


VII. Introduction au filtrage IP▲
Dans ce chapitre nous verrons en détail la théorie du filtrage IP, ce que c'est, comment ça fonctionne et certaines choses basiques comme où placer les pare-feux, les règles de filtrage, etc.
Les questions de ce chapitre pourront être, où placer un pare-feu ? Dans la plupart des cas, c'est une question simple, mais dans des réseaux étendus cela peut devenir ardu. Quelles seraient les règles ? Qui aurait accès et où ? Qu'est-ce qu'un filtre IP ? Nous y répondrons ici.
VII-A. Qu'est-ce qu'un filtre IP ?▲
Il est important de bien comprendre ce qu'est un filtre IP. Iptables est un filtre IP, et si vous ne comprenez pas complètement cela, vous irez au devant de sérieux problèmes dans la conception de vos pare-feux.
Un filtre IP opère principalement au niveau de la couche 2 de la pile de référence TCP/IP. Iptables cependant peut également travailler au niveau de la couche 3. Mais par définition un filtre IP travaille sur la seconde couche.
Si l'implémentation du filtre IP suit strictement la définition, il devrait être capable, en d'autres termes, de filtrer les paquets basés sur leurs en-têtes IP (adresses source et destination, TOS/DSCP/ECN, TTL, protocole, etc.). Toutes choses actuellement dans l'en-tête IP. Cependant, l'implémentation de Iptables n'est pas strictement en accord avec la définition, il est aussi capable de filtrer les paquets basés sur d'autres en-têtes se trouvant dans le paquet (TCP, UDP, etc.), et l'adresse MAC.
Il y a une chose cependant sur laquelle Iptables est très strict aujourd'hui. Il ne "suit" pas les flux ou les morceaux de données ensemble. Ce serait une grosse perte de temps. Il garde la trace des paquets et regarde si ils font partie du même flux de données (via numéros d'interclassement, numéros de port, etc.) à peu près comme la vraie pile TCP/IP. Ceci est appelé traçage de connexion, et grâce à ça nous pouvons effectuer de la translation (masquage/traduction) d'adresse source et destination (généralement appelé DNAT et SNAT), aussi bien que de la vérification d'état de paquets.
Comme nous avons vu ci-dessus, Iptables ne peut pas connecter des données provenant de différents paquets entre eux, et donc vous ne pourrez jamais être tout à fait certains que vous verrez la totalité des données à tout moment. Je mentione ça car il y a constamment des questions sur les différentes listes de discussion concernant netfilter et iptables à ce sujet. Par exemple, chaque fois qu'il survient un nouveau virus basé sur Windows, diverses personnes me demandent comment supprimer tous les flux contenant une chaîne spécifique. Par exemple, si nous regardons quelque chose comme ça :
cmd.exeQue se passe-t-il si l'auteur du virus/exploit est suffisamment malin pour rendre la taille du paquet si petite que cmd tienne dans un seul paquet et .exe dans le paquet suivant ? Les fonctions d'appariement de chaîne sont incapables de passer à travers les frontières de paquet, le paquet continuera sa route.
Certains pourront se poser la question, pourquoi ne pas faire simplement des vérifications de chaîne ? C'est actuellement très simple. Ce serait trop coûteux en temps processeur. Le traçage de connexion prend déjà beaucoup de temps processeur. Ajouter une autre couche complexe au traçage de connexion, surchargerait la plupart des pare-feux. Sans parler de la quantité de mémoire supplémentaire qui serait nécessaire pour effectuer cette tâche pour chaque machine.
Il existe une seconde raison pour que cette fonctionnalité ne soit pas développée. Il existe une technique appelée proxy (mandataire). Les proxies ont été développés pour le traffic dans les couches les plus hautes, et donc répondent au mieux à ces besoins. Les proxies ont été créés à l'origine pour gérer les téléchargements et les pages les plus souvent utilisées et accélérer les transferts avec des connexions Internet lentes. Par exemple, Squid est un proxy pour le web. Une personne qui désire charger une page envoie la requête, le proxy soit extrait la requête soit reçoit la requête et ouvre la connexion au navigateur, et ensuite le connecte au serveur web et charge le fichier, et une fois chargé le fichier ou la page, l'envoie au client. Maintenant, si un second navigateur désire lire la même page, le fichier ou la page sont déja chargés par le proxy, et peuvent être envoyés directement, vous économisant du temps (et de la bande passante).
Comme vous pouvez le comprendre, les proxies ont un ensemble de fonctionnalités leur permettant de voir le contenu des fichiers qu'ils chargent. À cause de ça, ils sont bien meilleurs pour visualiser l'ensemble des flux, fichiers, pages, etc.
VII-B. Termes et expressions du filtrage IP▲
Pour pleinement comprendre les chapitres suivants il y a quelques termes et expressions généraux que vous devez connaître, incluant nombre de détails par rapport au chapitre TCP/IP. Voici une liste des termes les plus couramment utilisés dans le filtrage IP.
- Effacement/refus (Drop/Deny) - Quand un paquet est effacé ou refusé, il est tout simplement supprimé. Aucune réponse n'est faite s'il est effacé, de même l'hôte destinataire du paquet ne sera pas prévenu. Le paquet disparaît simplement.
- Rejet (Reject) - De façon basique, c'est la même chose que effacer/refuser, sauf qu'une notification est envoyée à l'hôte expéditeur du paquet rejeté. La réponse peut être spécifiée ou automatiquement calculée pour une certaine valeur. Actuellement, il n'y a malheureusement pas de fonctionnalité dans Iptables qui permette de prévenir l'hôte destinataire que le paquet a été rejeté. Ce serait très bien dans certaines circonstances, car l'hôte destinataire n'a pas la possibilité d'arrêter une attaque par DoS (Denial of Service) quand ça se produit.
- État (State) - Un état spécifique d'un paquet par rapport à l'ensemble d'un flux de paquets. Par exemple, si le paquet est le premier que voit le pare-feu ou dont il a connaissance, il est considéré comme nouveau (le paquet SYN dans une connexion TCP), ou s'il fait partie d'une connexion déja établie dont a connaissance le pare-feu. Les états sont connus par le traçage de connexion, qui garde les traces de toutes les sessions.
- Chaîne - Une chaîne contient un ensemble de règles qui sont appliquées aux paquets qui traversent la chaîne. Chaque chaîne a un but spécifique (ex. quelle table est connectée et à qui, qui spécifie que cette chaîne est habilitée à le faire), et une zone d'application spécifique (ex. seulement les paquets transmis, ou seulement les paquets destinés à un hôte). Dans Iptables il existe plusieurs chaînes différentes, comme nous le verrons plus loin.
- Table - Chaque table possède une fonctionnalité spécifique, et Iptables possède trois tables. Les tables nat, mangle et filter. Par exemple, la table filter est destinée à filtrer les paquets, tandis que la table nat est destinée aux paquets NAT (Network Address Translation).
- Match - Ce terme peut avoir deux sens différents quand il est employé avec iptables. Le premier sens est une simple correspondance qui indique à la règle ce que l'en-tête doit contenir. Par exemple, la correspondance --source nous indique que l'adresse source doit être une plage réseau spécifique ou une adresse hôte. Le second indique si la règle entière est une correspondance. Si le paquet apparie toute la règle, les instructions saut et cible seront exécutées (ex. le paquet sera supprimé).
- Cible (Target) - C'est généralement une cible placée pour chaque règle dans une table de règles. Si la règle est pleinement appariée, la spécification de cible nous indique que faire avec le paquet. Par exemple, si nous l'effaçons, l'acceptons, le traduisons (nat), etc. Il existe aussi une chose appelée spécification de saut, pour plus d'information voir la description de saut dans la liste. Enfin, il peut ne pas y avoir de cible ou de saut dans chaque règle.
- Règle (Rule) - Une règle est un ensemble de correspondances avec cible unique dans la plupart des implémentations de filtres IP, incluant l'implémentation d'Iptables. Il existe certaines implémentations qui nous permettent d'utiliser plusieurs cibles/actions par règle.
- Table de règles (Ruleset) - Une table de règles est un ensemble complet de règles placé dans une implémentation de filtre IP. Dans le cas d'Iptables, ceci inclut toutes les règles placées dans le filtre, nat et mangle, et toutes les chaînes qui suivent. La plupart du temps, elles sont écrites dans un fichier de configuration.
- Saut (Jump) - L'instruction jump est très proche d'une cible. Une instruction jump est écrite exactement de la même façon qu'une cible dans Iptables, sauf que au lieu d'écrire un nom de cible, vous écrivez un nom de chaîne. Si la règle apparie, le paquet sera désormais envoyé à la seconde chaîne et exécuté comme d'habitude dans cette chaîne.
- Traçage de connexion - Un pare-feu qui implémente le traçage de connexion est capable de suivre les connexions/flux. La possibilité de faire ceci a un impact sur le processeur et l'usage mémoire. C'est malheureusement vrai également dans Iptables, mais beaucoup de travail a été fait sur ce sujet. Cependant, le bon côté de la chose est que le pare-feu sera beaucoup plus sécurisé avec un traçage de connexion bien utilisé par celui qui en établira les règles.
- Acceptation (Accept) - Pour accepter un paquet et le laisser passer à travers les règles du pare-feu. C'est l'opposé des cibles effacement et refus, de même pour la cible rejet.
- Gestion des règles (Policy) - Il existe deux sortes de gestion des règles dans l'implémentation d'un pare-feu. En premier nous avons la gestion des chaînes, qui indiquent le comportement par défaut du pare-feu. C'est l'usage principal du terme que nous utiliserons dans ce didacticiel. Le second type de gestion des règles est la gestion de sécurité établie par une stratégie d'ensemble d'une entreprise par exemple, ou pour un segment de réseau spécifique. Les stratégies de sécurité sont des documents a étudier de près avant de commencer l'implémentation d'un pare-feu.
VII-C. Comment configurer un filtre IP ?▲
Une des premières choses à considérer lors de la configuration d'un pare-feu est son emplacement. Un des premiers endroits qui vient à l'esprit est la passerelle entre votre réseau local et l'Internet. C'est un endroit qui devrait être très sécurisé. Ainsi, dans les grands réseaux ce peut-être une bonne idée de séparer différentes divisions entre elles par des pare-feux. Par exemple, pourquoi l'équipe de développement aurait accès au réseau des ressources humaines, ou pourquoi ne pas protéger le département comptabilité des autres ?
Ceci indique que vous devriez configurer vos réseaux aussi bien que possible, et les planifier pour qu'ils soient isolés. Spécialement si le réseau est de taille moyenne ou grande (100 stations de travail ou plus, basé sur différents aspects du réseau). Dans les petits réseaux, essayez de configurer les pare-feux pour seulement autoriser le genre de trafic que vous désirez.
Ce peut être aussi une bonne idée de créer une "zone démilitarisée" (DMZ) dans votre réseau dans le cas où vous avez des serveurs qui sont connectés à l'Internet. Une DMZ est un petit réseau physique avec des serveurs, qui est isolé à l'extrême. Ceci réduit le risque que quelqu'un puisse s'introduire dans les machines de la DMZ, et également puisse y implanter des chevaux de Troie ou autre depuis l'extérieur. La raison pour laquelle nous l'appelons zone démilitarisée est qu'elle doit être joignable depuis l'intérieur et l'extérieur, et donc être une sorte de zone grise.
Il existe deux moyens pour configurer le comportement d'un pare-feu, et dans cette section nous verrons ce que vous devriez considérer avant d'implémenter votre pare-feu.
Avant de commencer, vous devriez comprendre que la plupart des pare-feux ont des comportements par défaut. Par exemple, si aucune règle n'est spécifiée dans une chaîne, elle peut-être acceptée ou effacée par défaut. Malheureusement, il y a seulement une gestion de règles par chaîne, mais il est souvent facile de les contourner si vous voulez avoir différentes gestions des règles par interface réseau, etc.
Il existe deux stratégies de base que nous utilisons habituellement. Soit nous supprimons (DROP) tout sauf ce que nous spécifions, soit nous acceptons tout excepté ce que nous spécifions comme devant être supprimé. La plupart du temps nous sommes principalement intéressés par la stratégie de suppression, et ensuite accepter ce que nous désirons de façon spécifique. Ceci indique que le pare-feu est plus sécurisé par défaut, mais il peut aussi indiquer que nous aurons plus de travail pour simplement obtenir un pare-feu qui fonctionne correctement.
Votre première décision à prendre est de simplement savoir quel type de pare-feu vous allez utiliser. Quel niveau de sécurité ? Quelles sortes d'applications pourront passer à travers le pare-feu ? Certaines applications sont horribles pour les pare-feux pour la simple raison qu'elles négocient les ports à utiliser pour les flux de données dans une session. Ceci rend extrêmement ardu pour le pare-feu de savoir quel port ouvrir. Les applications les plus communes fonctionnent avec Iptables, mais les rares autres ne fonctionnent pas à ce jour, malheureusement.
Il y a aussi quelques applications qui fonctionnent en partie, comme ICQ. L'utilisation normale d'ICQ fonctionne correctement, mais pas les fonctions de chat (discussions) et d'envoi de fichiers, car elles nécessitent un code spécifique pour décrire le protocole. Comme les protocoles ICQ ne sont pas standardisés (ils sont propriétaires et peuvent être modifiés à tout moment) la plupart des filtres ont choisis soit de ne pas le gérer, soit d'utiliser un programme de correction (patch) qui peut être appliqué aux pare-feux. Iptables a choisi de les utiliser comme programmes séparés.
Ce peut être également une bonne idée d'appliquer des mesures de sécurité en couche, ce dont nous avons discuté plus haut. Ce qui veut dire, que vous pourriez utiliser plusieurs mesures de sécurité en même temps, et pas sur un seul concept de sécurité. En prenant ceci comme concept ça décuplera vos mesures de sécurité. Pour un exemple, voir la figure :
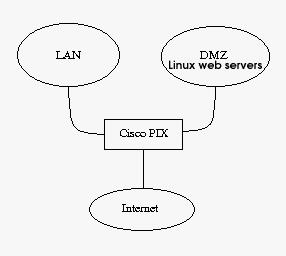
Comme vous pouvez le voir, dans cet exemple j'ai choisi de placer un pare-feu Cisco PIX dans le périmètre des trois connexions réseau. Je peux faire du NAT sur le réseau local (LAN), comme sur la DMZ si nécessaire. Il bloquera aussi tout le trafic sortant sauf les retours http ou ftp ou ssh. Il permet également le trafic http entrant depuis le LAN et l'Internet, de même pour le trafic ftp et ssh depuis le LAN. De plus, nous pouvons noter que chaque serveur web est basé sur Linux, avec Iptables et netfilter sur les machines avec les mêmes stratégies de sécurité.
En plus de tout ça, nous pouvons ajouter Snort sur chacune des machines. Snort est un excellent système de détection d'intrusion dans un réseau (NDIS) qui vérifie les signatures dans les paquets, et il peut soit envoyer un courrier à l'administrateur ou même répondre de façon active à l'attaque en bloquant l'IP expéditeur. Il faut noter que la réponse active ne doit pas être utilisée à la légère, car Snort a un comportement un peu extrême dans le rapport d'attaques (ex. rapport sur une attaque qui n'en est pas réellement une).
Une bonne idée est aussi d'ajouter un proxy en face des serveurs web pour capturer les mauvais paquets, avec la même possibilité pour toutes les connexions web générées localement. Avec un proxy web vous pouvez gérer de façon plus précise le trafic web de vos employés, aussi bien que restreindre leur usage à certaines extensions. Avec un proxy web sur vos propres serveurs, vous pouvez l'utiliser pour bloquer certaines connexions. Un bon proxy qu'il peut être intéressant d'utiliser est Squid.
Une autre précaution qui peut être prise est d'installer Tripwire. Qui est une excellente ligne de défense en dernier ressort pour ce type d'application. Il effectue une somme de contrôle sur tous les fichiers spécifiés dans le fichier de configuration, et ensuite l'exécute depuis cron pour vérifier s'ils sont identiques, ou n'ont pas changés de façon illégale. Ce programme est capable de savoir si quelqu'un a pénétré dans le système pour le modifer. Une suggestion est de l'exécuter sur tous les serveurs web.
Une dernière chose à noter est qu'il est toujours bon de suivre les standards. Comme vous l'avez déja vu avec ICQ, si vous ne suivez pas les systèmes standardisés, ça peut provoquer de grosses erreurs. Dans votre propre environnement ceci peut être ignoré pour certains domaines, mais si vous êtes sur une large bande ou une baie de modems, ça peut devenir très important. Les personnes qui se connectent doivent toujours pouvoir accéder aux services, et vous ne pouvez pas espérer que ces personnes utilisent le système d'exploitation de votre choix. Certaines personnes travaillent sous Windows, certaines autres sous Linux ou même VMS, etc. Si vous fondez votre sécurité sur des systèmes propriétaires, vous allez au devant de problèmes.
Un bon exemple de ceci est certains services à large bande qui sont apparus en Suède et qui fondent leur sécurité sur des ouvertures de session réseau Microsoft. Ceci peut sembler une bonne idée au départ, mais lorsque vous considerez d'autres systèmes d'exploitation, ce n'est pas une si bonne idée. Comment quelqu'un tournant sous Linux fera-t-il ? Ou VAX/VMS ? Ou HP/UX ? Avec Linux on peut le faire bien sûr, si l'administrateur réseau ne refuse pas à quiconque d'utiliser le service s'ils utilisent Linux. Cependant, ce didacticiel n'est pas une discussion théologique pour savoir qui est le meilleur, c'est simplement un exemple pour vous faire comprendre que c'est une mauvaise idée de ne pas utiliser les standards.
VII-D. Au prochain chapitre▲
Ce chapitre vous a montré certains éléments de base du filtrage IP et des mesures de sécurité que vous pouvez appliquer pour sécuriser vos réseaux, stations de travail et serveurs. Les sujets suivants ont été approchés :
- Utilisation du filtrage IP
- Stratégies de filtrage IP
- Planification de réseau
- Planification de pare-feu
- Techniques de sécurité en couche
- Segmentation de réseau
Dans le prochain chapitre nous verrons rapidement la Translation d'Adresse Réseau (NAT), et ensuite regarderons de plus près Iptables et ses fonctionnalités.