes » à l'option X11Forwarding dans le fichier de configuration du serveur /etc/sshd_config et dans le fichier de configuration des clients (les valeurs par défaut pour tous les utilisateurs peuvent être définies dans le fichier de configuration /etc/ssh_config et être redéfinies par chaque utilisateur dans le fichier config de leur répertoire .ssh/). Si ces options sont activées, SSH se charge de fixer la variable d'environnement DISPLAY de la machine distante à un serveur X virtuel de cette machine. Les programmes X se connectent alors à ce serveur, et celui-ci effectue automatiquement le transfert des communications vers le serveur X du client. Il ne faut donc pas, quand on utilise SSH, modifier manuellement la variable d'environnement DISPLAY. Vous trouverez plus d'information sur X Window dans le Chapitre 10.
Pour les autres protocoles, les opérations ne sont pas réalisées automatiquement par SSH. Il faut donc établir un réseau privé virtuel manuellement. Le principe est le suivant : les programmes clients sont paramétrés pour se connecter sur un port local différent de celui utilisé habituellement pour leur protocole. Ainsi, ils ne s'adressent pas directement au serveur distant, mais plutôt à un proxy local établi par SSH pour l'occasion. Ce proxy établit un canal de communication chiffré avec le démon sshd de la machine distante. Toutes les informations du protocole encapsulé passent alors par le canal chiffré, et le démon sshd de la machine distante retransmet ces informations au service distant auquel le client devait se connecter.
Tout ce mécanisme ne fonctionne que parce qu'il est possible de rediriger les clients sur un port réservé par SSH sur leur machine locale. Cette redirection peut être initiée aussi bien du côté serveur que du côté client, lors de la connexion. Du côté du client, la redirection de port peut être réalisée avec la commande suivante :
ssh -Llocal:serveur:port machine [commande]où local est le port de la machine locale auquel il faudra se connecter pour accéder au service distant, fonctionnant sur le port port de la machine serveur. Cette commande ouvre une session SSH sur la machine machine (qui, normalement, est la même que serveur), et réalise la redirection du flux destiné au port local dans le canal de cette session.
Il faut bien comprendre que cette redirection se fait en plus de la connexion SSH, et que la syntaxe donnée ci-dessus ouvre une connexion sur la machine distante (ou exécute la commande spécifiée en paramètre, s'il en est spécifié une). Si l'on désire simplement établir un tunnel, on peut refermer la session juste après avoir lancé le programme qui doit utiliser ce tunnel. En effet, SSH maintient le tunnel ouvert tant qu'un programme détient une connexion sur le port redirigé. On peut aussi exécuter une commande sleep sur un délai arbitraire, qui permettra de se connecter sur le port redirigé et qui se terminera automatiquement.
Du côté serveur, la syntaxe est similaire. Cette fois, la commande permet d'indiquer le port que le client devra utiliser pour accéder à un service non sécurisé du serveur. La syntaxe à utiliser est la suivante :
ssh -Rport:client:local machine [commande]où port est le port que le client devra utiliser, client est la machine cliente, et local est le port local utilisé par le service que l'on veut exposer de manière sécurisée au client. Encore une fois, cette commande ouvre une connexion SSH, il faut donc spécifier la machine à laquelle on se connecte (en l'occurrence, le client). Une commande peut être spécifiée de manière optionnelle, s'il n'y en a pas, un shell sera lancé sur la machine distante.
Note : Prenez bien conscience que SSH ne s'assure du chiffrement que des données transmises sur le réseau. Si la machine cliente ou la machine serveur ne sont pas correctement configurées, un pirate peut espionner les communications réseau internes à cette machine. Pour éviter ce type de risque, il faut utiliser des protocoles réseau eux-mêmes chiffrés. Autrement dit, une fois sorti du tunnel SSH, vous vous exposez à nouveau aux risques d'intrusion.
Il existe d'autres méthodes de tunneling sous Linux, qui sont sans aucun doute plus ergonomiques que SSH. En effet, non seulement les tunnels SSH ne peuvent pas être créés automatiquement (ils nécessitent une connexion), mais en plus les connexions SSH se terminent dès que le dernier client disparaît. En fait, les fonctionnalités de SSH sont un plus, mais elles ne sont pas destinées à remplacer des solutions plus adaptées pour réaliser des tunnels. Vous trouverez plus d'informations sur les réseaux privés virtuels ci-dessous.
IX-E-2-c. Utilisation d'IPSec▲
Le protocole IPSec est une extension du protocole IP qui permet de répondre aux besoins d'authentification et de confidentialité, grâce aux techniques de cryptographie. Les principes utilisés sont les mêmes que pour SSH, mais ils sont mis en pratique au plus bas niveau, ce qui fait que tous les protocoles de haut niveau en bénéficient automatiquement.
IX-E-2-c-i. Fonctionnement d'IPSec▲
IPSec définit des protocoles complémentaires permettant d'encapsuler les données transférées dans les paquets IP et assurant les services d'authentification et de confidentialité. Le protocole AH (abréviation de l'anglais « Authentication Header ») permet, comme son nom l'indique, d'assurer que les machines sont bien celles qu'elles prétendent être. Cela permet de supprimer tous les risques d'attaque de l'homme du milieu. Le protocole AH permet également d'assurer l'intégrité des données. En revanche, il n'en assure pas la confidentialité. Le protocole ESP (abréviation de l'anglais « Encapsulating Security Payload ») permet d'assurer cette confidentialité. En revanche, contrairement à ce que de nombreuses documentations affirment, il ne permet pas d'assurer l'authenticité des interlocuteurs, ce qui fait que la confidentialité peut être brisée par une attaque de l'homme du milieu. Il est donc nécessaire d'utiliser les deux protocoles si les interlocuteurs ne sont pas authentifiés de manière physique. Ces deux protocoles permettent également de prévenir les attaques par rejeu au niveau protocolaire, car ils utilisent un numéro de séquence dont la prédétermination est très difficile pour chaque paquet échangé.
Note : En réalité, le protocole ESP peut également assurer l'authenticité des données, même s'il ne permet pas d'assurer l'authenticité des interlocuteurs. Cette fonctionnalité peut être utile si l'authenticité des machines est assurée par un autre mécanisme. Toutefois, cette condition n'est généralement pas vérifiée et il faut utiliser le protocole AH pour authentifier les machines. De ce fait, le mécanisme d'authentification d'ESP est rarement utilisé.
AH et ESP peuvent être utilisées dans deux modes différents : le mode transport et le mode tunnel. Le mode transport est le mode de communication natif, dans lequel les en-têtes des protocoles AH et ESP sont insérés entre l'en-tête IP et ses données. De ce fait, les protocoles de haut niveau sont simplement encapsulés dans les protocoles AH et ESP. Le mode tunnel, quant à lui, permet de créer un réseau virtuel complet, en encapsulant la communication entre les interlocuteurs dans un canal chiffré. Ce sont donc les paquets IP de la communication qui sont eux-mêmes encapsulés dans les protocoles AH et ESP.
IPSec utilise les algorithmes de cryptographie symétriques pour assurer ces fonctionnalités. Par exemple, l'authenticité des machines et l'intégrité des données sont garanties par le protocole AH grâce à la génération de condensés cryptographiques paramétrés par une clef privée. Seules les machines partageant cette clef peuvent donc communiquer avec ce protocole, et toute modification des données serait détectée lors de la vérification de la signature. De même, ESP assure la confidentialité des données en les chiffrant avec un algorithme de chiffrement à clef privée.
Chaque canal de communication IPSec peut utiliser ses propres paramètres. Bien entendu, il est hors de question de transférer ces paramètres (et encore moins les clefs privées utilisées !) dans chaque paquet IP ! IPSec identifie donc ces paramètres par un numéro d'identification (appelé «« Security Parameter Index », « SPI » en abrégé), grâce auquel chaque interlocuteur peut retrouver les paramètres de la connexion chiffrée. L'association entre le SPI et ces paramètres est appelée une « SA » (abréviation de l'anglais « Security Association »). Les associations de sécurité sont stockées sur chaque machine dans une base de données que l'on appelle la SAD (de l'anglais « SA Database »).
Les associations de sécurité ne permettent que de définir la manière dont les communications doivent être protégées. Cela dit, une machine n'est pas obligée de chiffrer toutes ses connexions, et l'on peut parfaitement vouloir ne chiffrer les communications qu'entre deux machines, ou que pour certains protocoles. Il est donc également nécessaire de définir quelles communications doivent être chiffrées. Cela se fait grâce à une politique de sécurité (« Security Policy » en anglais, « SP » en abrégé). Les politiques de sécurité sont également stockées dans une base de données sur chaque machine, base de données que l'on appelle la « SPD » (abréviation de « SP Database »).
Bien entendu, la définition des clefs secrètes, des associations et des politiques de sécurité peut devenir une opération très lourde sur de grands réseaux. En effet, il est nécessaire de définir des clefs privées pour chaque couple de machines. Par conséquent, un protocole de gestion des clefs et des associations de sécurité a été défini pour automatiser l'établissement des connexions. Ce protocole est le protocole « ISAKMP » (abréviation de l'anglais « Internet Security Association and Key Management Protocol »). Comme SSH, ce protocole s'appuie sur les algorithmes de cryptographie asymétriques pour échanger les clefs privées et définir les associations de sécurité de manière sûre avec des machines authentifiées. Ainsi, grâce à ce protocole, seuls les politiques de sécurité et les couples de clefs publiques/privées des machines doivent être définis. Les associations de sécurité et les clefs privées n'ont plus à être manipulées.
IX-E-2-c-ii. Configuration manuelle d'IPSec en mode transport▲
La configuration manuelle d'IPSec reste intéressante, car elle permet de bien saisir la manière dont les opérations se déroulent. Elle se fait simplement en définissant les SA et les SP sur chaque machine, à l'aide de l'outil setkey. Cet outil peut être retrouvé sur le site Web consacré à IPSec.
Les associations et les politiques de sécurité peuvent être spécifiées directement en ligne de commande si on lance setkey avec l'option -c. Toutefois, la manière la plus simple de charger les associations et les politiques dans les bases de données du système est de les définir dans un fichier de configuration et de demander à setkey de le lire en lui fournissant le chemin sur ce fichier à l'aide de l'option -f. En général, ce fichier de configuration est placé dans le répertoire /etc/ et se nomme ipsec.conf.
Les commandes acceptées par setkey sont nombreuses. Le fichier de configuration d'exemple suivant vous en donnera un aperçu :
#!/usr/sbin/setkey -f
# Vide la base de données des SAs :
flush;
# Vide la base de données des SPs :
spdflush;
# Définit les SAs pour le protocole AH :
# add source dest protocole SPI algo clef
add 170.20.57.31 170.20.58.40 ah 0x200 \
-A hmac-md5 0x848255320c7fd11b6082f9628f078af7;
add 170.20.58.40 170.20.57.31 ah 0x201 \
-A hmac-md5 0xcd23ef4b73ea54b626d16092293a298a;
# Définit les SAs pour le protocole ESP :
# add source dest protocole SPI algo clef
add 170.20.57.31 170.20.58.40 esp 0x300 \
-E 3des-cbc 0xe6933d365096e13be514ea1d881d87371100b15119e2ffb9;
add 170.20.58.40 170.20.57.31 esp 0x301 \
-E 3des-cbc 0xb2b630c9e9692c36d248b7206bda17c47f772f96290ac05f;
# Définit les politiques :
# spadd source dest protocole -P politique
# politique = direction action regles
# regle = ipsecp/mode/options/niveau
# options = règles de définition des tunnels
# niveau = use ou require
spdadd 170.20.57.31 170.20.58.40 any -P out ipsec
esp/transport//require
ah/transport//require;
spdadd 170.20.58.40 170.20.57.31 any -P in ipsec
esp/transport//require
ah/transport//require;Ce fichier permet de décrire les associations de sécurité utilisées pour communiquer entre deux machines d'adresses 170.20.57.31 et 170.20.58.40, ainsi que la politique de sécurité de la machine 170.20.57.31. Bien que largement commenté, ce fichier requiert quelques explications complémentaires.
Tout d'abord, la première ligne permet de considérer ce fichier comme un fichier exécutable, dont l'interpréteur est la commande setkey elle-même. Les deux lignes suivantes permettent de vider les bases de données contenant les associations et les politiques de sécurité. Attention, cela a pour conséquence de désactiver complètement IPSec, les services réseau qui doivent être protégés ne doivent donc pas être lancés lorsque ce fichier est interprété.
Viennent ensuite les définitions des associations de sécurité utilisées par les protocoles AH et ESP. Ces associations doivent être définies strictement de la même manière sur les deux machines pour lesquelles la liaison est sécurisée. Elles sont simplement ajoutées à la base de données des associations à l'aide de la commande add de setkey. Cette commande prend en paramètre les adresses IP source et destination des machines intervenant dans la communication sécurisée, suivies du nom du protocole pour lequel l'association est définie (à savoir, ah ou esp), suivi de l'identifiant de l'association (le « SPI »), et pour finir des options relatives au protocole.
Les options des protocoles dépendent évidemment de ceux-ci. Le protocole AH n'accepte que l'option -A, qui permet de spécifier l'algorithme d'authentification à utiliser (ici, l'algorithme MD5). ESP quant à lui peut également accepter l'option -E, qui permet de spécifier un algorithme de chiffrement des données. Il est inutile de spécifier un algorithme d'authentification pour ESP si l'on utilise également le protocole AH, comme c'est le cas ici. Il est également possible de n'utiliser que le protocole ESP et de lui demander de réaliser à la fois l'authentification et le chiffrement des communications. Toutefois, comme on l'a dit plus haut, cela nécessite d'avoir déjà une authentification des machines (ce qui n'est pas assuré en général, une adresse IP pouvant être vampirisée par un pirate).
Les algorithmes utilisables sont variés et dépendent des options que vous avez spécifiées dans la configuration du noyau. Ceux utilisés ici sont relativement fréquents, à savoir MD5 pour l'authentification et le triple DES pour le chiffrement. Vous remarquerez que ces algorithmes ont besoin d'une clef secrète pour fonctionner. Dans le fichier d'exemple précédent, cette clef est spécifiée en hexadécimal (c'est-à-dire en base 16). La taille des clefs dépend de l'algorithme utilisé. Pour MD5, il vous faudra utiliser une clef de 16 octets, et pour le triple DES, une clef de 24 octets. Les clefs de cet exemple ont été générées par lecture du fichier spécial de périphérique /dev/random, dont le but est de fournir des données aléatoires, avec la commande suivante :
dd if=/dev/random count=n bs=1 | xxd -psoù n est le nombre d'octets à créer. Bien entendu, ces clefs devant rester secrètes, le fichier de configuration ipsec.conf ne doit pas être accessible en lecture aux autres utilisateurs que l'administrateur.
Note : Vous remarquerez que les associations de sécurité utilisent deux clefs privées distinctes pour les deux directions du flux de données entre les machines qui communiquent par IPSec. Cela n'est pas une obligation, on peut très bien utiliser la même clef pour les deux directions.
Comme il l'a déjà été indiqué, définir les associations de sécurité ne suffit pas pour sécuriser les communications. En effet, il est également nécessaire de définir la politique de sécurité. Cela est réalisé à l'aide de la commande spdadd. Cette commande prend en paramètre l'adresse source et l'adresse destination, le protocole ou le port qui doit être sécurisé (any signifiant que toutes les communications doivent être sécurisées), et la politique de sécurité elle-même. Cette politique permet d'indiquer la direction du trafic réseau (in signifiant le trafic entrant et out signifiant le trafic sortant), et ce que l'on doit faire des données. L'option ipsec indique qu'elles doivent être sécurisées par IPSec. L'option discard permet d'interdire le trafic entre les machines, et l'option none permet d'autoriser ce trafic et de laisser les communications se faire classiquement.
Si l'on indique qu'IPSec doit être utilisé, il faut indiquer, respectivement pour AH et ESP, le mode de fonctionnement (ici, transport) et le niveau de sécurité exigé. La valeur utilisée est généralement require, ce qui permet de n'accepter les communications que si elles se font par IPSec. Vous trouverez le détail des autres options dans la page de manuel de setkey
Ainsi, la première ligne spdadd du fichier donné en exemple ci-dessus indique que tout le trafic sortant de 170.20.57.31 et allant vers 170.20.58.40 doit être encapsulé en mode transport dans les protocoles AH et ESP, en utilisant les associations de sécurité définies précédemment. De même, la deuxième ligne spdadd indique que tout le trafic entrant dans 170.20.57.31 et en provenance de 170.20.58.40 doit être sécurisé par IPSec.
Vous constaterez que les adresses IP sources et destination sont inversées dans les deux commandes, parce que la direction indiquée est inversée et que l'on ne peut pas définir, sur la machine 170.20.57.31, les règles à appliquer sur la machine 170.20.58.40. Bien entendu, sur la machine 170.20.58.40, ces directions devront être échangées. Ainsi, pour reprendre l'exemple, les lignes permettant de définir la politique de sécurité sur cette machine doivent être les suivantes :
# Définit la politique de sécurité sur 170.20.58.40 :
spdadd 170.20.57.31 170.20.58.40 any -P in ipsec
esp/transport//require
ah/transport//require;
spdadd 170.20.58.40 170.20.57.31 any -P out ipsec
esp/transport//require
ah/transport//require;Note : Pour que les communications se fassent par IPSec, il est nécessaire que vous laissiez passer le trafic AH ou ESP au travers de votre pare-feu. Le protocole AH utilise le numéro de protocole 51 et le protocole ESP le numéro 50.
IX-E-2-c-iii. Configuration manuelle d'IPSec en mode tunnel▲
La configuration d'IPSec en mode tunnel est similaire à celle utilisée pour le mode transport. Elle est toutefois légèrement plus compliquée, puisqu'il est nécessaire de spécifier les adresses des passerelles entre lesquelles le tunnel sera établi. Le fichier de configuration suivant donne un exemple de définition de tunnel IPSec utilisant les adresses 192.168.20.1 et 192.168.20.2, entre deux machines d'adresses 170.20.57.31 et 170.20.58.40 :
#!/usr/sbin/setkey -f
# Vide la base de données des SAs :
flush;
# Vide la base de données des SPs :
spdflush;
# Définit les SAs pour les en-têtes :
# add source dest protocole SPI algo clef
add 170.20.57.31 170.20.58.40 ah 0x200 -m tunnel -A hmac-md5 0x848255320c7fd11b6
082f9628f078af7;
add 170.20.58.40 170.20.57.31 ah 0x201 -m tunnel -A hmac-md5 0xcd23ef4b73ea54b62
6d16092293a298a;
# Définit les SAs pour les paquets :
# add source dest protocole SPU algo clef
add 170.20.57.31 170.20.58.40 esp 0x300 -m tunnel -E 3des-cbc 0xe6933d365096e13b
e514ea1d881d87371100b15119e2ffb9;
add 170.20.58.40 170.20.57.31 esp 0x301 -m tunnel -E 3des-cbc 0xb2b630c9e9692c36
d248b7206bda17c47f772f96290ac05f;
# Définit les politiques :
# spadd source dest protocoles politique
# politique = direction action regles
# regle = ipsecp/mode/options/niveau
# options = règles de définition des tunnels
# niveau = use ou require
spdadd 192.168.20.2 192.168.20.1 any -P in ipsec
esp/tunnel/170.20.58.40-170.20.57.31/require
ah/tunnel/170.20.58.40-170.20.57.31/require;
spdadd 192.168.20.1 192.168.20.2 any -P out ipsec
esp/tunnel/170.20.57.31-170.20.58.40/require
ah/tunnel/170.20.57.31-170.20.58.40/require;Ce fichier commence par définir les associations de sécurité décrivant comment le trafic réseau doit se faire entre les machines 170.20.57.31 et 170.20.58.40. La première différence avec le mode transport est l'utilisation de l'option -m, qui prend en paramètre le mode de communication. Ici, il est demandé que tout le trafic IP, et non pas les communications elles-mêmes, soit encapsulé dans les protocoles AH et ESP. Cela a effectivement pour effet de faire un tunnel « IP over IPSec ».
La deuxième différence provient ensuite de la définition des politiques de sécurité. À présent, ces politiques ne portent plus sur les véritables adresses réseau des machines (à savoir 170.20.57.31 et 170.20.58.40), mais sur les adresses des interfaces réseau permettant d'accéder au tunnel (respectivement 192.168.20.1 et 192.168.20.2). De plus, les informations de routage pour le trafic dans le tunnel sont spécifiées dans les règles de la politique : il doit passer dans le tunnel IPSec établi entre 170.20.57.31 et 170.20.58.40.
Note : Du fait que les communications doivent être transférées via le tunnel IPSec, il est nécessaire d'autoriser le routage sur les deux machines du tunnel. Cela se fait en autorisant le routage au niveau du pare-feu et en exécutant la commande suivante :
echo 1 > /proc/sys/net/ipv4/ip_forwardLes directions indiquées dans les politiques correspondent à la machine 170.20.57.31. Bien entendu, ces directions devront être inversées sur la machine 170.20.58.40 pour rendre la communication symétrique.
IX-E-2-c-iv. Autoconfiguration avec ISAKMP▲
La configuration manuelle d'IPSec est réalisable pour l'établissement d'un tunnel ou pour le chiffrement des connexions entre deux ou trois machines, mais au-delà de ce nombre, elle devient très vite lourde et contraignante. En effet, il est nécessaire de définir une clef privée de communication pour chaque couple de machines, ce qui peut faire un grand nombre de clefs. Par exemple, pour un réseau de trois machines, pas moins de six clefs AH et ESP sont nécessaires (douze si ces clefs ne sont pas utilisées pour les deux sens du trafic) !
C'est pour cette raison que le protocole d'échange de clef ISAKMP a été développé. Ce protocole utilise le port 500 du protocole UDP pour définir les associations de sécurité à utiliser pour les connexions IPSec, et de les renouveler régulièrement afin d'accroître la sécurité des communications. En effet, utiliser toujours la même clef dans une association de sécurité peut permettre à un attaquant de la calculer en observant certains paquets réseau dont il peut deviner une partie du contenu, par exemple les paquets de demandes de connexion TCP.
Pour l'établissement des associations de sécurité, le protocole ISAKMP utilise plusieurs phases. La première phase permet d'établir une association de sécurité de contrôle entre les deux machines, par l'intermédiaire de laquelle les autres associations de sécurité seront établies. La deuxième phase est l'établissement des associations de sécurité utilisées pour les communications.
La première phase peut être réalisée selon plusieurs modes d'authentification. Le mode « principal » est le mode le plus sûr. Le mode « agressif » est plus économe en terme de trafic réseau, mais il n'est pas utilisable de manière fiable en pratique. Dans chacun de ces modes, plusieurs techniques d'authentification sont utilisables, mais, en raison d'erreurs de conception du protocole ISAKMP, seule l'authentification basée sur les mécanismes de clefs publiques est fiable. De ce fait, le protocole ISAKMP fonctionne de manière tout à fait similaire à OpenSSH, puisqu'il commence par établir une association de sécurité privée à partir des clefs publiques et privées, puis il utilise ce canal chiffré pour effectuer les échanges des associations de sécurité IPSec des communications. Dans ce type de configuration, il n'est plus nécessaire de définir qu'un couple de clefs privée et publique par machine.
Note : Pour ceux qui sont intéressés par les problèmes de sécurité, les autres mécanismes d'authentification proposés par le protocole ISAKMP sont :
- l'authentification par signature, qui est sujette à l'attaque de l'homme du milieu ;
- et l'authentification par secret partagé.
Ce dernier type d'authentification est très problématique, car il ne résout pas le problème de la gestion des clefs d'une part, et il requiert de connaître l'identité des machines qui se connectent d'autre part. Cela implique que les adresses IP des machines qui se connectent soient fixes dans le mode principal, et que les informations d'identité soient transférées sur le réseau pour éviter d'avoir à connaître ces adresses IP dans le mode agressif. Cela n'est pas le plus grave, le mode agressif transférant également des données chiffrées dont on connaît le contenu sur le réseau, permettant ainsi à un attaquant de faire une attaque par dictionnaire et de trouver le secret partagé.
Sous Linux, le protocole ISAKMP est implémenté par le démon racoon. racoon utilise des certificats x509 pour authentifier les machines, aussi vous faudra-t-il en générer pour chacune de vos machines.
Les certificats x509 sont des fichiers contenant l'identité d'une personne ainsi que sa clef publique, ce qui permet donc de l'authentifier de manière fiable à condition que l'on soit sûr du certificat provient bien d'elle. Pour s'assurer de cela, il est courant de faire signer le certificat par une autorité de certification en laquelle on a confiance et dont le rôle est de bien s'assurer que la personne qui demande la signature de son certificat est bien celle qu'elle prétend être (moyennant finances bien entendu). Il est possible de signer soi-même ses propres certificats, ce qui ne résout bien sûr pas le problème de l'authenticité du certificat, mais permet au moins de s'assurer qu'il n'a pas été modifié par une tierce personne. Cela suppose bien entendu que le problème du transfert de l'empreinte du certificat vers le destinataire est résolu.
Les certificats peuvent être créés et manipulés à l'aide de l'outil OpenSSL, dont la ligne de commande est malheureusement relativement complexe. La création d'un nouveau certificat se fait typiquement avec la commande suivante :
openssl req -new -nodes -newkey rsa:1024 -sha1 \
-keyform PEM -keyout machine1.private -outform PEM -out requete.pemCette commande permet de créer une requête de certification d'une clef publique RSA de 1024 bits avec l'algorithme de génération de condensé SHA1, et de stocker la clef privée correspondante dans le fichier machine1.private. La requête elle-même est stockée dans le fichier requete.pem. Des informations permettant de vous identifier vous seront demandées, et seront incluses dans la requête de certification.
La création du certificat se fait ensuite simplement, en signant la requête de certification. Nous pouvons le faire nous-mêmes, en signant la requête avec la clef privée que l'on vient de créer. Pour cela, il faut utiliser la commande suivante :
openssl x509 -req -in requete.pem \
-signkey machine1.private -out machine1.publicUne fois cette opération effectuée, vous pouvez vous débarrasser du fichier de requête de certification (c'est-à-dire du fichier requete.pem). Vous disposerez alors d'un couple de clef privée/publique dans les fichiers machine1.private et machine1.public.
Une fois que vous aurez créé vos clefs pour toutes vos machines, vous pourrez les distribuer sur vos différentes machines. Chaque machine doit bien entendu disposer de sa clef privée, ainsi que de l'ensemble des clefs publiques des autres machines. L'échange des clefs publiques est l'opération sensible, puisqu'il s'agit de s'assurer que les clefs reçues sont bien celles que l'on a émises. Pour cela, on pourra utiliser un condensé de la clef et s'assurer que ce condensé est bien le même après échange. Attention toutefois, il faut être certain que le condensé soit échangé de manière sûre. OpenSSL vous permet d'obtenir un condensé de vos clefs publiques avec la commande suivante :
openssl dgst clef.publicoù clef.public est la clef dont on désire obtenir le condensé.
Le démon racoon utilise le fichier de configuration /etc/racoon.conf pour décrire la manière dont les différentes phases de la négociation des associations de sécurité doivent être faites. Il est possible de définir des options différentes pour différents clients, identifiés par leurs adresses IP. Toutefois, en raison de l'utilisation courante des adresses IP dynamiques, une configuration implicite doit souvent être donnée. Vous trouverez ci-dessous un exemple de fichier de configuration racoon.conf :
path certificate "/etc/ssl/certs";
remote anonymous
{
exchange_mode main;
certificate_type x509 "neptune.public" "neptune.private";
verify_cert off;
my_identifier asn1dn;
peers_identifier asn1dn;
proposal
{
encryption_algorithm 3des;
hash_algorithm md5;
authentication_method rsasig;
dh_group modp1024;
}
}
sainfo anonymous
{
pfs_group modp1024;
encryption_algorithm 3des;
authentication_algorithm hmac_md5;
compression_algorithm deflate;
}La première ligne indique le chemin du répertoire dans lequel les fichiers de clefs publiques des clients se trouveront, ainsi que les fichiers de clefs publique et privée de la machine locale. La section remote permet de définir les options d'authentification d'un client pendant la première phase du protocole ISAKMP. Le mot-clé anonymous indique ici que tous les clients pour lesquels une section remote plus spécifique n'est pas disponible devront utiliser cette section. C'est donc la section à utiliser pour tous les clients disposant d'une adresse IP dynamique.
La définition de la première phase du protocole contient les directives suivantes :
- la directive exchange_mode, qui indique le mode de fonctionnement à utiliser pendant cette phase (le mode principal est choisi ici, parce que c'est le seul qui soit réellement sûr) ;
- la directive certificate_type, qui permet d'indiquer que le mécanisme d'authentification utilise des certificats X509 (grâce à l'option x509) ;
- la directive verify_cert, qui permet d'indiquer si les certificats manipulés doivent être vérifiés auprès d'une autorité de certification ou non (la configuration présentée ici ne le permet pas, car nous avons signé nous-mêmes nos certificats) ;
- les directives my_identifier et peers_identifier, qui indiquent la manière dont les machines sont identifiées (leur option asn1dn indique que les informations qui ont été demandées lors de la création des certificats des machines sont utilisées pour retrouver leurs certificats) ;
- et enfin, la directive proposal, qui permet de fournir les paramètres cryptographiques utilisés pour l'association de sécurité de contrôle négociée pendant la première phase du protocole ISAKMP.
Les paramètres de l'association de sécurité de contrôle permettent de spécifier l'algorithme de chiffrement et l'algorithme de génération des signatures (directives encryption_algorithm et hash_algorithme respectivement), ainsi que la méthode d'authentification des machines (utilisation du protocole RSA, directive authentication_method). La directive dh-group permet de fournir un paramètre à l'algorithme d'échange de clefs Diffie Hellman, utilisé lors de l'échange des clefs privées.
La section sainfo permet de définir les paramètres des associations de sécurité négociées pendant la deuxième phase du protocole ISAKMP. Son format est semblable à la section de définition de l'association de sécurité de contrôle vue précédemment. Toutefois, une différence importante est que la méthode d'authentification est à présent basée sur un secret partagé et non plus sur le mécanisme des clefs publiques et privées des machines. De ce fait, l'algorithme de génération de signatures utilisé par le protocole AH nécessite une clef secrète échangée pendant la première phase. Ce n'est donc plus un simple algorithme de génération d'empreintes. La directive hmac_md5 permet d'utiliser un algorithme MD5 modifié pour être paramétré par la clef secrète.
Vous noterez que toutes ces informations permettent de définir la manière dont les associations de sécurité doivent être générées. Cependant, ces associations de sécurité ne sont pas forcément utilisées : il faut pour cela définir la politique de sécurité. Cette opération peut bien entendu se faire avec setkey. Le fichier de configuration ipsec.conf d'un serveur ressemble alors à celui-ci :
spdadd 0.0.0.0/0 serveur any -P in ipsec
esp/transport//require
ah/transport//require;
spdadd serveur 0.0.0.0/0 any -P out ipsec
esp/transport//require
ah/transport//require;Les fichiers de configuration ipsec.conf des clients devront avoir des directions de trafic inversées. Vous noterez que les adresses spécifiées pour les clients utilisent des plages d'adresses dans les commandes d'ajout de règles de politique de sécurité. En effet, on ne sait a priori pas quelles sont les adresses de ces clients, car ils auront généralement une adresse IP allouée dynamiquement. La seule adresse connue est en général celle du serveur, référencée ici par le nom de machine serveur. Si l'adresse du serveur est elle aussi dynamique, la configuration est plus contraignante, car il faut que toutes les communications se fassent par IPSec (et les clients ne peuvent plus se connecter qu'aux serveurs qu'ils connaissent).
Il est également possible de demander à racoon de définir lui-même la politique de sécurité, lorsque des tentatives de connexion ont lieu. Cela peut être réalisé à l'aide de la directive generate_policy de la section remote.
Une fois le fichier de configuration racoon.conf défini, il ne reste plus qu'à lancer racoon. Ceci peut se faire avec la commande suivante :
racoon -f /etc/racoon.confL'option -f permet de lui indiquer le fichier de configuration qu'il doit utiliser. Si vous désirez lancer racoon en avant-plan pour pouvoir déboguer votre configuration, vous pouvez utiliser -F, et augmenter le niveau de traces avec l'option -d.
IX-F. Configuration des fonctions serveur▲
En général, les gens ne voient Internet que du point de vue client en termes d'architecture client / serveur. Cela signifie qu'ils se contentent de se connecter à Internet, et n'utilisent que des logiciels clients qui communiquent avec des serveurs situés sur Internet. Ce mode d'utilisation est de loin le plus courant et celui qui convient à la majorité des gens, qui n'ont en général même pas conscience de l'existence du monde des serveurs.
Cependant, il est parfois nécessaire de mettre en place des petits serveurs, sans forcément être un fournisseur d'accès à Internet ou un hébergeur de site Web. Par exemple, il peut être intéressant de fournir la possibilité de réaliser une connexion par téléphone à un ordinateur distant que l'on doit laisser allumé pour une raison ou une autre, afin de réaliser une opération de maintenance. Il est également possible de faire une liaison PPP entre deux ordinateurs par un câble série pour échanger des données, ou pour relier par l'intermédiaire du réseau téléphonique deux réseaux séparés physiquement.
Cette section présente donc les techniques de base permettant de paramétrer Linux pour accepter les communications entrantes, tant pour satisfaire aux demandes de connexion distantes que pour établir une liaison PPP.
IX-F-1. Paramétrage des connexions extérieures▲
Nous avons vu dans la Section 6.8 que le programme en charge de demander l'identification des utilisateurs sur les terminaux de login était le programme getty. Ce programme ne permet aux utilisateurs que de s'identifier. Lorsque quelqu'un saisit son nom, getty se contente de lancer le processus login pour que celui-ci réalise l'authentification de l'utilisateur en lui demandant son mot de passe. En fait, getty peut très bien lancer un autre programme que login si l'identification n'est pas nécessaire sur le terminal qu'il gère, mais, en général, il faut identifier les utilisateurs.
Le programme getty est donc le point d'entrée par lequel il faut nécessairement passer pour utiliser le système. Dans le cas des terminaux virtuels, getty utilise une ligne de communication virtuelle, mais il peut parfaitement utiliser une ligne de communication réelle (c'est d'ailleurs ce pour quoi il a été conçu à l'origine). En particulier, il est possible de lancer un processus getty sur une ligne série, afin de permettre l'utilisation de terminaux réels connectés sur le port série correspondant.
La ligne série sur laquelle le processus getty fonctionne n'est pas forcément connectée à un terminal physique. Elle peut parfaitement être connectée à un modem. Dans ce cas, les utilisateurs devront appeler le serveur pour se connecter à l'aide d'un logiciel d'émulation de terminal. Il existe plusieurs logiciels permettant d'appeler un ordinateur distant et d'émuler un terminal. On citera par exemple le logiciel HyperTerminal de Windows, et les programmes Telix et Minicom. Ce dernier est couramment fourni avec les distributions de Linux, car c'est un logiciel libre.
En fait, il existe plusieurs variantes de getty, spécialisées pour des usages spécifiques, et permettant de faciliter le paramétrage du fichier de configuration /etc/inittab, dans lequel sont définis les terminaux disponibles. Les distributions de Linux sont souvent fournies avec les versions suivantes :
- mingetty, qui est un getty simplifié, couramment utilisé pour les terminaux virtuels ;
- mgetty, qui est une version spécialement conçue pour être utilisée sur les lignes série connectées à un modem. mgetty est en particulier capable d'initialiser les modems, de décrocher automatiquement la ligne lorsqu'il y a un appel, et de gérer les principales commandes des modems compatibles Hayes ;
- agetty, qui est une version complète de getty, utilisable aussi bien sur les lignes série (avec ou sans modem) que pour les terminaux virtuels. On utilisera de préférence cette version si l'on désire proposer une connexion par l'intermédiaire d'un câble null-modem.
Note : Les câbles null-modem sont des câbles série symétriques, qui permettent de relier deux ordinateurs par l'intermédiaire de leurs ports série. Ces câbles peuvent être trouvés chez la plupart des revendeurs de matériel informatique (vous pouvez également en fabriquer un vous-même si vous avez du temps à perdre).
Connaissant les diverses possibilités de ces programmes, proposer un service de connexion extérieur est relativement simple. Il suffit en effet de rajouter dans le fichier de configuration /etc/inittab les lignes permettant de lancer les programmes getty sur les bonnes lignes. Par exemple, pour offrir une connexion modem sur le deuxième port série (couramment appelé COM2), on ajoutera la ligne suivante :
S1:23:respawn:/usr/sbin/mgetty -n 3 -s 38400 ttyS1Cette commande indique à init que mgetty doit être relancé à chaque fois qu'il se termine dans les niveaux d'exécution 2 et 3. Il doit prendre le contrôle de la ligne série utilisée par le fichier spécial de périphérique /dev/ttyS1, utiliser la vitesse de communication de 38400 bauds sur cette ligne (option -s) et ne décrocher qu'au bout de la troisième sonnerie (option -n). Vous pouvez bien entendu ajuster ces options en fonction de vos besoins.
En revanche, si l'on désire offrir une possibilité de connexion sur un port série par l'intermédiaire d'un câble null-modem, on utilisera plutôt le programme agetty. La ligne à ajouter dans le fichier /etc/inittab sera alors :
S1:123:respawn:/sbin/agetty -L 38400 ttyS1Notez que les options sont quelque peu différentes. La vitesse de la ligne est donnée directement, et l'option -L indique que la ligne série utilisée est locale et ne gère pas le signal de porteuse CD (abréviation de l'anglais « Carrier Detect ») habituellement utilisé pour détecter les coupures téléphoniques. Encore une fois, vous pouvez adapter ces commandes selon vos besoins. N'hésitez pas à consulter les pages de manuel des programmes mgetty et agetty pour obtenir plus de renseignements.
Note : Vous pouvez tester vos connexions série à l'aide de l'émulateur de terminal minicom. S'il est installé sur votre distribution, vous pourrez le lancer simplement en tapant la commande minicom. Si vous l'utilisez sur une connexion directe (c'est-à-dire par un câble null-modem), vous devrez utiliser l'option -o, afin d'éviter que minicom n'envoie les codes d'initialisation du modem sur la ligne série.
Il se peut que vous ne parveniez pas à vous connecter sur vos ports série. Dans ce cas, la première des choses à faire est de regarder les paramètres de la ligne série à l'aide de la commande stty. Vous devriez vous intéresser tout particulièrement à la vitesse utilisée, et éventuellement vous assurer que les deux ports série des deux ordinateurs utilisent la même vitesse, ou que le modem est capable de gérer la vitesse utilisée par le port série. Si besoin est, vous pouvez modifier la vitesse d'un port série à l'aide de la commande stty. Par exemple, pour configurer le port série COM2 à la vitesse de 115200 bauds, vous devez taper la commande suivante :
stty -F /dev/ttyS1 ispeed 115200IX-F-2. Configuration des liaisons PPP▲
Le protocole PPP utilisé par les fournisseurs d'accès à Internet est, comme son nom l'indique (« Point to Point Protocol », ou « protocole de liaison point à point »), un protocole permettant de relier deux ordinateurs uniquement. Ce protocole est complètement symétrique, et la mise en place d'un serveur PPP n'est pas plus compliquée que celle d'un client. Les liaisons PPP sont donc couramment utilisées pour relier deux réseaux distants par l'intermédiaire des lignes téléphoniques.
Lorsque nous avons présenté la configuration des accès à Internet, nous avons utilisé des options spécifiques à ce cas de figure afin de gérer le fait que les paramètres réseau sont imposés par le fournisseur d'accès. Dans le cas d'un serveur, ces paramètres ne sont pas nécessaires, puisque nous sommes cette fois à la place du fournisseur d'accès. En revanche, certains paramètres supplémentaires devront être spécifiés, notamment pour configurer le modem afin d'accepter les connexions externes.
En général, il faut lancer une instance du démon pppd pour chaque ligne série utilisée pour les connexions entrantes, car pppd ne peut gérer qu'une seule connexion à la fois. Cette technique peut paraître lourde, mais en fait elle est relativement pratique, car elle permet de spécifier des options spécifiques à chaque ligne série. Comme d'habitude, ces options peuvent être spécifiées sur la ligne de commande de pppd, mais elles peuvent également être enregistrées dans un fichier de configuration. Le fichier de configuration global /etc/ppp/options est généralement utilisé pour stocker les options communes à toutes les lignes série. Les options spécifiques à chaque ligne sont enregistrées quant à elles dans les fichiers options.ttySx, où ttySx est le nom du fichier spécial de périphérique utilisé pour accéder à cette ligne. L'usage de ces fichiers de configuration permet de simplifier notablement les lignes de commandes utilisées pour lancer pppd.
La ligne de commande à utiliser pour lancer pppd en mode serveur diffère peu de celle utilisée pour établir une connexion PPP en tant que client. Les deux principales différences proviennent du fait que :
- le serveur doit spécifier l'adresse IP qu'il utilisera pour l'interface PPP et l'adresse IP qu'il donnera au client lors de l'établissement de la liaison ;
- le script chat utilisé ne doit pas composer un numéro, mais initialiser le modem pour qu'il réponde aux appels entrants.
Les adresses IP sont spécifiées en ligne de commande à l'aide de la syntaxe suivante :
locale:distanteoù locale est l'adresse IP de l'interface PPP du serveur, et distante est l'adresse IP que le client recevra lorsqu'il se connectera. Ces deux adresses peuvent appartenir au même réseau (auquel cas le lien PPP constitue un réseau en soi) ou non (le lien PPP constitue alors pas un pont entre deux réseaux distincts). Ainsi, l'option suivante :
192.168.30.1:192.168.31.1indiquera à pppd que l'adresse IP de l'interface PPP locale sera 192.168.30.1, et que les clients qui se connecteront sur la ligne correspondante devront recevoir l'adresse 192.168.31.1.
Notez que les adresses utilisées ici font partie des adresses IP réservées pour les réseaux locaux. Ce n'est pas ce que font les fournisseurs d'accès à Internet en général, car ils disposent d'un ensemble d'adresses IP réelles redistribuables, mais les adresses réservées sont parfaitement utilisables. Le seul cas où cela pourrait être gênant serait si l'on voulait faire passer les adresses des deux passerelles de la liaison PPP sur Internet, mais les paquets utilisant ces adresses ne circulent justement que sur cette liaison (à moins que les passerelles ne se trouvent sur des réseaux locaux et utilisent des adresses de ces réseaux pour la liaison PPP, auquel cas, de toute manière, il faudrait utiliser la technique du masquerading pour connecter ces réseaux sur Internet).
Le script d'initialisation du modem, quant à lui, peut être spécifié à l'aide de l'option init de pppd. Cette option fonctionne exactement comme l'option connect que l'on a utilisée pour établir la liaison téléphonique dans la Section 9.3.2. La différence est ici que l'on ne cherche pas à composer un numéro de téléphone, mais plutôt à initialiser le modem pour qu'il décroche automatiquement la ligne lorsqu'il reçoit un appel.
Il existe malheureusement plusieurs dialectes de langages de commandes utilisés par les modems. En général, chaque modem dispose donc de ses propres commandes, et il faut consulter sa documentation pour savoir leurs syntaxes. Malgré cela, ce n'est pas trop gênant, car la plupart des modems sont compatibles avec le standard Hayes, dont les commandes sont bien connues. Pour l'initialisation d'un modem pour un serveur, les commandes d'initialisation suivantes seront très utiles :
|
Commande |
Signification |
|
ATS0=n |
Décrochage automatique si n vaut 1, manuel si n vaut 0. |
|
AT&C1 |
Activation du contrôle de la ligne CD (« Carrier Detect ») pour signaler les raccrochages des clients. Cette commande n'est utile que si l'option modem est passée en paramètre à pppd sur sa ligne de commande. |
|
AT&K3 |
Activation du contrôle de flux matériel (pour optimiser les échanges de données entre le modem et l'ordinateur). Cette option nécessite d'utiliser l'option crtscts dans la ligne de commande de pppd. |
Finalement, la ligne de commande à utiliser est donc la suivante :
pppd port vitesse detach modem crtscts init "/usr/sbin/chat -v \
-f /etc/ppp/script" &où port est le nom du fichier spécial de périphérique à utiliser pour cette connexion, par exemple /dev/ttyS0, vitesse est la vitesse de la ligne, par exemple 115200, et /etc/ppp/script est le nom du fichier du script chat devant servir à l'initialisation du modem. L'option detach permet de demander à pppd de se détacher du terminal courant, afin que l'on puisse le lancer en arrière-plan.
Vous trouverez ci-dessous un script chat d'exemple, permettant de spécifier les options vues ci-dessus :
"" ATZ
OK ATS0=1
OK AT&C1
OK AT&K3
OK ""Note : Vous remarquerez qu'il n'est pas nécessaire, contrairement à ce que l'on a vu lors de la configuration d'un client PPP, de spécifier le nom de l'utilisateur et le protocole d'identification et d'authentification utilisé. Cela est normal, car le serveur n'a pas à s'identifier auprès de la machine cliente en général (il peut bien entendu le faire s'il le désire, mais dans ce cas seuls les clients capables de gérer ce type de connexion pourront se connecter).
En revanche, il peut être nécessaire d'exiger que les clients s'identifient et s'authentifient à l'aide de l'un des protocoles PAP ou CHAP. Pour cela, il suffit simplement d'ajouter les noms des clients et leurs secrets respectifs dans les fichiers de secrets /etc/ppp/pap-secrets et /etc/ppp/chap-secrets, et d'ajouter l'une des options require-pap ou require-chap sur la ligne de commande du démon pppd. Remarquez que le format des fichiers pap-secrets et chap-secrets est le même aussi bien pour les connexions entrantes que pour les appels vers l'extérieur. Cela signifie que l'on doit donner d'abord le nom du client, ensuite le nom du serveur, et ensuite son secret et enfin la liste des adresses IP que les clients peuvent utiliser.
Remarquez également que la colonne spécifiant la liste des adresses IP ne doit pas rester vide lorsqu'on désire créer un secret pour le serveur. En effet, pppd se base sur l'adresse IP de la machine distante et sur le nom du client pour déterminer le secret à utiliser lors de l'authentification. Cependant, si l'on désire utiliser les mêmes secrets pour toutes les lignes (et donc pour toutes les adresses que le client peut se voir imposer), on pourra utiliser une étoile. Cela signifie que toutes les adresses correspondront à la ligne, et seul le nom du client sera utilisé pour déterminer le secret à utiliser. Par exemple, si le serveur se nomme monserveur et le poste client s'appelle jdupont, on utilisera la ligne suivante :
#Client Serveur Secret Adresses
jdupont monserveur gh25k;f *Lorsque la liaison PPP est établie, le démon pppd configure l'interface réseau correspondante. Le protocole utilisé par défaut est bien entendu le protocole IP. En général, il est nécessaire de configurer cette interface afin de spécifier les règles de routage permettant au client d'envoyer et de recevoir des paquets. Lors de l'établissement de la liaison, le démon pppd ajoute donc automatiquement une règle de routage pour indiquer que tous les paquets à destination de l'adresse du client doivent passer par l'interface ppp de la liaison courante. Cette règle convient dans la majorité des cas, et en tout cas pour les fournisseurs d'accès à Internet, car le client ne dispose que d'une seule machine. En revanche, si la liaison PPP est utilisée pour relier deux réseaux, les règles de routages par défaut ne suffiront plus, car des paquets à destination de toutes les machines du réseau distant doivent être envoyés via l'interface ppp (et inversement). Pour résoudre ces petits problèmes, on devra compléter ou modifier les scripts /etc/ppp/ip-up et /etc/ppp/ip-down. Ces deux scripts sont appelés par le démon pppd respectivement lors de l'établissement de la liaison PPP et lors de sa terminaison. On placera donc les commandes de routage complémentaires dans le script ip-up, et on fera le ménage correspondant dans le script ip-down.
Remarquez que ces deux scripts sont communs à toutes les interfaces ppp que les différents démons pppd peuvent utiliser. Ils sont également utilisés lors de l'établissement d'une connexion en tant que client. Leur modification devra donc être entourée d'un soin extrême. Afin de distinguer les différents cas d'utilisation, ces scripts sont appelés avec les paramètres suivants :
|
Paramètre |
Signification |
|
$1 |
Nom de l'interface réseau (par exemple, « ppp0 ». |
|
$2 |
Nom du fichier spécial de périphérique de la ligne série utilisée (par exemple, « ttyS0 »). |
|
$3 |
Vitesse de la ligne série. |
|
$4 |
Adresse IP locale de l'interface réseau. |
|
$5 |
Adresse IP du client. |
|
$6 |
Paramètre complémentaire, que l'on peut passer au script à l'aide de l'option ipparam de pppd. |
Un script classique fait un test sur le nom de l'interface réseau et ajuste les règles de routage en fonction de cette interface, en se basant sur les adresses IP locales et distantes reçues en paramètre. La plupart des distributions fournissent un script d'exemple que vous pouvez bien entendu modifier soit directement, soit à l'aide de leur outil de configuration.
Le démon pppd se termine à chaque fois que la liaison PPP se termine. Ce comportement est normal pour un client, mais ce n'est pas généralement ce que l'on cherche à faire pour un serveur. Il faut donc relancer pppd régulièrement à chaque fois qu'il se termine. Cela peut être réalisé en ajoutant sa ligne de commande dans le fichier de configuration /etc/inittab dans les niveaux d'exécution adéquats. Comme init impose une taille réduite sur les lignes de commandes des programmes qu'il peut lancer, il est nécessaire d'utiliser les fichiers d'options de pppd. Par exemple, si l'on veut assurer le service PPP pour une ligne entrante sur le deuxième port série dans les niveaux d'exécution 2 et 3, on utilisera la ligne suivante :
ppp1:23:respawn:/usr/sbin/pppd /dev/ttyS1 115200 \
192.168.30.1:192.168.31.1"avec les options suivantes activées dans le fichier d'options /etc/ppp/options.ttyS1 :
# Initialisation du modem :
init "/usr/sbin/chat -v -f /etc/ppp/client.ttyS1
# Protocole d'authentification :
require-pap
# Contrôle de la ligne téléphonique :
modem
# Contrôle de flux matériel :
crtsctsIX-F-3. Liaison de deux ordinateurs par un câble série▲
La connexion entre deux ordinateurs par l'intermédiaire d'un câble série est un cas particulier des liaisons PPP. Les techniques utilisées sont les mêmes, mais plusieurs simplifications importantes peuvent être faites :
- les deux ordinateurs sont reliés directement par un câble null-modem, et aucun modem ne s'intercale pour compliquer les choses. Par conséquent, on peut supprimer les scripts chat d'initialisation et de connexion ;
- on a le contrôle physique sur les deux ordinateurs, ce qui implique que les mécanismes d'identification et d'authentification sont superflus. Il est donc inutile de préciser les secrets PAP ou CHAP sur chaque machine ;
- il n'y a que deux ordinateurs à relier, donc les règles de routages sont élémentaires ;
- enfin, les adresses choisies sont connues d'avance et peuvent être spécifiées de manière symétrique sur le client et le serveur.
Il découle de ces simplifications que l'établissement d'une liaison PPP au travers d'un câble null-modem est une opération très facile. Comme vous allez le constater, le protocole PPP est effectivement symétrique.
Sur le « serveur », il suffit de lancer par exemple la commande suivante :
pppd /dev/ttyS0 115200 192.168.30.1:192.168.31.1 detach crtscts &Cette commande permet de lancer le démon pppd sur le port série COM1 (fichier spécial de périphérique /dev/ttyS0) en utilisant la vitesse de 115200 bauds (vitesse maximale généralement supportée par les ports série des ordinateurs), en utilisant l'adresse IP locale 192.168.30.1 et l'adresse IP distante 192.168.31.1. Le démon pppd doit se détacher du terminal, car il est lancé en arrière-plan. Enfin, le contrôle de flux matériel est utilisé (option crtscts).
La commande sur le « client » est absolument symétrique, puisque seules les adresses locales et distantes sont interverties :
pppd /dev/ttyS0 115200 192.168.31.1:192.168.30.1 detach crtscts &Bien entendu, le port série utilisé peut être différent de celui du serveur, mais il est impératif que les deux ports série soient configurés pour utiliser les mêmes paramètres de communication (vitesse, nombre de bits de données, bit de parité, bit d'arrêt). Vous aurez donc peut-être à utiliser la commande stty pour fixer ces paramètres sur le serveur et sur le client.
Une fois ces deux commandes lancées, la connexion PPP est établie. Le démon pppd ajoute alors automatiquement une règle de routage pour acheminer les paquets d'un ordinateur à l'autre. Vous n'aurez donc pas à modifier les scripts /etc/ppp/ip-up et /etc/ppp/ip-down. Comme vous pouvez le constater, l'utilisation de PPP pour relier simplement deux ordinateurs n'est pas une opération très compliquée…
IX-F-4. Configuration d'un serveur DHCP▲
Le protocole DHCP est géré, au niveau serveur, par le démon dhcpd. Ce démon se configure par l'intermédiaire du fichier de configuration /etc/dhcpd.conf, dans lequel se trouvent les définitions des réseaux à configurer, ainsi que les différentes informations qui doivent être communiquées aux clients. Ce fichier de configuration peut contenir plusieurs déclarations de réseau différentes, chacune étant introduite par le mot clé subnet. Ces déclarations permettent de définir les options pour les clients de différents réseaux de manière indépendante, mais si certaines de ces options sont communes à tous vos sous-réseaux, vous pouvez les factoriser en tête du fichier dhcpd.conf. Par exemple, le fichier de configuration suivant :
# Exemple de fichier de configuration dhcpd.conf :
default-lease-time 600;
max-lease-time 86400;
option subnet mask 255.255.255.0;
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.10 192.168.1.100;
range 192.168.1.150 192.168.1.200;
option broadcast-address 192.168.1.255;
option routers 192.168.1.1;
option domain-name "monrezo.perso";
}
subnet 192.168.53.0 netmask 255.255.255.0 {
range 192.168.53.10 192.168.53.254;
option broadcast-address 192.168.53.255;
option routers 192.168.53.2;
option domain-name "autrerezo.org";
}permet de configurer les deux réseaux 192.168.1.0 et 192.168.53.0 en spécifiant un masque de sous-réseau égal à 255.255.255.0 et une durée de bail d'adresse IP par défaut de 10 minutes (option default-lease-time) et maximale d'un jour (option max-lease-time). Vous remarquerez que ces dernières options utilisent la seconde comme unité de temps.
Comme vous pouvez le constater, la syntaxe du fichier de configuration dhcpd.conf n'est pas bien compliquée. Le mot clé subnet doit être suivi de l'adresse du réseau sur lesquels les clients à configurer par DHCP se trouvent. Le mot clé netmask doit être suivi quant à lui par le masque de ce sous-réseau. Les adresses IP attribuées aux clients peuvent être choisies dans différentes plages de valeurs, chacune étant spécifiée par le mot clé range suivi de l'adresse de début et de l'adresse de fin de la plage. Il est également possible d'attribuer des adresses fixes à certaines machines, avec la syntaxe suivante :
hardware ethernet 08:00:2b:4c:59:23;
fixed-address 192.168.1.101;où les mots clés hardware ethernet introduisent l'adresse Ethernet de l'interface réseau de la machine cliente, et où fixed-address spécifie l'adresse IP que cette machine doit utiliser pour cette interface.
Enfin, un grand nombre d'options peuvent également être spécifiées, par exemple pour définir les adresses de diffusion (mot clé broadcast-address), les adresses des passerelles (mot clé routers), les noms de domaines (mot clé domain-name) ou encore les durées des bails accordés aux machines clientes (mots clés default-lease-time et max-lease-time). La liste complète des options utilisables est donnée dans la page de manuel dhcpd.conf et je vous invite à la consulter si vous désirez en savoir plus.
Lorsque vous aurez rédigé le fichier de configuration adapté à votre installation, il ne vous restera plus qu'à lancer le démon dhcpd. Celui-ci utilise la syntaxe suivante :
dhcpd interface0 [interface1 […]]où interface0, interface1, etc., sont les interfaces réseau utilisées pour accéder aux réseaux à configurer en DHCP. Ces interfaces doivent être configurées avec des adresses de réseau pour lesquelles il est possible de trouver une section subnet correspondante dans le fichier de configuration /etc/dhcpd.conf. Enfin, la commande de démarrage du démon dhcpd pourra être placée dans les fichiers d'initialisation du serveur DHCP.
Note : Le démon dhcpd utilise les fonctionnalités d'accès direct aux cartes réseau et de filtrage des paquets du noyau Linux pour écouter sur le réseau les demandes de configuration par DHCP des clients. Par conséquent, vous devrez activer ces options dans la configuration du noyau si ce n'est déjà fait. Pour cela, il vous faudra cocher les options « Packet socket », « Packet socket: mmapped IO » et « Socket Filtering » du menu « Networking options ». Vous devrez également activer l'option « IP: multicasting » dans la liste des options pour le protocole IP afin de permettre au démon d'effectuer des émissions de paquets en mode broadcast. Le détail de la configuration et de la compilation du noyau a été vu dans la Section 7.3.
IX-G. Systèmes de fichiers en réseau▲
L'une des utilités principales d'un réseau est de permettre le partage des fichiers entre plusieurs ordinateurs. Cela nécessite de disposer d'un système de fichiers réseau sur les machines qui désirent accéder à des fichiers d'une autre machine, et d'un programme serveur sur les machines ainsi accédées par les clients.
Il existe deux grands standards de protocole pour les systèmes de fichiers en réseau. Le premier standard fonctionne quasiment exclusivement sous Unix, il s'agit du protocole « NFS » (abréviation de l'anglais « Network File System »), introduit originellement par Sun Microsystems et repris par la suite par les autres éditeurs de systèmes Unix. Le deuxième protocole est le protocole « SMB » (abréviation de l'anglais « Server Message Block »), qui a été introduit par Microsoft pour les systèmes DOS et Windows.
Les deux protocoles sont incompatibles, et si les deux solutions fonctionnent parfaitement en environnements homogènes, il est assez difficile de faire communiquer les deux types de systèmes. Les principaux problèmes proviennent de l'impossibilité d'utiliser le protocole réseau NetBIOS d'IBM sur les machines Unix, et des limitations des systèmes Microsoft en ce qui concerne la gestion des utilisateurs, les droits d'accès et les liens symboliques. De plus, la différence de gestion des fins de lignes dans les fichiers textes entre Unix et les systèmes Microsoft pose des problèmes qui peuvent difficilement être résolus de manière systématique.
Malgré ces limitations, les machines fonctionnant sous DOS ou Windows peuvent accéder aux systèmes de fichiers NFS des machines Unix grâce à des programmes spéciaux. Ces programmes sont souvent des extensions propriétaires aux systèmes Microsoft, et peuvent être relativement coûteux sans pour autant garantir une grande fiabilité et des performances honnêtes. L'utilisation de NFS sur les machines Windows ne sera donc pas traitée ici. Inversement, les machines Unix peuvent accéder aux partages Microsoft, mais là encore, il peut se présenter des difficultés. La principale difficulté est ici la nécessité d'encapsuler NetBIOS dans le protocole TCP/IP. En effet, le protocole SMB utilise les messages NetBIOS, protocole qui n'est pas géré nativement par les machines Unix. Dans tous les cas, des logiciels complémentaires sont nécessaires.
IX-G-1. Installation d'un serveur de fichiers NFS▲
L'installation d'un serveur NFS est la solution de prédilection pour le partage des fichiers sous Unix. Il faut savoir cependant que NFS n'offre pas des performances remarquables d'une part, et qu'il ouvre des brèches dans la sécurité du système d'autre part.
Comme il l'a été dit ci-dessus, l'installation d'un serveur NFS requiert l'utilisation de programmes spécifiques. Plus précisément, NFS utilise deux démons pour fournir les services NFS aux machines clientes. Ces deux démons se nomment respectivement « mountd » et « nfsd ». Le premier démon prend en charge les requêtes de montage des systèmes de fichiers NFS, et nfsd effectue les requêtes d'accès aux fichiers pour les clients. Par ailleurs, ces deux démons utilisent les mécanismes d'appels de procédure à distance « RPC » (abréviation de l'anglais « Remote Procedure Call » de Sun Microsystems. Ces services sont désormais disponibles sur toutes les machines Unix et constitue la norme en la matière. Il est donc également nécessaire de mettre en place les services RPC avant de lancer les démons NFS.
Le principe de fonctionnement des appels de procédures à distance est le suivant. Chaque programme désirant fournir des services RPC écoute sur un port TCP ou UDP pour des requêtes éventuelles. Les clients qui veulent utiliser ces services doivent envoyer leurs requêtes sur ce port, en précisant toutes les informations nécessaires à l'exécution de cette requête : numéro de la requête et paramètres de la requête. Le serveur exécute cette requête et renvoie le résultat. Les bibliothèques RPC fournissent les fonctions nécessaires pour effectuer le transfert des paramètres et les appels à distance eux-mêmes.
En pratique cependant, les clients ne savent pas sur quel port le serveur RPC attend leurs requêtes. Un mécanisme a donc été mis en place pour leur permettre de récupérer ce port et communiquer ensuite avec le serveur. Chaque serveur RPC est identifié par un numéro de programme unique, ainsi qu'un numéro de version. Lorsqu'ils démarrent, les serveurs s'enregistrent dans le système en précisant le port sur lequel ils écouteront les requêtes. Les clients peuvent alors interroger le système distant pour demander le port sur lequel ils trouveront un serveur donné, à partir du numéro de programme et du numéro de version de celui-ci.
Il existe donc un service RPC particulier, nommé « portmapper », qui fournit aux clients qui le demandent les numéros de port des autres serveurs. Bien entendu, le portmapper doit être toujours contactable, ce qui implique qu'il utilise systématiquement le même numéro de port. Par convention, le portmapper est identifié par le numéro de programme 100000, et il écoute les requêtes des clients sur les ports 111 des protocoles TCP et UDP.
La mise en place des serveurs de fichiers passe donc par le lancement de ces trois démons : le démon portmapper, le démon mountd et le démon nfsd. Les fichiers exécutables de ces démons sont respectivement portmap, rpc.mountd et rpc.nfsd. Ils sont normalement placés dans le répertoire /sbin/ ou /usr/sbin/. Vous devrez donc lancer ces trois démons sur la machine serveur de fichiers, il est probable que votre distribution fasse le nécessaire dans ses scripts de démarrage.
Note : Il est prévu d'intégrer les fonctionnalités de serveur NFS dans le noyau de Linux. Cependant, le serveur de fichiers du noyau n'est pas encore finalisé, et ne sera donc pas décrit ici.
Une fois les démons lancés, vous pourrez configurer les systèmes de fichiers exportés par votre serveur. Ces systèmes de fichiers sont en fait de simples répertoires que vous mettez à disposition de certaines machines. La liste de ces répertoires est placée dans le fichier de configuration /etc/exports. Chaque ligne de ce fichier caractérise un répertoire accessible par les autres machines du réseau. Ces lignes utilisent le format suivant :
répertoire machinesoù répertoire est le chemin sur le répertoire à exporter, et machines est une liste de machines pouvant accéder à ce répertoire. Cette liste contient des noms de machines, des adresses IP ou des noms de réseaux, séparés par des espaces. Il est également possible d'utiliser les caractères génériques '?' et '*' afin de spécifier des groupes de machines.
Des options peuvent être utilisées pour chaque machine, à l'aide de la syntaxe suivante :
machine(options)où machine est l'une des entrées de la liste de machines d'une ligne du fichier exports, et options est la liste des options pour cette entrée, séparées par des virgules. Les options les plus utilisées sont bien entendu ro et rw, qui permettent de fournir à cette machine ou à ce groupe de machine respectivement un accès en lecture seule et en lecture et écriture sur le répertoire.
Le problème fondamental de NFS est la sécurité. En effet, les fichiers sont exportés par défaut avec un identificateur d'utilisateur qui est celui qui possède le fichier sur la machine serveur. Or il est tout à fait possible que cet identificateur ne corresponde pas au même utilisateur sur tous les clients. Cela signifie que les utilisateurs des machines clientes peuvent parfaitement avoir accès à des fichiers qui ne leur appartiennent pas sur le serveur. Ce problème est fondamental, aussi faut-il le prendre en considération sérieusement.
NFS fournit plusieurs solutions pour assurer la sécurité sur les systèmes de fichiers exportés. La première, qui est aussi la plus restrictive, est d'attribuer les fichiers exportés à un utilisateur ne disposant de quasiment aucun droit (opération que l'on nomme souvent « squashing de l'utilisateur »). Cet utilisateur spécial est l'utilisateur « nobody », dont l'identificateur est 65534 par défaut. Ainsi, tous les clients accèdent à ces fichiers au nom de l'utilisateur nobody, et ne peuvent donc pas modifier les fichiers du serveur. Le squashing de l'utilisateur root est toujours réalisé par défaut, pour des raisons de sécurité évidentes.
La deuxième solution est nettement moins sûre. Elle nécessite de lancer le démon « ugidd » sur chaque machine client. Ce démon est appelé par le serveur NFS pour déterminer l'identificateur des utilisateurs du client à partir de leur nom. Ainsi, chaque fichier est exporté avec l'identificateur de l'utilisateur qui porte le même nom que celui qui possède le fichier accédé sur le serveur. Les problèmes de sécurité posés par cette solution sont énormes : rien ne garantit que deux utilisateurs distincts sur deux machines différentes ne puissent pas avoir le même nom d'une part, et un attaquant potentiel peut utiliser le démon ugidd pour obtenir la liste des utilisateurs de la machine cliente d'autre part (ce qui constitue déjà la moitié du travail pour s'introduire dans le système de la machine cliente). Cependant, cette solution est très pratique pour les réseaux dont on contrôle chaque machine, à condition de restreindre l'accès au démon ugidd au serveur uniquement, par exemple en ayant recours à tcpd.
La troisième solution est de définir sur le serveur l'association entre les identificateurs des utilisateurs du serveur et les identificateurs du client, ce pour chaque machine cliente. Cette technique est sûre, mais nettement plus compliquée à mettre en œuvre.
Enfin, la dernière solution est d'utiliser les services d'information du réseau NIS (abréviation de l'anglais « Network Information Service »), qui permettent de définir un certain nombre d'informations de manière globale sur un réseau. En particulier, il est possible de centraliser la définition des utilisateurs et des mots de passe. Cette solution est très lourde à mettre en œuvre, puisqu'elle nécessite de configurer NIS au préalable. Elle n'est donc mise en place que sur les grands réseaux, et un particulier n'a pas de raisons d'y recourir (à moins de vouloir explorer ces mécanismes bien entendu). Nous n'en parlerons donc pas.
Toutes ces techniques peuvent être activées à l'aide d'options fournies dans la liste des options pour chaque machine déclarée dans le fichier de configuration /etc/exports. Les options utilisées sont décrites ci-dessous :
- l'option all_squash permet d'exporter tous les fichiers comme appartenant à l'utilisateur nobody. C'est l'option la plus sûre, mais aussi la plus restrictive ;
- l'option map_daemon permet d'utiliser le démon ugidd, qui doit être lancé sur les machines clientes et accessibles du serveur. L'accès aux répertoires exportés sera refusé si ce démon ne peut être contacté par le serveur NFS. C'est certainement la solution la plus pratique pour un particulier ;
- l'option map_static=fichier permet d'utiliser un fichier de correspondance des identificateurs des utilisateurs du serveur NFS sur les identificateurs des utilisateurs de la machine cliente.
Comme on peut le voir, cette dernière option permet de définir spécifiquement, pour chaque machine, la correspondance des identificateurs d'utilisateurs. Le fichier fourni en paramètre à l'option map_static contient un certain nombre de lignes, chacune définissant l'association entre les identificateurs d'utilisateurs de la machine distante et les identificateurs de ces utilisateurs sur le serveur. Ces lignes sont introduites à l'aide du mot clé uid. Il est également possible de donner les correspondances sur les groupes des utilisateurs avec le mot clé gid :
# Exemple de fichier de correspondance d'identificateurs :
# client serveur
uid 0-99 -
uid 500-1000 1000
gid 0-49 -
gid 50-100 1000Dans l'exemple donné ci-dessus, les utilisateurs ayant un identificateur compris entre 0 et 99 inclus seront associés à l'utilisateur nobody (ils subissent le « squashing »). Il en est de même pour les groupes allant de 0 à 49. En revanche, les utilisateurs dont les identificateurs vont de 500 à 1000 sur la machine cliente se voient respectivement considérés comme les utilisateurs d'identificateur 1000 à 1500 par le serveur NFS. De même, les groupes d'identificateurs 50 à 100 sont considérés comme les groupes d'identificateurs 1000 à 1050.
L'exemple qui suit va permettre d'éclaircir un peu ces notions. Il montre comment les trois types de contrôle des identificateurs peuvent être mis en place, pour trois types de clients différents :
# Exemple de fichier /etc/exports :
# Répertoire /pub : accessible de tout le monde, avec les droits
# de l'utilisateur nobody :
/pub (ro,all_squash)
# Répertoire /home : accessible de toutes les machines du réseau local,
# avec contrôle des utilisateurs effectué par le démon rpc.ugidd :
/home *.monrezo.org(map_daemon)
# Répertoire /usr : accessible par la machine 192.168.5.2, avec mapping
# des utilisateurs :
/usr 192.168.5.2(map_static=/etc/nfs/192.168.5.2.map)Le fichier /etc/nfs/192.168.5.2.map utilisé dans la troisième ligne définit la correspondance entre les utilisateurs de la machine 192.168.5.2 et le serveur NFS :
# Fichier de correspondance pour 192.168.5.2 :
# client serveur
uid 0-99 -
uid 500 507
gid 0-49 -
gid 50 50Les informations stockées dans le fichiers /etc/exports sont prises en compte lors de l'exécution de la commande exportfs. Cette commande est généralement exécutée à chaque démarrage de la machine dans les scripts de démarrage du système, avec l'option -a. Cette option permet d'exporter tous les systèmes de fichiers référencés dans /etc/exports, tout comme la commande mount utilise cette option pour monter tous les systèmes de fichiers au démarrage.
À chaque modification du fichier /etc/exports, il est nécessaire de signaler cette modification au démon mountd. Cela peut être fait simplement à l'aide de la commande suivante :
exportfs -aIX-G-2. Configuration d'un client NFS▲
Une fois la configuration du serveur NFS effectuée, il ne reste plus qu'à configurer les postes clients. Bien entendu, la manière de réaliser cela dépend du système utilisé. Nous allons voir ici comment accéder à un répertoire exporté par un serveur à partir d'une machine fonctionnant sous Linux.
Du point de vue du client, les fichiers accédés par NFS sont considérés comme des fichiers normaux d'un système de fichiers classique. Ils sont donc gérés directement par le noyau, en tant que système de fichiers à part entière. L'utilisation de NFS est donc directe, pour peu que l'on ait activé les fonctionnalités NFS dans le noyau.
Encore une fois, vous devrez modifier la configuration du noyau si celui fourni avec votre distribution ne gère pas les systèmes de fichiers NFS (ce qui est fort peu probable). La seule fonctionnalité à activer, en plus de la gestion du réseau bien entendu, est l'option « NFS filesystem support » du menu « Network File Systems » (ce menu est un sous-menu du menu « Filesystems » si vous utilisez la configuration en mode texte).
Lorsque le noyau sera compilé et installé, il sera capable d'utiliser les systèmes de fichiers NFS nativement. Vous n'aurez donc pas besoin des démons nfsd et mountd, tout sera pris en charge par le noyau. Cependant, si le serveur exporte ses répertoires avec l'option map_daemon, il sera nécessaire de lancer le démon ugidd sur la machine cliente (le fichier exécutable se nomme rpc.ugidd et se trouve dans le répertoire /usr/sbin/). Il est conseillé de lancer ce démon à partir d'inetd, en l'encapsulant à l'aide du démon tcpd.
Le montage d'un système de fichiers NFS se fait classiquement, avec la commande mount. Il suffit ici de préciser le type de système de fichiers « nfs » avec l'option -t, et d'utiliser la syntaxe suivante pour le fichier spécial de périphérique à utiliser :
machine:répertoireoù machine est le nom du serveur NFS, et répertoire est le chemin absolu sur le répertoire exporté par cette machine et auquel on désire accéder. Ainsi, si la machine « mon.serveur.nfs » exporte le répertoire « /mon/répertoire/exporté », la commande suivante permettra de monter ce système de fichiers NFS dans le répertoire /mnt :
mount -t nfs \
mon.serveur.nfs:/mon/répertoire/exporté /mntLe système de fichiers NFS accepte des options permettant d'optimiser les transferts d'informations. Ces options peuvent être fournies en ligne de commande à mount à l'aide de l'option -o. Les plus utiles sont sans doute rsize, qui permet de fixer la taille des blocs de données transférés pour la lecture des fichiers, et wsize, qui permet de fixer cette taille pour l'écriture des fichiers. Il est recommandé d'utiliser des paramètres raisonnables afin d'éviter des erreurs de transfert et des pertes de données. La valeur par défaut est 1024, mais il est recommandé d'utiliser des blocs de taille 8192 pour obtenir de meilleures performances. Ainsi, la commande précédente pourra être optimisée comme suit :
mount -t nfs -o rsize=8192,wsize=8192 \
mon.serveur.nfs:/mon/répertoire/exporté /mntBien entendu, ces valeurs dépendent de la bande passante de votre réseau, et vous aurez sans doute à effectuer des tests de transferts de fichiers pour trouver les valeurs optimales.
IX-G-3. Installation d'un serveur de fichiers SMB▲
Bien que les protocoles SMB et NFS soient profondément différents, les principes utilisés pour mettre en place un serveur SMB sont quasiment les mêmes que ceux utilisés pour un serveur NFS. L'installation d'un serveur SMB requiert en effet l'utilisation de deux démons qui prennent en charge les services fournis par les serveurs de fichiers SMB. Ces démons utilisent tous deux le fichier de configuration smb.conf, placé le plus souvent dans le répertoire /etc/. Seuls les serveurs doivent faire fonctionner ces démons, les clients Linux quant à eux se contentent d'utiliser le système de fichiers SMB du noyau.
Ces démons, ainsi que tous les outils nécessaires à l'utilisation du protocole SMB, sont fournis dans la suite logicielle « Samba », dont le nom est évidemment inspiré de « SMB ». Cette suite logicielle est distribuée sous la licence GNU et est donc complètement libre d'utilisation. Elle est normalement fournie avec toutes les distributions. La version actuelle est la 3.0.3. Si ce n'est pas celle fournie avec votre distribution, il est fortement recommandé d'effectuer une mise à jour.
L'installation de Samba ne pose pas de problème particulier. Nous ne la décrirons donc pas ici. Sachez cependant qu'elle est recommandée même sur les postes clients, car bien que les démons ne soient pas lancés sur ceux-ci, les outils permettant de se connecter à un serveur de fichiers sont fournis avec Samba et restent nécessaires.
Comme on l'a vu ci-dessus, le protocole SMB se base sur le protocole de bas niveau NetBIOS. NetBIOS est un protocole très primitif, qui n'utilise pas un mécanisme d'adressage semblable à celui de la plupart des protocoles modernes. Chaque machine est identifiée sur le réseau par un nom unique, qu'elle doit déclarer avant de pouvoir utiliser les ressources du réseau. Tout nouvel arrivant sur le réseau signale donc aux autres qu'il désire utiliser son nom, afin de déterminer si ce nom est déjà pris ou non par une autre machine.
L'un des plus gros défauts de NetBIOS est tout simplement qu'il n'est pas routable tel quel, et qu'il est impossible de structurer un réseau en se basant seulement sur les noms NetBIOS. C'est pour cette raison que l'on encapsule souvent NetBIOS dans un protocole plus évolué capable de traverser les routeurs, comme TCP/IP par exemple. C'est exactement ce que fait Samba, qui apparaît donc comme un service réseau Unix classique permettant de comprendre les paquets NetBIOS encapsulés dans les paquets TCP/IP. Cette technique suppose évidemment que tous les clients du réseau, y compris les postes Windows, soient configurés pour encapsuler NetBIOS dans TCP/IP. L'utilisation de TCP/IP est de toute manière fortement recommandée si l'on veut réaliser un réseau un tant soit peu sérieux, et les versions récentes de Windows utilisent également cette technique.
Outre les noms d'ordinateurs, le protocole NetBIOS permet de définir des groupes d'ordinateurs, qui contiennent tous les ordinateurs supposés échanger des informations couramment. Un ordinateur ne peut faire partie que d'un seul groupe, mais il peut également ne faire partie d'aucun groupe s'il le désire. Ces groupes d'ordinateurs sont créés uniquement en fonction du travail qu'ils ont à effectuer, et ne sont a priori absolument pas liés à leur emplacement géographique ni à leur emplacement sur le réseau. Ainsi, il est possible de communiquer avec tous les ordinateurs d'un groupe, un peu comme le protocole TCP/IP permet d'utiliser des adresses de diffusion. Dans le monde Windows, ces groupes de machines sont plus couramment dénommés des « workgroup », et il n'y a en fait aucune différence technique. Pour le protocole SMB, chaque ordinateur du réseau doit faire partie d'un groupe bien défini, bien que ce ne soit pas une nécessité au niveau de NetBIOS.
Lorsqu'un groupe de travail possède une base de données centrale permettant de réaliser l'authentification des utilisateurs lors des accès aux machines par le réseau, on dit qu'il s'agit d'un domaine. En pratique, un domaine n'est donc rien d'autre qu'un groupe de travail dont font partie un ou plusieurs serveurs d'authentification. Il existe plusieurs types de serveurs de domaine. Un serveur primaire est un serveur central, sur lequel se fait la gestion globale des utilisateurs. Outre un serveur primaire, un domaine peut également contenir un ou plusieurs serveurs de sauvegarde si nécessaire. Comme leur appellation l'indique, ces serveurs sont capables de remplacer le serveur primaire en cas de défaillance de celui-ci. Ils maintiennent donc une copie des tables d'utilisateurs, et la synchronisent régulièrement avec celle du serveur primaire. Enfin, un domaine peut contenir des serveurs membres, qui sont comme des serveurs de sauvegarde, à ceci près qu'ils ne peuvent pas remplacer le serveur de domaine primaire. Bien entendu, le domaine contient également les stations de travail classiques, qui effectuent des requêtes sur le serveur primaire.
Afin de gérer la liste des noms NetBIOS du réseau, Samba fournit le démon « nmbd ». Ce démon est essentiel au fonctionnement correct de Samba et doit donc toujours être lancé. Il peut également être configuré en tant que serveur WINS (abréviation de l'anglais « Windows Internet Name Server »), afin de pouvoir fournir les noms NetBIOS sur Internet. WINS est une technique développée par Microsoft pour résoudre le problème du nommage des postes de travail sur Internet. Un serveur WINS est donc à NetBIOS un peu ce qu'un serveur DNS est à TCP/IP. Le démon nmbd est installé classiquement dans le répertoire /usr/bin/ ou dans le répertoire /usr/sbin/. Vous devrez le lancer avec l'option -D, faute de quoi il ne démarrera pas en tant que démon :
/usr/sbin/nmbd -DLe deuxième démon fourni par Samba est « smbd ». Celui-ci gère effectivement le protocole SMB, et est donc en charge d'effectuer la gestion des utilisateurs et des partages. Il doit être lancé également avec l'option -D si l'on veut qu'il démarre en tant que démon. Ce démon est normalement installé au même endroit que nmbd :
/usr/sbin/smbd -DVous pourrez éventuellement faire en sorte que ces démons soient lancés automatiquement en modifiant les scripts de démarrage de votre système. Une fois ces deux démons lancés, votre machine Linux se comportera exactement comme une machine Windows serveur classique. Ainsi, les ressources partagées par ce serveur seront accessibles par les clients SMB, comme les postes Windows par exemple.
Malheureusement, la plupart des clients SMB ne gèrent pas les notions avancées des systèmes de fichiers Unix. Le protocole SMB ne supporte d'ailleurs qu'une partie infime de ces fonctionnalités. De plus, la gestion des droits sur les fichiers exportés par un serveur de fichiers Windows se base généralement sur le modèle de sécurité des d'ACLs (« Access Control List »), plutôt que sur le modèle de sécurité Unix classique. Samba peut donc être configuré pour utiliser le support des ACLs natif des systèmes de fichiers Linux, ainsi que pour utiliser les modèles de sécurité primitifs des anciennes versions de Windows.
La première difficulté à résoudre concerne la gestion des droits d'accès aux fichiers des partages. Sous Unix, chaque fichier et chaque répertoire disposent de droits d'accès, et seuls les utilisateurs autorisés peuvent les manipuler. Dans le monde Windows, il n'y a quasiment pas de notion d'utilisateur, et en général pas de gestion de la sécurité. Seuls Windows NT/2000/XP disposent de ces fonctionnalités, à condition qu'ils utilisent des systèmes de fichiers NTFS et que le type de partage utilisé le permette.
En fait, la gestion de la sécurité se fait de manière globale, pour tous les fichiers d'un partage. Il existe principalement deux modes de contrôle d'accès aux partages SMB :
- le contrôle d'accès au niveau ressource, qui se fait à partir d'un mot de passe unique pour la ressource, sans tenir compte de l'utilisateur qui cherche à y accéder ;
- le contrôle d'accès au niveau utilisateur, qui nécessite de fournir un nom d'utilisateur et un mot de passe.
Le contrôle d'accès au niveau utilisateur nécessite de se trouver dans un domaine, et non dans un simple Workgroup. Il faut donc disposer d'un serveur de domaine afin de réaliser l'authentification des utilisateurs qui cherchent à accéder à ces ressources. Pour des raisons commerciales, Microsoft s'est arrangé pour que seuls Windows NT, Windows 2000 et Windows XP serveur puissent servir de contrôleurs de domaine, ce qui fait qu'il est impossible d'utiliser le contrôle d'accès au niveau utilisateur sur un réseau ne disposant que de machines sous Windows 95, 98, ou NT/2000/XP client (heureusement, Samba est capable de servir de contrôleur de domaine, cependant, nous ne verrons pas ce type de configuration). Il va de soi que le contrôle d'accès au niveau utilisateur est la seule solution réellement sûre du point de vue de la sécurité.
Pour couronner le tout, les partages ne permettent que de fixer les droits de lecture et d'écriture pour celui qui accède aux fichiers du partage. Les droits d'exécution n'ont pas de signification sous Windows puisque, contrairement aux fichiers Unix, le type des fichiers est déterminé par leur extension. Les notions de sécurité des partages sont donc profondément différentes de celles utilisées par Unix, surtout pour le contrôle d'accès au niveau ressource, puisqu'aucun nom d'utilisateur n'est requis lors de l'authentification ! Mais ce n'est pas tout. Les fichiers Unix appartiennent tous à un utilisateur et à un groupe d'utilisateurs, chose qui n'a pas de signification pour Windows. De plus, les systèmes de fichiers Unix font la distinction entre les majuscules et les minuscules dans les noms de fichiers, ce que ne fait pas Windows. Et ils disposent de la notion de liens physiques et symboliques. Autant de problèmes qui doivent être gérés par Samba.
Note : Le fait de ne pas disposer des informations concernant les droits des utilisateurs sur les fichiers accédés par SMB n'empêche pas le serveur de fichiers de contrôler les accès effectués par le client. Si par exemple, un fichier est marqué comme étant en lecture seule, aucun client ne peut y écrire, même par l'intermédiaire d'un partage accédé en lecture et écriture.
Pour résoudre tous ces problèmes, Samba dispose d'un grand nombre d'options, qui peuvent être utilisées dans le fichier de configuration /etc/samba/smb.conf. Ces options permettent d'indiquer la manière dont l'authentification doit être faite, les droits avec lesquels les fichiers sont accédés ou créés, les utilisateurs au nom desquels les fichiers sont créés, et le comportement à suivre lorsqu'un client essaie de suivre un lien symbolique. Seules les principales options gérées par Samba seront décrites ici. Les options avancées seront laissées de côté, car Samba propose un nombre incroyable de fonctionnalités et les traiter toutes dépasserait le cadre de ce document. Vous pourrez trouver des informations complémentaires en cas de nécessité dans la documentation de Samba, ou bien dans l'excellent livre « Using Samba » de Robert Eckstein, publié aux éditions O'Reilly. Une version en ligne de ce livre est fournie avec les sources de Samba et complète ainsi la documentation officielle de ce programme.
La plupart des distributions fournissent un fichier de configuration /etc/samba/smb.conf contenant la plupart des options par défaut, plus quelques exemples de configuration. Par exemple, les répertoires des utilisateurs sont souvent exportés par défaut. Vous pourrez bien entendu modifier ce fichier de configuration. Il est donc peut-être nécessaire de donner quelques précisions.
Le fichier smb.conf est structuré en sections permettant de fixer les paramètres de différentes fonctionnalités du logiciel. Chaque section est introduite par son nom, donné entre crochets. Certaines sections sont spécifiques à Samba et d'autres permettent de définir les partages que vous désirez créer. Les paramètres définis dans les sections se présentent sous la forme de couple « paramètre = valeur », où paramètre est le nom d'un des paramètres possibles dans cette section, et valeur est la valeur que ce paramètre peut prendre.
Parmi les sections propres à Samba, on compte la section « [global] ». Cette section est particulièrement importante, car elle fixe les paramètres globaux de Samba, ainsi que les valeurs par défaut des paramètres des autres sections. La section [global] suivante peut servir d'exemple :
[global]
# Définit le nom NetBIOS du serveur :
netbios name = Linux
server string = Linux fait la Samba (version %v)
# Définit le nom du groupe de travail :
workgroup = monrezo
# Fixe les règles de gestion de la sécurité :
security = user
encrypt passwords = yes
smb passwd file = /etc/samba/passwd
# Définit la correspondance entre les noms d'utilisateurs Windows
# et les noms Unix :
username map = /etc/samba/usermap
# Définit le compte Unix à utiliser pour invité :
guest ok = no
guest account = nobody
# Définit les paramètres réseau :
socket options = TCP_NODELAY
interfaces = eth0
bind interfaces only = yesCette section commence par définir le nom NetBIOS du serveur et sa description. Par défaut, le nom utilisé par Samba est le nom de domaine Unix de la machine, mais vous pouvez changer ce nom comme bon vous semble. Vous avez dû remarquer que dans la description de la machine (mot clé server string), la version de Samba est récupérée avec %v. En fait, Samba définit un certain nombre de variables qui sont remplacées dynamiquement lors de la connexion à un partage. Ainsi, %v représente la version de Samba utilisée, %u représente le nom de l'utilisateur qui se connecte, etc. Toutes ces variables sont décrites dans la page de man du fichier smb.conf.
Le nom du groupe de travail dont fait partie la machine est ensuite introduit avec le mot clé workgroup. Dans le cas présent, il s'agit du groupe de travail « monrezo ».
Viennent ensuite les options de sécurité. Le mot clé security permet de définir le mode de contrôle d'accès aux partages mis à disposition des clients par le serveur Samba. La valeur user indique que ce contrôle d'accès se fait au niveau utilisateur, ce qui est le plus cohérent sous Unix. Chaque utilisateur doit donc fournir son nom et son mot de passe pour accéder à ces partages. Samba peut également gérer le contrôle d'accès au niveau ressource, si l'on utilise la valeur share. Dans ce cas, Samba essaiera de retrouver l'utilisateur qui cherche à se connecter à partir de son mot de passe. Il faut donc ajouter dans ce cas une ligne telle que celle-ci dans la section globale ou dans l'une des sections définissant un partage :
username = utilisateursoù utilisateurs représente la liste des utilisateurs que Samba utilisera pour tester le mot de passe fourni. Bien entendu, si un nom d'utilisateur est fourni par le client pour accéder à cette ressource, ce nom est utilisé directement. Samba mémorisera également ce nom pour les demandes d'accès ultérieures à la ressource partagée. Cet algorithme n'est pas très sûr, car un utilisateur peut se connecter par hasard au nom d'un autre. Aussi n'est-il pas recommandé d'utiliser le contrôle d'accès au niveau ressources.
Jusqu'à Windows 95 et Windows NT4 Service Pack 2 compris, les mots de passe fournis par les clients étaient transférés en clair sur le réseau. Cela n'étant pas sûr, Microsoft a décidé d'adopter une nouvelle technique, dans laquelle les mots de passe à transférer sont chiffrés par une clef fournie par le serveur. Ainsi, une personne mal intentionnée écoutant les paquets transférés sur le réseau ne pourrait pas capter ces mots de passe. Samba est capable de gérer les deux cas de configuration, à l'aide de l'option encrypt password. Cependant, si vous décidez d'activer le chiffrement des mots de passe, vous devrez également créer un fichier de mots de passe pour les clients SMB. L'emplacement de ce fichier est indiqué avec l'option smb passwd file.
Le format du fichier de mot de passe de Samba ressemble fortement à celui du fichier de mot de passe Unix /etc/passwd. Vous pourrez trouver dans la documentation de Samba une description détaillée de ce fichier. Cependant, la chose la plus importante, c'est bien sûr de pouvoir ajouter des entrées pour chaque utilisateur dans ce fichier. Cette opération se fait avec l'utilitaire smbpasswd. Exécutée sous le compte root, la commande suivante permet d'ajouter un utilisateur et de définir son mot de passe :
smbpasswd -a utilisateuroù utilisateur est le nom de l'utilisateur dont on veut créer un nouveau mot de passe. L'utilisateur peut bien entendu changer son mot de passe avec smbpasswd.
Il est possible que les noms des utilisateurs Windows ne soient pas identiques à leurs logins sur la machine serveur de fichiers. En fait, il est même possible que plusieurs utilisateurs utilisent un même compte, créé uniquement pour les partages SMB. Samba fournit donc la possibilité d'utiliser un fichier de correspondance entre les noms des utilisateurs avec l'option username map. Le format du fichier de correspondance est très simple, puisqu'il est constitué de lignes définissant chacune une association entre un nom de login Unix et un nom d'utilisateur Windows. Ces lignes utilisent la syntaxe suivante :
login = utilisateuroù login est le nom de login de l'utilisateur sur la machine Unix, et utilisateur est le nom qu'il utilisera pour accéder aux partages.
L'option guest ok permet d'autoriser les connexions sans mot de passe sous un compte spécial, que l'on nomme le compte invité. Pour cela, il suffit de lui affecter la valeur yes. Cette option peut être fixée à no dans la section de configuration globale, et redéfinie dans les sections spécifiques de certains partages. Dans tous les cas, les connexions qui s'effectuent en tant qu'invité doivent utiliser un compte utilisateur Unix classique. Ce compte peut être défini à l'aide de l'option guest account, en général, l'utilisateur nobody utilisé par NFS est le plus approprié.
Enfin, il est possible de définir des paramètres réseau dans la section de configuration globale. Ces paramètres réseau permettent de fixer des options de sécurité complémentaires et des options d'optimisation. L'option interfaces donne la liste des interfaces à partir desquelles les demandes de connexion des clients seront acceptées. Ce type de contrôle est activé lorsque le paramètre bind interfaces only prend la valeur yes. Ces options conviennent parfaitement pour un réseau local de particulier. L'option socket options quant à elle permet de définir les paramètres de fonctionnement des communications TCP. L'option TCP_NODELAY indique au système d'envoyer les paquets TCP dès que Samba le demande, sans chercher à en regrouper plusieurs pour optimiser la taille des paquets. Cette option accélère significativement le fonctionnement des programmes tels que Samba, qui utilisent beaucoup de petits paquets pour envoyer des requêtes ou des réponses. Sans cette option, le système chercherait à regrouper ces paquets, même si Samba n'en a pas d'autres à envoyer, et ralentirait ainsi inutilement les transferts de données.
Chaque partage fourni par le serveur SMB dispose également d'une section, dont le nom est le nom utilisé pour ce partage. Ces sections sont beaucoup plus simples que la section global, comme le montre l'exemple suivant :
[Données]
# Donne le chemin sur le répertoire utilisé par ce partage :
path = /usr/share/samba/données
# Description du partage :
comment = Disque de données
# Nom de volume Windows :
volume = SMB-LNX
# Options d'accès :
writeable = yes
guest ok = yesComme vous pouvez le constater, l'option path permet de définir le répertoire utilisé pour stocker les fichiers du partage. Ce répertoire est un répertoire du serveur, et le chemin doit donc obligatoirement être un chemin Unix valide. En particulier, il faut tenir compte ici de la casse des noms de fichiers. L'option comment donne la description du partage, telle qu'elle apparaîtrait dans le voisinage réseau de Windows. Le nom de volume quant à lui est celui qui sera donné si un client Windows attache une lettre de lecteur à ce partage. Il est spécifié à l'aide de l'option volume. Enfin, les options d'accès utilisées dans cet exemple permettent d'autoriser l'écriture dans les fichiers de ce partage, et d'autoriser les accès en tant qu'invité (c'est-à-dire sans mot de passe).
Samba dispose d'une fonctionnalité intéressante afin de définir automatiquement un partage pour chacun des répertoires personnels des utilisateurs déclarés dans le serveur. Lorsqu'un client cherche à accéder à un partage qui n'est pas défini par une section qui lui est propre, Samba tente de le localiser un répertoire personnel d'utilisateur portant ce nom. S'il le trouve, il utilisera ce répertoire pour effectuer le partage automatiquement. Les paramètres de ce partage automatique sont définis dans la section [homes], dont vous trouverez un exemple ci-dessous :
[homes]
comment = Répertoires personnels
browsable = no
writable = yesL'utilisation de l'option browsable = no ici sert simplement à indiquer qu'il ne doit pas apparaître de partage nommé homes. En effet, ce qui est désiré ici, c'est d'exposer les noms des répertoires personnels des utilisateurs, pas le partage homes lui-même. Les autres options sont les mêmes que pour les partages normaux.
La section [homes] peut poser quelques problèmes, puisqu'elle partage également le compte root. Cela n'est certainement pas le comportement désiré. Il est même fortement recommandé d'interdire les connexions pour les utilisateurs privilégiés du système. Cela peut être réalisé en utilisant l'option invalid users :
invalid users = root bin daemon adm sync shutdown \
halt mail news uucp operator gopherEn fait, il est conseillé de placer cette option dans la section [global], afin d'interdire les connexions de ces utilisateurs sur tous les partages.
Enfin, Samba fournit une fonctionnalité comparable à la section [homes] pour les imprimantes partagées. Il est en effet capable d'analyser le fichier de configuration /etc/printcap pour déterminer la liste des imprimantes installées, et les partager pour les clients Windows. Ces imprimantes apparaîtront donc comme des imprimantes partagées classiques. Pour cela, il suffit d'ajouter les lignes suivantes dans la section [global] du fichier smb.conf :
[global]
# Définit le type d'impression utilisé (bsd ou cups) :
printing = bsd
# Lit la définition des imprimantes installées dans /etc/printcap
# (type de commande BSD uniquement) :
printcap name = /etc/printcap
load printers = yesLa première ligne indique à Samba le type de commande à utiliser pour réaliser une impression. Si vous utilisez le système d'impression BSD, vous devez fixer l'option printing à bsd. Si vous utilisez CUPS, la valeur à utiliser est cups.
Les options concernant toutes les imprimantes que Samba trouvera peuvent être précisées dans la section [printers]. Cette section joue donc le même rôle pour les imprimantes partagées que la section [homes] joue pour les répertoires personnels des utilisateurs. La section donnée ci-dessous pourra vous servir d'exemple :
[printers]
comment = Imprimantes
browseable = no
printable = yes
writeable = no
guest ok = no
path = /tmp
create mode = 0700L'option browseable a ici la même signification que dans la section [homes]. On ne désire en effet pas qu'un partage portant le nom printers apparaisse dans les voisinages réseau des machines Windows ! En revanche, l'option printable permet d'indiquer clairement que ces partages sont des imprimantes. Il est évident que l'on ne peut pas écrire sur une imprimante, l'option writeable est donc fixée à no. Enfin, les impressions ne sont autorisées que pour les utilisateurs identifiés, et l'utilisateur invité n'a pas le droit de soumettre un travail d'impression.
Le mécanisme utilisé par Samba pour imprimer un document est le suivant. Lorsqu'un client demande une impression sur une des imprimantes partagées, Samba copie le fichier que le client lui envoie en local. Ce fichier est ensuite communiqué au gestionnaire d'impression Unix, en l'occurrence lpr sous Linux. Celui-ci imprime le fichier et le supprime du disque. Dans la section [printers], l'option path permet d'indiquer dans quel répertoire les fichiers temporaires envoyés par les clients doivent être stockés. Il est tout à fait cohérent de les placer dans le répertoire /tmp comme dans l'exemple donné ci-dessus. Enfin, il est logique de protéger ces fichiers contre les autres utilisateurs. Cela est réalisé à l'aide de l'option create mode, qui fixe les droits de ces fichiers à 0 pour tout le monde, sauf pour le compte root, à leur création. Ainsi, seuls les programmes fonctionnant sous le compte root (donc Samba et la commande lpr) peuvent lire, écrire et effacer ces fichiers.
Il est bien entendu possible de définir les imprimantes manuellement, à raison d'une section par imprimante. Ce type de configuration ne sera toutefois pas décrit ici.
Toute modification du fichier de configuration de Samba implique de la signaler aux démons smbd et nmbd. Cela peut être réalisé en leur envoyant un signal SIGHUP. Vous devrez donc taper les commandes suivantes :
killall -HUP smbd
killall -HUP nmbdComme on peut le voir, le fichier de configuration smb.conf n'est pas très compliqué, mais utilise un grand nombre d'options. Heureusement Samba fournit l'outil de configuration « SWAT » (abréviation de l'anglais « Samba Web Administration Tool »), qui permet d'effectuer la configuration de Samba graphiquement. Comme son nom l'indique, SWAT joue le rôle de serveur Web, et peut être utilisé avec n'importe quel navigateur en se connectant sur le port 901 de la machine sur laquelle il tourne.
Pour que cela puisse fonctionner, il faut ajouter le service réseau « swat » dans votre fichier de configuration /etc/services :
swat 901/tcpVous devrez également ajouter une ligne dans votre fichier /etc/inetd.conf, afin que le démon inetd puisse lancer SWAT automatiquement lorsqu'un client cherche à l'utiliser sur le réseau. Vous devrez donc ajouter la ligne suivante :
swat stream tcp nowait.400 root /usr/local/samba/bin/swat swatet signaler à inetd la modification de inetd.conf à l'aide de la commande :
killall -HUP inetdVous pourrez alors accéder à la configuration graphique de SWAT à l'aide d'un navigateur Web, en utilisant simplement l'URL suivante :
http://localhost:901SWAT demandera bien entendu le nom de l'utilisateur root et son mot de passe pour permettre la modification du fichier smb.conf. Notez qu'il est fortement déconseillé de laisser la possibilité de réaliser une connexion Web sur le compte root, et que vous ne devriez pas autoriser les connexions non locales sur le port TCP 901. L'utilisation de SWAT ne pose pas vraiment de problèmes et ne sera donc pas décrite plus en détail ici.
IX-G-4. Configuration d'un client SMB▲
L'utilisation des volumes partagés par l'intermédiaire du protocole SMB sous Linux est très simple. Elle se fait exactement comme pour NFS : il suffit simplement de monter le volume dans un répertoire vide de l'arborescence de votre système de fichiers.
Pour que cela puisse être réalisable, il faut bien entendu que le noyau supporte le système de fichiers SMB. Ce système de fichiers est considéré par le noyau exactement comme le système de fichiers NFS : il s'agit d'un système de fichiers réseau. Vous pourrez donc activer le support de ce système de fichiers à l'aide de l'option de configuration « SMB filesystem support (to mount WfW shares etc.) », que vous trouverez normalement dans le menu « Network File Systems » (ce menu est un sous-menu du menu « Filesystems » si vous utilisez le programme de configuration en mode texte). La compilation du noyau et son installation ont été décrites en détail dans la Section 7.3.
Lorsque vous aurez configuré et installé ce noyau, vous pourrez monter les volumes partagés par des serveurs de fichiers SMB (qu'il s'agisse de serveurs Linux ou Windows) exactement comme n'importe quel système de fichiers, et accéder à leurs ressources. Malheureusement, la commande mount du système ne supporte pas encore complètement le système de fichiers SMB. Elle utilise donc un programme complémentaire nommé smbmount, fourni avec la distribution de Samba. Notez bien que ce programme ne fait pas officiellement partie de Samba, il est seulement fourni en tant qu'utilitaire complémentaire pour Linux. Bien qu'il fasse également partie d'un paquetage indépendant, il est recommandé d'utiliser la version fournie avec Samba. Cela signifie que vous devrez installer Samba sur les postes clients, même si vous ne lancez pas les démons smbd et nmbd. La commande standard mount du système sera peut-être modifiée un jour pour intégrer toutes les fonctionnalités de la commande smbmount, ce qui rendra inutile l'installation de Samba sur les postes clients.
Quoi qu'il en soit, la syntaxe de la commande smbmount est très simple :
smbmount partage répertoireoù partage est le nom de partage du volume à monter, et répertoire est son point de montage (par exemple, /mnt/). Le nom de partage utilisé est exactement le même nom que celui utilisé par Windows, à ceci près que les antislashs ('\') sont remplacés par des slashs ('/'). Ainsi, pour monter dans /mnt/ le partage Données du serveur de fichiers SMBSERVER, vous devrez utiliser la commande suivante :
smbmount //smbserver/données /mntRemarquez que le protocole SMB ne fait pas la distinction entre les majuscules et les minuscules (tout comme Windows d'une manière générale), et que vous pouvez utiliser indifféremment les majuscules ou les minuscules.
L'utilisation des slashs à la place des antislashs dans le nom du partage est due au fait que l'antislash est un caractère spécial que shell interprète comme étant la poursuite de la commande courante sur la ligne suivante. Vous pouvez utiliser des antislashs si vous le désirez, mais dans ce cas, vous devrez mettre le nom de partage entre guillemets, pour empêcher le shell de les interpréter. Malheureusement, l'antislash est également un caractère d'échappement dans les chaînes de caractères, et est utilisé pour introduire des caractères spéciaux. Étant lui-même un caractère spécial, il doit lui aussi être précédé d'un antislash d'échappement ! Il faut donc doubler tous les antislashs, et la commande précédente devient particulièrement longue et peu pratique avec cette syntaxe :
smbmount "\\\\smbserver\\données" /mntIl est très facile de faire des erreurs avec de telles commandes, aussi je ne vous la conseille pas.
En fait, il est possible de faire en sorte que la commande mount classique du système puisse être utilisée pour réaliser les montages de partages SMB à partir de la version 2.0.6. ou plus de Samba. Pour cela, il suffit de créer dans le répertoire /sbin/ un lien symbolique mount.smbfs vers la commande smbmount. Lorsqu'on utilisera la commande mount avec le type de système de fichiers smbfs, celle-ci utilisera ce lien et appellera ainsi automatiquement smbmount. Les paramètres fournis à mount seront transmis tels quels à smbmount. En particulier, vous pourrez utiliser une commande de ce type :
mount -t smbfs partage répertoireoù partage et répertoire sont toujours les noms de partage et de répertoire devant servir de point de montage.
Une fois le partage monté, vous pouvez l'utiliser comme un système de fichiers classique. Lorsque vous aurez fini de l'utiliser, vous pourrez simplement le démonter, avec la commande smbumount :
smbumount /mntIl est également possible d'utiliser la commande système classique umount, mais cela nécessite de repasser sous le compte root, ou de fixer le bit setuid sur l'exécutable de umount, ce qui est un énorme trou de sécurité. La commande smbumount en revanche peut être setuid, car elle vérifie que l'utilisateur ne cherche à démonter que les partages qu'il a lui-même montés.
Les partages au niveau ressource ne prennent pas en compte la notion d'utilisateur et de groupe d'utilisateurs des systèmes de fichiers Unix classiques. Par conséquent, le propriétaire et le groupe des fichiers accédés par un partage de ressources sont fixés par défaut à l'utilisateur qui a effectué le montage et à son groupe. Cela est naturel et ne pose pas de problèmes pour la plupart des utilisateurs, mais peut être gênant lorsqu'on monte un partage en tant que root pour le compte d'un autre utilisateur. Pour résoudre ce problème, il est possible de préciser le nom de l'utilisateur et son groupe à l'aide des options uid et gid de la commande smbmount :
smbmount partage répertoire -o uid=utilisateur,gid=groupeoù utilisateur et groupe sont respectivement les noms ou les numéros de l'utilisateur et du groupe auquel les fichiers devront être attribués. Les paramètres uid et gid peuvent également être utilisés avec la commande mount. Dans ce cas, ils sont passés tels quels à smbmount.
Vous l'aurez sans doute remarqué, la commande smbmount vous demande de taper un mot de passe pour accéder au partage. Ce mot de passe est le mot de passe attendu par le serveur de fichiers SMB. Pour Windows, il s'agit du mot de passe attribué au partage. Pour les serveurs de fichiers Samba, il s'agit du mot de passe de l'utilisateur au nom duquel se fait le partage, ou du mot de passe SMB enregistré dans le fichier de mots de passe smbpasswd de Samba. Dans tous les cas, ce mot de passe est demandé, même s'il est vide. La commande smbmount peut accepter une option password, qui permet de préciser ce mot de passe. Cependant, il est fortement déconseillé de l'utiliser, et ce pour deux raisons. Premièrement, le mot de passe apparaît en clair lorsqu'il est saisi, et la ligne de commande peut être vue par n'importe quel utilisateur avec la commande ps. Cela pose donc un problème de sécurité évident. Deuxièmement, l'option password n'est pas reconnue par la commande mount, et ne peut donc être utilisée qu'avec smbmount. C'est pour cela qu'une autre solution a été proposée, bien qu'encore imparfaite : définir le nom d'utilisateur et le mot de passe dans la variable d'environnement USER. Pour cela, il suffit d'utiliser l'une des commandes suivantes :
export USER=utilisateur%secret
export USER=utilisateur/workgroup%secretoù utilisateur est le nom d'utilisateur classique, workgroup est le groupe de travail et secret le mot de passe sur le partage à monter. Cette technique n'est pas non plus très sûre, et n'est en aucun cas pratique.
Une autre solution, plus sûre, est de définir les paramètres d'identification et d'authentification de l'utilisateur dans un fichier et de fournir ce fichier en paramètre à la commande smbmount à l'aide de l'option credentials :
smbmount partage répertoire -o credentials=fichieroù fichier est le fichier contenant l'identification de l'utilisateur. Ce fichier utilise la syntaxe suivante :
username = utilisateur
password = secretoù utilisateur est le nom de l'utilisateur et secret son mot de passe. Cette technique est la technique recommandée pour réaliser le montage de partages SMB directement dans le fichier de configuration /etc/fstab, car c'est la seule qui permette de ne pas avoir à saisir le mot de passe ni d'avoir à le définir en clair dans une ligne de commande.