


VI. Administration du système de base▲
Un certain nombre d'opérations que l'on peut faire avec un système Unix ne rentrent pas dans le cadre d'une utilisation quotidienne, mais sont destinées plutôt à l'administration du système lui-même. Ces opérations peuvent être réalisées à l'aide de commandes Unix spéciales, généralement réservées à l'administrateur du système, ou peuvent être réalisées en modifiant les fichiers de configuration du système.
Il est très probable que le programme d'installation ou le programme de configuration de votre distribution vous permette d'effectuer ces tâches de manière relativement aisée ou conviviale. L'utilisation de ces programmes est très simple, puisqu'en général il suffit de répondre à quelques questions et les modifications sont effectuées automatiquement pour vous. Il est fortement recommandé de toujours essayer les programmes de ce type en premier lieu, car eux seuls connaissent les spécificités de chaque distribution. Cela dit, ces programmes ne peuvent pas tout prévoir, parce que Linux est un système capable d'effectuer un grand nombre de tâches très diversifiées d'une part, et parce que ce que vous voulez en faire personnellement ne correspond pas forcément à un standard prédéterminé d'autre part.
Cette partie décrira donc les commandes d'administration et de maintenance les plus importantes et le mécanisme général d'amorçage des systèmes Linux. Les principaux fichiers de configuration permettant de modifier le comportement du système seront également décrits afin de permettre un usage courant de Linux dans de bonnes conditions. Les notions les plus avancées concernant l'administration système ne seront en revanche pas abordées, car cela dépasserait le cadre de ce document. Les lecteurs les plus intéressés pourront toujours se référer à un guide d'administration Unix.
L'administration du système est un peu moins sensible que son installation. En effet, les seuls risques que l'on encourt sont de détruire les fichiers de configuration du système, et donc de devoir les recréer manuellement. Il n'y a pas de manipulation de partitions ou de système de fichiers à créer, aussi le risque de perdre des données est-il nettement plus faible. Cependant, les opérations d'administration se feront sous le compte root, ce qui implique une prudence extrême. C'est pour cette raison que nous allons commencer par sauvegarder l'ensemble des fichiers de configuration, afin de pouvoir revenir à l'état initial après installation, sans repasser par la case départ.
VI-A. Sauvegarde de la configuration d'installation▲
La sauvegarde de la configuration du système est une opération facile à réaliser. En effet, tous les fichiers de configuration sont placés dans le répertoire /etc/. Par conséquent, il suffit de faire une archive des fichiers de ce répertoire et de ses sous-répertoires. Cette opération peut être réalisée avec la commande suivante :
tar cvfz /root/install.conf.tar.gz /etc/*Cette commande créera une archive nommée install.conf.tar.gz dans le répertoire personnel de l'administrateur système. On notera que, pour certaines distributions, quelques fichiers de configuration sont placés dans le répertoire /sbin/init.d/. Pour ces distributions, on utilisera donc plutôt la commande suivante :
tar cvfz /root/install.conf.tar.gz /etc/* /sbin/init.d/*De cette manière, si l'on a un gros problème avec la configuration de la machine, on peut revenir simplement à la configuration utilisée juste après l'installation du système avec la simple commande suivante :
tar xvfz /root/install.conf.tar.gzcommande que l'on exécutera dans la racine du système de fichiers.
Cette commande écrasera tous les fichiers existants par ceux de la sauvegarde. Les fichiers qui ont été ajoutés depuis cette sauvegarde seront bien entendu conservés.
Il est également recommandé de faire une sauvegarde identique à celle-ci une fois que l'on aura réussi à configurer le système correctement et que, théoriquement, il n'y aura plus à toucher aux fichiers de configuration. Cette sauvegarde devra être placée sur une disquette ou un support amovible que l'on conservera en lieu sûr.
VI-B. Mise à l'heure du système▲
Les systèmes d'exploitation utilisent l'heure pour un certain nombre de tâches. En particulier, les fichiers disposent de plusieurs dates (date de création, date d'accès et date de dernière modification), qui sont utilisées par différents programmes. Les programmes de sauvegarde en font évidemment partie, parce qu'ils se basent sur les dates de modification des fichiers pour déterminer quels sont les fichiers qui doivent être sauvegardés depuis la dernière sauvegarde (cas des sauvegardes dites « incrémentales »). Les programmes de maintenance sont également lancés à des dates précises, et les applications normales des utilisateurs peuvent utiliser la date système pour l'intégrer dans leurs documents. En clair, il est important que votre système soit à l'heure.
En fait, il existe deux horloges dans votre système. La première horloge, qui est l'horloge de référence pour toutes les opérations effectuées dans le système, est l'horloge dite « système ». Cette horloge est maintenue par le noyau grâce à un compteur qui est incrémenté régulièrement, sur la base d'une interruption matérielle. La précision de ce compteur est a priori la même que celle de l'interruption du timer matériel. Sur les PC, cette interruption a lieu, par défaut, 18,6 fois par seconde, ce qui donne pour la plus petite unité de temps mesurable environ 1/20 de seconde (cependant, la plupart des systèmes reprogramment la fréquence de cette interruption à 100 Hz environ). La deuxième horloge est l'horloge matérielle, qui est l'horloge qui maintient l'heure de votre ordinateur pendant qu'il est éteint. Cette horloge est couramment appelée l'horloge CMOS, parce qu'elle est gérée par un composant CMOS qui stocke toutes les informations permanentes du BIOS.
Pour répondre immédiatement à une question (désormais sans objet), précisons que Linux n'a aucun problème vis-à-vis des dates critiques du changement de millénaire. En effet, les systèmes Unix n'utilisent qu'un seul format de date au niveau application : le nombre de secondes écoulées depuis le 01/01/1970 à 0 heure. Ce compteur est stocké sur 32 chiffres binaires sur la plupart des machines et passe donc allègrement le cap de l'an 2000. En fait, le débordement de ce compteur est prévu pour 2038, mais n'aura jamais lieu, car l'apparition des processeurs 64 bits va porter, d'ici là, la taille de ce compteur à 64 bits. Cela étant, il est possible que certaines applications mal écrites n'utilisent pas ce format de date, et ne soient donc pas compatibles. Heureusement, ce cas de figure est très rare sous Unix. Bien entendu, le problème reste entier si l'horloge matérielle de votre PC n'est pas compatible. Dans ce cas, la solution la plus simple est de régler l'heure système à chaque démarrage, manuellement ou à l'aide de scripts de correction de la date renvoyée par l'horloge matérielle.
La valeur du compteur de l'horloge système est toujours interprétée en temps universel (« UTC » en anglais, abréviation de « Universal Time Coordinated »), c'est-à-dire le temps de référence valide dans le monde entier. Ce temps ne comprend pas les fuseaux horaires ni les réglementations concernant les heures d'hiver et d'été. Cette convention est utilisée partout dans le système, ce qui est la condition sine qua non pour que tous les ordinateurs du monde utilisent la même date et la même heure. Ainsi, deux ordinateurs connectés à Internet peuvent communiquer sans se poser de questions quant à leurs localisations respectives, ce qui simplifie beaucoup les choses. Notez également que le fait de compter le temps en secondes permet de s'affranchir des conventions de découpage du temps et des calendriers utilisés dans chaque pays.
Bien entendu, les dates présentées à l'utilisateur doivent être traduites en temps local, corrigé des écarts pour l'heure d'été et l'heure d'hiver. Cela est réalisé par tous les programmes qui doivent afficher ces dates (par exemple, les simples commandes ls et date). Cette conversion est effectuée par le système en fonction du fuseau horaire et des plages de validité des horaires d'été et d'hiver.
La solution la plus simple pour régler la date et l'heure de votre machine est donc de régler l'horloge matérielle sur le temps universel, et de définir le fuseau horaire dans lequel elle se trouve, pour que le système puisse calculer l'heure locale. Malheureusement, les systèmes d'exploitation de Microsoft ne voient pas la chose de la même manière. Ils attendent que l'horloge matérielle soit réglée à l'heure locale. Par conséquent, si Linux est installé sur un ordinateur disposant déjà de Windows, vous devrez régler l'heure de votre ordinateur en temps local. A priori, cela ne fait aucune différence, le système étant également capable de calculer le temps universel à partir de l'heure locale et de la zone horaire. Cependant, cela a un inconvénient : il est nécessaire de mettre à l'heure l'horloge système en cas de déplacement de la machine, et à chaque changement d'horaire d'été ou d'hiver. Bien sûr, Windows est supposé être capable de mettre à jour l'heure matérielle en « observation avec l'heure d'été / d'hiver ». Mais il utilise pour cela des règles qui sont fixées définitivement dans le système et qui ne peuvent pas être mises à jour avec les réglementations locales (par exemple, la règle de changement d'heure a été modifiée en 1996, si bien que Windows 95 n'a jamais pu fonctionner correctement sur ce point…).
Quoi qu'il en soit, la mise à l'heure d'un système Linux requiert la définition de la zone horaire, la mise à l'heure du système et la mise à l'heure de l'horloge matérielle. La définition de la zone horaire est primordiale et doit avoir lieu avant toute autre opération, car le réglage des horloges dépend évidemment de cette zone.
Les zones horaires sont définies par un ensemble de règles, qui comprennent chacune la période de validité de la règle (en général avec une date de départ et une date de fin) et la différence entre le temps universel et le temps local lorsque cette règle s'applique (gestion des horaires d'été et d'hiver compris). Toutes ces règles portent le nom de la zone géographique dans laquelle elles sont valides. Vous pourrez trouver des exemples de définitions de règles (ainsi que l'historique des conventions concernant le temps) dans le répertoire « timezone » des sources de la bibliothèque C GNU.
Les fichiers de règles des zones horaires doivent être compilés avec le programme zic et installés dans le répertoire /usr/share/zoneinfo. Normalement, votre système dispose de la totalité des règles, déjà compilées, des différentes zones horaires du monde. Le programme zic permet également de définir la zone horaire active. Cette opération se fait dans les fichiers de démarrage de votre système, avec une commande similaire à la suivante :
zic -l zoneoù zone est le chemin relatif du fichier de définition des règles de la zone horaire locale, par rapport au répertoire de base /usr/share/zoneinfo. Pour les systèmes situés en France métropolitaine, la commande utilisée est donc celle-ci :
zic -l Europe/ParisUne fois la zone horaire fixée, il est possible de régler l'horloge système. Il existe deux solutions pour cela. La première solution est d'utiliser la commande système date. Cette commande, appelée sans paramètres, permet d'obtenir la date système, exprimée en temps local. Mais elle permet également de modifier la date et l'heure système avec l'option -s. La syntaxe complète utilisée est donnée ci-dessous :
date -s "MM/JJ/AAAA HH:MM:SS"Il n'est pas nécessaire de préciser l'année si celle-ci ne doit pas être changée. De même, vous pouvez ne donner que l'heure, si la date du jour est correcte. En revanche, vous devez obligatoirement préciser l'heure si vous changez la date. Notez que l'heure doit être donnée en temps local, à moins que l'option -u ne soit précisée. Le système réglera son horloge en temps universel automatiquement, selon les règles de zones horaires en vigueur qui ont été indiquées par zic. Vous pouvez obtenir l'heure exacte en appelant le 3699.
La deuxième solution est celle qui est utilisée au démarrage du système. Elle consiste à initialiser l'horloge système à partir de l'horloge matérielle. Cette opération se fait normalement à l'aide de la commande clock (qui en fait est un lien symbolique vers hwclock, mais la commande Unix traditionnelle est clock). La syntaxe de cette commande est la suivante :
clock [-u] -s | -w | -aL'option -s permet d'initialiser l'horloge système à partir de la date et de l'heure stockées dans l'horloge matérielle. C'est typiquement cette commande qui est utilisée dans les scripts de démarrage du système. L'option -w permet de réaliser l'opération inverse, c'est-à-dire sauvegarder la date et l'heure de l'horloge système dans l'horloge matérielle. Elle n'est en général utilisée qu'après avoir remis à l'heure l'horloge système. L'option -a permet, quant à elle, de corriger l'avance ou le retard que l'horloge matérielle peut prendre.
Ce dernier point mérite quelques explications complémentaires. En fait, l'horloge matérielle n'est pas extrêmement précise, et peut se décaler petit à petit de l'heure réelle. Heureusement, ce décalage est constant, ce qui fait qu'il est possible de le mesurer et de le prendre en compte. Le programme clock utilise le fichier /etc/adjtime pour enregistrer de combien est ce décalage afin de pouvoir effectuer les corrections. Le principe de fonctionnement est le suivant :
- lors du premier réglage de l'horloge matérielle (avec l'option -w), il enregistre l'instant de ce réglage dans le fichier /etc/adjtime ;
- lors des réglages suivants, il calcule le temps qui s'est écoulé depuis le réglage précédent, et le décalage entre l'heure de l'horloge matérielle et l'heure à laquelle celle-ci aurait dû se trouver. Il enregistre ce décalage et met à jour la date de mise à l'heure (pour pouvoir refaire ce calcul ultérieurement) ;
- lorsqu'on l'appelle avec l'option -a, clock ajuste l'horloge matérielle. Pour cela, il regarde la date courante, calcule le temps écoulé depuis la dernière mise à l'heure ou le dernier ajustement, en déduit l'avance ou le retard de l'horloge matérielle, et la remet à l'heure en conséquence. Il enregistre également la date de cet ajustement comme nouvelle date de mise à l'heure, afin de ne pas faire deux fois l'ajustement pour cette période la prochaine fois.
De cette manière, il est possible de maintenir l'horloge système à une valeur proche de la réalité (sans ce genre de mécanisme, il est courant de prendre 5 minutes d'écart en trois ou quatre mois, ce qui est déjà considérable).
Les scripts d'initialisation de votre système doivent donc certainement contenir au moins les deux lignes suivantes après le réglage de la zone horaire :
# Ajuste l'horloge matérielle :
clock -a
# Initialise l'horloge système :
clock -sDans tous les cas, l'option -u permet d'indiquer que l'horloge matérielle est réglée en temps universel. Si votre machine ne dispose pas d'autre système que Linux, il est recommandé de procéder ainsi et d'utiliser systématiquement cette option.
Note : Il est important de définir la zone horaire avec zic avant d'utiliser clock. En effet, si l'horloge matérielle est réglée en temps local, clock ne pourra pas déterminer l'heure en temps universel. D'autre part, clock initialise la structure de zone horaire interne noyau, que celui-ci utilise notamment pour l'écriture des dates en temps local sur les systèmes de fichiers FAT (Eh oui, les dates des fichiers des systèmes de fichiers FAT sont enregistrées en temps local…).
Sachez également que l'horloge système peut également se décaler sensiblement sur de longues périodes. Évidemment, ce phénomène ne peut se détecter que si le système reste actif suffisamment longtemps, ce qui en pratique ne se produit que dans les serveurs (n'oubliez pas que Linux peut fonctionner des mois sans interruption…). Si vous êtes intéressé par la manière de resynchroniser l'horloge système pour de telles configurations, vous devriez vous intéresser à la diffusion du temps sur le réseau Internet avec le protocole NTP (« Network Time Protocol »). En général, la resynchronisation de l'heure système doit se faire progressivement afin de ne pas perturber la ligne du temps pour les applications. Cela peut être fait avec le programme adjtimex.
VI-C. Gestion des utilisateurs et de la sécurité▲
La règle de sécurité numéro un sous Unix est de ne jamais travailler dans le compte root. En effet, ce compte dispose de tous les droits, et la moindre erreur de la part de l'utilisateur dans ce compte peut endommager non seulement ses propres données, mais également l'ensemble du système d'exploitation. De plus, le fait de ne pas travailler sous le compte root restreint à un seul utilisateur les dégâts que pourraient faire un éventuel virus ou programme défectueux.
L'une des premières étapes dans l'installation d'un système est donc de créer un compte utilisateur normal, qui devra être utilisé pour le travail quotidien. Le compte root ne doit donc être réservé qu'aux tâches d'administration, et toute opération réalisée sous cette identité doit être contrôlée deux fois avant d'être effectivement lancée. Les programmes d'installation des distributions demandent donc toujours un mot de passe pour protéger le compte root et le nom et le mot de passe pour au moins un compte utilisateur standard après une nouvelle installation. Le mot de passe root doit être choisi avec un grand soin, surtout si l'ordinateur est susceptible d'être connecté à Internet. En effet, la moindre erreur de configuration au niveau des services fournis par l'ordinateur, couplée avec un mot de passe faible, risque de laisser votre ordinateur à la merci de pirates mal intentionnés.
Ces mêmes programmes d'installation peuvent être utilisés par la suite pour ajouter de nouveaux utilisateurs dans le système. Il est d'ailleurs recommandé de les utiliser dès qu'une telle opération doit être effectuée. Cela dit, il est bon de connaître la manière dont les utilisateurs sont gérés dans les systèmes Unix, aussi une approche plus bas niveau sera-t-elle adoptée dans cette section.
VI-C-1. Mécanismes d'authentification des utilisateurs▲
La sécurité des systèmes Unix repose fondamentalement sur les mécanismes d'authentification des utilisateurs. Ces mécanismes visent à s'assurer que chacun est bien celui qu'il prétend être, afin de donner à chacun les droits d'accès aux différents services du système en fonction de ses privilèges.
L'accès aux services du système repose donc sur deux opérations essentielles : l'identification et l'authentification. L'opération d'identification consiste à annoncer qui l'on est, afin de permettre au système de déterminer les droits auxquels on a droit, et l'opération d'authentification consiste à « prouver » qu'on est bien celui qu'on prétend être. Le système refuse ses services à tout utilisateur inconnu (c'est-à-dire qui s'est identifié sous un nom inconnu) ou qui n'a pas passé avec succès la phase d'authentification.
En interne, les systèmes Unix identifient les utilisateurs par un numéro qui est propre à chacun, son « UID » (abréviation de l'anglais « User IDentifier »), mais il existe une correspondance entre cet UID et un nom d'utilisateur plus humainement lisible. Ce nom est classiquement appelé le « login », en raison du fait que c'est la première chose que le système demande lorsqu'on cherche à accéder à ses services, pendant l'opération dite de login.
L'authentification des utilisateurs se fait classiquement par mot de passe, bien que d'autres mécanismes soient possibles en théorie. L'accès au système se passe donc toujours de la manière suivante :
- le système demande à l'utilisateur son nom (c'est-à-dire son login) ;
- il demande ensuite son mot de passe ;
- il vérifie la validité du couple (login / mot de passe) pour déterminer si l'utilisateur a le droit de l'utiliser ;
- et, si l'utilisateur est connu et s'est correctement authentifié, le programme qui a réalisé l'authentification prend l'identité et les privilèges de l'utilisateur, fixe son environnement et ses préférences personnelles, puis lui donne accès au système.
L'exemple classique de ces opérations est tout simplement l'opération de login sur une console : le programme getty de gestion de la console demande le nom de l'utilisateur, puis passe ce nom au programme login qui l'authentifie en lui demandant son mot de passe. Si l'authentification a réussi, il prend l'identité de cet utilisateur et lance son shell préféré. La suite des opérations dépend du shell. S'il s'agit de bash, le fichier de configuration /etc/profile est exécuté (il s'agit donc du fichier de configuration dans lequel toutes les options communes à tous les utilisateurs pourront être placées par l'administrateur), puis les fichiers de configuration ~/.bash_profile et ~/.bashrc sont exécutés. Ces deux fichiers sont spécifiques à chaque utilisateur et permettent à chacun d'entre eux de spécifier leurs préférences personnelles. Le fichier ~/.bash_profile n'est exécuté que lors d'un nouveau login, alors que le fichier ~/.bashrc est exécuté à chaque nouveau lancement de bash.
Bien entendu, ces opérations nécessitent que des informations relatives aux utilisateurs soient stockées dans le système. Historiquement, elles étaient effectivement stockées dans le fichier de configuration /etc/passwd. Cela n'est, en général, plus le cas. En effet, cette technique se révèle peu pratique lorsque plusieurs ordinateurs en réseau sont accédés par des utilisateurs itinérants. Dans ce genre de configuration, il est courant de recourir à un service réseau permettant de récupérer les informations concernant les utilisateurs à partir d'un serveur centralisé. Plusieurs solutions existent actuellement (NIS, LDAP, etc.), mais elles fonctionnent toutes plus ou moins selon le même principe. De plus, même pour des machines isolées, le fichier /etc/passwd ne contient plus que les informations « publiques » sur les utilisateurs. Les informations utilisées pour l'authentification sont désormais stockées dans un autre fichier de configuration, qui n'est lisible que pour l'utilisateur root : le fichier /etc/shadow. La raison première de procéder ainsi est d'éviter que des utilisateurs malicieux puissent « casser » les mots de passe.
Note : Les mots de passe n'ont jamais été stockés en clair dans le fichier passwd. Le mécanisme d'authentification repose en effet sur une fonction à sens unique générant une empreinte. Les fonctions de ce type ne disposent pas de fonction inverse, il n'est donc virtuellement pas possible de retrouver un mot de passe à partir de son empreinte. Lorsqu'un utilisateur saisit son mot de passe, l'empreinte est recalculée de la même manière que lorsqu'il l'a défini initialement, et c'est cette empreinte qui est comparée avec celle qui se trouve dans le fichier /etc/passwd ou le fichier /etc/shadow. Ainsi, il est nécessaire de connaître le mot de passe en clair pour authentifier l'utilisateur, mais à aucun moment ce mot de passe n'est stocké sur le disque dur.
Cela dit, même si la récupération des mots de passe est quasiment impossible, la connaissance des empreintes des mots de passe peut être d'une aide précieuse. Un intrus potentiel peut essayer de calculer les empreintes de tous les mots de passe possibles et imaginables à l'aide d'un dictionnaire ou de mots de passe probablement choisis par les utilisateurs peu inventifs, et comparer le résultat avec ce qui se trouve dans le fichier de mot de passe. S'il y a une correspondance, l'intrus pourra pénétrer le système et tenter d'utiliser d'autres failles pour acquérir les droits de l'utilisateur root. Cette technique, dite attaque du dictionnaire, est tout à fait réalisable, d'une part parce que la puissance des machines actuelles permet de calculer un nombre considérable d'empreintes à la seconde, et d'autre part parce que bon nombre de personnes utilisent des mots de passe triviaux (leur date de naissance, le nom de leur chien, etc.) facilement devinables et testables.
Les systèmes Unix utilisent deux techniques pour pallier ces problèmes. La première est de ne pas calculer l'empreinte du mot de passe tel qu'il est fourni par l'utilisateur, mais de la calculer avec une donnée générée aléatoirement et stockée dans le fichier de mot de passe. Cette donnée, que l'on appelle classiquement « sel », jour le rôle de vecteur d'initialisation de l'algorithme de génération d'empreinte. Le sel n'est jamais le même pour deux utilisateurs, ce qui fait que deux utilisateurs qui auraient le même mot de passe n'auraient toutefois pas la même empreinte. Cela complique la tâche des attaquants qui utilisent la force brute, car ils doivent ainsi recalculer les empreintes pour chaque utilisateur.
La deuxième technique utilisée est tout simplement de ne pas laisser le fichier des empreintes accessible à tout le monde. C'est pour cela que le fichier de configuration /etc/shadow a été introduit. Étant lisible uniquement par l'utilisateur root, un pirate ne peut pas récupérer les empreintes de mots de passe pour les comparer avec des empreintes de mots de passe précalculées. Il doit donc essayer les mots de passe un à un, ce qui peut en décourager plus d'un, surtout si le système se bloque pendant un certain temps après quelques tentatives infructueuses…
La technique d'authentification par mot de passe peut paraître relativement primitive, à l'heure où les cartes à puce sont légion et où l'on commence à voir apparaître des scanners d'empreintes digitales. En fait, c'est une bonne solution, mais qui ne saurait en aucun cas être exhaustive en raison des problèmes mentionnés ci-dessus. L'idéal est donc d'utiliser plusieurs systèmes d'authentification en série, ce qui laisse libre cours à un grand nombre de possibilités.
Il est évident que la technique des mots de passe traditionnellement utilisée sur les systèmes Unix n'évoluera pas aisément vers de nouveaux mécanismes d'authentification. C'est pour cela que les programmes devant réaliser une opération d'authentification ou de gestion des utilisateurs de manière générale ont été modifiés pour utiliser la bibliothèque PAM (abréviation de l'anglais « Pluggable Authentification Modules »). Cette bibliothèque permet de réaliser les opérations d'identification et d'authentification de manière externe aux programmes qui l'utilisent, et se base pour ces opérations des fichiers de configuration et des modules dynamiquement chargeables. Ainsi, grâce à la bibliothèque PAM, l'administrateur peut définir avec précision les différentes opérations réalisées pour identifier et authentifier les utilisateurs, sans avoir à modifier les programmes qui ont besoin de ces fonctionnalités. De plus, il est possible d'ajouter de nouveaux modules au fur et à mesure que les besoins évoluent, et de les intégrer simplement en modifiant les fichiers de configuration.
De nos jours, la plupart des distributions utilisent la bibliothèque PAM. Bien entendu, il existe des modules qui permettent de réaliser les opérations d'identification et d'authentification Unix classiques, et ce sont ces modules qui sont utilisés par défaut. Nous verrons le format des fichiers de configuration de la bibliothèque PAM plus en détail dans les sections suivantes.
Note : Les mécanismes décrits ici ne sont sûrs que dans le cadre d'une connexion sur un terminal local. Cela dit, il faut bien prendre conscience que la plupart des applications réseau sont de véritables passoires ! En effet, ils utilisent des protocoles qui transmettent les mots de passe en clair sur le réseau, ce qui implique que n'importe quel pirate peut les capter en moins de temps qu'il n'en faut pour le dire. Les protocoles applicatifs suivants sont réputés pour être non sûrs et ne devront donc JAMAIS être utilisés sur un réseau non sûr (et donc, à plus forte raison, sur Internet) :
- TELNET, qui permet d'effectuer des connexions à distance :
- FTP, qui permet de transférer et de récupérer des fichiers sur une machine distante ;
- POP3, qui permet de consulter son mail ;
- SMTP, qui permet d'envoyer des mails à un serveur de messagerie ;
- X, qui permet aux applications graphiques d'afficher leurs fenêtres sur un terminal X.
Cette liste n'est pas exhaustive, mais regroupe déjà les protocoles réseau des applications les plus utilisées.
La sécurisation de ces protocoles ne peut se faire qu'en les encapsulant dans un autre protocole utilisant un canal de communication chiffré. L'un des outils les plus courants pour cela est sans doute ssh. Cet outil sera décrit dans la Section 9.5.2.2 du chapitre traitant du réseau.
VI-C-2. Création et suppression des utilisateurs▲
La création d'un nouvel utilisateur est une opération extrêmement facile. Il suffit simplement de lui créer un répertoire personnel dans le répertoire /home/ et de le définir dans le fichier de configuration /etc/passwd. Si votre système utilise les shadow passwords, ce qui est probable, il faut également définir cet utilisateur dans le fichier de configuration /etc/shadow. De plus, il faut ajouter cet utilisateur dans au moins un groupe d'utilisateurs dans le fichier /etc/group.
Le fichier de configuration /etc/passwd est constitué de plusieurs lignes, à raison d'une ligne par utilisateur. Chaque ligne est constituée de plusieurs champs, séparés par deux points (caractère ':'). Ces champs contiennent respectivement le login de l'utilisateur, l'empreinte de son mot de passe, son identifiant numérique, l'identifiant numérique de son groupe principal, son nom complet ou un commentaire, le chemin de son répertoire personnel et le chemin sur son interpréteur de commandes favori. Si le champ du mot de passe contient un astérisque, le compte est désactivé. S'il est vide, le mot de passe est stocké dans le fichier /etc/shadow.
Le fichier de configuration /etc/shadow a une syntaxe similaire à celle de /etc/passwd, mais contient les champs suivants : le login de l'utilisateur, l'empreinte de son mot de passe, le nombre de jours depuis que le mot de passe a été défini (comptés à partir du premier janvier 1970), le nombre de jours après cette date à attendre avant que le mot de passe puisse être changé, le nombre de jours au-delà duquel le mot de passe doit obligatoirement être changé, le nombre de jours avant la date d'expiration de son mot de passe pendant lesquels l'utilisateur doit être averti que son mot de passe va expirer, le nombre de jours à attendre avant de désactiver le compte après l'expiration du mot de passe, et le nombre de jours depuis que le compte est désactivé, compté depuis le premier janvier 1970. Il est possible de supprimer l'obligation pour les utilisateurs de changer régulièrement de mot de passe en donnant un nombre de jours minimum supérieur au nombre de jours maximum avant le changement de mot de passe.
Enfin, le fichier de configuration /etc/group, dans lequel les groupes d'utilisateurs sont définis, ne dispose que des champs suivants : le nom du groupe, son mot de passe (cette fonctionnalité n'est plus utilisée), son identifiant numérique, et la liste des utilisateurs qui y appartiennent, séparés par des virgules.
Bien entendu, tous ces champs ne doivent pas être modifiés à la main. La commande useradd permet de définir un nouvel utilisateur simplement. Cette commande suit la syntaxe suivante :
useradd [-c commentaire] [-d répertoire] [-e expiration] [-f inactivité] \
[-g groupe] [-G groupes] [-m [-k modèle]] [-p passe]
[-s shell] [-u uid [-o]] loginComme vous pouvez le constater, cette commande prend en paramètre le login de l'utilisateur, c'est-à-dire le nom qu'il devra utiliser pour s'identifier sur le système, et un certain nombre d'options complémentaires. Ces options sont récapitulées dans le tableau suivant :
|
Option |
Signification |
|
-c |
Permet de définir le champ commentaire du fichier de mot de passe. |
|
-d |
Permet de fixer le répertoire personnel de l'utilisateur. |
|
-e |
Permet de fixer la date d'expiration du compte. Cette date doit être spécifiée au format AAAA-MM-JJ. |
|
-f |
Permet de définir le nombre de jours avant que le compte ne soit désactivé une fois que le mot de passe est expiré. La valeur -1 permet de ne jamais désactiver le compte. |
|
-g |
Permet de définir le groupe principal auquel l'utilisateur appartient. Il s'agit souvent du groupe users. |
|
-G |
Permet de donner la liste des autres groupes auxquels l'utilisateur appartient. Cette liste est constituée des noms de chacun des groupes, séparés par des virgules. |
|
-m |
Permet de forcer la création du répertoire personnel de l'utilisateur. Les fichiers du modèle de répertoire personnel stockés dans le répertoire /etc/skel/ sont automatiquement copiés dans le nouveau répertoire. Si ces fichiers doivent être copiés à partir d'un autre répertoire, il faut spécifier celui-ci à l'aide de l'option -k |
|
-p |
Permet de donner le mot de passe initial du compte. Cette option ne doit jamais être utilisée, car le mot de passe apparaît dans la ligne de commande du processus et peut être lue par un utilisateur mal intentionné. On fixera donc toujours le mot de passe initial de l'utilisateur à l'aide de la commande passwd. |
|
-s |
Permet de spécifier le shell par défaut utilisé par l'utilisateur. |
|
-u |
Permet de spécifier l'UID de l'utilisateur. Cette valeur doit être unique en général, cependant, il est possible de forcer l'utilisation d'un même UID pour plusieurs utilisateurs à l'aide de l'option -o. Cela permet de créer un deuxième compte pour un utilisateur déjà existant. |
L'ajout d'un groupe se fait avec la commande groupadd, qui suit la syntaxe suivante, beaucoup plus simple que celle de useradd :
groupadd [-g GID [-o]] nomoù nom est le nom du groupe et GID son numéro. Il n'est normalement pas possible de définir un groupe avec un identifiant numérique déjà attribué à un autre groupe, sauf si l'on utilise l'option -o.
De la même manière, la suppression d'un utilisateur peut se faire manuellement en effaçant son répertoire personnel et en supprimant les lignes qui le concernent dans les fichiers /etc/passwd, /etc/shadow et /etc/group. Il est également possible d'utiliser la commande userdel. Cette commande utiliser la syntaxe suivante :
userdel [-r] loginoù login est le nom de l'utilisateur. L'option -r permet de demander à userdel d'effacer récursivement le répertoire personnel de l'utilisateur, ce qu'elle ne fait pas par défaut. Il existe également une commande groupdel pour supprimer un groupe d'utilisateurs (cette commande supprime le groupe seulement, pas les utilisateurs qui y appartiennent !).
Note : Comme pour la plupart des autres opérations d'administration système, il est fortement probable que l'outil de configuration fourni avec votre distribution dispose de toutes les fonctionnalités nécessaires à l'ajout et à la suppression des utilisateurs. Il est recommandé d'utiliser cet outil, car il peut effectuer des opérations d'administration complémentaires que les outils standards n'effectuent pas forcément, comme la définition des comptes mail locaux par exemple.
VI-C-3. Description de la bibliothèque PAM▲
La bibliothèque PAM permet de centraliser toutes les opérations relatives à l'identification et à l'authentification des utilisateurs. Ces tâches sont en effet déportées dans des modules spécialisés qui peuvent être chargés dynamiquement dans les programmes qui en ont besoin, en fonction de paramètres définis dans des fichiers de configuration. Le comportement des applications peut donc être parfaitement défini simplement en éditant ces fichiers.
La bibliothèque PAM permet une très grande souplesse dans l'administration des programmes ayant trait à la sécurité du système et devant réaliser des opérations privilégiées. Il existe déjà un grand nombre de modules, capables de réaliser une multitude de tâches diverses et variées, et que l'on peut combiner à loisir pour définir le comportement de toutes les applications utilisant la bibliothèque PAM. Il est hors de question de décrire chacun de ces modules ici, ni même de donner la configuration des programmes qui utilisent PAM. Cependant, nous allons voir les principes généraux permettant de comprendre comment les modules de la bibliothèque sont utilisés.
Initialement, toute la configuration de PAM se faisait dans le fichier de configuration /etc/pam.conf. Ce fichier contenait donc la définition du comportement de chaque programme utilisant la bibliothèque PAM, ce qui n'était pas très pratique pour l'administration et pour les mises à jour. Les informations de chaque programme ont donc été séparées en plusieurs fichiers distincts, à raison d'un fichier par application, tous stockés dans le répertoire /etc/pam.d/. Il est fort probable que votre distribution utilise cette solution, aussi le format du fichier /etc/pam.conf ne sera-t-il pas décrit.
Certains modules utilisent des fichiers de configuration pour déterminer la manière dont ils doivent se comporter. Ces fichiers de configuration sont tous stockés dans le répertoire /etc/security/. Les modules de PAM eux-mêmes sont, quant à eux, stockés dans le répertoire /lib/security/.
Le principe de fonctionnement est le suivant. Lorsqu'un programme désire réaliser une opération relative à l'authentification d'un utilisateur, il s'adresse à la bibliothèque PAM pour effectuer cette opération. La bibliothèque recherche dans le répertoire /etc/pam.d/ le fichier de configuration correspondant à cette application (il porte généralement le nom de l'application elle-même), puis détermine les modules qui doivent être chargés dynamiquement dans l'application. Si le fichier de configuration d'une application ne peut pas être trouvé, le fichier de configuration /etc/pam.d/other est utilisé, et la politique de sécurité par défaut qui y est définie est utilisée. Quel que soit le fichier de configuration utilisé, chaque module est utilisé en fonction des paramètres qui y sont stockés. Les modules peuvent, s'ils en ont besoin, utiliser leurs propres fichiers de configuration, qui se trouvent dans le répertoire /etc/security/. Ces fichiers portent généralement le nom du module avec l'extension .conf. Par exemple, le fichier de configuration du module limits, qui prend en charge les limites d'utilisation des ressources système pour chaque utilisateur, est le fichier /etc/security/limits.conf.
Les fichiers de configuration des applications sont constitués de lignes définissant les différents modules qui doivent être chargés, le contexte dans lequel ils sont chargés, et comment doit se comporter l'application en fonction du résultat de l'exécution des opérations réalisées par ces modules. L'ordre des lignes est important, puisqu'elles sont analysées les unes après les autres. Chaque ligne est constituée de trois colonnes. La première colonne indique le cadre d'utilisation du module. La deuxième colonne indique le comportement que doit adopter la bibliothèque PAM en fonction du résultat renvoyé par le module après son exécution. Enfin, la troisième colonne donne le chemin d'accès complet au module, éventuellement suivi des options qui doivent lui être communiquées pour son exécution.
Les modules peuvent être utilisés dans l'un des contextes suivants :
- auth, qui est le contexte utilisé par les programmes qui demandent l'authentification de l'identité de l'utilisateur ;
- account, qui est le contexte utilisé par les programmes qui désirent obtenir des informations sur l'utilisateur (répertoire personnel, shell, etc.)
- password, qui est le contexte utilisé par les applications qui cherchent à revalider l'authentification de l'utilisateur. Les programmes comme passwd par exemple, qui demandent le mot de passe de l'utilisateur avant d'en fixer un nouveau, sont susceptibles d'utiliser ce contexte ;
- session, qui est le contexte utilisé par les applications lorsqu'elles effectuent les opérations de gestion d'ouverture et de fermeture de session. Ce contexte peut être utilisé pour réaliser des tâches administratives, comme l'enregistrement de l'utilisateur dans la liste des utilisateurs connectés ou le chargement des préférences personnelles de l'utilisateur par exemple.
Une même application peut définir plusieurs jeux de règles pour plusieurs contextes différents, et certains modules peuvent être utilisés dans plusieurs contextes différents également. Cependant, lorsqu'une application réalise une demande à la bibliothèque PAM, cette demande n'est exécutée que dans le cadre d'un contexte bien défini. Attention cependant, une même application peut effectuer plusieurs opérations successivement dans des contextes différents. Par exemple, le programme login peut utiliser le contexte auth pour valider l'identité de l'utilisateur, puis le contexte account pour déterminer le répertoire personnel de l'utilisateur, et enfin le contexte session pour enregistrer l'utilisateur dans le journal des utilisateurs connectés.
Le comportement de la bibliothèque PAM en fonction du résultat de l'exécution des modules dépend de ce qui est spécifié dans la deuxième colonne des lignes de ces modules. Les options qui peuvent y être utilisées sont les suivantes :
- required, qui permet d'indiquer que le succès de l'opération effectuée par le module est nécessaire pour que l'opération effectuée dans le contexte spécifié dans la première colonne de la ligne réussisse. Un échec sur cette ligne ne provoque pas l'arrêt de l'analyse du fichier de configuration, ce qui permet d'appeler d'autres modules, par exemple pour générer des traces dans les fichiers de traces du système. Cependant, quel que soit le comportement des modules suivants, l'opération demandée par le programme appelant échouera ;
- requisite, qui permet d'indiquer que le succès de l'opération effectuée par le module est nécessaire, faute de quoi l'opération réalisée par le programme appelant échoue immédiatement. Les autres modules ne sont donc pas chargés en cas d'échec, contrairement à ce qui se passe avec l'option required ;
- sufficient, qui permet d'indiquer que le succès de l'exécution du module garantira le succès de l'opération demandée par le programme appelant. Les modules suivants seront chargés malgré tout après l'appel de ce module, sauf s'il s'agit de modules de type required ;
- optional, qui permet d'indiquer que le résultat du module ne doit être pris en compte que si aucun autre module ne peut déterminer si l'opération est valide ou non. Dans le cas contraire, le module est chargé, mais son résultat est ignoré.
À titre d'exemple, nous pouvons présenter deux implémentations possibles du fichier de configuration par défaut /etc/pam.d/other. Une configuration extrêmement sûre interdira l'accès à toute fonctionnalité fournie par un programme n'ayant pas de fichier de configuration. Dans ce cas de configuration, on utilisera un fichier comme celui-ci :
auth required /lib/security/pam_warn.so
auth required /lib/security/pam_deny.so
account required /lib/security/pam_deny.so
password required /lib/security/pam_warn.so
password required /lib/security/pam_deny.so
session required /lib/security/pam_deny.soNous voyons que toutes les opérations de type authentification ou de revalidation de l'identité sont d'abord tracées dans les fichiers de traces du système, puis déclarées comme interdites. Une telle configuration peut être un peu trop restrictive, car, en cas d'erreur dans un fichier de configuration d'une application, l'accès à cette application peut être interdit systématiquement. Une autre configuration, plus permissive, cherchera à utiliser les mécanismes d'identification et d'authentification Unix classiques. Cela se fait avec les modules pam_unix_auth, pam_unix_acct, pam_unix_passwd et pam_unix_session :
auth required /lib/security/pam_unix_auth.so
account required /lib/security/pam_unix_acct.so
password required /lib/security/pam_unix_passwd.so
session required /lib/security/pam_unix_session.soLes autres fichiers de configuration ne seront pas décrits ici, car ils dépendent de chaque application et de chaque distribution. Vous pouvez consulter ceux qui sont installés sur votre système si vous désirez en savoir plus.
Nous ne décrirons pas non plus la syntaxe des fichiers de configuration des différents modules, car cela dépasserait largement le cadre de ce document. Cela dit, la plupart de ces fichiers sont parfaitement commentés et leur modification ne devrait pas poser de problème particulier. À titre d'exemple, on peut présenter le cas du module de gestion des limites des ressources consommées par les utilisateurs. Si l'on désire restreindre le nombre de processus que les utilisateurs peuvent lancer, on pourra ajouter la ligne suivante dans le fichier /etc/security/limits.conf :
@users hard nproc 256Il faudra également demander le chargement de ce module dans les fichiers de configuration des applications fournissant un accès au système. Pour cela, on ajoutera une ligne telle que celle-ci à la fin de leur fichier de configuration :
session required /lib/security/pam_limits.soIl est également possible de limiter le nombre de logins de chaque utilisateur, la quantité de mémoire qu'il peut consommer, la durée de connexion autorisée, la taille maximum des fichiers qu'il peut manipuler, etc. Vous trouverez de plus amples renseignements sur la configuration des modules de PAM dans le guide d'administration de PAM pour Linux, que l'on trouvera avec les sources de PAM.
VI-D. Gestion des paquetages▲
Il existe plusieurs systèmes de gestion de paquetages, chaque distribution fournissant ses propres outils. Toutefois, les fonctionnalités de ces outils sont toujours de maintenir la liste des paquetages installés, et de permettre l'installation, la mise à jour et la suppression de ces paquetages. Nous ne présenterons ici que les systèmes de paquetages des distributions les plus utilisées. Si les outils de votre distribution ne sont pas décrits dans cette section, ne vous alarmez pas, leur documentation vous permettra sans doute de trouver rapidement la manière de réaliser les opérations élémentaires équivalentes.
VI-D-1. Le gestionnaire de paquetages rpm▲
La plupart des distributions actuelles utilisent le format de fichier « rpm » (« Redhat Package Manager ») pour leurs paquetages. Ce format de fichier a été introduit par la distribution Redhat, mais a été licencié sous la licence GNU, ce qui a permis aux autres distributions de l'utiliser. Ces fichiers encapsulent tous les fichiers des paquetages, ainsi que des informations permettant de gérer les dépendances entre les paquetages, leurs versions, la manière de les installer dans le système, de les supprimer ou de les mettre à jour facilement.
Les fichiers rpm peuvent être manipulés à l'aide du programme rpm. Il est probable que le programme d'installation de votre distribution vous évite d'avoir à manipuler cet outil vous-même. Cependant, les principales commandes de rpm seront décrites ici, afin que vous puissiez l'utiliser en cas de besoin.
Le programme rpm utilise une syntaxe très classique :
rpm options [paquetage]Les options indiquent les opérations à effectuer. La première option est bien entendu l'option -i, qui permet l'installation d'un paquetage :
rpm -i paquetageLa mise à jour d'un paquetage déjà installé se fait à l'aide de l'option -U :
rpm -U paquetageLa suppression d'un paquetage se fait à l'aide de l'option -e :
rpm -e paquetageLa commande permettant d'obtenir les informations (auteur, description, version) sur un paquetage contenu dans un fichier rpm est la suivante :
rpm -qi -p paquetageEnfin, la commande pour lister tous les fichiers d'un paquetage contenu dans un fichier rpm est la suivante :
rpm -ql -p paquetageCette commande affiche les chemins complets, ce qui permet de savoir dans quel répertoire chaque fichier sera installé.
Il existe beaucoup d'autres options disponibles. Cependant, leur description dépasserait le cadre de ce document. Vous pouvez toujours consulter la page de manuel rpm si vous désirez plus d'informations.
VI-D-2. Le gestionnaire de paquetages apt▲
Les distributions basées sur la distribution Debian utilisent le gestionnaire de paquetages apt-get, qui est sans doute l'un des plus performants qui soient. Ce gestionnaire de paquetages permet d'installer, mettre à jour et supprimer des paquetages en tenant compte des dépendances entre ceux-ci, et ce à partir de n'importe quelle source. Ainsi, si l'on est connecté en réseau, il est possible d'installer ou de mettre à jour n'importe quel paquetage via le réseau. Dans le cas contraire, il faut référencer le répertoire contenant les paquetages pour que apt-get puisse les utiliser, ce après quoi les opérations sont exactement les mêmes.
La liste des localisations des paquetages est stockée dans le fichier de configuration /etc/apt/sources.list. Ce fichier contient une ligne par référentiel disponible. Le format général de ces lignes est le suivant :
type site distribution sectionsoù type est le type du paquetage, site est l'emplacement du référentiel, distribution est le nom de la distribution, et sections une liste des sections dans lesquelles les paquetages pourront être trouvés. Le type de paquetage le plus courant est deb, qui est utilisé pour les paquetages binaires pour la distribution Debian. Par exemple, la ligne suivante permet de référencer le site principal de Debian aux États-Unis :
deb http://http.us.debian.org/debian stable main contrib non-freePar défaut, le fichier /etc/apt/sources.list contient les références sur les principaux sites Internet de Debian. Si vous voulez installer des paquetages que vous avez téléchargés, il va vous falloir y rajouter une ligne telle que celle-ci :
deb file:/base répertoire/où base est un répertoire dans lequel vous devez placer un sous-répertoire contenant vos paquetages, et répertoire est le nom de ce sous-répertoire. Vous pouvez bien entendu classer vos paquetages dans différents sous-répertoires, du moment que vous ajoutez les lignes adéquates dans le fichier sources.list.
apt-get recherchera alors, dans chacun de ces sous-répertoires, un fichier d'index contenant la liste des paquetages. Ce fichier doit être nommé Packages.gz, et peut être créé simplement en compressant le résultat de la commande dpkg-scanpackages. La commande à utiliser pour créer un tel fichier est la suivante :
dpkg-scanpackages répertoire /dev/null | gzip > répertoire/Packages.gzoù répertoire est le sous-répertoire du répertoire de base dans lequel vous avez placé vos paquetages binaires. Cette ligne de commande suppose que le répertoire courant soit le répertoire base spécifié dans la ligne que vous avez ajoutée dans le fichier sources.list.
Dans le cas des CD-ROM, la procédure est plus simple. En effet, l'utilitaire apt-cdrom permet de prendre en compte un CD-ROM de manière automatique, avec une simple commande telle que celle-ci :
apt-cdrom -d répertoire addoù répertoire est le répertoire servant de point de montage de votre CD-ROM. Cette commande ajoute la référence du CD-ROM dans le fichier /var/lib/apt/cdrom.list. Il n'existe pas de commande pour supprimer un CD-ROM de cette liste.
Une fois les sources de paquetages définies, leur manipulation est élémentaire. Avant toute chose, il est nécessaire de mettre à jour la liste des paquetages dans le système de paquetages. Cette opération doit être réalisée de manière assez régulière en général, car cette liste évolue assez rapidement. Pour effectuer cette opération, il suffit d'exécuter la commande update d'apt-get :
apt-get updateL'installation d'un paquetage se fait avec la commande install d'apt-get :
apt-get install paquetagepaquetage est ici le nom du paquetage à installer. Si ce paquetage est déjà installé et que l'on désire le réinstaller, par exemple pour le réparer ou pour le mettre à jour ajoutera l'option --reinstall :
apt-get --reinstall install paquetageLa suppression d'un paquetage est toute aussi simple. Elle se fait évidemment avec la commande remove :
apt-get remove paquetageCette commande supprime le paquetage, mais ne détruit pas les fichiers de configuration qu'il a installés. Cela permet d'éviter de perdre les éventuelles modifications que l'on pourrait y avoir apportées. Si l'on désire supprimer ces fichiers également, il faut ajouter l'option --purge :
apt-get --purge remove paquetageLa mise à jour de tous les paquetages existants se fait simplement avec la commande upgrade d'apt-get :
apt-get upgradeCette commande ne permet pas toujours de résoudre les nouvelles dépendances sur les paquetages. C'est pour cela que la commande dist-upgrade a été définie. Elle permet de mettre à jour le système complet (mais est évidemment bien plus longue).
Enfin, si vous désirez obtenir des informations sur un paquetage, vous devez utiliser le programme apt-cache. Ce programme permet de rechercher un paquetage à l'aide de mots-clefs, et d'afficher les informations complètes sur le paquetage. Par exemple, pour obtenir des informations sur un paquetage, il faut utiliser la commande suivante :
apt-cache show paquetageoù paquetage est le nom du paquetage. De même, pour obtenir la liste des paquetages qui se rapporte à un mot-clef particulier, il faut utiliser la commande search d'apt-cache :
apt-cache search mot-cléoù mot-clé est le mot-clé que l'on doit rechercher dans les paquetages.
VI-D-3. Le gestionnaire de paquetages pkgtool▲
Les distributions basées sur la Slackware utilisent le gestionnaire de paquetages pkgtool. Celui-ci est beaucoup plus rudimentaire que les gestionnaires présentés précédemment, car il ne prend pas en charge les dépendances entre les paquetages, et ne s'occupe pas de localiser les paquetages sur le réseau. Bien entendu, la manipulation des paquetages est très simplifiée, et il est du ressort de l'utilisateur de savoir ce qu'il fait.
L'installation d'un paquetage se fait avec la commande installpkg :
installpkg paquetageoù paquetage est le nom du paquetage à installer.
La suppression d'un paquetage se fait avec la commande removepkg :
removepkg paquetageEnfin, la mise à jour d'un paquetage se fait avec la commande upgradepkg :
upgradepkg paquetageCette commande supprime toutes les anciennes versions du paquetage après avoir installé la nouvelle. La commande upgradepkg peut également accepter en paramètre l'option --install-new, qui permet d'installer le paquetage s'il n'est pas encore installé, et l'option --reinstall, qui permet de réinstaller le paquetage s'il est déjà installé.
Enfin, la Slackware fournit l'outil pkgtool, qui est un peu plus convivial à utiliser que les outils en ligne de commande précédents. Cet outil fournit une interface utilisateur en mode texte permettant d'installer, de supprimer, d'obtenir des informations sur les paquetages, ainsi que de reconfigurer le système.
VI-E. Notion de niveau d'exécution et amorçage du système▲
La plupart des systèmes Unix disposent de plusieurs modes de fonctionnement, que l'on appelle des niveaux d'exécution. Dans chaque niveau d'exécution, un certain nombre de services sont accessibles. Ainsi, le lancement et l'arrêt des services des systèmes Unix peut se faire de manière groupée simplement en changeant de niveau d'exécution. En général, il existe 7 niveaux d'exécution, dont seulement trois fournissent des services bien définis pour quasiment toutes les distributions de Linux.
Le niveau 0 correspond à l'arrêt du système, et aucun service n'est disponible (à part le redémarrage de la machine bien entendu…). Le fait de passer dans le niveau d'exécution 0 correspond donc à arrêter le système. Le niveau 6 correspond au redémarrage de la machine. Le fait de passer dans le niveau d'exécution 6 revient donc à arrêter et à redémarrer la machine. Le niveau d'exécution 1 correspond au mode de fonctionnement mono utilisateur (encore appelé mode de maintenance). Ce niveau d'exécution fournit les services de base pour un seul utilisateur (normalement l'administrateur du système). Dans ce niveau d'exécution, l'administrateur peut changer la configuration et effectuer les tâches de maintenance les plus critiques (par exemple, vérifier le système de fichiers racine). La signification des autres niveaux d'exécution dépend de la distribution que vous utilisez, mais en général le niveau d'exécution 2 correspond au mode multiutilisateur avec réseau, mais sans XWindow, et les niveaux d'exécution 3 et 4 correspondent au mode multiutilisateur avec login graphique sous XWindow. Les autres niveaux restent à votre disposition.
Le programme en charge de gérer les niveaux d'exécution est le programme init. Ce programme est le premier programme lancé par le noyau après qu'il a été chargé et démarré par le gestionnaire d'amorçage (à savoir, en général, LILO ou le GRUB). Ce programme ne peut pas être détruit ou arrêté, et c'est réellement le processus père de tous les autres dans le système. Le rôle fondamental d'init est de gérer les changements de niveau d'exécution et de lancer et arrêter les services du système en fonction de ces niveaux. Toutefois, il s'occupe également de tâches de base concernant la gestion des autres processus. En particulier, il permet de supprimer les processus zombies.
Note : Un processus « zombie » est un processus qui vient de se terminer et dont aucun processus n'a lu le code de retour. De tels processus apparaissent généralement lorsque leur processus père se termine avant eux, car, généralement, c'est toujours le processus père qui lit le code de retour de ses processus fils.
Il suffit d'utiliser la syntaxe suivante pour forcer le changement de niveau d'exécution :
init niveauoù niveau est le niveau d'exécution à atteindre. Cela dit, cette manière de faire est assez rare, car en général on n'a pas besoin de changer de niveau d'exécution, sauf pour arrêter et redémarrer la machine. Mais pour ces opérations, les commandes shutdown, halt et reboot sont déjà disponibles.
Le niveau d'exécution dans lequel le système doit se placer lors de son démarrage peut également être précisé en paramètre du noyau lors du démarrage. Vous devrez donc utiliser une commande semblable à celle-ci : LILO boot:linux niveau si vous utilisez LILO, ou kernel noyau niveau si vous utilisez le GRUB pour démarrer le noyau noyau Linux dans le niveau d'exécution niveau. Ainsi, pour passer en mode monoutilisateur (c'est-à-dire le mode de maintenance), il suffit de taper la commande suivante à l'amorçage de LILO :
LILO boot:linux 1
ou la commande suivante sur la ligne de commande interactive du GRUB :
kernel /boot/vmlinuz 1
Note : Il est également possible d'utiliser le paramètre single, qui est synonyme du niveau d'exécution 1.
Le comportement d'init est défini dans le fichier de configuration /etc/inittab. Ce fichier contient la description des niveaux d'exécution, le niveau par défaut dans lequel le système se place au démarrage, et les actions qu'init doit effectuer lorsque certains événements arrivent. En particulier, il est indiqué quels sont les scripts qui doivent être exécutés lors du changement de niveau d'exécution. Il est fortement, mais alors très fortement déconseillé de toucher au fichier /etc/inittab pour des raisons bien évidentes. Vous trouverez de plus amples renseignements dans les pages de manuel d'init et d'inittab.
Lorsqu'on change de niveau d'exécution, ainsi qu'au démarrage du système, init appelle des scripts de configuration pour effectuer les opérations de configuration du système et de lancement et d'arrêt des différents services. Comme on l'a vu, ces scripts sont spécifiés dans le fichier /etc/inittab. En général, ils sont tous placés dans le répertoire /etc/rc.d/ (ou /sbin/init.d/, selon votre distribution). Ce répertoire contient donc :
- le script exécuté lors du démarrage du système ;
- les scripts exécutés lors de la sortie d'un niveau d'exécution ;
- les scripts exécutés lors de l'entrée dans un niveau d'exécution.
Le script appelé lors du démarrage du système est en général spécifié directement dans /etc/inittab. Vous pouvez y ajouter les commandes spécifiques à votre système, par exemple les commandes de configuration du matériel. Ce fichier n'est exécuté qu'une seule fois et est placé directement dans /etc/rc.d/ (ou dans /sbin/init.d/).
En revanche, les scripts appelés lors du changement de niveau d'exécution sont souvent placés dans des sous-répertoires du répertoire rc.d ou init.d. Ils sont classés à raison d'un répertoire par niveau d'exécution. Ces sous-répertoires portent le nom de rc0.d, rc1.d, rc2.d, etc. pour les différents niveaux d'exécution. En fait, un seul script est exécuté par init lorsqu'on change de niveau d'exécution, et ce script se charge d'exécuter les bons scripts dans les sous-répertoires de rc.d ou init.d. Classiquement, ce script principal est appelé avec le numéro du niveau d'exécution en paramètre, et il commence par appeler les scripts de sortie du niveau d'exécution courant, puis les scripts d'entrée dans le nouveau niveau d'exécution.
La distinction entre les scripts d'entrée et de sortie dans chaque répertoire rc?.d se fait par la première lettre du script. Sur certaines distributions, la lettre 'K' correspond aux scripts de sortie et la lettre 'S' au script d'entrée (ces deux lettres correspondent respectivement aux mots anglais « Kill » et « Start »). De plus, l'ordre dans lequel ces scripts doivent être exécutés est indiqué par le nombre suivant cette lettre dans le nom du script. Cela dit, ces conventions peuvent varier selon votre distribution. Consultez votre documentation pour plus de détails à ce sujet.
Il est assez courant que les répertoires rc?.d ne contiennent que des liens symboliques vers les fichiers de scripts, et que ceux-ci soient tous placés directement dans le répertoire /etc/rc.d/ (ou /sbin/init.d/). La raison en est qu'un même script peut être utilisé pour différents niveaux d'exécution, et qu'il n'a donc pas de raison d'être dans le répertoire d'un niveau plutôt que celui d'un autre.
De même, il est assez courant que chacun de ces scripts gère à la fois l'entrée et la sortie du niveau d'exécution, selon le paramètre qu'il reçoit lors de son appel. Parmi les paramètres les plus courants, on retrouve les suivants :
- start, pour le démarrage du service correspondant ;
- stop, pour son arrêt.
Ce sont les deux paramètres que le script de contrôle de changement de niveau d'exécution (celui appelé par init et enregistré dans /etc/inittab) utilisera lors de l'entrée et de la sortie du niveau d'exécution. Il existe d'autres paramètres, par exemple restart permet de redémarrer le service correspondant.
De cette manière, vous pouvez ajouter ou supprimer des services simplement dans chaque niveau d'exécution. Il suffit d'écrire un fichier script capable de prendre en paramètre l'action à réaliser sur le service (start ou stop), de le placer dans /etc/rc.d/ (ou /sbin/init.d/) et de créer les liens dans les sous-répertoires /etc/rc.d/rc?.d/ (ou /sbin/init.d/rc?.d/). Dès lors, votre service sera arrêté ou redémarré selon le niveau d'exécution dans lequel passera le système.
La rédaction des scripts shells de configuration dépasse largement le cadre de ce document, de même que la configuration du comportement du système à chaque changement de niveau d'exécution. La description qui était donnée ici permet simplement d'avoir une idée plus claire de la manière dont le système se comporte au démarrage et à l'arrêt. Consultez la documentation de votre distribution pour plus de détails à ce sujet.
VI-F. Maintenance des systèmes de fichiers▲
Cette section vous présentera les opérations de base sur les systèmes de fichiers, telle que leur création, leur montage et démontage, et leur vérification. Vous y trouverez également la manière de monter automatiquement les systèmes de fichiers les plus utilisés au démarrage du système, ainsi que la manière de monter « à la demande » les systèmes de fichiers amovibles. Vous verrez enfin comment réaliser des agrégats de volumes et comment chiffrer vos systèmes de fichiers. En revanche, la description des systèmes de fichiers réseau sera donnée dans le chapitre traitant de la configuration réseau.
VI-F-1. Création des systèmes de fichiers▲
Nous avons vu lors de l'installation comment créer un nouveau système de fichiers EXT2 sur une partition à l'aide de la commande mke2fs. Cependant, Linux peut gérer de nombreux autres systèmes de fichiers, et leur création peut se faire de manière tout à fait semblable à la création d'un système de fichiers EXT2.
Pour chaque système de fichiers, une commande spécifique est fournie afin de le créer. Toutefois, une commande générique de création de systèmes de fichiers permet d'uniformiser la manière de créer les systèmes de fichiers, rendant ainsi inutile la connaissance de ces commandes spécifiques.
Cette commande générique est la commande mkfs. Elle prend en paramètre le type de système de fichiers à créer, que l'on peut spécifier à l'aide de l'option -t. En fait, mkfs appelle systématiquement la commande de création du système de fichiers spécifié en paramètre. Pour que cela fonctionne, il est nécessaire que cette commande ait un nom de la forme mkfs.type, où type est le nom du système de fichiers. Ainsi, pour créer un système de fichiers JFS (système de fichiers journalisé créé par IBM) sur la première partition du premier disque SCSI, il suffit d'exécuter la commande suivante :
mkfs -t jfs /dev/sda1En général, les commandes mkfs.type ne sont rien d'autre que des liens vers les programmes de création spécifiques des systèmes de fichiers.
Les commandes de création des systèmes de fichiers peuvent prendre des options particulières, qu'il faut donc pouvoir leur fournir via mkfs. mkfs transfère donc toutes les options qu'il trouve après la spécification du type de système de fichiers telles quelles aux programmes de création spécifique des systèmes de fichiers. La liste des options effectivement disponibles peut être consultée dans les pages de manuel respectives de ces programmes.
VI-F-2. Montage des systèmes de fichiers▲
Comme il l'a été vu dans le chapitre expliquant les généralités sur Unix, les systèmes de fichiers ne sont donc pas accessibles directement. Ils doivent en effet subir une opération que l'on nomme le montage avant de pouvoir être utilisés. Le montage est donc l'opération qui consiste à associer un répertoire au point d'entrée d'un système de fichiers. Une fois monté, les données d'un système de fichiers sont accessibles à partir de ce répertoire. L'opération de montage permet ainsi de réaliser une abstraction du support des systèmes de fichiers, qui peuvent se trouver aussi bien sur disque qu'en mémoire ou que sur un réseau.
L'opération permettant de monter un disque suit la syntaxe suivante :
mount [-t type] fichier baseoù fichier est le fichier contenant le système de fichiers à monter (en général, il s'agit d'un fichier spécial de périphérique, mais ce peut également être une image disque), et base est le point de montage, c'est-à-dire le répertoire à partir duquel le système de fichiers doit être accédé. L'option -t permet d'indiquer le type du système de fichiers. Notez qu'en général il n'est pas nécessaire de le préciser, car le noyau sait reconnaître la plupart des systèmes de fichiers automatiquement.
Pour information, les types de systèmes de fichiers les plus utilisés sont les suivants :
- ext2, pour les systèmes de fichiers EXT2 ;
- ext3, pour les systèmes de fichiers EXT3. Il est nécessaire d'avoir créé le journal du système de fichiers au préalable, avec l'option -j de la commande mke2fs ou de la commande tune2fs ;
- reiserfs, pour les systèmes de fichiers ReiserFS ;
- iso9660, pour les CD-ROM (qu'ils soient avec extensions Joliet ou Rock Ridge ou en mode ISO 9660 pur) ;
- ntfs, pour les systèmes de fichiers NTFS ;
- msdos, pour les systèmes de fichiers FAT normaux ;
- vfat, pour les systèmes de fichiers FAT32.
Si le répertoire de montage n'est pas vide, les fichiers qui s'y trouvent sont masqués par le système de fichiers monté. Il est donc recommandé de ne monter les systèmes de fichiers que dans des répertoires vides.
Pour les supports de système de fichiers amovibles, il arrive parfois que Linux ne puisse pas déterminer la géométrie ou la table de partition du support de données. Par exemple, lorsque l'on insère une carte mémoire dans un lecteur de carte, Linux considère que le périphérique n'a pas changé (puisque le lecteur de carte est toujours branché) et ne relit donc pas les informations de la carte mémoire. Il peut donc être nécessaire de demander explicitement au système de relire la table de partition du périphérique. Cela peut être réalisé avec l'option --rereadpt de la commande blockdev :
blockdev --rereadpt périphériqueoù périphérique est le fichier spécial de périphérique dont la table de partition doit être relue.
La commande mount peut prendre diverses options pour le montage des systèmes de fichiers. Par exemple, elle permet de monter des systèmes de fichiers en lecture seule, ou de monter des systèmes de fichiers placés dans des images disques. Ces options sont introduites par l'option de ligne de commande -o, et doivent être séparées les unes des autres par des virgules.
Par exemple, pour monter un système de fichiers ISO9660 en lecture seule, on utilisera la ligne de commande suivante :
mount -t iso9660 -o ro fichier baseUne autre option utile pour le montage des CD-ROM est sans doute l'option session, qui permet d'indiquer le numéro de la session à monter dans le cas des CD-ROM multisessions. Par exemple, pour monter la deuxième session d'un CD-ROM multisession, on utilisera une ligne de commande telle que celle-ci :
mount -t iso9660 -o ro,session=2 fichier baseLe système de fichiers EXT3 prend également des options supplémentaires par rapport au système de fichiers EXT2. Ces options permettent de contrôler la manière dont la journalisation des opérations sur disque est réalisée. Avec EXT3, le journal peut être utilisé pour stocker toutes les opérations concernant la structure de données même du système de fichiers (c'est-à-dire ce que l'on appelle les « métadonnées » du système de fichiers) et les opérations concernant les données des fichiers elles-mêmes. La différence est importante et il faut bien la comprendre. Si l'on choisit de ne journaliser que les métadonnées du système de fichiers, les informations concernant les répertoires, les fichiers et les droits d'accès seront toujours dans un état cohérent. En revanche, les données stockées dans les fichiers eux-mêmes peuvent être a priori fausses à la suite d'un redémarrage impromptu. Si, en revanche, on décide de stocker également les informations concernant les données des fichiers dans le journal, le contenu des fichiers sera également garanti, au détriment d'une perte de performances notable. Le mode de fonctionnement à utiliser est spécifié à l'aide de l'option data du système de fichiers, qui doit donc être fixée lors de l'opération de montage. Cette option peut prendre l'une des trois valeurs suivantes :
- journal, qui permet d'effectuer une journalisation complète des métadonnées et des données des fichiers. Il est donc garanti que le contenu des fichiers est toujours cohérent, tout comme l'est le système de fichiers. Cette option procure le maximum de sécurité, mais c'est également celle qui pénalise le plus les performances du système (les données sont écrites deux fois, une fois dans le journal, et une fois sur disque) ;
- ordered, qui est l'option par défaut et qui permet de ne journaliser que les métadonnées, mais qui garantit également que les tampons d'écriture sont vidés avant chaque journalisation d'une opération disque. Tout comme avec l'option journal, il est garanti que le système de fichiers est dans un état cohérent. Les données des fichiers seront également cohérentes avec les structures de données du système de fichiers. Cependant, rien ne garantit que le contenu des fichiers sera lui aussi cohérent en interne, car même si les données sont écrites avant toute modification du système de fichiers, aucun contrôle n'est effectué pour que les écritures soient réalisées dans l'ordre dans lequel les applications les ont effectuées. Cela dit, les performances sont meilleures qu'avec l'option journal, tout en garantissant une sécurité quasi totale des fichiers ;
- writeback, qui permet de ne journaliser que les métadonnées du système de fichiers. Le contenu des fichiers peut donc être incorrect, voire même contenir des données aléatoires à la suite d'un arrêt brutal du système, mais le système de fichiers est toujours dans un état correct. Cette option permet donc simplement de rendre facultatives la vérification et la réparation des systèmes de fichiers EXT2 au redémarrage. Les performances sont quasiment aussi bonnes que pour le système de fichiers EXT2.
Enfin, il est possible de monter un système de fichiers plusieurs fois, éventuellement avec des options différentes, dans différents points de montage. De même, il est possible de monter une partie d'un système de fichiers seulement dans un autre répertoire, par exemple pour réaliser un raccourci vers un sous ensemble du système de fichiers hôte. Vous pouvez consulter la page de manuel de la commande mount pour obtenir plus de détail à ce sujet.
Vous pourrez trouver la liste des autres options acceptées par mount et par les systèmes de fichiers dans la page de manuel mount.
VI-F-3. Démontage des systèmes de fichiers▲
Les systèmes de fichiers sont gérés de manière très efficace par les systèmes d'exploitation. Des mécanismes de copie en mémoire des données sont utilisés afin d'accélérer leur lecture, et les écritures peuvent être différées pour être regroupées et ainsi optimiser les transferts. De ce fait, l'état du système de fichiers sur le support n'est quasiment jamais exactement en phase avec celui du système de fichiers en mémoire lorsqu'il est en cours d'utilisation. Il est donc nécessaire de signaler au système d'exploitation que l'on désire l'arrêter avant de couper le courant, ou que l'on désire retirer un lecteur amovible avant de le faire, afin qu'il puisse effectuer les synchronisations nécessaires. Ne pas le faire risquerait de provoquer des pertes de données irrémédiables. Cette opération s'appelle simplement le démontage.
Note : Bien entendu, les commandes d'arrêt du système se chargent (entre autres) de démonter tous les systèmes de fichiers avant d'éteindre l'ordinateur.
La commande permettant de démonter un système de fichiers est beaucoup plus simple que celle permettant de les monter, car aucune option n'est nécessaire. Il suffit en effet d'exécuter l'une des commandes suivantes :
umount fichierou :
umount baseDans ces commandes, fichier représente le fichier contenant le système de fichiers à démonter, et base est le répertoire dans lequel ce système de fichiers est monté. On peut utiliser l'un ou l'autre de ces paramètres, la commande umount se débrouillera pour retrouver l'autre automatiquement. On notera qu'il est impossible de démonter un système de fichiers qui est en cours d'utilisation par quelqu'un. En particulier, il ne faut pas être dans le répertoire servant de point de montage pour pouvoir démonter un système de fichiers, car dans ce cas on est en train de l'utiliser. Faites bien attention à l'orthographe de la commande umount, elle a perdu son 'n' depuis bien longtemps déjà, et on ne l'a jamais retrouvé. Si vous savez où il se trouve, faites-le savoir.
Pour les supports de systèmes de fichiers amovibles, le démontage du système de fichiers peut ne pas être suffisant. En effet, il peut être nécessaire d'arrêter le périphérique correctement avant de l'éjecter. C'est en particulier le cas pour les systèmes de fichiers sur les clefs USB par exemple. Cette opération peut être réalisée à l'aide de la commande eject :
eject périphériqueoù périphérique est le fichier spécial du périphérique à éjecter. Cette commande réalise également l'opération de démontage sur les systèmes de fichiers montés avant d'éjecter le disque.
VI-F-4. Vérification des systèmes de fichiers▲
La vérification des systèmes de fichiers est une opération que l'on ne devrait jamais avoir à faire. Il y a plusieurs raisons à cela. Premièrement, si l'on arrête le système correctement avant d'éteindre la machine, et si l'on démonte bien les systèmes de fichiers avant de retirer les lecteurs amovibles, les systèmes de fichiers sont normalement toujours dans un état correct. Deuxièmement, les systèmes de fichiers Unix sont réputés pour être très fiables. Troisièmement, une vérification périodique est faite par le système au bout d'un certain nombre de démarrages. Quatrièmement, si un système de fichiers n'est pas démonté correctement avant l'arrêt du système, celui-ci sera vérifié automatiquement au démarrage suivant, ce qui fait qu'il n'y a pas lieu de le faire soi-même. Enfin, pour les systèmes de fichiers journalisés tels que EXT3, JFS ou ReiserFS, cette opération peut être réalisée très rapidement à l'aide des informations qui sont stockées dans le journal des transactions du système de fichiers.
Toutefois, même le meilleur système du monde ne saurait être à l'abri des secteurs défectueux du disque dur sur lequel il est installé. Il est donc parfois nécessaire d'effectuer une vérification manuelle des systèmes de fichiers, et il faut savoir le faire même quand plus rien ne fonctionne.
Un système de fichiers ne se manipule que lorsqu'il est démonté. Cela pose évidemment quelques problèmes pour le système de fichiers racine, puisqu'on ne peut pas accéder aux outils de vérification sans le monter. Pour ce système de fichiers, il n'y a donc que deux possibilités :
- soit on utilise une disquette de démarrage contenant les outils de vérification et de réparation des systèmes de fichiers ;
- soit on monte le système de fichiers racine en lecture seule.
La deuxième solution est la seule réalisable si l'on ne dispose pas de disquette de démarrage. Par conséquent, c'est cette méthode qui sera décrite ici.
La première étape consiste à passer en mode mono utilisateur, afin de s'assurer que personne ni aucun programme n'accède au système de fichiers racine en écriture. Pour cela, il suffit de taper la commande suivante :
init 1qui fait passer le système dans le niveau d'exécution 1. On peut également passer le paramètre single au noyau lors de l'amorçage du système, comme il l'a été expliqué dans la section précédente. Ensuite, il faut s'assurer que le système de fichiers racine est en lecture seule, ce qui se fait avec la commande suivante :
mount -n -o remount,ro /L'option remount permet de démonter et de remonter le système de fichiers racine, et l'option ro indique qu'il doit être remonté en lecteur seule (« ro » signifie « Read Only »). Les options sont séparées par des virgules (attention, il ne faut pas insérer d'espace). De plus, l'option -n indique à mount qu'il ne doit pas écrire dans le fichier /etc/mtab lorsqu'il aura remonté le système de fichiers, parce que ce fichier sera alors également en lecture seule et qu'on ne pourra pas y écrire. Ce fichier est utilisé par mount pour mémoriser les systèmes de fichiers qui sont montés, afin de pouvoir en donner la liste (ce que la commande mount fait lorsqu'elle est appelée sans paramètres) et de permettre à la commande umount de vérifier que les systèmes de fichiers à démonter ne le sont pas déjà.
Note : Normalement, le noyau monte toujours le système de fichiers racine en lecture seule lors de l'amorçage. Ce sont les scripts de démarrage du système, lancés par init, qui le remontent en lecture / écriture s'il est dans un état correct. Il est donc fortement probable, si votre système ne démarre plus correctement, que le système de fichiers racine soit déjà en lecture seule après un démarrage en mode de maintenance. La commande précédente n'est donc décrite qu'à titre indicatif.
Une fois le système de fichiers racine monté en lecture seule, on peut utiliser le programme fsck afin de le vérifier et éventuellement le réparer. En réalité, ce programme ne fait rien d'autre que d'appeler un programme spécifique pour chaque système de fichiers, de la même manière que mkfs appelle des programmes spécifiques pour les créer. Par exemple, pour les systèmes de fichiers EXT2 et EXT3, fsck appelle le programme fsck.ext (qui est un lien vers e2sfck).
La ligne de commande à utiliser pour vérifier un système de fichiers avec fsck est la suivante :
fsck -a fichieroù fichier est le fichier spécial du périphérique ou le fichier image contenant le système de fichiers à vérifier. Il faut donc, généralement, spécifier la partition sur laquelle le système de fichiers racine se trouve. L'option -a demande à fsck d'effectuer les éventuelles corrections automatiquement en cas d'erreur sur le système de fichiers ainsi vérifié, sans confirmation de la part de l'utilisateur.
Il est également possible de demander la vérification de tous les systèmes de fichiers enregistrés dans le fichier de configuration /etc/fstab. Ce fichier contient la liste des systèmes de fichiers les plus utilisés et leurs options respectives. Il suffit donc d'ajouter l'option -A :
fsck -a -AIl n'est évidemment plus nécessaire de spécifier le fichier spécial du périphérique contenant le système de fichiers à vérifier, puisque cette information est enregistrée dans le fichier /etc/fstab. La syntaxe de ce fichier sera décrite dans la section suivante.
Si le disque dur contient des secteurs défectueux, il peut être nécessaire de les marquer comme tels dans les structures du système de fichiers afin de ne pas les utiliser par la suite. De manière générale, la recherche de ces blocs peut être faite à l'aide du programme badblocks. Cette commande effectue un test de lecture de tous les blocs du disque sur lequel le système de fichiers se trouve, et génère une liste des blocs défectueux. Vous pouvez l'appeler directement et fournir cette liste au programme e2fsck à l'aide de son option -l, mais le plus simple est encore de demander à e2fsck d'appeler badblocks lui-même. Pour cela, il suffit de lui passer l'option -c, ce qui se fait en faisant précéder cette option d'un double-tiret dans la ligne de commande de fsck :
fsck -a -- -c périphériqueNote : L'option -c est spécifique à e2fsck et peut ne pas fonctionner avec d'autres systèmes de fichiers. En particulier, certains systèmes de fichiers ne sont pas capables de gérer correctement les blocs défectueux des disques durs. C'est le cas du système de fichiers ReiserFS.
Le programme badblocks peut également effectuer un test d'écriture sur le disque dur, si on lui communique l'option -w. Il va de soi que ce type de test est destructif, car toutes les données du disque sont alors écrasées par des motifs particuliers. Il ne faut donc JAMAIS utiliser cette option sur un système de fichiers contenant des données !
De manière générale, il vaut mieux prévenir que guérir, aussi est-il recommandé d'utiliser la commande badblocks au moins une fois avant d'utiliser un système de fichiers. Cette vérification peut être réalisée de manière automatique lors de la création du système de fichiers à l'aide de l'option -c de la commande mke2fs.
Une fois que vous aurez terminé la vérification du système de fichiers, vous pourrez le remonter en lecture et écriture avec la commande suivante :
mount -n -o remount,rw /Cette commande est similaire à celle que l'on a vue pour monter le système de fichiers en lecture seule, à ceci près que l'option rw est utilisée à la place de l'option ro. Cette option permet de remonter le système de fichiers en lecture et en écriture (« rw » est l'abréviation de l'anglais « Read Write »).
VI-F-5. Configuration du montage des systèmes de fichiers▲
Le montage des systèmes de fichiers peut devenir très vite une opération assez fastidieuse. Heureusement, elle peut être automatisée au démarrage pour les systèmes de fichiers situés sur les disques fixes, et simplifiée pour les systèmes de fichiers amovibles. Pour cela, il faut enregistrer ces systèmes de fichiers et leurs options de montage dans le fichier de configuration /etc/fstab.
Ce fichier contient, entre autres, le répertoire de montage, le type du système de fichiers et le fichier de périphérique à utiliser pour chaque système de fichiers. De cette manière, il est possible d'utiliser la commande mount de manière simplifiée, en ne précisant que le répertoire servant de point de montage ou le fichier spécial de périphérique.
Le fichier /etc/fstab contient une ligne pour chaque système de fichiers enregistré. Chaque ligne contient plusieurs champs séparés par des espaces. Les informations suivantes sont enregistrées dans ces champs :
- le fichier spécial permettant d'accéder au système de fichiers ;
- le répertoire servant de point de montage par défaut ;
- le type du système de fichiers ;
- les options de montage pour ce système de fichiers ;
- un entier indiquant si le système de fichiers doit être sauvegardé ;
- un entier indiquant l'ordre que ce système de fichiers doit avoir dans la liste des systèmes de fichiers à vérifier.
Grâce à ces informations, l'emploi de la commande mount est plus simple :
mount périphériqueou :
mount répertoireoù périphérique est le fichier spécial de périphérique contenant le système de fichiers à monter, et répertoire est le répertoire servant de point de montage indiqué dans le fichier /etc/fstab. Il est possible d'utiliser indifféremment le fichier spécial de périphérique ou le répertoire du point de montage.
Le type du système de fichiers est l'un des types disponibles acceptés par la commande mount. Consultez la page de manuel de cette commande pour plus de renseignements à ce sujet. Les principales options disponibles pour le montage sont les suivantes :
- l'option defaults, qui permet de choisir les options par défaut pour ce système de fichiers ;
- l'option auto, qui permet de faire en sorte que le système de fichiers soit monté automatiquement au démarrage du système ;
- l'option user, qui permet d'autoriser le montage de ce système de fichiers par les utilisateurs ;
- l'option ro, qui permet de monter le système de fichiers en lecture seule ;
- l'option rw, qui permet de monter le système de fichiers en lecture et écriture ;
- l'option exec, qui permet d'autoriser l'exécution des fichiers exécutables sur ce système de fichiers si celui-ci ne supporte pas la notion de droit d'exécution ;
- l'option acl, qui permet d'autoriser l'utilisation des ACL (« Access Control List ») pour fixer les droits des utilisateurs sur les fichiers ;
- l'option uid=utilisateur, qui permet de spécifier le numéro utilisateur de l'utilisateur propriétaire du répertoire racine de ce système de fichiers ;
- l'option gid=groupe, qui permet de spécifier le numéro groupe du groupe d'utilisateurs auquel le répertoire racine du système de fichiers appartient ;
- l'option mode=valeur, qui permet de fixer les droits sur le répertoire racine du système de fichiers à monter. La valeur valeur est donnée en octal ;
- l'option umask=valeur, qui permet de fixer les droits sur les fichiers qui ne sont pas gérés par le système de fichiers. La valeur valeur est donnée en octal ;
- les options codepage=cp et iocharset=charset, qui permettent de fixer les tables de conversion des caractères pour les systèmes de fichiers pour lesquels les noms de fichiers doivent être transcodés.
Nous allons détailler un peu quelques-unes de ces options.
Par défaut, les utilisateurs n'ont pas le droit de monter et de démonter les systèmes de fichiers. L'option user permet de désactiver cette protection. Elle peut être utile pour permettre le montage et le démontage des disquettes et des CD-ROM. De même, l'exécution des fichiers exécutables n'est par défaut pas autorisée sur les systèmes de fichiers. Cette restriction permet d'éviter l'exécution de programmes placés sur des systèmes de fichiers de systèmes d'exploitation différents. Elle peut être levée grâce à l'option exec.
Tous les systèmes de fichiers disposant de l'option auto seront montés automatiquement au démarrage du système par la commande mount -a. Les autres systèmes de fichiers sont montables manuellement, avec les autres options indiquées dans le fichier /etc/fstab.
Les options ro et rw permettent d'indiquer à mount si le système de fichiers doit être monté en lecture seule ou en lecture et écriture. Les systèmes de fichiers devant être réparés doivent être montés en lecture seule si l'on ne peut pas les démonter (c'est le cas notamment du système de fichiers racine). Il en va de même pour les CD-ROM, car on ne peut bien entendu pas écrire dessus.
Les options uid et gid permettent de spécifier le propriétaire et le groupe du répertoire racine du système de fichiers à monter. Par défaut, c'est l'utilisateur root qui devient propriétaire de ce système de fichiers.
L'option mode permet de spécifier les droits d'accès sur tous les fichiers du système de fichiers à monter. L'option umask permet quant à elle de fixer les droits qui ne sont pas gérés par le système de fichiers. Ce peut être utile pour les systèmes de fichiers FAT et FAT32. Il est ainsi possible de donner les droits de lecture et d'exécution pour les fichiers de ces systèmes avec une valeur de masque nulle. Cela permet de monter les systèmes de fichiers FAT et FAT32 de telle sorte que tous les fichiers appartiennent à l'utilisateur root par défaut, et de donner cependant tous les droits à tous les utilisateurs sur ces fichiers. On prendra garde à ces options, car elles permettent à quiconque d'écrire des fichiers sous le nom de root, et donc constituent un grave défaut dans la sécurité du système.
Les options codepage et iocharset permettent de spécifier respectivement la page de codes et le jeu de caractères utilisés pour les systèmes de fichiers qui ne stockent pas les noms de fichiers Unix nativement. En particulier, elles permettent de modifier la page de code et le jeu de caractères sélectionnés par défaut dans la configuration du noyau pour les systèmes de fichiers FAT. L'option codepage est utilisée pour donner la page de codes utilisée pour la conversion des noms de fichiers en noms de fichiers courts. En général, pour les systèmes français, la page de codes utilisée est la page de codes 850. Il faut donc donner à cette option la valeur cp850. L'option iocharset quant à elle est utilisée pour faire la conversion des noms de fichiers Unix en Unicode. Elle est utilisée pour les systèmes de fichiers VFAT, car ceux-ci stockent les noms de fichiers longs en Unicode. Pour la plupart des systèmes, le jeu de caractères le plus approprié est sans doute le jeu de caractères ISO8859-1. Aussi faut-il généralement donner à cette option la valeur iso8859-1. Cette option n'est pas nécessaire pour les systèmes de fichiers FAT purs, puisque ceux-ci ne savent pas gérer les noms de fichiers longs.
Les deux derniers champs de /etc/fstab spécifient des options pour des programmes annexes. L'avant-dernier contrôle le comportement du programme de sauvegarde dump, et le dernier celui du programme de vérification de système de fichiers fsck. Consultez les pages de manuel pour plus de détails à ce sujet.
Si vous disposez de systèmes de fichiers FAT ou FAT32, vous pourrez monter ces partitions automatiquement lors du démarrage du système. Comme les systèmes de fichiers basés sur la FAT ne peuvent pas gérer les droits des utilisateurs, vous allez devoir faire un choix pour fixer ces droits à une valeur raisonnable. Vous pouvez par exemple donner le droit de lecture à tous les utilisateurs, mais le droit d'écriture uniquement à l'administrateur système. La ligne à ajouter dans le fichier /etc/fstab sera alors la suivante :
/dev/partition répertoire vfat auto,exec,codepage=cp850,iocharset=iso8859-1 0 0où partition est la partition contenant le système de fichiers FAT, et répertoire est le répertoire servant de point de montage pour cette partition. Cette ligne permettra de monter automatiquement ce système de fichiers en tant que FAT32 au démarrage du système. Les fichiers binaires seront exécutables, bien qu'ils ne soient pas stockés sur un système de fichiers EXT2. Si vous voulez laisser les droits d'écriture aux utilisateurs, vous pouvez utiliser la ligne suivante à la place de celle indiquée ci-dessus :
/dev/partition répertoire vfat auto,codepage=cp850,iocharset=iso8859-1,umask=0 0 0Cette ligne permet de monter le système de fichiers FAT en laissant les droits d'exécution et d'écriture aux utilisateurs. Cependant, aucun fichier exécutable de ce système de fichiers ne pourra être lancé, car l'option exec n'a pas été précisée.
Par ailleurs, certaines distributions spécifient des options incorrectes pour le système de fichiers /dev/pts/ dans le fichier /etc/fstab. Veuillez vous assurer que la ligne utilisée pour ce système de fichiers est bien identique à la ligne suivante :
none /dev/pts devpts auto,gid=5,mode=620 0 0Si ce n'est pas le cas, certains émulateurs de terminaux développés récemment ne fonctionneront pas correctement. Le système de fichiers /dev/pts/ est en effet un système de fichiers virtuel, géré directement par le noyau, dans lequel des fichiers spéciaux de périphériques utilisés par les émulateurs de terminaux sont placés. Si les droits ne sont pas correctement fixés sur le répertoire racine de ce système de fichiers, les émulateurs de terminaux utilisant cette fonctionnalité ne pourront se connecter au système que sous le compte root. Il faut donc impérativement corriger cette ligne, si vous voulez que les utilisateurs normaux puissent utiliser ces émulateurs. Notez également qu'il faut que tout le monde ait les droits d'écriture et de lecture sur le fichier spécial de périphérique /dev/ptmx pour que les utilisateurs non privilégiés puissent utiliser ce système de fichiers virtuel.
Vous devrez également ajouter le système de fichiers virtuel /dev/shm/ dans votre fichier /etc/fstab. Ce système de fichiers permet aux applications qui le désirent d'utiliser des segments de mémoire partagée de manière compatible avec la norme POSIX, par exemple pour réaliser des communications interprocessus. Ce système de fichiers permet en effet de créer des fichiers qui sont directement stockés dans la mémoire virtuelle et qui peuvent être ouverts par plusieurs processus simultanément, ce qui permet d'utiliser les fonctionnalités classiques de partage de fichiers pour partager des zones de mémoire entre plusieurs processus. Ce type de communication peut être utilisé par des processus courants, aussi faut-il vous assurer que la ligne suivante se trouve bien dans le fichier fstab :
tmpfs /dev/shm tmpfs defaults 0 0Bien entendu, vous devrez créer le point de montage /dev/shm/ si celui-ci n'existe pas avant de monter ce système de fichiers virtuels.
Vous pouvez monter les systèmes de fichiers virtuels du noyau, qui vous permettront d'obtenir des informations sur votre système et d'en modifier le comportement, en ajoutant les deux lignes suivantes dans le fichier /etc/fstab :
proc /proc proc defaults 0 0
sysfs /sys sysfs defaults 0 0La première ligne monte le système de fichiers /proc/, qui contient tous les paramètres du noyau et permet de paramétrer son comportement, et la deuxième contient le système de fichiers /sys/, qui contient une vue de tous les objets systèmes gérés par le noyau. Ce système de fichiers n'est disponible qu'avec les versions 2.6 et plus du noyau. Ces deux lignes ne sont généralement pas nécessaires, car ces systèmes de fichiers sont montés automatiquement dans les scripts d'initialisation des distributions.
Enfin, si vous utilisez des périphériques USB, il vous faudra également monter le système de fichiers virtuel /proc/bus/usb/ en ajoutant la ligne suivante dans le fichier fstab :
none /proc/bus/usb usbfs defaults 0 0Cette ligne doit être placée après celle qui effectue le montage du système de fichiers virtuel /proc/.
VI-F-6. Montage des systèmes de fichiers à la demande▲
Les systèmes de fichiers sur les supports amovibles ne peuvent pas être montés automatiquement au démarrage du système, étant donné qu'ils ne sont pas forcément présents à ce moment. Les entrées qui les décrivent dans le fichier fstab doivent donc utiliser l'option noauto. De ce fait, l'utilisation des systèmes de fichiers stockés sur les supports amovibles nécessite toujours un montage et un démontage manuel, et même si ces opérations sont simplifiées, elles restent gênantes.
Il est toutefois possible de faire en sorte que ces systèmes de fichiers soient montés à la demande, c'est-à-dire dès qu'un accès est réalisé dans les répertoires de montage dédiés à ces systèmes par un quelconque programme. Ainsi, il n'est plus nécessaire de monter ces systèmes de fichiers manuellement. Le démontage quant à lui peut être réalisé automatiquement après un temps d'inactivité, ou manuellement, lorsqu'on veut retirer le lecteur amovible. Notez que le démontage reste vital si le système de fichiers est accédé en écriture, car des données pourraient être perdues si l'on supprime le lecteur avant qu'elles ne soient écrites.
Les opérations de montage et de démontage sont réalisées par un démon, que le noyau appelle automatiquement dès qu'une opération susceptible de concerner un système de fichiers amovible se produit. Ce démon se nomme automount, et il s'appuie donc sur une fonctionnalité dédiée du noyau Linux. Pour que le montage automatique des systèmes de fichiers fonctionne, il faut activer soit l'option « Kernel automounter support », soit l'option « Kernel automounter version 4 support (also supports v3) » du menu « File systems » du programme de configuration du noyau.
Note : Un démon est un processus qui tourne en arrière-plan dans le système. Les démons fonctionnent souvent dans le compte root et offrent des services de base que les autres programmes utilisent. Le terme « démon » provient de la traduction littérale « daemon », ce qui signifie « ange » en réalité. Le démon se place donc en tant qu'intermédiaire entre Dieu (c'est-à-dire le noyau) et les hommes (c'est-à-dire les applications normales). Le terme « daemon » a été ensuite éclairci et défini comme l'acronyme de l'anglais « Disk And Execution MONitor ».
Le démon automount peut surveiller plusieurs points de montage, s'ils sont tous placés dans le même répertoire. Le noyau surveille simplement les accès sur les sous-répertoires de ce répertoire, et signale à automount toutes les opérations susceptibles de nécessiter un montage de système de fichiers.
Les informations spécifiques aux points de montage doivent être stockées dans un fichier de configuration, que l'on doit fournir à automount en ligne de commande. Cette ligne de commande est donc typiquement de la forme suivante :
automount -t durée répertoire file fichieroù durée est la durée d'inactivité avant démontage automatique du système de fichiers, répertoire est le répertoire dont les sous-répertoires seront utilisés comme points de montage des systèmes de fichiers (il s'agit généralement du répertoire /mnt/), et fichier est le fichier de configuration pour les points de montage placés dans ce répertoire. La durée d'inactivité doit être spécifiée en secondes, et la valeur par défaut est de cinq minutes. Pour désactiver le démontage automatique, il suffit de spécifier une valeur nulle.
Note : automount est capable d'utiliser d'autres méthodes de paramétrage des systèmes de fichiers amovibles que des fichiers de configuration, principalement utilisées dans le contexte du montage automatique des systèmes de fichiers en réseau. Ces méthodes de paramétrage ne seront toutefois pas décrites ici, vous pouvez consulter la page de manuel du démon automount pour plus de détails à ce sujet.
Les fichiers de configuration pour automount sont généralement placés dans le répertoire /etc/, et portent un nom de la forme « auto.nature », où nature est la nature des systèmes de fichiers décrits par ce fichier. Par exemple, le fichier de configuration pour les lecteurs amovibles locaux pourrait s'appeler /etc/auto.local. Ce fichier de configuration est constitué de plusieurs lignes, à raison d'une ligne par point de montage. Chaque ligne utilise la syntaxe suivante :
répertoire -options périphériqueoù répertoire est le sous-répertoire du répertoire spécifié en ligne de commande à automount et devant servir de point de montage, options est la liste des options de montage du système de fichiers, séparées par des virgules, et périphérique est la localisation du système de fichiers. Pour les lecteurs amovibles, il s'agit du fichier spécial de périphérique permettant d'y accéder, précédé du caractère ':'.
Par exemple, pour réaliser le montage automatique du lecteur de CD-ROM et du lecteur de disquettes, vous devez ajouter deux lignes telles que celles-ci dans le fichier de configuration d'automount :
cdrom -fstype=iso9660,ro :/dev/cdrom
floppy -fstype=auto,umask=0 :/dev/fd0Vous noterez que les options sont précédées d'un tiret ('-'), et que les fichiers spéciaux de périphérique sont précédés d'un deux-points (':'). Une fois ce fichier défini, vous n'aurez plus qu'à lancer automount avec la ligne de commande suivante :
automount -t 60 /mnt file /etc/auto.localEn général, les distributions lancent automatiquement le démon automount au démarrage, via le script d'initialisation rc.autofs. Ce script utilise le fichier de configuration /etc/auto.master pour déterminer les noms des fichiers de configuration à fournir en paramètre aux démons automount, ainsi que pour déterminer les options avec lesquelles ils doivent être lancés. Ce fichier est constitué de lignes, à raison d'une ligne par instance du démon automount qui doit être lancée. Le format de ces lignes est le suivant :
répertoire fichier optionsoù répertoire est le répertoire spécifié en ligne de commande à automount, fichier est le fichier de configuration, et option est la liste des options à lui fournir. Par exemple, pour lancer automatiquement automount comme dans l'exemple précédent, la ligne suivante devrait être ajoutée dans le fichier /etc/auto.master :
/mnt /etc/auto.local -t 60Note : Vous noterez que lorsque les systèmes de fichiers ne sont pas montés, le répertoire contenant leurs points de montage est vide. De ce fait, les chemins sur ces répertoires devront être saisis explicitement pour forcer le montage des systèmes de fichiers. Cela peut être gênant lorsque l'on utilise les fonctionnalités de complétion automatique des shells, ou lorsqu'on cherche à localiser un fichier dans un de ces répertoires avec un gestionnaire de fichiers ou une boîte de dialogue d'un programme graphique. Une solution pour résoudre ce problème est de forcer une référence aux points de montage. Pour cela, il suffit de définir des liens symboliques sur les points de montage, et d'utiliser ces liens symboliques vers ces points de montage. Par exemple, on pourra définir les liens symboliques /cdrom et /floppy pour référencer les points de montage /mnt/cdrom et /mnt/floppy, et laisser automount monter les systèmes de fichiers relatifs et créer les répertoires des points de montage dès qu'on accèdera aux liens symboliques.
VI-G. Gestion des volumes▲
Linux fournit des mécanismes très puissants permettant de créer des fichiers spéciaux de périphérique de type bloc virtuels, et d'indiquer les données qui seront accédées au travers de ces fichiers. Cela permet de manipuler des systèmes de fichiers stockés sur un fichier. Linux permet également de réaliser des agrégats de volumes. Ces agrégats peuvent ensuite être accédés via différentes techniques, par exemple pour réaliser de la réplication de données ou tout simplement pour simuler un périphérique de très grande taille. Ils permettent également de réaliser à la volée des opérations de chiffrement sur les données écrites, et de les déchiffrer en lecture. Ainsi, ces mécanismes d'agrégation sont utilisés pour gérer les volumes de manière beaucoup plus souple que les mécanismes de partitionnement classiques et pour créer des systèmes de fichiers chiffrés à l'aide des algorithmes cryptographiques du noyau. Nous allons présenter tous ces mécanismes dans les sections suivantes.
VI-G-1. Gestion des fichiers images▲
Linux permet de stocker des systèmes de fichiers dans des fichiers image et de les manipuler de manière transparente, grâce à un mécanisme de périphériques de type bloc virtuel. Le principe est d'associer le fichier à l'un de ces périphériques, et d'utiliser simplement le fichier spécial de périphérique correspondant comme un fichier spécial de périphérique de type bloc classique. Il est ainsi possible de construire une image de systèmes de fichiers de manière tout à fait transparente, et d'accéder aux données stockées dans une image de CD-ROM de manière tout aussi facile.
Les fichiers spéciaux de périphérique utilisés pour manipuler les fichiers images sont les fichiers /dev/loopX, où X est un numéro allant de 0 à 7. Ces fichiers ne sont utilisables que si l'option « Loopback device support » du menu « Block devices » a été activée dans la configuration du noyau.
L'association entre le périphérique de type bloc virtuel et le support des données peut être réalisée à l'aide de la commande losetup. La syntaxe la plus simple de cette commande est la suivante :
losetup /dev/loopX fichieroù loopX est le fichier spécial de périphérique de type bloc virtuel à utiliser, et fichier est le fichier dans lequel les données de ce périphérique doivent être stockées. Une fois cette association faite, on peut utiliser ce périphérique comme un véritable périphérique. Ainsi, pour créer un système de fichiers dans un fichier image de 10 Mo, on procédera comme suit :
dd if=/dev/zero of=image bs=1024 count=10240
losetup /dev/loop0 image
mkfs -t ext2 /dev/loop0Note : La commande dd permet de copier un certain nombre de blocs, ici 10240 (option count) de 1024 octets (taille indiquée par l'option bs) du fichier spécial de périphérique /dev/zero dans le fichier image. Cette commande a déjà été présentée dans le chapitre d'installation pour réaliser une copie du secteur de boot principal du disque dur.
En réalité, les commandes de création de systèmes de fichiers peuvent également créer directement les systèmes de fichiers dans des fichiers images. La manière classique de procéder a toutefois été présentée ici pour la bonne compréhension du mécanisme de gestion des fichiers images.
Le montage d'un système de fichiers placé dans l'image disque est ensuite réalisable de manière tout à fait classique, en utilisant le fichier spécial de périphérique /dev/loopX adéquat dans la commande mount. Toutefois, cette commande permet de réaliser le montage d'une image de manière simplifiée grâce à son option loop. Celle-ci permet de configurer le périphérique virtuel image de manière automatique avant de réaliser le montage. Elle prend donc en paramètre le fichier spécial de périphérique virtuel à utiliser, ainsi que le chemin sur le fichier image contenant le système de fichiers. Ainsi, pour monter une image de CD-ROM, vous pouvez utiliser la commande suivante :
mount -t iso9660 -o ro,loop=/dev/loop0 image /mnt/cdromLorsque l'on n'a plus besoin du périphérique de type bloc virtuel, il est possible de supprimer l'association avec le support de données simplement avec la commande suivante :
losetup -d /dev/loopXoù X est toujours le numéro du fichier spécial de périphérique virtuel. Lorsque l'on utilise l'option loop de la commande mount, cette opération est réalisée automatiquement par la commande umount et ne doit plus être effectuée manuellement.
VI-G-2. Agrégation de volumes▲
Les agrégats de volumes de Linux permettent de construire un périphérique virtuel constitué d'un certain nombre de volumes de données. Ceux-ci peuvent être regroupés pour réaliser un volume de grande taille, ou mis en parallèle afin de répliquer les données sur plusieurs disques par exemple. Il est donc possible, grâce à cette fonctionnalité, de regrouper plusieurs disques durs ou plusieurs partitions en une seule partition logique, ou au contraire de subdiviser de manière fine des partitions ou des disques existants. De même, il est possible de prendre en charge au niveau logiciel les fonctionnalités RAID normalement disponibles uniquement avec du matériel spécialisé. Nous ne présenterons toutefois pas ces fonctionnalités ici.
La réalisation des agrégats de volumes se fait à l'aide de l'outil dmsetup. Cet outil peut être récupéré sur le site de Redhat s'il n'est pas fourni avec votre distribution. Son installation se fait par compilation des sources, par exécution des commandes suivantes dans le répertoire des sources :
./configuremake
make installLa principale commande de dmsetup est celle qui permet de créer un nouvel agrégat. Cela se fait simplement grâce à l'option create :
dmsetup create agrégat définitionoù agrégat est le nom de l'agrégat et définition est le nom d'un fichier contenant la définition de cet agrégat. Si vous ne fournissez pas ce paramètre, dmsetup attendra que vous le définissiez en ligne de commande.
La définition d'un agrégat se fait de manière générale à l'aide de plusieurs lignes, à raison d'une ligne par composante de l'agrégat. Chaque ligne a la forme suivante :
début taille méthode argumentsdébut est le secteur de début de la plage de secteurs de l'agrégat qui seront stockés dans la composante. taille est le nombre de secteurs de cette plage. méthode est la méthode d'agrégation utilisée, elle est suivie par des options qui lui sont spécifiques. La méthode la plus classique est sans doute linear, qui permet de stocker des données de l'agrégat dans les secteurs correspondants de la composante. Dans le cas de la méthode linéaire, ces secteurs sont spécifiés simplement avec le nom du fichier spécial de périphérique contenant les secteurs, et le numéro du premier secteur à partir duquel la composante sera stockée.
Par exemple, pour créer un agrégat des deux partitions /dev/hda2 et /dev/hdb1, respectivement de tailles 16579080 et 59665410 secteurs, il suffit d'utiliser les deux lignes suivantes :
0 16579080 linear /dev/hda2 0
16579080 59665410 linear /dev/hdb1 0On constatera que le secteur de départ dans l'agrégat de la deuxième composante est le secteur suivant le dernier secteur défini par la première composante. De manière générale, il n'est pas possible de définir des trous dans un agrégat. La totalité des deux partitions est utilisée dans cet exemple, pour créer un volume de taille totale 40 Go environ (pour rappel, un secteur de disque dur fait 512 octets, les deux partitions de cet exemple font donc environ 8 et 32 Go).
Une fois l'agrégat créé, un fichier spécial de périphérique portant le nom de l'agrégat doit apparaître dans le répertoire /dev/mapper/. Ce fichier spécial de périphérique peut être utilisé comme n'importe quel fichier spécial de périphérique, pour y créer un système de fichiers, pour le monter et pour le démonter. Par exemple, pour créer un agrégat group0 avec les définitions précédentes, il suffit d'exécuter la commande suivante :
dmsetup create group0 group0.defoù group0.def est le fichier contenant les deux lignes définissant les composantes vues ci-dessus. La création et le montage du système de fichiers se font ensuite avec les commandes suivantes :
mke2fs /dev/mapper/group0
mount /dev/mapper/group0 /mnt/groupoù /mnt/group/ est le nom du répertoire où le système de fichiers agrégé doit être monté.
Lorsqu'un agrégat n'est plus utilisé, il peut être supprimé à l'aide de l'option remove de dmsetup
dmsetup remove agrégatCela ne supprime bien entendu pas les données, mais détruit l'association entre les composantes de cet agrégat.
Note : Les fonctionnalités d'agrégation de volumes ne sont disponibles que si les options « Multiple devices driver support (RAID and LVM) », « Device mapper support » et « Crypt target support » du noyau ont été activées dans le menu « Multidevice support (RAID and LVM) » du programme de configuration du noyau.
dmsetup utilise le fichier spécial de périphérique /dev/mapper/control pour communiquer avec le noyau. Vous devrez donc créer ce fichier si votre distribution ne le fournit pas. Pour cela, vous pouvez exécuter le script devmap_mknot.sh fourni dans le répertoire scripts/ des sources de dmsetup. Ce script permet également de créer le répertoire /dev/mapper/ si celui-ci n'existe pas.
VI-G-3. Chiffrement des systèmes de fichiers▲
Il est possible de créer des systèmes de fichiers chiffrés afin de garantir la confidentialité des données qui y sont stockées. Ces systèmes de fichiers sont chiffrés à la volée par le noyau avec des algorithmes de chiffrement très puissants, que l'on paramètre avec une clef de chiffrement. Cette clef doit bien entendu rester secrète, faute de quoi tout ce travail de chiffrement devient inutile. Le chiffrement et le déchiffrement sont réalisés de manière complètement transparente par le noyau lors des accès aux répertoires et aux fichiers du système de fichiers, qui apparaît donc en clair lorsqu'on l'utilise. La différence est donc que le système de fichiers reste illisible pour tous les autres ordinateurs, ou pour tous les autres utilisateurs s'ils n'ont pas la clef de décryptage et que le système de fichiers n'est pas monté (rappelons que le mécanisme des droits Unix permet à un utilisateur d'interdire aux autres utilisateurs de consulter ses données).
Pour créer un tel système de fichiers, il est nécessaire de créer un volume agrégé, et d'utiliser un algorithme de chiffrement comme algorithme d'agrégation. Ceci se fait simplement en indiquant que les composantes de l'agrégat utilisent la technique d'agrégation crypt. Cette technique est semblable à la technique linear, à ceci près qu'elles permettent de chiffrer les données à la volée. L'algorithme de chiffrement utilisé peut alors être spécifié et prendre en paramètre une clef privée, qui doit être fournie à chaque fois que l'agrégat est redéfini, faute de quoi les données resteront indéchiffrables. Pour des raisons de sécurité, un vecteur d'initialisation peut être utilisé afin de rendre plus difficiles les tentatives de décryptage par la force brute. Ce vecteur d'initialisation est ajouté à la clef de chiffrement et permet ainsi d'obtenir des données chiffrées différentes pour deux systèmes de fichiers même si les clefs utilisées sont identiques. Dans l'implémentation actuelle, le vecteur d'initialisation utilisé est le numéro du secteur chiffré, ce qui n'est pas la panacée étant donné que ce numéro est prédictible, mais c'est déjà mieux que rien.
La technique d'agrégation crypt prend en paramètre l'algorithme de chiffrement à utiliser, la clef privée à utiliser pour chiffrer le volume agrégé, un décalage à ajouter au numéro du secteur pour déterminer le vecteur d'initialisation, le fichier spécial de périphérique sur lequel les données chiffrées seront écrites, et le numéro du secteur de ce périphérique à partir duquel les données seront écrites. Les décalages fournis permettent de n'utiliser qu'une partie d'un périphérique de type bloc pour stocker les données chiffrées. En général, ces valeurs seront nulles, car les données sont souvent stockées sur la totalité du périphérique hôte.
Ainsi, la définition d'une composante de l'agrégat chiffré se fait selon la syntaxe suivante :
début taille crypt algorithme clef décalage périphérique origineoù début et taille définissent la composante dans l'agrégat, algorithme et clef l'algorithme de chiffrement et la clef privée utilisée, décalage le décalage pour le vecteur d'initialisation, périphérique le fichier spécial de périphérique dans lequel les données chiffrées devront être écrites, et origine le secteur de départ dans ce périphérique à partir duquel les données seront écrites.
Les algorithmes utilisables sont les algorithmes de chiffrement inclus dans la configuration du noyau, dont vous pourrez trouver la liste et les paramètres dans le fichier /proc/crypto. Pour chaque algorithme de chiffrement, vous pouvez indiquer si vous désirez utiliser un vecteur d'initialisation ou non en ajoutant un suffixe à leur nom. Le suffixe ecb signifie qu'il n'y a pas de vecteur d'initialisation, et le suffixe plain signifie que le vecteur utilisé est le numéro de secteur. Bien entendu, vous devriez utiliser plain, en attendant qu'une meilleure technique ne soit mise au point. Ainsi, le nom d'algorithme des-plain indique que l'algorithme DES doit être utilisé avec un vecteur d'initialisation. La clef de cet algorithme doit faire 64 bits (soit huit octets).
Une fois l'agrégat défini, celui-ci peut être accédé comme un périphérique de type bloc classique, via son fichier spécial de périphérique dans le répertoire /dev/mapper/. La création du système de fichiers se fait de la même manière que pour les autres fichiers spéciaux de type bloc. Par exemple, pour chiffrer la partition /dev/hda2 (dont la taille est supposée être de 10000000 blocs) avec l'algorithme AES, vous devrez définir l'agrégat suivant :
0 10000000 crypt aes-plain clef 0 /dev/hda2 0où clef est une clef de taille comprise entre 16 et 32 octets. Si cet agrégat a été nommée cr0, vous pourrez ensuite créer le système de fichiers simplement avec la commande suivante :
mkfs -t ext2 /dev/mapper/cr0et le monter dans le répertoire /mnt/secure/ avec une commande telle que celle-ci :
mount /dev/mapper/cr0 /mnt/secureEnfin, il est possible d'utiliser un fichier en tant que périphérique de stockage des données chiffrées. Pour cela, il faut associer ce fichier à un fichier de type bloc virtuel à l'aide de la commande losetup. Ce fichier peut ensuite être utilisé pour définir un agrégat, comme n'importe quel autre fichier spécial de périphérique.
VI-H. Configuration des terminaux virtuels▲
Un terminal est, comme son nom l'indique, un équipement qui se trouve au bout d'une connexion à un ordinateur et qui permet de travailler sur l'ordinateur. Un terminal comprend généralement un clavier et un écran (graphique pour les terminaux X), et parfois une souris. Initialement, les terminaux étaient des périphériques passifs connectés sur un port série de l'ordinateur. Cette architecture permettait de partager une même unité centrale avec plusieurs utilisateurs. De nos jours, la plupart des terminaux sont simplement d'autres ordinateurs du réseau, qui se connectent à l'aide d'un programme que l'on appelle « émulateur de terminal ». L'émulateur de terminal se contente de simuler un terminal réel et permet de se connecter à toute machine gérant des terminaux clients. Du point de vue du système, tous les utilisateurs sont connectés via des terminaux, qu'ils soient physiques ou émulés.
Les connexions locales sont donc réalisées par l'intermédiaire d'un terminal local, la console. La console est tout simplement le périphérique prenant en charge le clavier et l'écran. Ce périphérique est géré directement par le noyau, et émule un modèle de terminal standard, le VT102. En fait, la console n'est utilisée directement en tant que terminal de login qu'en mode monoutilisateur (c'est-à-dire en mode maintenance). En mode multiutilisateur, la console est partagée entre plusieurs terminaux dits « virtuels », parce qu'ils simulent la présence de plusieurs terminaux sur la même console. Ces terminaux virtuels se partagent le clavier et l'écran, mais seulement un de ces terminaux peut accéder à la console à chaque instant : celui qui traite les caractères saisis au clavier et qui réalise l'affichage. Pour pouvoir passer d'un terminal virtuel à un autre, il faut utiliser une séquence de touches spéciale, par exemple ALT+Fn (ou CTRL+ALT+Fn si vous êtes sous XWindow), où Fn est l'une des touches de fonction du clavier. Si l'on utilise cette combinaison avec la touche F1, on accédera au premier terminal virtuel. Avec la touche F2, ce sera le deuxième, avec F3, le troisième, etc.
Il est donc possible de simuler la présence de plusieurs écrans et claviers sur une même machine, ce qui est très pratique lorsqu'on commence à lancer plusieurs programmes en même temps (cela nécessite évidemment de se connecter plusieurs fois sur des terminaux différents). Bien entendu, la configuration du clavier et la police de caractères utilisée sont communes à tous les terminaux virtuels, puisqu'ils utilisent tous la même console.
La plupart des distributions utilisent au moins quatre terminaux virtuels, plus éventuellement un terminal pour le serveur X. Mais il est possible de définir d'autres terminaux, qu'ils soient graphiques ou non. Nous allons maintenant voir comment modifier le nombre de terminaux virtuels disponibles. L'utilisation des terminaux avec XWindow sera traitée dans le chapitre traitant de la configuration de XWindow.
Chaque terminal virtuel utilise un fichier spécial de périphérique du répertoire /dev/. Le nom de ce fichier commence toujours par « tty » et est complété par le numéro du terminal. Ainsi, le fichier spécial de périphérique /dev/tty1 correspond au premier terminal virtuel, accessible avec la combinaison de touches CTRL+ALT+F1, le fichier spécial de périphérique /dev/tty2 correspond au deuxième terminal virtuel, etc. Linux peut gérer jusqu'à 64 terminaux virtuels, cependant, il est nécessaire de définir d'autres combinaisons de touches pour accéder aux terminaux 13 et suivants (puisqu'il n'existe que 12 touches de fonctions). Il serait possible d'utiliser les combinaisons de touches ALT+DROITE et ALT+GAUCHE pour les atteindre, mais d'une part ce ne serait pas très pratique, et d'autre part, vous ne devriez pas avoir besoin de plus de quatre ou cinq terminaux virtuels. Nous n'utiliserons donc ici que les douze premiers terminaux virtuels.
Les terminaux virtuels sont créés par le noyau à la demande, dès qu'un processus cherche à y accéder. Ainsi, le système n'alloue les ressources utilisées pour la gestion de ces terminaux que lorsque cela est nécessaire. Les terminaux peuvent être créés par différents processus, et leur emploi n'est pas restreint à la simple connexion des utilisateurs. Par exemple, il est possible d'afficher un message sur un terminal simplement en écrivant dans son fichier spécial de périphérique. Ainsi, si vous tapez la commande suivante sous le compte root :
echo Coucou > /dev/tty11la chaîne de caractères « Coucou » devrait apparaître sur le terminal virtuel 11.
En général, les terminaux virtuels sont utilisés soit pour afficher les messages du système, soit pour permettre aux utilisateurs de se connecter, soit pour XWindow. Les terminaux peuvent donc être attribués à différents programmes, selon l'emploi qu'on leur réserve. Il faudra cependant bien prendre garde au fait que les terminaux ne sont pas partageables entre tous les processus. Ainsi, on ne devra pas essayer de lancer un serveur X sur un terminal utilisé par un processus de connexion en mode texte.
Pour créer des terminaux de login, il suffit de demander au système de lancer les processus de connexion sur chaque terminal désiré. Ce travail est à la charge du processus fondamental du système : init. La définition des terminaux de login se fait donc dans le fichier de configuration /etc/inittab. Si vous regardez le contenu de ce fichier, vous trouverez quelques lignes semblables à la suivante :
1:2345:respawn:/sbin/getty 9600 tty1 linux
2:2345:respawn:/sbin/getty 9600 tty2 linux
etc.Ces lignes indiquent à init que plusieurs processus getty doivent être lancés sur les différents terminaux virtuels. Le programme getty est le programme qui vous demande votre nom d'utilisateur sur les terminaux virtuels. Plus précisément, getty initialise le terminal, demande le nom d'utilisateur et lance le programme login en lui fournissant le nom saisi, afin que celui-ci demande le mot de passe de cet utilisateur.
Si vous désirez rajouter des terminaux de login à votre configuration, vous devrez donc rajouter des lignes de ce genre dans le fichier /etc/inittab. En fait, ces lignes sont constituées de quatre champs :
- le premier champ est le numéro de la ligne. En pratique, ce numéro doit être celui du terminal virtuel qui sera utilisé par getty ;
- le champ suivant (« 2345 ») contient les numéros des niveaux d'exécution dans lesquels cette ligne est valide. Ces numéros doivent être spécifiés les uns à la suite des autres, sans séparateur. Dans l'exemple donné ci-dessus, ces lignes sont valides dans les niveaux d'exécution 2 à 5 compris, c'est-à-dire tous les niveaux d'exécution classiques ;
- le troisième champ indique à init des options pour le lancement du programme getty. Dans l'exemple donné ci-dessus, le programme getty doit être relancé immédiatement dès qu'il se termine. Cela est le comportement désiré, puisque la terminaison de getty correspond à la déconnexion de l'utilisateur courant, et qu'il faut laisser la possibilité de se reconnecter aux suivants ;
- le dernier champ indique le programme à lancer et ses options de ligne de commande. Dans notre cas, il s'agit de /sbin/getty. Les options indiquées sont la vitesse de la ligne de communication utilisée, le nom du terminal sur lequel getty doit travailler et son type (ici, ce sont des terminaux de type « linux »).
Vous pouvez bien entendu vous baser sur les lignes existantes pour en créer de nouvelles. L'opération est très simple : il suffit de renuméroter les lignes et les terminaux virtuels utilisés. Prenez garde cependant à ne pas affecter à getty un terminal utilisé par XWindow. Il est recommandé d'effectuer ces modifications dans le niveau d'exécution 2 pour ne pas être gêné par XWindow.
Une fois les modifications ajoutées, vous pourrez demander à init de relire son fichier de configuration avec la commande suivante :
init QDès lors, les nouveaux terminaux sont prêts à être utilisés.
VI-I. Configuration de la console▲
Comme nous venons de le voir, tous les terminaux virtuels utilisent la même console. La suite logique des opérations est donc de voir comment on réalise la configuration de celle-ci… Nous allons donc voir dans ce chapitre la manière de paramétrer le clavier et l'affichage du texte à l'écran.
Pour cela, il est nécessaire de bien comprendre les mécanismes mis en œuvre pour le traitement des codes émis par le clavier d'une part, et pour l'affichage des symboles des lettres à partir de leurs codes d'autre part. Ces mécanismes sont relativement évolués et complexes, mais permettent de paramétrer avec précision la disposition des touches du clavier, le comportement des applications et l'allure des symboles affichés à l'écran.
Le plus simple pour comprendre le fonctionnement de la console est encore de voir les différentes étapes entrant en ligne de compte de l'appui sur une touche jusqu'à l'action correspondant à cet appui. Notez bien que cette action n'est pas forcément l'affichage d'une lettre à l'écran : cela dépend de l'application qui a traité l'événement correspondant à l'appui sur la touche. Il est toutefois nécessaire de présenter auparavant quelques notions sur la manière dont les caractères sont représentés dans les programmes.
VI-I-1. Pages de codes et Unicode▲
De par leur nature de calculateurs, les ordinateurs n'ont jamais été conçus pour manipuler nativement du texte. Cela signifie qu'ils n'ont aucune notion de caractère ou de symbole : pour eux, tout est numérique. Par conséquent, il a fallu trouver le moyen de représenter les caractères humains sous une forme numérique afin de pouvoir réaliser des programmes de manipulation de texte. Cette représentation est effectuée en associant à chaque caractère un numéro donné, et en travaillant directement sur ces numéros. Par exemple, le caractère 'A' est classiquement représenté par le nombre 65, la lettre 'B' par le nombre 66, etc. L'opération consistant à effectuer cette association sur chaque caractère d'un texte constitue ce que l'on appelle l'encodage du texte. Plusieurs manières de réaliser cet encodage ont été inventées, mais l'un des standards les plus utilisés est l'encodage ASCII. Lorsqu'il a été créé, l'encodage ASCII codait les caractères sur 7 bits. Depuis, il a été étendu pour utiliser 8 bits, ce qui fait que chaque caractère est dorénavant codé sur un octet. Ainsi, il est possible de représenter 256 caractères différents avec un octet, ce qui est suffisant pour toutes les langues occidentales.
Cependant, le standard ASCII initial ne spécifiait que l'encodage des caractères utilisés en anglais, tout simplement parce que les Américains parlent anglais. Évidemment, cela ne convenait pas pour les pays qui utilisent des lettres accentuées, c'est-à-dire pour quasiment tout le monde. Il a donc fallu définir d'autres conventions que celle initialement utilisée, afin d'associer des codes numériques aux caractères utilisés par les autres pays. Ces conventions constituent ce que l'on appelle les pages de codes. Chaque pays est donc susceptible d'utiliser une page de codes qui lui est spécifique. Par exemple, la page de codes 437 représente l'encodage utilisé aux États-Unis, et la 850 celle utilisée en France.
Historiquement, les pages de codes n'ont pas été immédiatement standardisées, ce qui a conduit à la prolifération de pages différentes et parfois incompatibles. Ainsi, les pages de codes utilisées en France sont les pages de codes 850 sous DOS, 1252 sous Windows, ISO 8859-1 et ISO 8859-15 sous Unix. Ces deux dernières constituent la norme actuelle, et sont celles qui doivent être utilisées de préférence. La norme ISO 8859-1 est également connue sous le nom latin-1, et la norme ISO 8859-15 sous le nom latin-0. La norme latin-0 est une extension de la latin-1, qui ne prévoyait pas le codage de certains caractères européens (comme le o e dans l'o français) et le symbole de l'Euro.
Le défaut majeur de l'ASCII et de ses dérivés est de travailler sur des nombres à 8 bits. Si le nombre de 256 caractères différents convient pour la plupart des pays occidentaux, ce n'est pas le cas de quelques autres pays, qui utilisent un nombre de symboles de très loin supérieur à 256. C'est notamment le cas du Japon et de la Chine, qui ne peuvent pas encoder tous leurs idéogrammes sur des nombres à 8 bits. Il a donc fallu introduire d'autres types d'encodages, plus riches, permettant de satisfaire aux besoins de tout le monde.
Après des tentatives infructueuses d'encodages à taille variable (un ou plusieurs octets selon le caractère codé), Unicode a été introduit et normalisé sous le nom ISO 10646. Unicode est une convention de codage universelle des caractères, qui utilise pour cela des nombres 32 bits (il existe également une version plus ancienne qui n'utilise que 16 bits). Chaque caractère est représenté par un nombre et un seul, comme pour l'ASCII. Cependant, avec ses 16 ou 32 bits, le jeu de caractères Unicode est suffisamment large pour coder tous les caractères de toutes les langues du monde. Bien entendu, tous les codes ne sont pas utilisés, et le jeu de caractères Unicode est discontinu. Pour des raisons de compatibilité, les 256 premiers caractères Unicode sont les mêmes que ceux définis dans la norme ISO 8859-1 (ce qui rend malheureusement non compatible la norme ISO 8859-15, plus complète). Les autres caractères sont affectés à d'autres plages de codes, qui sont parfaitement définies. Ainsi, l'utilisation d'Unicode permettra, à terme, de n'avoir plus qu'une seule page de codes pour tous les pays.
Malheureusement, Unicode est une évolution relativement récente, et la plupart des programmes travaillent encore avec des caractères 8 bits, ce qui rend l'utilisation d'Unicode prématurée. Linux, quant à lui, est capable de gérer l'Unicode. Cependant, pour des raisons d'économie de place, il ne l'utilise pas directement. Il préfère en effet utiliser l'encodage UTF-8 (abréviation de l'anglais « Unicode Tranfer Format »). Cet encodage est un encodage à taille variable, qui permet d'encoder les caractères Unicode avec de un à six octets selon leur emplacement dans la page de codes Unicode.
VI-I-2. Principe de fonctionnement du clavier▲
En général, les claviers envoient une série de codes à l'unité centrale lorsqu'on appuie sur une touche. Certaines touches génèrent un seul code, d'autres peuvent en produire jusqu'à une dizaine. Ces codes, que l'on appelle scancode, sont récupérés par le pilote du clavier dans le noyau de Linux, et constituent le début du traitement des saisies clavier. Les scancodes permettent normalement de déterminer avec certitude l'événement qui s'est produit, pour peu que l'on connaisse parfaitement le type de clavier utilisé. Malheureusement, ils sont spécifiques à chaque modèle de clavier, et il est difficilement concevable pour un programme de prendre en charge les particularités de tous les claviers existants. De plus, qui peut prévoir aujourd'hui combien de touches les claviers du futur auront, et quels scancodes ceux-ci utiliseront ?
Linux effectue donc un travail d'uniformisation en interprétant les scancodes et en les traduisant en d'autres codes, les keycodes. Ces codes sont toujours les mêmes, quel que soit le clavier utilisé. Les keycodes simplifient le traitement des données provenant du clavier en définissant un code de touche unique à chacune des touches du clavier. Les keycodes sont également souvent appelés les codes de touches virtuelles, car ils correspondent aux scancodes d'un clavier virtuel uniforme et commun à toutes les plates-formes. La gestion des événements clavier par l'intermédiaire des keycodes est donc beaucoup plus aisée, car il n'y a plus à se soucier ici que de ce clavier virtuel. La correspondance entre les scancodes, donc les touches physiques, et les keycodes, ou codes de touches virtuelles, est définie dans le pilote du clavier. La plupart des claviers courants sont pris en charge et, en général, peu de personnes ont besoin de modifier ce type d'information. Toutefois, afin de permettre l'intégration des claviers futurs, il est possible de compléter la table de conversion des scancodes en codes de touches virtuelles.
L'interprétation des keycodes est une opération relativement compliquée et peu commode à cause du grand nombre de dispositions de clavier existantes et, pour chaque type de clavier, des différentes déclinaisons existantes en fonction des langages des divers pays qui les utilisent. C'est pour cela qu'une autre association, qui permet de définir le comportement à obtenir pour chaque combinaison de codes de touches virtuelles, a été introduite. Cette correspondance est décrite dans un fichier que l'on appelle couramment le plan de clavier (ou keymap en anglais). Les keymaps contiennent donc, pour chaque touche ou combinaison de touches virtuelles utilisée, la définition d'une action à effectuer ou d'un code de caractère à renvoyer. Ces codes sont renvoyés en ASCII, codés selon la page de codes définie dans le plan de clavier. Cependant, certaines touches ne sont pas associées à une lettre ASCII et ne peuvent donc pas être représentées par des codes simples. C'est le cas, par exemple, des touches du curseur et des touches de suppression du clavier. Ces touches sont donc signalées aux programmes à l'aide de séquences de codes appelées les codes d'échappement. Les codes d'échappement sont en réalité des séquences de codes ASCII dont le premier est le code du caractère d'échappement Escape (dont le numéro est 27, quelle que soit la page de codes utilisée). Ces séquences sont donc utilisées typiquement pour signaler aux programmes qui les lisent qu'un traitement particulier doit être effectué, par exemple le déplacement du curseur.
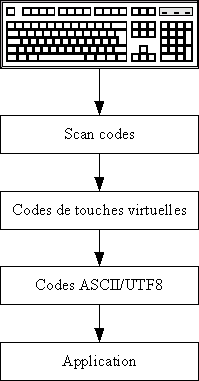
Les programmes peuvent travailler à n'importe lequel des trois niveaux de traitement que l'on vient de décrire. Les programmes qui récupèrent directement les scancodes travaillent en mode raw (ce qui signifie en anglais que les données sont « brutes »). Ils n'utilisent donc pas la traduction en codes de touches virtuelles et doivent nécessairement connaître les caractéristiques physiques des claviers qu'ils veulent supporter. C'est le cas par exemple des serveurs X. Les programmes qui utilisent les keycodes travaillent dans le mode nommé medium raw ou keycode. Cependant, la plupart des programmes travaillent avec les codes issus du plan de clavier, qui sont normalisés et font bénéficier d'une plus grande portabilité (y compris avec d'autres systèmes Unix que Linux). Dans ce cas, on dit qu'ils travaillent en mode ASCII, ou xlate (abréviation de l'anglais « translate », ce qui signifie « traduction »).
Note : En fait, la console peut également travailler en Unicode, dans le mode UTF-8. Ce mode permet de travailler directement en Unicode, si vous le désirez. Cependant, vous devrez vous assurer dans ce cas que tous les programmes que vous utilisez sont capables de fonctionner avec un encodage à taille variable.
Dans tous les cas, les programmes lisent les données provenant du clavier sur la console, par l'intermédiaire du fichier spécial de périphérique /dev/console. En fait, ces programmes ne savent pas qu'ils lisent les données du clavier local. Pour eux, ces données semblent provenir d'un terminal VT102, et ils traitent ces données comme celles provenant de n'importe quel terminal. Cela signifie que ces données semblent provenir d'une ligne de communication, à laquelle le terminal local est connecté. Et qui dit ligne de communication, dit paramètres de transmission des informations sur la ligne ! Les caractères issus de la keymap peuvent donc subir un traitement supplémentaire, en fonction des paramètres de la ligne de communication (virtuelle) utilisée par la console. Cependant, il n'est en général pas nécessaire de modifier ces paramètres, puisque la ligne de communication utilisée est bien entendu idéale (quitte à être virtuelle, autant être idéale, non ?).
Gloups !? Que c'est compliqué ! C'est effectivement la réflexion que vous êtes en droit de vous faire. Cependant, si l'on prend un peu de distance par rapport à ce mécanisme en trois passes, on comprend son intérêt. Premièrement, la contrainte initiale est la complexité des scancodes. Sur ce point, il n'y a rien à dire. Grâce aux keycodes, il n'est plus nécessaire de se soucier du modèle de clavier utilisé. Ensuite, grâce aux keymaps, il est possible de faire l'association entre les keycodes et les lettres écrites sur les touches du clavier. Ainsi, la disposition du clavier, ainsi que les raccourcis clavier, peuvent être complètement paramétrés. Enfin, les applications qui gèrent les touches spéciales du clavier peuvent interpréter les codes d'échappement, qui sont ceux renvoyés par le terminal de la console. Dans tous les cas, les programmes qui lisent les données du clavier considèrent que ces données proviennent d'un terminal classique. Ils n'ont donc pas besoin de faire des hypothèses sur l'origine des données, et leur programmation en est d'autant plus simple.
Passons maintenant aux travaux pratiques. La commande kbd_mode permet de déterminer le mode de fonctionnement du clavier. Si vous l'essayez à partir d'une console, vous verrez que le clavier est en mode ASCII. Inversement, si vous tapez cette commande à partir d'une session X, vous constaterez que XWindow utilise le clavier en mode raw, et gère donc les scancodes lui-même. Vous pouvez également visualiser les codes renvoyés dans les trois modes de fonctionnement du clavier avec la commande showkey. Lancée avec l'option -s, elle permet d'afficher les scancodes lors de l'appui sur chaque touche. Vous pourrez constater que toutes les touches ne renvoient pas le même nombre de codes. Vous pourrez utiliser l'option -k pour visualiser les keycodes renvoyés par le noyau lors de l'appui et du relâchement des touches. Enfin, si vous utilisez l'option -a, vous verrez les codes de touches ASCII. Vous pourrez constater que les touches spéciales renvoient des séquences de codes d'échappement.
Note : Notez également que certaines touches renvoient des caractères de contrôle (notés ^A à ^Z). Ces caractères correspondent en fait aux codes ASCII allant de 1 à 26 et ne sont pas des séquences d'échappement. Ils peuvent également être générés avec les combinaisons de touches CTRL+A à CTRL+Z. Si vous ne me croyez pas, tapez la commande ls dans une console et tapez la combinaison de touches CTRL+M (celle affectée à la touche Entrée). Vous verrez, c'est comme si vous aviez tapé Entrée !
Le programme showkey ne peut pas être lancé sous XWindow, parce que celui-ci gère lui-même le clavier. showkey se termine de lui-même au bout de dix secondes après la dernière frappe, ou lors de l'appui de la séquence de touches CTRL+D s'il est en mode ASCII.
VI-I-3. Principe de fonctionnement de l'écran de la console▲
Il est temps maintenant de passer au mécanisme d'affichage des caractères sur l'écran. Comme vous avez pu le voir dans les paragraphes précédents, le fait d'appuyer sur une touche ne fait rien d'autre que de fournir des codes numériques aux programmes. Contrairement à ce que vous pourriez penser, les codes de ces touches ne sont pas forcément transmis directement à l'écran (heureusement, comment taperiez-vous votre mot de passe à l'abri des regards indiscrets sinon ?). En fait, l'affichage des caractères à l'écran est un des paramètres de la ligne du terminal, que l'on nomme echo. Pour la plupart des programmes, l'écho automatique est désactivé. Pour d'autres ce sont les applications qui, en fonction des codes qu'elles lisent sur la console, effectuent une action. Mais la majorité de ces actions nécessitent effectivement d'afficher des résultats sur le moniteur. Pour réaliser cela, les programmes écrivent les données à afficher dans le fichier spécial de périphérique de la console.
Comme nous l'avons vu, la console de Linux se comporte comme un terminal local. Cela implique que les applications qui désirent écrire des données doivent les envoyer par la ligne de communication via laquelle elles sont connectées à ce terminal. Tout comme les scancodes du clavier, les caractères envoyés à la console par les applications subissent un traitement imposé par les paramètres de la ligne de communication virtuelle utilisée. Bien entendu, ce traitement est encore une fois minimal, puisque cette ligne est idéale. Notez que les programmes n'en savent absolument rien, car, pour eux, tout se passe comme s'ils écrivaient sur un terminal réel. Quoi qu'il en soit, le flux de caractères arrive au niveau du gestionnaire de la console après ce traitement de base.
Comme nous l'avons déjà dit plus haut, la console Linux émule un terminal VT102, et recherche donc les codes de contrôle et les séquences d'échappement de ces consoles. Ces codes d'échappement sont classiquement utilisés pour effectuer des opérations sur la console, par exemple le déplacement du curseur, la prise en compte de la couleur et des attributs des caractères affichés, l'effacement de l'écran, etc. Pour information, tous les codes de la console sont décrits dans la page de manuel console_codes.
Les codes qui ne sont pas reconnus comme étant des codes d'échappement sont traités en tant que caractères normaux. Le gestionnaire de la console doit donc déterminer quel caractère doit être imprimé à l'écran pour chaque code fourni par l'application. Cela n'est pas une opération facile, parce que les polices de caractères, qui contiennent la définition de la représentation graphique des caractères, n'utilisent pas forcément la page de codes active dans le système. Cela signifie que les caractères définis dans la police n'apparaissent pas forcément dans le même ordre que celui de la page de codes, et pour cause : une police peut parfaitement être utilisable dans plusieurs pays différents ! Cela complique donc un peu plus les choses, puisqu'il faut utiliser une table de conversion entre la page de codes du texte à afficher et l'encodage propre de la police.
Afin de réaliser cette conversion, le gestionnaire de la console Linux commence par convertir tous les caractères qu'il reçoit en « Unicode ». Si la console est en mode UTF-8, cette opération est immédiate, car l'UTF-8 est un encodage Unicode. En revanche, si la console est en mode ASCII, cette opération nécessite l'emploi d'une table de conversion. Linux dispose de quatre tables de conversion :
- la première table permet de faire la conversion entre la page de codes ISO 8859-1 et Unicode (cette conversion est, par définition, immédiate) ;
- la deuxième table permet de faire la conversion entre les codes graphiques des terminaux VT100 et Unicode ;
- la troisième table permet d'effectuer la conversion entre la page de codes 437 et Unicode ;
- et la quatrième et dernière table est réservée à l'usage personnel de l'utilisateur.
La dernière table est très utile, car elle permet de définir une nouvelle table de conversion si nécessaire. Par défaut, elle convertit les codes reçus en codes Unicode spéciaux, qui représentent les codes utilisés par la police de caractères chargée. Ainsi, lorsque cette table est utilisée, les codes reçus par la console seront utilisés directement pour localiser les caractères dans la police de caractères. Cela ne peut fonctionner que si les applications utilisent le même encodage que la police de caractères courante.
Linux dispose de deux jeux de caractères, nommés respectivement G0 et G1, qui permettent de sélectionner la table de conversion à utiliser. Par défaut, ces jeux de caractères pointent respectivement sur la première et la deuxième table de conversion, mais cela peut être modifié à l'aide de codes d'échappement. Seul un jeu de caractères est actif à un moment donné. Par défaut, il s'agit du jeu G0, ce qui implique que la table de conversion utilisée par défaut est la table ISO 8859-1 vers Unicode. Il est également possible de changer de jeu de caractères, à l'aide d'un code de contrôle. Ce mécanisme ne sera pas décrit plus en détail ici, car il ne nous sera pas utile.
Note : En fait, la recherche des codes de contrôle est effectuée a posteriori, après la conversion en Unicode.
Dans tous les cas, les codes envoyés par l'application sont donc convertis en Unicode (16 bits). Ils peuvent donc être reconvertis aisément dans l'encodage utilisé par la police de caractère chargée en mémoire vidéo. Par défaut, cette opération est triviale, et l'encodage cible est donc l'encodage ISO 8859-1, sauf si la quatrième table de conversion a été utilisée. Dans ce cas en effet, l'encodage cible est le même encodage que celui utilisé par l'application (tout se passe donc comme si rien ne s'était passé). Enfin, la dernière opération est tout simplement l'écriture du code dans la mémoire vidéo. Ce code est utilisé par la carte graphique comme index dans la police de caractère, et le caractère ainsi localisé est affiché.
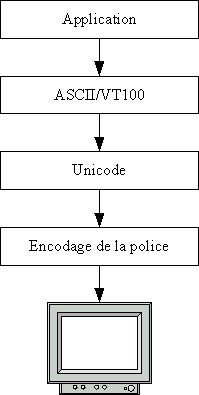
Gloups !? Que c'est compliqué ! Ça ne va pas recommencer ? Eh si ! Mais, encore une fois, ce mécanisme permet de rendre indépendantes les applications des polices de caractères. Chacun peut utiliser l'encodage qu'il désire, et grâce à un petit passage en Unicode, tous les caractères finissent par être représentés par le bon symbole à l'écran… En fait, le passage par Unicode donne la possibilité de définir les tables de conversion des polices uniquement par rapport à Unicode, et non par rapport à tous les encodages possibles que les applications peuvent utiliser. Cela permet donc l'utilisation de polices de caractères diverses et variées, sans avoir à modifier les applications.
VI-I-4. Configuration du clavier▲
Bien que les distributions modernes fournissent les outils nécessaires à la configuration correcte du clavier, vous aurez peut-être à intervenir pour le personnaliser selon vos propres désirs. La configuration du clavier comprend la définition des scancodes, la définition du plan de clavier, et le réglage de la vitesse de répétition et de la touche de verrou numérique.
VI-I-4-a. Définition de scancodes▲
La définition des scancodes est une opération qui nécessite une bonne connaissance du fonctionnement du clavier des PC. Heureusement, rares sont les personnes qui disposent de claviers non standards, c'est-à-dire, en pratique, de claviers disposant de plus de 105 touches. Notez que Linux reconnaît parfaitement les touches « Windows » qui ont été introduites par Microsoft, et il n'y a donc pas lieu de définir leurs scancodes. Cependant, les claviers les plus récents disposent de touches « Internet » ou « Multimedia », qui ne sont pas encore reconnues par Linux en standard. L'utilisation de ces touches se traduit donc simplement par un message d'erreur dans les traces systèmes. Si vous disposez d'un tel clavier, et que vous désirez utiliser ces touches, vous allez devoir les définir dans la table des scancodes du noyau.
Pour réaliser cette opération, il faut avant tout déterminer les scancodes envoyés par le clavier lors de l'appui sur la touche à définir. Comme nous l'avons indiqué plus haut, les scancodes peuvent être visualisés avec l'option -s de showkey :
showkey -sLes scancodes sont exprimés en hexadécimal, c'est-à-dire en base 16. Dans cette base, les lettres A à F représentent les chiffres manquants à la base 10, c'est-à-dire les chiffres ayant respectivement pour valeur 10, 11, 12, 13, 14 et 15.
En général, le clavier envoie un scancode lors de l'appui sur une touche, puis le même scancode augmenté de 128 lors de son relâchement. Le nombre de 128 provient du fait que le bit de poids fort du scancode est mis à un lors du relâchement de la touche. Ainsi, la touche 'A' des claviers français renvoie le scancode 16 lors de l'appui, soit 0x10 en hexadécimal, et le scancode 144, soit 0x90, lors du relâchement (notez que la valeur 128 se note 0x80 en hexadécimal, et que l'on a bien 0x90 = 0x10 + 0x80).
Cependant, certaines touches renvoient des scancodes plus complexes. Ces touches sont généralement des touches qui ont été ajoutées après la définition des premiers claviers PC, et qui ont sensiblement le même rôle qu'une touche déjà présente. C'est exactement le cas de la touche CTRL de droite par rapport à la touche CTRL de gauche. Pour cette raison, les scancodes de ces touches sont les mêmes que ceux de certaines touches « classiques », mais ils sont précédés du préfixe 0xE0, qui indique qu'il s'agit d'une touche étendue. Par exemple, la touche CTRL de gauche (c'est-à-dire la première touche de contrôle qui ait été utilisée) utilise le scancode 0x1D à l'appui, et le scancode 0x9D au relâchement. La touche CTRL de droite renvoie donc la séquence suivante à l'appui :
0xE0 0x1Det la séquence suivante au relâchement :
0xE0 0x9DL'intérêt de procéder ainsi est que les vieux programmes, incapables de gérer les codes de touches étendus, ignoraient purement et simplement le code 0xE0. Ainsi, ils confondaient les deux touches CTRL, ce qui est le comportement désiré.
D'autres touches étendues utilisent des séquences de scancodes variables. Par exemple, les touches du curseur (entre la touche Entrée et le pavé numérique) ont été ajoutées pour simplifier le déplacement du curseur à l'écran. Initialement, on n'utilisait que les touches du pavé numérique, en combinaison de la touche Majuscule de droite si le verrou numérique était enclenché. Par conséquent, la séquence de scancodes générée lors de l'utilisation de la touche Flèche Haute du pavé numérique était 0x48 si le verrou numérique n'était pas enclenché, et 0x2A 0x48 sinon (soit le scancode de la touche Majuscule de gauche suivi du scancode de la touche 8 du pavé numérique). Lors du relâchement, la séquence était inversée (et augmentée de 128) : 0xC8 ou 0xC8 0xAA selon l'état du verrou numérique. La touche Flèche Haute étendue renvoie donc deux séquences de scancodes différents selon l'état du verrou numérique 0xE0 0x48 ou 0xE0 0x2A 0xE0 0x48.
Lors du relâchement, la séquence suivante complexe 0xE0 0xC8 ou 0xE0 0xC8 0xE0 0xAA est émise selon l'état du verrou numérique. Notez que l'état du verrou numérique est maintenu en interne par l'électronique du clavier, indépendamment de l'état de la diode lumineuse du verrou numérique. Celui-ci peut en effet être enclenché sans que la diode soit allumée, si le programme de gestion du clavier ne synchronise pas le clavier et sa diode.
Enfin, pour couronner le tout, certaines touches spéciales utilisent une séquence de scancodes spécifiques. Par exemple, la touche Pause ne renvoie que la séquence 0xE1 0x1D 0x45 0xE1 0x9D 0xC5 à l'appui. Elle utilise donc le préfixe 0xE1 au lieu de 0xE0, et simule l'appui et le relâchement immédiat des touches CTRL + Verrou Numérique (ce qui était la manière de provoquer la pause avant l'introduction de la touche Pause).
Comme vous pouvez le constater, tout cela est très compliqué. Heureusement, le noyau fait le ménage pour vous et élimine les touches suivantes :
- les touches non étendues sont traitées immédiatement (scancodes 0x01 à 0x58) ;
- la touche Pause est gérée automatiquement ;
- les codes 0x2A et 0xAA de la touche Majuscule de droite sont automatiquement éliminés.
Grâce à ce traitement, les seuls scancodes que vous manipulerez sont les scancodes simples non connus, et les scancodes précédés du préfixe 0xE0.
L'association d'un scancode inconnu à un keycode se fait à l'aide de l'utilitaire setkeycodes. Sa syntaxe est la suivante :
setkeycodes scancode keycodeoù scancode est le numéro du scancode, exprimé en hexadécimal et sans le préfixe « 0x », et keycode est bien entendu le numéro de keycode à attribuer à cette touche. Les numéros de scancodes peuvent être simples (par exemple 48) ou précédés de leur préfixe (par exemple E048). Les numéros de keycodes doivent être exprimés en décimal, et doivent être compris entre 1 et 127.
Par exemple, mon clavier dispose de 12 touches « Multimédia » supplémentaires, dont les scancodes ne sont pas reconnues par le noyau. La touche Arrêt du son générant les scancodes suivants à l'appui :
0xE0 0x20je peux lui associer le keycode 119 avec la commande suivante :
setkeycodes E020 119Il va de soi qu'il faut s'assurer que chaque keycode n'est utilisé qu'une fois (à moins, bien entendu, de vouloir que plusieurs touches aient le même comportement). Pour cela, vous aurez sans doute besoin de voir les correspondances entre scancodes et keycodes. La commande suivante vous donnera la liste de ces correspondances :
getkeycodesLes keycodes sont présentés à raison de huit par ligne. Le scancode de la touche décrite par le premier élément de chaque ligne est affiché en tête de la ligne. Les autres scancodes peuvent être déduits en ajoutant le numéro de la colonne dans laquelle se trouve chaque keycode au numéro du scancode du premier keycode.
VI-I-4-b. Définition d'un plan de clavier▲
Comme nous l'avons expliqué dans les paragraphes précédents, les plans de clavier définissent les associations entre les keycodes et les caractères ou les séquences d'échappement renvoyés par le clavier. Les plans de clavier permettent également de définir des séquences de composition, afin d'obtenir de nouveaux caractères en composant les actions de plusieurs touches.
La définition d'un plan de clavier est donc constituée de trois parties. La première partie décrit les symboles accessibles pour certaines touches du clavier. Par exemple, les symboles accessibles pour la touche A peuvent être les caractères 'a', 'A', 'æ' et 'Æ', à l'aide des touches de majuscule et AltGr. La deuxième partie permet d'affecter des chaînes de caractères à certaines touches particulières. Cette partie peut contenir par exemple la définition de touches de raccourci pour les commandes les plus utilisées. En pratique cependant, elles sont souvent utilisées pour définir des séquences d'échappement pour les touches de fonction et les touches du curseur, séquences qui seront interprétées ensuite par les applications. Enfin, la dernière partie permet de définir les compositions de touches pour obtenir des caractères qui n'auraient été accessibles autrement que par des combinaisons de touches compliquées.
Pour chaque touche normale du clavier, il est possible de définir jusqu'à 256 symboles différents. Ces symboles sont sélectionnés grâce à des touches de modification du comportement de base des autres touches, par exemple la touche Ctrl ou la touche Alt Gr. Linux est capable de gérer des combinaisons de touches faisant intervenir jusqu'à huit touches de modification différentes en plus de la touche affectée (remarquez qu'avec dix doigts, on peut encore y parvenir !). Ces touches sont récapitulées dans le tableau suivant :
|
Touche de modification |
Valeur |
Description |
|
Shift |
1 |
Touches de passage en majuscule (situées au-dessus des touches Ctrl sur les claviers français). |
|
altgr |
2 |
Touche Alt Gr, située à droite de la barre d'espacement. |
|
control |
4 |
Touches Ctrl, situées aux extrémités inférieures du clavier. |
|
alt |
8 |
Touche Alt, située à gauche de la barre d'espacement. |
|
shiftl |
16 |
Touche de majuscule de gauche. |
|
shiftr |
32 |
Touche de majuscule de droite. |
|
ctrll |
64 |
Touche Ctrl de gauche. |
|
ctrlr |
128 |
Touche Ctrl de droite. |
Chaque touche dispose d'un code numérique qui est une puissance de deux. Lorsqu'elles sont utilisées dans une combinaison avec une touche donnée, la somme de ces valeurs est calculée pour déterminer le numéro du symbole dans la liste des symboles associés à la touche. Comme on peut le voir, toutes les valeurs possibles allant de 0 à 255 sont réalisables selon la combinaison de touches utilisée, ce qui permet donc de définir effectivement 256 symboles différents pour chaque touche du clavier.
Cependant, les touches Shift et Ctrl sont utilisées plusieurs fois dans le tableau, précisément trois fois, la première ne faisant pas de distinction entre la touche de droite et la touche de gauche. En pratique donc, toutes les combinaisons ne sont pas réalisables. Mais en réalité, les touches de contrôle du clavier sont des touches comme les autres, et peuvent être placées n'importe où dans le plan de clavier. Il est donc parfaitement possible de réaliser une distinction entre les touches Majuscule, Majuscule Droite et Majuscule Gauche (et de même pour les touches Ctrl). Par exemple, on peut associer la touche Majuscule à la touche Echap, ce qui permet de faire la distinction entre les trois variantes de touches de majuscules… Heureusement, il n'est pas nécessaire d'aller jusque là. Les plans de clavier n'utilisent en pratique que les quatre premières touches de contrôle, qui sont celles que vous connaissez.
La définition des symboles accessibles pour une touche utilise la syntaxe suivante :
keycode = symbole symbole symbole …où keycode est le keycode qui identifie la touche en question, et symbole est un des symboles acceptés dans les plans de clavier. Vous pourrez obtenir la liste des symboles utilisés grâce à la commande suivante :
dumpkeys --long-infoVous pourrez voir par exemple les symboles A, B, C, etc. qui représentent les lettres classiques, ainsi que des symboles spéciaux comme exclamdown, hyphen, cedilla, etc. pour les lettres non alphabétiques. Il existe également des symboles pour les touches spéciales comme Backspace, Delete, Escape. Enfin, le symbole VoidSymbol permet de signaler l'absence de symbole pour la combinaison de touches considérée.
En théorie, il faut définir la liste des 256 symboles accessibles pour chaque touche. Le premier symbole est donc le symbole obtenu par appui direct de la touche, le deuxième est celui obtenu par la combinaison Majuscule + Touche, le troisième celui de la combinaison AltGr + Touche, le quatrième par Majuscule + AltGr + Touche, etc. Évidemment, il est très fastidieux de définir ces 256 possibilités. Pour simplifier le format des plans de clavier, il est possible de ne spécifier que les combinaisons utilisées, ce qui réduit en pratique à quatre colonnes de symboles un plan de clavier français. De plus, les derniers symboles sont facultatifs s'ils sont tous VoidSymbol. Vous pouvez indiquer au début du plan de clavier les valeurs des combinaisons de touches de modifications qui seront effectivement utilisées avec la syntaxe suivante :
keymaps valeursoù valeurs est la liste des valeurs ou des plages de valeurs des combinaisons de touches utilisées. Les éléments de cette liste sont séparés par des virgules, et les plages de valeurs sont indiquées par leurs première et dernière valeurs, séparées par un tiret.
Vous pouvez également utiliser une autre syntaxe, qui permet de ne modifier que les symboles associés à certaines combinaisons de touches. Cette syntaxe est très utile lorsque vous ne désirez modifier que quelques affectations de touches :
modificateur keycode = symboleDans cette syntaxe, modificateur est la liste des modificateurs devant intervenir dans la combinaison de touches, et keycode et symbole sont toujours le keycode de la touche et le symbole à générer. Les modificateurs autorisés sont les noms des touches de modification indiquées dans le tableau ci-dessus, plus le modificateur plain, qui signifie qu'aucune touche de modification n'est utilisée. Par exemple, la ligne suivante :
plain keycode 16 = qpermet d'affecter le symbole q à la touche A de votre clavier, et la ligne :
alt keycode 30 = apermet d'affecter le symbole a à la combinaison de touches Alt + Q (n'essayez surtout pas ces deux exemples, vous deviendriez fou).
Note : Par défaut, les symboles utilisables dans les plans de clavier sont les symboles du jeu de caractères ISO 8859-1. D'autres encodages sont utilisables, mais celui-ci convient parfaitement pour un clavier français.
Comme nous l'avons dit plus haut, la deuxième partie d'un plan de clavier permet d'affecter des chaînes de caractères à certaines touches. Cela est facilement réalisable, avec la syntaxe suivante :
string symbole = "chaîne"où symbole est le nom d'un des symboles affecté précédemment à une touche, et chaîne est une chaîne de caractères. Les chaînes de caractères étant délimitées par des guillemets anglais (« " »), ceux-ci ne peuvent pas être utilisés en tant que caractères de ces chaînes. Pour résoudre ce problème, on peut utiliser un antislash comme caractère d'échappement :
\"Vous pouvez également spécifier des caractères directement à l'aide de leur valeur en base huit, à l'aide de la syntaxe suivante :
\0valeuroù valeur est la valeur du caractère. Bien entendu, l'antislash étant utilisé comme caractère d'échappement, il doit lui-même être précédé d'un caractère d'échappement si l'on désire l'utiliser dans une chaîne de caractères :
\\Ainsi, si l'on veut faire en sorte que la touche F4 affiche la chaîne de caractères « Coucou », il suffit d'utiliser la ligne suivante dans le plan de clavier :
string F4 = "Coucou"Bien entendu, les chaînes de caractères les plus utiles sont celles qui définissent les séquences d'échappement pour les touches spéciales. Par exemple, la définition de la touche Page Haut est la suivante :
string PageUp = "\033[5~"Vous pouvez reconnaître ces séquences d'échappement à la présence du caractère octal 033, soit 27 en décimal, qui n'est rien d'autre que le caractère Escape dans le jeu de caractères ISO 8859-1. Ne vous inquiétez par pour l'instant de la forme apparemment compliquée de ces séquences d'échappement, nous verrons plus loin comment elles sont utilisées.
Enfin, les plans de clavier contiennent la définition des compositions. Les compositions de touches sont accessibles à l'aide d'une touche spéciale dite de composition, dont le symbole est Compose dans le plan de clavier (il est donc nécessaire que ce symbole soit affecté à l'une des touches du clavier pour utiliser les compositions). Lorsqu'on appuie sur la touche de composition, le clavier attend deux autres touches, dont les caractères serviront de base au caractère composé. Par exemple, les caractères '^' et 'a' donnent le caractère composé 'â'.
Les compositions utilisent la syntaxe suivante :
compose 'caractère' 'caractère' to 'résultat'où caractère est un des deux caractères à composer et résultat est le caractère résultant de la composition. Notez bien que les compositions se font sur les caractères, et pas sur les touches. Elles sont donc actives, quelle que soit la méthode obtenue pour générer ces caractères (combinaison de touches ou touches simples).
Note : Le noyau définit la plupart des compositions nécessaires pour le jeu de caractères ISO 8859-1. Ne les cherchez donc pas en vain dans votre plan de clavier, vous ne les trouverez pas forcément…
D'une manière générale, vous pourrez trouver de plus amples renseignements concernant les plans de clavier dans la page de man keymaps.
Il est long et difficile de créer un plan de clavier de toutes pièces. Heureusement, encore une fois, cette description n'était que didactique. Vous n'aurez certainement même pas à modifier votre plan de clavier (sauf si vous voulez faire des expériences), car des plans de claviers prédéfinis sont fournis avec toutes les distributions. Ces plans de clavier sont en général stockés dans le répertoire /usr/lib/kbd/keymap. Pour les claviers de PC français, je vous conseille tout particulièrement le plan de clavier fr-latin0.map.gz du sous-répertoire i386/azerty. Ce plan de clavier permet d'accéder à toutes les touches utilisées par le français, plus la plupart des touches utilisées en Europe. Il utilise l'encodage ISO 8859-15, afin d'avoir accès aux rares caractères manquants dans l'encodage ISO 8859-1.
Le chargement d'un plan de clavier est très simple. Il suffit de taper la commande suivante sous le compte root :
loadkeys keymapoù keymap est le nom du fichier contenant le plan de clavier à utiliser. Si l'on ne spécifie pas de fichier, loadkey attend que vous tapiez la spécification des touches directement. Vous pourrez valider en générant le caractère EOF (abréviation de « End Of File », ce qui signifie « Fin de fichier ») à l'aide de la combinaison de touche CTRL + D, ou abandonner avec le classique CTRL + C.
En général, les distributions utilisent la commande loadkey dans les fichiers d'initialisation du système, pour charger le plan de clavier que vous avez choisi à l'installation dès le démarrage. Il est recommandé de ne modifier le plan de clavier courant que par l'intermédiaire du programme de configuration du système fourni avec votre distribution.
VI-I-4-c. Modification des paramètres du clavier▲
Il nous faut encore voir deux petits utilitaires permettant de fixer quelques paramètres du clavier pour finir notre tour d'horizon de ce périphérique. Le premier de ces outils permet de manipuler l'état des diodes lumineuses qui indiquent si le verrou numérique, le verrou des majuscules ou l'arrêt défilement sont actifs. Cet utilitaire se nomme logiquement setleds, et il permet non seulement de fixer l'état de ces diodes, mais également l'état du clavier. Rappelons en effet que les diodes peuvent être désynchronisées par rapport à l'état réel du clavier. Ce cas de figure peut se produire si l'on passe d'un terminal X à un terminal en mode console, tout simplement parce que les serveurs X ne savent pas comment déterminer l'état du clavier sur une console afin de le restaurer.
La syntaxe de setleds est la suivante :
setleds -D num | caps | scrolloù num, caps et scroll sont des options permettant de préciser respectivement l'état des verrous numériques, majuscules et défilement. Ces options sont de la forme +num, -num pour le verrou numérique, et de forme similaire pour les autres verrous. Comme leur syntaxe l'indique, elles permettent d'enclencher ou de désenclencher l'état des verrous correspondants du clavier.
L'état des verrous du clavier est conservé par chaque terminal virtuel, indépendamment les uns des autres. Cette commande devra donc être répétée pour tous les terminaux virtuels utilisés. L'option -D permet de rendre les changements permanents pour le terminal sélectionné. Ainsi, si ce terminal est réinitialisé, la modification sera conservée. C'est en général l'effet désiré. Sachez qu'il est également possible d'effectuer une modification temporaire, et de ne modifier que l'affichage des diodes (sans changer l'état des verrous).
Il est recommandé de placer les quelques lignes suivantes dans les fichiers d'initialisation de votre système afin d'activer le verrou numérique pour tous les terminaux, si votre distribution ne vous permet pas de le faire par l'intermédiaire de son programme de configuration :
INITTTY=`ls /dev/tty[1-9] /dev/tty1[0-2]`
for tty in $INITTTY; do
setleds -D +num < $tty
doneCes lignes appellent la commande setleds sur les terminaux virtuels 1 à 12.
Le deuxième utilitaire est kbdrate. Sa fonction est de fixer les paramètres de délai d'attente avant répétition lorsqu'on maintient une touche enfoncée, ainsi que la vitesse de répétition utilisée une fois que ce délai d'attente est dépassé. Sa syntaxe est elle aussi très simple :
kbdrate -s -r taux -d délaioù taux est le taux de répétition, et délai est le délai d'attente avant le début des répétitions de la touche enfoncée. L'option -s indique à kbdrate de ne pas afficher de messages pendant l'exécution de la commande. Les délais d'attente spécifiés peuvent être de 250, 500, 750 ou 1000 millisecondes. Les taux de répétition utilisables vont de 2 à 30 caractères par seconde. Toutefois, les claviers ne peuvent pas accepter toutes les valeurs intermédiaires pour le taux de répétition. Vous trouverez la liste exhaustive des valeurs admissibles dans la page de manuel kbdrate.
VI-I-5. Choix de la police de caractères▲
Par défaut, la police de caractères utilisée par Linux est la police enregistrée dans la carte graphique. Cette police convient pour l'affichage des textes anglais, car elle utilise la page de codes 437. Il est donc souhaitable, sinon recommandé, de changer de police de caractères à la fois pour bénéficier d'un encodage adapté à la langue française, et pour bénéficier d'améliorations esthétiques éventuelles.
Linux est fourni avec un certain nombre de fichiers de polices, qui sont normalement installées dans le répertoire /usr/lib/kbd/consolefonts. Comme vous pourrez le constater si vous y jetez un coup d'œil, ce répertoire contient un grand nombre de polices, utilisant divers encodages. Les polices les plus utiles pour un ordinateur situé en France sont sans doute les polices iso01*, lat1-* et lat0-*. Cette dernière police utilise l'encodage ISO 8859-15, et contient donc tous les symboles utilisés en Europe. Il est recommandé, mais non nécessaire, d'utiliser une des polices encodées en ISO 8859-1 ou en ISO 8859-15, avec un plan de clavier approprié. Par exemple, le plan de clavier fr-latin0.map.gz pourra être utilisé avec la police de caractères lat0-16.psfu.gz.
Les polices de caractères sont chargées aisément avec l'utilitaire setfont. La syntaxe de ce programme est très simple :
setfont policeoù police est le fichier de police à charger. Si vous ne spécifiez aucun fichier de police, la police par défaut sera chargée.
Notez que les fichiers de polices peuvent utiliser un encodage particulier spécifique, qui ne correspond à aucune des tables de conversion prédéfinies du noyau. Pour ces polices, il est nécessaire de spécifier des tables de conversion qui leur sont propres. Ces tables permettent de convertir les codes des caractères reçus par la console en codes Unicode spéciaux. Tous ces codes appartiennent à une plage de codes Unicode réservée au système, et que Linux utilise pour définir les codes qui permettront d'accéder directement aux caractères de la police. L'association entre les codes de caractères de l'application et leurs descriptions dans la police de caractères est donc réalisée grâce à ces tables de conversion.
Vous pouvez charger une table de conversion spécifique à l'aide de l'utilitaire mapscrn. Cet utilitaire prend en ligne de commande un fichier contenant la table de conversion, et charge cette dernière dans la quatrième table de conversion du noyau (c'est-à-dire la table réservée à l'utilisateur) :
mapscrn fichier(où fichier est le fichier contenant la description de la table de conversion).
Notez que l'utilitaire mapscrn charge la table de conversion, mais ne s'assure pas que le jeu de caractères courant utilise cette table. Par conséquent, vous aurez sans doute à utiliser les codes d'échappement \033(K et \033)K pour faire pointer respectivement les jeux de caractères G0 et G1 sur la quatrième table. Ces codes d'échappement peuvent être saisis à l'aide de la commande cat :
catIl vous faudra alors taper sur la touche Echap, puis saisir « (K » ou « )K », et enfin signaler la fin de fichier avec un CTRL + D. Faites bien attention à ce que vous faîtes : en cas d'erreur, le jeu de caractères utilisé peut rendre l'écran totalement illisible. Si cela devait se produire, vous devrez taper à l'aveugle la commande reset. Cette table s'assure que le jeu de caractères actif est le jeu de caractères G0, et que celui-ci utilise la première table de conversion. Vous pourrez également recharger la police par défaut à l'aide de setfont.
Heureusement, la plupart des polices de caractères contiennent également la table de conversion à utiliser, et setfont effectue tout le travaille en une seule passe. Il charge la police de caractères dans la carte graphique, puis sa table de conversion dans le noyau, et s'assure enfin que le jeu de caractères G0 soit actif et utilise cette table. Ainsi, l'utilisation de mapscrn est devenue facultative.
La dernière étape dans la configuration de la police de caractères est le chargement de la table de conversion Unicode vers les indices des caractères dans la police. Cette table est essentielle, puisque c'est elle qui indique l'emplacement des caractères de la police à utiliser pour chaque code Unicode. Ces tables dépendent donc de l'encodage utilisé par la police de caractères.
Le chargement des tables de conversion est réalisé par le programme loadunimap. La syntaxe de ce dernier est la même que celle de mapscrn :
loadunimap fichieroù fichier est un fichier de conversion approprié. Vous trouverez de tels fichiers dans le répertoire /usr/lib/kbd/consoletrans. Les fichiers proposés permettent d'utiliser les polices de caractères encodées selon les encodages les plus courants.
Bien entendu, certaines polices disposent de leur propre table d'encodage. Encore une fois, l'utilisation de loadunimap est rendue facultative par setfont, qui se charge d'effectuer tout le travail. C'est notamment le cas pour les polices fr-latin0.psfu.gz et fr-latin1.psfu.gz, dont le « u » en fin d'extension indique la présence de la table de conversion Unicode.
VI-I-6. Configuration des paramètres du terminal▲
La configuration du gestionnaire de la console ne concerne à proprement parler que les plans de clavier et les polices de caractères. Pour les applications, tout se passe comme si elles accédaient à un terminal comme les autres, donc par l'intermédiaire d'une ligne de communication. En général, les lignes de communication utilisées pour les terminaux sont des lignes série, c'est-à-dire des lignes sur lesquelles les données sont envoyées sous la forme de petits paquets de 5 à 8 bits, et contrôlées par d'autres bits éventuellement facultatifs (bit de stop et bit de parité). Il va de soi que tous les terminaux ne sont pas identiques, et qu'un certain nombre de paramètres doivent être définis tant au niveau des terminaux qu'au niveau des lignes de communication utilisées.
Ces paramètres peuvent être fixés avec la commande stty. Leur nombre interdit ici une description exhaustive, d'autant plus que pour un terminal local, ils sont tous initialisés à des valeurs par défaut correctes, et vous n'aurez pas à les modifier. Vous pouvez toutefois consulter la page de manuel de stty pour de plus amples renseignements à ce sujet.
Si vous êtes curieux, vous pourrez obtenir à tout moment la liste des paramètres de la ligne de communication d'un terminal avec l'option -a de stty :
stty -aComme vous pourrez le constater, le nombre des options utilisées est assez impressionnant. Sont définis, entre autres, les paramètres de vitesse de communication de la ligne (option speed), le format des données transférées sur la ligne (option parodd pour la parité impaire, option cs8 pour des paquets 8 bits, etc.), la géométrie du terminal (options rows et columns), les caractères de contrôle affectés à un certain nombre d'actions (comme, par exemple, le caractère « ^Z », accessible par la combinaison de touches CTRL + Z, qui permet de suspendre l'exécution du programme utilisant la ligne, et le caractère « ^C », qui permet de le tuer) et des options de gestion des caractères transférés (par exemple, echo fait en sorte que tout caractère entrant est immédiatement réémis sur la console, ce qui permet de voir ce que l'on tape).
Parmi ces paramètres, les plus intéressants sont sans doute ceux définissant les actions associées aux différentes touches de contrôle. Vous pourrez modifier ces paramètres avec la syntaxe suivante :
stty action caractèreoù action est l'une des actions gérées par stty, par exemple susp pour suspendre le processus en cours, intr pour le tuer, etc. Remarquez que l'action kill n'a rien à voir avec la gestion des signaux des processus. Elle permet simplement d'effacer la ligne courante du terminal.
VI-I-7. Description des terminaux▲
Le dernier maillon de la chaîne de gestion des caractères est bien entendu les applications. La plupart des applications sont capables de traiter les caractères simples comme les lettres de l'alphabet, les chiffres et la ponctuation. Cependant, il n'en va pas de même pour les codes d'échappement des terminaux. Comme nous l'avons vu, certaines touches sont programmées pour renvoyer des codes d'échappement dans le plan de clavier. Mais le gestionnaire de la console est également capable d'interpréter certains codes d'échappements, afin d'effectuer des actions spécifiques. Par exemple, les touches du curseur émettent des codes d'échappement spéciaux, et il est du ressort de chaque programme de reconnaître ces codes et d'agir en conséquence. De même, les programmes peuvent envoyer des codes d'échappement à la console pour déplacer le curseur affiché, effacer l'écran, effectuer un défilement, etc.
Le malheur, c'est que les codes d'échappement utilisables diffèrent selon les terminaux utilisés. Les terminaux les plus standards sont les terminaux VT100 et VT102 (la console Linux en fait partie). Cependant, les programmes ne peuvent pas savoir, a priori, quels codes d'échappement doivent être utilisés pour effectuer telle ou telle action.
C'est pour ces diverses raisons que les systèmes Unix disposent d'une base de données de définition des terminaux. Cette base de données contient tous les codes d'échappement que chaque type de terminal est capable de gérer, décrits d'une manière uniforme. Ainsi, les programmes désirant gérer correctement les terminaux n'ont qu'à consulter cette base de données pour interpréter et récupérer les codes d'échappement utilisés par le terminal. Historiquement, la définition des terminaux était réalisée dans le fichier de configuration /etc/termcap. Ce fichier est obsolète et a été remplacé par la base de données terminfo, que tous les programmes modernes doivent à présent utiliser. Cependant, le fichier de configuration /etc/termcap a été conservé par compatibilité avec les vieux programmes qui l'utilisent encore.
Le fichier termcap comprend une ligne pour chaque type de terminal décrit. Cette ligne est constituée d'un certain nombre de champs, séparés par le caractère ':'. Le premier champ de chaque ligne contient la description du terminal que cette ligne décrit. Les champs suivants sont des définitions des variables contenant les séquences d'échappement du terminal.
Les informations descriptives du terminal sont les suivantes :
- le nom abrégé du terminal ;
- le nom complet du terminal ;
- les autres noms sous lesquels le terminal est également connu ;
- la description détaillée du terminal (toujours en dernier).
Ces informations sont séparées les unes des autres par une barre verticale ('|').
Viennent ensuite les définitions des variables. Chaque variable est définie selon la syntaxe suivante :
variable=séquenceoù variable est le nom de la variable, et séquence est la séquence d'échappement associée à cette variable. Notez que certaines variables ne prennent pas de paramètres, et que leur présence dans la description du terminal signale simplement un comportement particulier de celui-ci. Notez également que pour les variables numériques, le caractère d'égalité est remplacé par un caractère dièse ('#').
Un certain nombre de variables peuvent être définies pour chaque terminal. Ce sont ces variables qui sont utilisées par les programmes pour retrouver les séquences d'échappement du terminal. Par conséquent, les noms de ces variables sont fixés une fois pour toutes, et elles représentent toujours la même fonctionnalité. La liste des fonctionnalités est, encore une fois, très grande, et les variables utilisables sont listées exhaustivement dans la page de manuel termcap.
Note : Il est évident que les lignes du fichier /etc/termcap peuvent devenir très longues. Il est donc possible de les étaler sur plusieurs lignes physiques, en insérant le caractère de continuation de ligne antislash ('\'). Après chaque retour à la ligne, il faut utiliser une indentation à l'aide du caractère de tabulation.
Vous trouverez ci-dessous un exemple de définition de terminal :
lx|linux|Console Linux:\
:do=^J:co#80:li#25:cl=\E[H\E[J:sf=\ED:sb=\EM:\
:le=^H:bs:am:cm=\E[%i%d;%dH:nd=\E[C:up=\E[A:\
:ce=\E[K:cd=\E[J:so=\E[7m:se=\E[27m:us=\E[36m:ue=\E[m:\
:md=\E[1m:mr=\E[7m:mb=\E[5m:me=\E[m:is=\E[1;25r\E[25;1H:\
:ll=\E[1;25r\E[25;1H:al=\E[L:dc=\E[P:dl=\E[M:\
:it#8:ku=\E[A:kd=\E[B:kr=\E[C:kl=\E[D:kb=^H:ti=\E[r\E[H:\
:ho=\E[H:kP=\E[5~:kN=\E[6~:kH=\E[4~:kh=\E[1~:kD=\E[3~:kI=\E[2~:\
:k1=\E[[A:k2=\E[[B:k3=\E[[C:k4=\E[[D:k5=\E[[E:k6=\E[17~:\
:k7=\E[18~:k8=\E[19~:k9=\E[20~:k0=\E[21~:K1=\E[1~:K2=\E[5~:\
:K4=\E[4~:K5=\E[6~:\
:pt:sr=\EM:vt#3:xn:km:bl=^G:vi=\E[?25l:ve=\E[?25h:vs=\E[?25h:\
:sc=\E7:rc=\E8:cs=\E[%i%d;%dr:\
:r1=\Ec:r2=\Ec:r3=\Ec:Cette ligne permet de définir le terminal associé à la console Linux. Vous pourrez par exemple reconnaître le nombre de colonnes et de lignes (variables co et li), ainsi que les codes d'échappement associés aux touches du curseur (variable ku, kd, kr et kl respectivement pour les touches haut, bas, droite et gauche). Par exemple, la variable cl donne la séquence d'échappement utilisable pour effacer l'écran et faire revenir le curseur en haut à gauche (séquence d'échappement « Esc [ H Esc [ J »). Comme il l'a déjà été dit plus haut, la liste complète des variables peut être obtenue en consultant la page de manuel termcap, et ce fichier ne sera pas décrit plus en détail ici.
La base de données terminfo a été introduite pour combler certaines limitations du fichier termcap. Si le principe de fonctionnement est presque le même, les informations fournies tiennent compte des terminaux plus récents et de nouvelles fonctionnalités. Cela signifie en pratique que de nouvelles variables ont été définies pour décrire les nouveaux terminaux. Inversement, certaines variables de termcap ont disparu parce qu'elles devenaient obsolètes, et ont été remplacées par des variables équivalentes de terminfo.
La principale différence entre terminfo et termcap est que la description des terminaux n'est plus stockée dans un fichier de configuration en mode texte. Toutes les données sont désormais stockées dans des fichiers binaires, qui peuvent être générés à l'aide du programme tic. Ces fichiers binaires sont usuellement placés dans les sous-répertoires du répertoire /usr/share/terminfo/. En fait, le nombre de fichiers de description est tellement grand qu'ils ont été regroupés par ordre alphabétique. Ainsi, le répertoire /usr/share/terminfo contient des sous-répertoires dont les noms sont les premières lettres des fichiers de description, et chaque fichier de description est situé dans le répertoire correspondant. Par exemple, le fichier de description des terminaux Linux se nomme tout simplement linux. Comme la première lettre de son nom est 'l', il est stocké dans le répertoire /usr/share/terminfo/l/, avec les descriptions de tous les autres terminaux dont le nom commence par 'l'.
Note : En fait, les fichiers de description de terminaux peuvent être placés à un autre emplacement que l'emplacement par défaut. Les bibliothèques de programmes utilisant les informations de terminfo cherchent en effet en premier dans le chemin référencé par la variable d'environnement TERMINFO, puis dans le répertoire .terminfo du répertoire de l'utilisateur. Ce n'est que si ces deux recherches échouent qu'elles utilisent les informations du répertoire par défaut.
Comme nous l'avons dit, les fichiers de description sont des fichiers binaires, qui ont été compilés à l'aide du compilateur tic. Cependant, vous pouvez parfaitement visualiser le contenu de ces fichiers ou comparer deux fichiers à l'aide de l'utilitaire infocmp. Par exemple, vous pouvez visualiser sous une forme lisible les informations du fichier de description des terminaux Linux avec la commande suivante :
infocmp linuxVous obtiendrez certainement un résultat semblable à ceci :
#Reconstructed via infocmp from file: /usr/lib/terminfo/l/linux
linux|linux console,
am, bce, eo, mir, msgr, xenl, xon,
colors#8, it#8, pairs#64,
acsc=+\020\,\021-\030.^Y0\333`\004a\261f\370g\361h\260i\316j\\
331k\277l\32m\300n\305o~p\304q\304r\304s_t\303u\264v\301w\302x\263y\\
363z\362{\343|\330}\234~\376,
bel=^G, blink=\E[5m, bold=\E[1m, civis=\E[?25l,
clear=\E[H\E[J, cnorm=\E[?25h, cr=^M,
csr=\E[%i%p1%d;%p2%dr, cub1=^H, cud1=^J, cuf1=\E[C,
cup=\E[%i%p1%d;%p2%dH, cuu1=\E[A, cvvis=\E[?25h,
dch=\E[%p1%dP, dch1=\E[P, dim=\E[2m, dl=\E[%p1%dM,
dl1=\E[M, ech=\E[%p1%dX, ed=\E[J, el=\E[K, el1=\E[1K,
flash=\E[?5h\E[?5l$<200/>, home=\E[H, hpa=\E[%i%p1%dG,
ht=^I, hts=\EH, ich=\E[%p1%d@, ich1=\E[@, il=\E[%p1%dL,
il1=\E[L, ind=^J, invis=\E[8m, kb2=\E[G, kbs=\177, kcbt=\E[Z,
kcub1=\E[D, kcud1=\E[B, kcuf1=\E[C, kcuu1=\E[A,
kdch1=\E[3~, kend=\E[4~, kf1=\E[[A, kf10=\E[21~,
kf11=\E[23~, kf12=\E[24~, kf13=\E[25~, kf14=\E[26~,
kf15=\E[28~, kf16=\E[29~, kf17=\E[31~, kf18=\E[32~,
kf19=\E[33~, kf2=\E[[B, kf20=\E[34~, kf3=\E[[C, kf4=\E[[D,
kf5=\E[[E, kf6=\E[17~, kf7=\E[18~, kf8=\E[19~, kf9=\E[20~,
khome=\E[1~, kich1=\E[2~, knp=\E[6~, kpp=\E[5~, kspd=^Z,
nel=^M^J, op=\E[39;49m, rc=\E8, rev=\E[7m, ri=\EM,
rmacs=\E[10m, rmir=\E[4l, rmpch=\E[10m, rmso=\E[27m,
rmul=\E[24m, rs1=\Ec, sc=\E7, setab=\E[4%p1%dm,
setaf=\E[3%p1%dm,
sgr=\E[0;10%?%p1%t;7%;%?%p2%t;4%;%?%p3%t;7%;%?%p4%t;5%;\
%?%p5%t;2%;%?%p6%t;1%;%?%p7%t;8%;%?%p9%t;11%;m,
sgr0=\E[m, smacs=\E[11m, smir=\E[4h, smpch=\E[11m,
smso=\E[7m, smul=\E[4m, tbc=\E[3g, u6=\E[%i%d;%dR,
u7=\E[6n, u8=\E[?6c, u9=\E[c, vpa=\E[%i%p1?,Comme vous pouvez le constater, le format de ces informations est similaire à celui de celles qui sont enregistrées dans le fichier /etc/termcap. Les principales différences sont que les différents champs sont séparés par des virgules (',') au lieu du caractère deux points (':'), et qu'il est possible de les répartir sur plusieurs lignes physiques (il est donc inutile d'utiliser le caractère antislash en fin de ligne physique pour indiquer la continuation de la ligne logique). De plus, le nom des variables utilisées dans les fichiers terminfo n'est pas le même a priori. Cependant, le principe d'utilisation de ces variables reste le même, chacune d'entre elles permet de définir une des fonctionnalités gérées par le terminal et de définir la séquence d'échappement nécessaire à l'obtention de cette fonctionnalité si nécessaire. Vous pourrez trouver la liste exhaustive des variables utilisables dans la page de manuel terminfo. Le format des fichiers de configuration de terminfo ne sera donc pas décrit plus en détail dans ce document.
Qu'ils utilisent des bibliothèques basées sur termcap ou terminfo, les programmes doivent tous connaître le nom du terminal courant pour récupérer les informations qui permettent de l'utiliser dans ces bases de données. C'est précisément ce à quoi sert la variable d'environnement TERM. Cette variable contient en permanence le nom du terminal courant, que les programmes peuvent utiliser comme index dans les bases de données termcap ou terminfo. Ainsi, si vous désirez travailler sur un terminal Linux, vous pourrez fixer le type de terminal correct avec la commande suivante :
export TERM=linuxLa liste des noms de terminaux utilisables peut être obtenue en lisant directement le fichier termcap. Cette liste peut être obtenue plus facilement pour terminfo, à l'aide de l'utilitaire toe (abréviation de l'anglais « Table Of terminfo Entry »).
Bien entendu, vous n'aurez à définir la valeur de TERM que si cette variable d'environnement n'est pas correctement définie, ce qui est très rare. En fait, cela ne peut se produire que lors d'une connexion à distance sur un autre ordinateur, dont les terminaux ne sont pas de type Linux.
VI-I-8. Paramétrage des applications▲
En théorie, la description du terminal courant fournie par les bases de données termcap ou terminfo est suffisante pour faire fonctionner correctement la plupart des applications. En particulier, les programmes qui utilisent les bibliothèques de fonctions de manipulation des terminaux sont capables d'utiliser ces informations. C'est le cas par exemple de tous les programmes qui utilisent les bibliothèques « curses » ou « ncurses », car celles-ci s'appuient sur la base de données terminfo.
Cependant, certaines applications utilisent un mécanisme plus simple (mais moins souple) pour gérer les terminaux. Pour ces applications, une configuration spécifique doit être effectuée, souvent pour chaque terminal, en précisant les codes d'échappement à utiliser dans leurs fichiers de configuration. On remarquera la présence du shell « bash », de l'éditeur « vi » et du programme de pagination « less » dans cette catégorie de logiciels. Comme ce sont les logiciels les plus couramment utilisés, il est indispensable d'indiquer comment les configurer pour une utilisation correcte.
VI-I-8-a. Configuration du clavier pour la bibliothèque readline▲
Un certain nombre d'applications, dont le shell « bash », utilisent la libraire GNU « readline » pour obtenir les lignes de commandes saisies par l'utilisateur. Tous ces programmes peuvent donc être configurés de la même manière, grâce au fichier de configuration de la bibliothèque readline.
Cette bibliothèque recherche son fichier de configuration en premier à l'emplacement indiqué par la variable d'environnement INPUTRC. Si cette variable d'environnement n'est pas définie, le fichier de configuration ~/.inputrc est lu pour déterminer les séquences d'échappement à utiliser. Il est donc recommandé de créer un fichier de configuration général /etc/inputrc et de définir la variable d'environnement INPUTRC afin de définir des paramètres communs à tous les utilisateurs. Vous pouvez également recopier ce fichier dans les répertoires personnels de tous les utilisateurs sous le nom .inputrc.
Ainsi, si vous voulez gérer correctement le clavier français sous le shell bash, vous devrez vous assurer que les lignes suivantes sont placées dans votre fichier inputrc :
# Active la gestion du huitième bit des caractères
# (par exemple pour les caractères accentués) :
set meta-flag on
set input-meta on
set output-meta on
set convert-meta off
# Définit les codes d'échappement associés aux touches du curseur :
"\e[1~": beginning-of-line
"\e[4~": end-of-line
"\e[2~": overwrite-mode
"\e[3~": delete-char
"\e[5~": history-search-backward
"\e[6~": history-search-forward
"\e[C": forward-char
"\e[D": backward-char
"\e[A": previous-history
"\e[B": next-history
# Redéfinit les codes d'échappement pour l'émulateur de terminal xterm :
$if term=xterm
"\e[H": beginning-of-line
"\e[F": end-of-line
$endifCe fichier commence par autoriser le traitement des caractères dont le bit « meta », c'est-à-dire le huitième bit, est positionné. C'est en particulier le cas de tous les caractères accentués dans les principales pages de codes ; ces options sont donc nécessaires pour pouvoir utiliser ces caractères dans le shell. La suite du fichier définit les actions associées à chaque code d'échappement du terminal. Le caractère d'échappement est représenté ici par la chaîne de caractères « \e ». Comme les codes d'échappement sont différents pour la console et pour les émulateurs de terminaux de XWindow, il est nécessaire de les redéfinir en fonction de la nature du terminal. Ce fichier présente un exemple d'expression conditionnelle sur le nom du terminal, tel qu'indiqué dans la variable d'environnement TERM, afin de ne redéfinir ces codes que pour ces terminaux.
VI-I-8-b. Configuration du clavier pour vi▲
L'éditeur en ligne de commande vi n'est pas réputé pour être agréable à utiliser. Cela provient essentiellement de sa distinction entre les modes de commande, d'édition et de visualisation. Mais cela n'est pas suffisant pour le rendre haïssable : la torture psychologique imposée par la mauvaise gestion du curseur vient souvent à bout des plus résistants. Heureusement, Linux fournit un clone nettement plus puissant et qui permet de résoudre ces problèmes : vim.
L'éditeur vim peut bien entendu être parfaitement compatible avec vi afin ne pas dérouter les habitués de vi. Mais il dispose en plus de fonctionnalités avancées qui en font un outil extrêmement configurable, et il est possible de le rendre nettement plus ergonomique que son ancêtre. Malheureusement, il faut reconnaître que la plupart des distributions fournissent un vim « brut de fonderie », ce qui fait que seuls ceux qui se lancent dans la lecture de son aide peuvent parvenir à l'utiliser correctement. Les options qui sont proposées ici sont donc données simplement à titre indicatif, mais permettront peut-être de rendre vim un peu plus ergonomique.
Les options de configuration de vim sont stockées dans deux fichiers. Le premier fichier est le fichier de configuration commun à tous les utilisateurs, vimrc. Ce fichier peut être placé soit dans le répertoire /etc/, soit dans le répertoire /usr/share/vim/, selon votre distribution. Le deuxième fichier est le fichier de préférences personnelles de chaque utilisateur, et se nomme .vimrc. Il est normalement placé dans le répertoire personnel de l'utilisateur.
Plusieurs types d'options peuvent être indiquées dans ces fichiers de configuration. Les premières associent les actions à effectuer aux codes d'échappement générés par les touches du curseur. Les autres spécifient simplement le comportement de l'éditeur et le paramétrage de ses principales fonctionnalités. Vous trouverez ci-dessous les principales options que vous pourrez ajouter à votre fichier de configuration vimrc. Ces options rendront sans doute l'utilisation de vim beaucoup plus agréable.
" Exemple d'options de configuration pour vim.
" Notez que les commentaires sont introduits ici
" par des guillemets anglais (") et non
" par des dièses ('#'), contrairement aux fichiers de configuration
" de la plupart des autres applications.
" Éviter à tout pris la compatibilité avec vi, qui est insupportable :
set nocompatible
" Définir les touches du clavier :
" Gestion du curseur en mode de visualisation :
map ^[OA k
map ^[[A k
map ^[OB j
map ^[[B j
map ^[OD h
map ^[[D h
map ^? h
map ^H h
map ^[OC l
map ^[[C l
map ^[[2~ i
map ^[[3~ x
map ^[[1~ 0
map ^[OH 0
map ^[[H 0
map ^[[4~ $
map ^[OF $
map ^[[F $
map ^[[5~ ^B
map ^[[6~ ^F
map ^[[E ""
map ^[[G ""
map ^[OE ""
" Gestion du pavé numérique en mode de visualisation :
map ^[Oo :
map ^[Oj *
map ^[Om -
map ^[Ok +
map ^[Ol +
map ^[OM ^M
map ^[Ow 7
map ^[Ox 8
map ^[Oy 9
map ^[Ot 4
map ^[Ou 5
map ^[Ov 6
map ^[Oq 1
map ^[Or 2
map ^[Os 3
map ^[Op 0
map ^[On .
" Gestion du pavé numérique en mode insertion :
map! ^[Oo :
map! ^[Oj *
map! ^[Om -
map! ^[Ok +
map! ^[Ol +
map! ^[OM ^M
map! ^[Ow 7
map! ^[Ox 8
map! ^[Oy 9
map! ^[Ot 4
map! ^[Ou 5
map! ^[Ov 6
map! ^[Oq 1
map! ^[Or 2
map! ^[Os 3
map! ^[Op 0
map! ^[On .
" Gestion du curseur dans les modes d'insertion et de commande :
map! ^[[H <Home>
map! ^[OH <Home>
map! ^[[F <End>
map! ^[OF <End>
map! ^[OA <Up>
map! ^[OB <Down>
map! ^[OC <Right>
map! ^[OD <Left>
map! ^[[3~ <Delete>
map! ^[OE <Space>
" Définir les autres options globales :
" Paramétrage des touches Backspace et Delete :
set t_kb=^?
set t_kD=ESC[3~
" Faire en sorte que le "backspace" efface même les sauts de lignes :
set bs=2
" Utiliser l'indentation automatique dans les fichiers C et C++
" (pour les programmeurs) :
set cindent
" Utiliser la coloration syntaxique pour les principaux langages
" de programmation :
set background=dark
if &t_Co > 1
syntax on
endif
" Signaler les correspondances de parenthèses, accolades et crochets :
set showmatch
" Rappeler le mode de fonctionnement courant :
set showmodeVous constaterez que certains caractères de contrôle sont utilisés dans ce fichier de configuration, dont le caractère de contrôle « ^[ », qui représente le caractère d'échappement. Ces caractères sont représentés avec la notation classique « ^C », où « C » est la lettre à utiliser avec la touche CTRL pour obtenir ce caractère. Ces notations ne font que représenter les caractères de contrôle, et doivent être remplacées par les caractères qu'elles représentent dans le fichier de configuration. Pour saisir ces caractères spéciaux, vous devrez passer en mode insertion dans vi, puis utiliser la combinaison de touches CTRL+V. Ce raccourci permet d'indiquer à vi qu'il doit insérer les codes d'échappement directement issus du clavier, sans les interpréter. Vous pourrez alors taper la séquence de touches générant le caractère de contrôle ou la séquence d'échappement désirée. Par exemple, vous pourrez obtenir le caractère « ^H » en tapant la combinaison de touches CTRL+H, et le caractère « ^? » en appuyant sur la touche Backspace (retour arrière). Les caractères d'échappement peuvent être générés par la touche Echap ou directement par les touches du curseur.
Note : En fait, vous pouvez également utiliser les chaînes de caractères « \e » et « <Esc> » pour représenter le caractère d'échappement. Mais certaines options ne fonctionnent pas avec ces notations, et je vous les déconseille.
Vous pouvez bien entendu ajouter d'autres options dans ce fichier de configuration. En pratique, toutes les options utilisables dans le mode de commande de vim peuvent être fixées définitivement dans ce fichier. Vous obtiendrez de l'aide sur ces options grâce à la commande « :help » de vim.
VI-I-8-c. Configuration du clavier pour less▲
Le programme de pagination less est naturellement bien plus agréable à utiliser que son ancêtre more, puisqu'il permet de revenir sur les pages déjà consultées. Cependant, il peut le devenir encore plus si l'on s'arrange pour qu'il reconnaisse les touches du curseur.
Le programme less lit ses informations de configuration dans un fichier binaire dont l'emplacement est spécifié par la variable d'environnement LESSKEY. Si cette variable d'environnement n'est pas définie, less utilise le fichier de configuration .less du répertoire personnel de l'utilisateur. Ce fichier binaire contient les associations entre les séquences d'échappement du terminal et les actions effectuées par less. Il est généré par le compilateur lesskey, à partir d'un fichier de configuration textuelle classique.
Ce fichier de configuration comprend plusieurs sections, qui permettent de définir les touches utilisées en mode de commande, les touches utilisées en mode d'édition de lignes (par exemple dans une commande de recherche), et enfin les variables d'environnement utilisées par less. Vous trouverez ci-dessous un exemple de fichier de configuration pour less. Vous trouverez de plus amples renseignements sur les actions qui peuvent être associées aux séquences d'échappement et aux caractères de contrôle dans la page de manuel lesskey.
# Exemple de fichier de configuration pour less
# Première section :
#command
\e[B forw-line
\e[A back-line
\e[6~ forw-scroll
\e[5~ back-scroll
\177 back-screen
^H back-screen
\e[3~ back-screen
\e[2~ visual
\e[1~ goto-line
\eOH goto-line
\e[4~ goto-end
\eOF goto-end
\eOM forw-line
# Deuxième section :
#line-edit
\177 backspace
^H backspace
\e[3~ delete
\e[1~ home
\e[H~ home
\eOH home
\e[4~ end
\e[F~ end
\eOF end
\e[5~ up
\e[6~ down
\e[2~ insert
\e[E insert
\e[G insert
\eOE insert
\eOo insert :
\eOj insert *
\eOm insert -
\eOk insert +
\eOl insert +
\eOM insert
\eOw insert 7
\eOx insert 8
\eOy insert 9
\eOt insert 4
\eOu insert 5
\eOv insert 6
\eOq insert 1
\eOr insert 2
\eOs insert 3
\eOp insert 0
\eOn insert .
# Troisième section :
#env
LESSCHARSET=latin1Conformément à un usage courant, les commentaires sont introduits par le caractère dièse ('#') dans ce fichier de configuration. Cependant, certains commentaires sont utilisés pour identifier le début des trois sections du fichier. Il s'agit des commentaires « #command », « #line-edit » et « #env ». Il ne faut donc surtout pas supprimer ces commentaires dans votre fichier de configuration.
Encore une fois, le caractère d'échappement est symbolisé par la chaîne de caractère « \e ». De même, les caractères de contrôle sont représentés par la notation classique « ^C », où C est la touche utilisée en combinaison avec CTRL pour générer ce caractère de contrôle. Notez que, contrairement au fichier de configuration /etc/vimrc, ces notations peuvent être utilisées directement dans le fichier de configuration de less.
Ce fichier de configuration pourra être compilé avec le programme lesskey afin de générer le fichier binaire utilisé par less. Pour cela, il faudra simplement utiliser la syntaxe suivante :
lesskey fichieroù fichier est le nom du fichier de configuration à compiler. Le fichier binaire généré est par défaut celui référencé par la variable d'environnement LESSKEY. Si cette variable n'est pas définie, un fichier .less sera créé dans le répertoire personnel de l'utilisateur.
VI-I-9. Configuration de la souris▲
L'installation de la souris est une opération très simple à réaliser. La seule chose importante est de bien connaître les différents types de souris et de ne pas les confondre. Autrefois, la plupart des souris étaient des souris connectées sur le port série (souris sérielles). Aujourd'hui, ces souris se font de plus en plus rares, et le port de prédilection est le port PS/2. Ce port a été introduit par IBM dans ses ordinateurs PS/2 et est quelque peu plus pratique que le port série, car il définit une interface standard pour toutes les souris. De plus, il permet de dégager un des ports série, ce qui simplifie la configuration des modems. Le port PS/2 ressemble au port clavier du même type, et en fait on peut se tromper et brancher la souris à la place du clavier et inversement. Il ne faut surtout pas confondre les souris PS/2 avec les souris Bus, qui ont été vendues autrefois et que l'on ne trouve quasiment plus à présent. Ces souris pouvaient se connecter sur des cartes spéciales voire, parfois, sur la carte graphique.
Pour que l'installation de la souris se fasse correctement, il faut s'assurer que les options concernant la souris ont bien été définies dans la configuration du noyau de Linux. Cela n'est pas nécessaire pour les souris série. Vous pouvez consulter la Section 7.3 pour plus de détails sur la configuration du noyau. Lorsque cette étape est faite, il ne reste plus qu'à indiquer au programme de gestion de la souris à quel type de souris il a affaire. Ce programme, nommé gpm, permet d'utiliser la souris en mode texte. La configuration de la souris pour XWindow sera vue dans le Chapitre 10.
La configuration de gpm se fait normalement par l'intermédiaire du programme de configuration de votre distribution. Lorsqu'on n'utilise pas XWindow, gpm est lancé automatiquement au démarrage. Il se peut que votre programme de configuration vous demande le type de souris à utiliser. Dans ce cas, il faut choisir le bon type, faute de quoi gpm ne fonctionnera pas correctement. Attention, si vous désirez utiliser une souris à molette (souris disposant d'une petite roue entre les deux boutons, et permettant de faire défiler le contenu des fenêtres), le type de souris à utiliser est « imps2 » et non simplement « ps2 ». Pour avoir la liste des types de souris gérés par gpm, il suffit de le lui demander avec la ligne de commande suivante :
gpm -t helpNormalement, vous aurez à utiliser gpm avec la ligne de commande suivante :
gpm -t type -m /dev/mouseoù type est le type de la souris que gpm doit utiliser et /dev/mouse est un lien vers le fichier spécial de périphérique gérant votre souris.
VI-J. Configuration de l'imprimante▲
Il existe deux systèmes d'impression concurrents sous Linux : LPRng (« Line Printer Next Generation ») et CUPS (« Common Unix Printing System »). LPRng est une évolution du système initial, LPR, qui est devenu très vite obsolète en raison de l'évolution des technologies d'impression. En effet, celui-ci a été conçu à l'époque où les imprimantes étaient encore des imprimantes matricielles et ne pouvaient imprimer qu'en noir et blanc. CUPS, quant à lui, a été créé pour fournir une infrastructure complètement nouvelle et pour s'affranchir des limitations de LPRng. C'est donc la solution d'avenir, mais il n'est pas rare de trouver encore des systèmes basés sur LPRng. D'autre part, la compatibilité au niveau des commandes d'impression est assurée par CUPS, ce qui fait que la présentation de LPRng n'est pas superflue.
Quelle que soit la technologie d'impression utilisée, l'imprimante reste généralement accessible par un port local. En effet, la plupart des imprimantes sont connectées sur le port parallèle ou sur un port USB (les imprimantes professionnelles mises à part, celles-ci disposant généralement d'une interface réseau). Nous supposerons donc dans la suite de ce document que l'imprimante est connectée soit sur le port parallèle (accessible via le fichier spécial de périphérique /dev/lp0), soit sur un port USB (accessible via le fichier /dev/usb/lp0).
VI-J-1. Concepts de base de l'impression sous Unix▲
La principale difficulté lors de l'impression d'un document est de le convertir de son propre format de fichier vers un format de données que l'imprimante est capable de comprendre. Le problème ici est qu'il existe une multitude de formats de documents et une multitude d'applications qui peuvent les générer, d'une part, et, d'autre part, que chaque fabricant d'imprimantes a développé ses propres jeux de commandes pour ses imprimantes. Il existe bien un standard pour les imprimantes laser avec le langage PostScript développé par Adobe, mais ce langage n'est pas utilisable avec la majorité des imprimantes à jet d'encre. De fait, la plupart des applications sont capables de générer un fichier PostScript lors d'une impression, mais ce fichier doit encore être traduit dans le langage spécifique de l'imprimante effectivement installée.
Il est donc toujours possible d'envoyer directement un fichier à imprimer à l'imprimante, en le recopiant directement sur le fichier spécial de périphérique de l'imprimante, mais cette technique suppose que ce fichier soit généré directement dans le langage de l'imprimante. Ceci ne peut que compliquer les applications qui permettent l'impression, et les empêcher de fonctionner ultérieurement avec de nouvelles imprimantes dont le langage leur sera inconnu. Cette technique ne convient donc, en général, que pour des fichiers textes simples. De plus, cette solution ne convient pas dans un système multitâche et multiutilisateur, puisqu’un seul programme seulement peut accéder à l'imprimante à un instant donné.
Les systèmes d'impression ont donc pour principal but de résoudre ces problèmes. La multiplicité des formats de fichiers et des langages d'imprimante est prise en charge par tout un jeu de programmes de conversion que l'on appelle les filtres. Les filtres ne sont en fait rien d'autre que des programmes qui reçoivent un fichier en entrée et qui fournissent la traduction de ce fichier dans un autre format en sortie. Les systèmes d'impression LPRNG et CUPS fournissent un certain nombre de filtres, qui peuvent être agencés afin de permettre l'impression de n'importe quel fichier sur l'importe quelle imprimante.
Enfin, en ce qui concerne le partage des ressources d'impression, les systèmes d'impression utilisent généralement un mécanisme de files d'attente (« spool » en anglais). Tous les travaux d'impression soumis sont placés dans une file d'attente, et attendent leur tour pour être envoyés à l'imprimante associée à cette file. Une fois que l'impression est terminée, les travaux sont supprimés de la file. Ainsi, un seul programme accède à l'imprimante : le sous-système d'impression. Notez qu'il est généralement possible de définir plusieurs files d'attente sur une même imprimante, selon la nature du travail à effectuer. Par exemple, une file peut se charger des documents textes, et une autre des documents graphiques en couleur. Bien entendu, le sous-système d'impression contrôle tous les accès à l'imprimante et assure qu'un seul document est en cours d'impression à chaque instant.
VI-J-2. Le système d'impression LPRng▲
Le système d'impression LPRng est constitué d'un démon nommé « lpd » et d'un jeu de commandes permettant de communiquer avec lui pour soumettre les travaux d'impression, visualiser ceux qui sont en attente ou en cours d'impression et les annuler.
VI-J-2-a. Le mécanisme des filtres APSFILTER▲
Sous Linux, le mécanisme de filtres de LPRng est généralement APSFILTER. Ce mécanisme est profondément orienté vers le langage de description de pages PostScript, initialement inventé par Adobe et que nombre d'imprimantes laser comprennent. En fait, il s'agit d'un véritable langage de programmation, qui permet de programmer les périphériques dont la vocation est d'afficher ou d'imprimer des documents. Techniquement parlant, PostScript permet d'obtenir une qualité d'impression irréprochable, car c'est l'imprimante elle-même qui « dessine » la page à imprimer.
APSFILTER utilise donc un premier jeu de filtres pour convertir les fichiers à imprimer en PostScript s'ils ne sont pas déjà dans ce format. Le langage PostScript apparaît donc comme le langage d'impression universel, que toutes les imprimantes sont supposées comprendre…
Le problème, c'est que ce n'est pas le cas. En particulier, les imprimantes à jet d'encre ne comprennent généralement pas le PostScript. Aussi APSFILTER utilise-t-il un second jeu de filtres, capables de convertir le PostScript dans le langage graphique de l'imprimante (si l'imprimante n'est pas une imprimante PostScript, bien entendu). APSFILTER utilise pour cela un « interpréteur PostScript ». Un interpréteur PostScript est un programme capable de comprendre les fichiers PostScript et de les convertir dans le format compris par l'imprimante. L'interpréteur couramment utilisé sous Linux est GhostScript, parce que c'est un logiciel libre (cependant, la version courante est toujours commerciale). Il est également capable d'afficher les fichiers PostScript sous XWindow, et de gérer la plupart des imprimantes du marché.
L'avantage de cette technique est que toutes les imprimantes apparaissent comme étant des imprimantes PostScript pour les programmes désirant imprimer. Ainsi, leur programmation est beaucoup plus simple, puisqu'ils n'ont qu'un seul format à gérer. Bon nombre d'applications génèrent directement des fichiers PostScript, qui sont donc envoyés directement à GhostScript pour l'impression définitive.
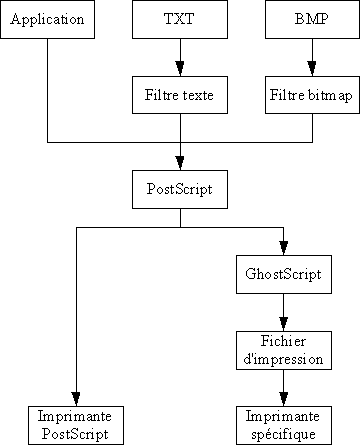
Comme on le voit, avec APSFILTER, le langage d'impression universel est le langage PostScript. Bien entendu, cela est idéal si l'on dispose effectivement d'une imprimante PostScript, mais même dans le cas contraire, les impressions se font parfaitement grâce à GhostScript.
VI-J-2-b. Installation des filtres et configuration des files d'impression▲
Les distributions modernes fournissent toutes un outil permettant d'effectuer la configuration du sous-système d'impression. Il est évidemment recommandé d'utiliser ces outils, car le résultat est assuré et la vie en est d'autant plus facile. De plus, les distributions peuvent fournir des filtres complémentaires que seuls ces outils connaissent et sont capables d'installer.
Si le jeu de filtres utilisé de votre distribution est APSFILTER, vous pourrez installer votre imprimante manuellement en exécutant le programme SETUP du répertoire /usr/share/apsfilter/.
Ce programme est réellement affreux à utiliser, car il s'agit en réalité d'un script, mais il effectue correctement son travail. Dès son démarrage, il vous demande d'accepter la licence logicielle (la licence GPL avec une forte invitation à envoyer une carte postale à l'auteur, qui les collectionne). La question suivante est donc si vous désirez obtenir l'adresse postale de l'auteur. Une fois ces deux questions passées, le programme d'installation commence réellement.
Le programme vous demande de confirmer les droits sur le répertoire des fichiers d'impression en cours, puis, si vous le faites effectivement, si vous désirez compléter le fichier de configuration de LPRNG /etc/printcap ou en créer un complètement nouveau. Vient ensuite le menu de configuration des imprimantes :
La première option vous permet de choisir le pilote de l'imprimante, qui donc en général est un des pilotes fournis avec l'interpréteur GhostScript. Vous devez sélectionner le pilote de votre imprimante ou, à défaut, celui de l'imprimante qui s'en rapproche le plus. La deuxième option vous permet de sélectionner l'interface de l'imprimante. Vous pourrez indiquer le port de l'imprimante ou, s'il s'agit d'une imprimante réseau, la manière d'y accéder. Les autres options du menu quant à elles sont relativement simples, et vous permettront respectivement de sélectionner le format du papier, la qualité et le mode d'impression, ainsi que la résolution de l'imprimante.
Vous pourrez (et devriez) tester la configuration ainsi définie avec l'option 'T'. Si le résultat vous convient, installez l'imprimante avec l'option 'I'. Vous pouvez installer plusieurs imprimantes ou plusieurs files d'impression pour la même imprimante en répétant les étapes précédentes. Finalement, terminez l'installation avec l'option 'Q', et envoyez une carte postale à l'auteur du logiciel.
VI-J-2-c. Commandes d'impression▲
La commande d'impression de LPRng est la classique commande lpr (abréviation de l'anglais « off Line PRint », ce qui signifie « impression différée »). Cette commande est très simple à utiliser, comme le montre la syntaxe suivante :
lpr fichieroù fichier est le nom du fichier à imprimer. Cette commande se contente de placer le fichier à imprimer dans un répertoire affecté à la file d'attente des travaux d'impression. Le travail d'impression est ensuite effectué par le démon lpd, qui fait passer chaque fichier à imprimer à travers la série de filtres pour le convertir dans le langage de l'imprimante, puis qui alimente l'imprimante.
La liste des travaux d'impression en attente peut être consultée avec la commande lpq. Chaque travail en attente porte un numéro, grâce auquel on peut le manipuler. Entre autres opérations, il est possible de l'abandonner à l'aide de la commande lprm.
Enfin, pour consulter et contrôler l'état des files d'impression, on peut utiliser la commande lpc. Cette commande peut prendre des options en ligne de commande afin de préciser l'opération à effectuer. Par exemple, l'option status permet d'obtenir l'état de chacune des files d'impression. Les autres options permettent d'arrêter le travail en cours, de le suspendre, de désactiver l'imprimante pour les travaux suivants, et inversement de relancer les travaux d'impression sur cette file.
VI-J-2-d. Description du fichier /etc/printcap▲
Le démon lpd utilise le fichier de configuration /etc/printcap pour déterminer l'ensemble des files d'impression existantes et quels filtres doivent être utilisés. Ce fichier est généré automatiquement par les utilitaires des distributions ou, à défaut, par le script d'installation d'APSFILTER. Toutefois, comme il est bon de savoir ce qui se passe lorsqu'une commande d'impression est envoyée au démon lpd, une brève description de ce fichier sera faite dans cette section.
Chaque file est décrite par une ligne du fichier /etc/printcap et une seule. Ces lignes sont constituées de divers champs, séparés par des deux-points (':'). Comme ces lignes peuvent être relativement longues, elles peuvent être réparties sur plusieurs lignes physiques en plaçant le caractère d'échappement '\' à la fin de chaque ligne, sauf la dernière.
Le premier champ de la description d'une file d'attente est une liste des noms sous lesquels cette file sera connue. Les différents noms sont écrits les uns à la suite des autres, séparés par une barre verticale (caractère '|').
Les champs suivants décrivent l'imprimante à utiliser, ainsi que les options générales de la file d'attente. Ces champs utilisent tous la même syntaxe :
option = valeurIl existe un grand nombre d'options, nombre d'entre elles sont facultatives. Cependant, il est impératif que le démon lpd puisse trouver l'imprimante à utiliser. Par conséquent, il faut lui fournir au moins l'une des deux options suivantes :
- l'option lp permet de spécifier le fichier spécial de périphérique auquel l'imprimante est connectée ;
- les options rm et rp permettent de spécifier respectivement le nom d'un serveur d'impression distant (« remote » en anglais) et de l'imprimante à utiliser sur ce serveur (« remote printer »).
Le démon lpd doit également connaître le répertoire dans lequel les travaux en attente seront stockés (répertoire dit de « spool »). Ce répertoire peut être défini avec l'option sd.
D'autres options peuvent être utiles, comme sh (cette option ne prend pas de valeur), qui permet de supprimer la page de garde au début de chaque impression, et mx, qui permet de spécifier la taille maximale des travaux d'impression soumis. Cette dernière option permet de fixer des quotas d'impression selon la taille des documents, afin de donner la possibilité aux autres documents d'être imprimés. Cette option utilise une syntaxe particulière :
mx#tailleoù taille est la taille maximale autorisée, exprimée en kilo-octets. Le fait de spécifier une taille nulle permet de supprimer ce contrôle.
L'exemple ci-dessous correspond à la définition d'une file d'attente locale élémentaire :
ascii|lp:lp=/dev/lp:sd=/var/spool/lpd/ascii:mx#0:shComme vous pouvez le constater, il n'y a aucune spécification des filtres d'impression à utiliser dans cet exemple. Les travaux sont donc directement envoyés à l'impression, sans traduction préalable. Il est donc nécessaire qu'ils soient déjà au format de l'imprimante. Si l'on veut utiliser des filtres d'impression, il faut utiliser l'une des options if, cf, df, gf, nf, rf, tf ou vf. Chacune de ces options permet de spécifier la ligne de commande d'un filtre d'impression spécifique. Le choix du filtre utilisé pour un travail d'impression est effectué lors de l'appel à la commande lpr, à l'aide d'une option en ligne de commande. Le filtre if est le filtre par défaut, il n'y a donc besoin d'aucune option pour l'utiliser. Les autres filtres peuvent être sélectionnés respectivement avec les options -c, -d, -g, -n, -f, -t et -v.
Comme on le voit, le sous-système d'impression ne reconnaît pas automatiquement le format de fichier utilisé. D'autre part, le nombre de filtres utilisables est limité à 8, ce qui peut ne pas suffire étant donné la prolifération des formats de fichiers. Pour résoudre ce problème, APSFILTER utilise un filtre générique (utilisé en tant que filtre par défaut) qui, lui, est capable de reconnaître le format du fichier à imprimer et de le diriger vers un autre filtre ou une série de filtres. Comme on l'a vu ci-dessus, l'ultime filtre utilisé est en général l'interpréteur GhostScript. Ainsi, il n'y a plus de limite sur le nombre de filtres utilisables, et les filtres sont sélectionnés automatiquement en fonction de la nature du document à imprimer.
VI-J-3. Le système d'impression CUPS▲
Le système d'impression CUPS a pour but de remplacer LPRng et d'offrir de nouvelles fonctionnalités. En particulier, il est plus facile de configurer et d'ajuster les paramètres avancés des imprimantes. CUPS permet une meilleure intégration dans un réseau hétérogène, car il implémente le protocole d'impression réseau IPP (« Internet Printing Protocol »), qui est devenu un standard de fait pour tous les systèmes d'exploitation. Couplé au logiciel Samba, il permet également d'accéder aux imprimantes des postes Windows.
CUPS est constitué du démon cupsd, qui gère à la fois les requêtes d'impression effectuées via le protocole d'impression IPP, qui est un protocole d'impression encapsulé dans des requêtes HTML (le langage de description de pages Web utilisé sur Internet). Le démon cupsd étend même ce protocole d'impression pour prendre en charge des pages Web de configuration, ce qui permet de réaliser l'administration du système d'impression très simplement par l'intermédiaire d'une interface Web. Il est ainsi possible de réaliser la configuration et la gestion des imprimantes, ainsi que des groupes d'imprimantes sur lesquelles les travaux d'impression peuvent être répartis. Enfin, CUPS fournit les fonctionnalités de base du système d'impression LPRng, en définissant automatiquement un fichier /etc/printcap correspondant à sa propre configuration, et en fournissant un jeu de commandes lp classiques redirigeant tous les travaux d'impression vers lui.
CUPS utilise également un nouveau système de filtres, qui permettent d'éviter de passer systématiquement par le format d'impression PostScript. Plusieurs filtres peuvent être utilisés pour passer par différents formats intermédiaires. Le choix de ces filtres est déterminé en fonction du coût de chaque conversion dans la chaîne de transformations du document vers le format final utilisé par l'imprimante. On peut donc dire que CUPS est à la fois plus facile à configurer et plus performant que LPRng, tout en restant compatible avec lui pour les applications.
VI-J-3-a. Le mécanisme des filtres de CUPS▲
CUPS utilise une architecture légèrement différente de celle de LPRng. Son système de filtres est plus complexe et plus puissant, et ne nécessite pas un passage obligé par le langage d'impression PostScript.
En réalité, CUPS fournit tout un jeu de filtres élémentaires capables de transformer un document d'un format dans un autre. Tous ces filtres sont agencés pour effectuer la traduction complète du document à imprimer dans le langage d'impression utilisé par l'imprimante. Contrairement à LPRng, les formats intermédiaires ne cette fois sont ni uniques, ni forcément du PostScript.
Il est parfois possible de trouver plusieurs jeux de filtres distincts qui réalisent la conversion du document dans le langage d'impression destination, en passant par différents formats intermédiaires. CUPS doit donc effectuer un choix entre les différents jeux de filtres. Pour cela, il attribue un coût à chaque conversion, et calcule le coût total de chaque jeu de filtres utilisable pour imprimer le document. Il choisit ensuite le jeu de filtres qui a le coût total minimal, et garantit ainsi les performances du système d'impression.
Bien entendu, certains de ces filtres utilisent le bon vieux GhostScript, et la plupart des gestionnaires d'imprimantes sont en réalité des drivers créés pour GhostScript ou pour le logiciel de retouche d'images The Gimp. CUPS requiert donc une version modifiée de l'interpréteur GhostScript, mais les distributions l'installent automatiquement et cela ne pose pas de problème. Finalement, l'impression des documents est une opération très facile, et l'utilisateur ne voit rien de toutes les transformations effectuées sur les documents par le mécanisme des filtres.
Enfin, contrairement à LPRng, CUPS donne la possibilité de fournir des paramètres complémentaires sur les filtres d'impression, ce qui confère une grande souplesse au système d'impression. C'est pour cette raison qu'il est recommandé d'utiliser CUPS si l'on désire faire des impressions couleur ou contrôler finement les paramètres d'impression.
VI-J-3-b. Configuration d'une imprimante CUPS▲
La manière la plus simple de configurer CUPS est d'utiliser son interface Web. Celle-ci est accessible à l'aide de n'importe quel navigateur Internet, en utilisant l'adresse http://localhost:631/admin. Lorsque l'on désire se connecter au serveur Web de CUPS via cette interface, celui-ci exige une authentification de l'administrateur. Vous devrez donc vous identifier en tant que root pour effectuer la configuration du système d'impression.
La page Web affichée présente trois zones permettant de réaliser les principales opérations de configuration du système d'impression.
L'ajout d'une imprimante se fait en cliquant sur le bouton « Add Printer ». Ce bouton ouvre une autre page, dans laquelle il est possible de donner le nom de l'imprimante (champ « Name »), son emplacement sur le réseau (champ « Location ») et sa description (champ « Description/ »). La description permet de détailler la nature de l'imprimante et peut contenir n'importe quel texte. Le bouton « Continue » permet de passer à l'écran suivant, qui fournit la liste des périphériques disponibles. Cette liste contient tous les fichiers spéciaux de périphériques de votre système, ainsi que les protocoles d'impression en réseau supportés par CUPS. La page suivante permet de sélectionner la marque de l'imprimante, et la suivante son modèle. Le bouton « Continue » permet alors de terminer l'installation de l'imprimante.
La configuration des imprimantes installées se fait en cliquant sur le bouton « Manage Printers ». L'écran qui s'affiche contient les boutons « Print Test Page » (impression d'une page de test), « Stop Printer » (suspension des impressions), « Reject Jobs » (interdiction de soumettre de nouveaux travaux d'impression), « Modify Printer » (modification de la définition de l'imprimante), « Configure Printer » (configuration avancée de l'imprimante) et « Delete Printer » (suppression de l'imprimante). La fonctionnalité de configuration avancée des imprimantes permet de fixer les valeurs des paramètres du pilote d'impression, comme la résolution, la taille et le type de papier, ainsi que les paramètres de correction des couleurs.
L'ajout d'un groupe d'imprimantes se fait en cliquant sur le bouton « Add Class ». Comme pour la définition des imprimantes, le formulaire qui apparaît vous permet de décrire le groupe d'imprimantes. L'écran suivant donne ensuite la possibilité d'indiquer les imprimantes qui font partie du groupe. Une fois un groupe d'imprimantes défini, il est possible d'effectuer les tâches d'administration le concernant à l'aide du bouton « Manage Classes ».
VI-J-3-c. Les fichiers de configuration de CUPS▲
Les fichiers de configuration de CUPS sont généralement placés dans le répertoire /etc/cups/. Le fichier le plus important est sans doute le fichier cupsd.conf, qui contient tous les paramètres de configuration du démon cupsd. Ces paramètres sont nombreux et bien décrits dans la documentation de cups, que l'on peut obtenir simplement en ouvrant un navigateur sur l'adresse http://localhost:631/documentation.html. De plus, ce fichier est très bien commenté, aussi seules les options les plus importantes seront-elles décrites ici.
Les principales options concernent la sécurité du système d'impression. Normalement, le démon d'impression cupsd ne doit pas fonctionner sous le compte root, pour éviter de lui donner tous les droits. Pour cela, il change d'identité lorsqu'il démarre et se place dans le compte utilisateur spécifié par l'option User. De même, il se place dans le groupe utilisateur spécifié par l'option Group. Généralement, les valeurs utilisées pour ces deux options sont l'utilisateur lp et le groupe sys, ce sont donc leurs valeurs implicites.
Un autre option particulièrement importante est l'option Listen. Cette option permet d'indiquer au démon cupsd sur quelles interfaces réseau il doit se mettre en écoute pour les clients désirant s'y connecter. Il n'est généralement pas conseillé de laisser ouvert un port non utilisé lorsqu'on se connecte à Internet, aussi est-il recommandé de configurer le démon cupsd pour qu'il n'écoute pas les requêtes provenant d'autres machines que la machine locale. Pour cela, on utilisera la ligne suivante dans le fichier de configuration cupsd.conf :
Listen 127.0.0.1:631Cette commande permet de ne répondre qu'aux requêtes provenant de la machine locale, sur le port dédié au protocole d'impression IPP, à savoir le port 631. Bien entendu, vous pourrez ajouter d'autres machines si vous disposez d'un réseau local, simplement en ajoutant d'autres options Listen. Notez que l'usage de cette option est incompatible avec l'option Port, qu'il faut donc commenter au préalable, faute de quoi cupsd ne répondra à aucune requête.
Note : Comme on le verra dans le chapitre sur la configuration réseau, l'adresse réseau 127.0.0.1 représente soi-même dans les communications réseau. Cela signifie ici que seuls les clients de la machine locale pourront utiliser le système d'impression.
Il est également possible de fixer des droits sur les différents répertoires de configuration de l'interface Web, ainsi que sur les répertoires virtuels utilisés par le protocole IPP lorsque des requêtes sont faites par les clients. Ainsi, il est possible de ne permettre l'impression que pour des clients qui vérifient certains critères. Les règles définissant les droits d'accès aux répertoires sont indiquées dans des sections Location, dont la syntaxe est similaire à celle des balises du langage XML. Par exemple, la section qui décrit les droits d'accès au répertoire de configuration /admin est typiquement de la forme suivante :
<Location /admin>
AuthType Basic
AuthClass System
Order Deny,Allow
Deny From All
Allow From 127.0.0.1
</Location>Vous constaterez que plusieurs informations sont données dans ce type de section. Premièrement, le type d'authentification utilisé est spécifié à l'aide de l'option AuthType. Les différentes valeurs possibles pour cette option sont décrites dans le tableau suivant :
|
Valeur |
Signification |
|
None |
Aucune identification n'est faite. |
|
Basic |
L'identification est réalisée via les mécanismes d'authentification HTML classique. cupsd attend ici un nom d'utilisateur et un mot de passe Unix classiques, qui doivent donc exister dans le fichier /etc/passwd. Notez qu'avec ce mode d'authentification, le mot de passe est envoyé en clair du navigateur Internet utilisé pour réaliser la connexion vers le serveur Web du démon cupsd. Cela signifie que si la communication ne se fait pas en local, une tierce personne pourrait voir le nom d'utilisateur et le mot de passe en écoutant les communications réseau. Ce mode d'authentification est donc extrêmement dangereux. |
|
Digest |
L'identification se fait de la même manière que pour le mode Basic, mais le nom de l'utilisateur et le mot de passe ne sont pas transmis en clair. Au lieu de cela, seules les signatures de ces informations, obtenues à l'aide d'une fonction de chiffrement à sens unique, sont transmises sur le réseau. Il n'est donc plus possible de déterminer le nom de l'utilisateur et son mot de passe en clair. De plus, les mots de passe utilisés ne sont pas forcément les mêmes que ceux du système, et ils sont stockés de manière indépendante dans le fichier passwd.md5 du répertoire /etc/cups/. Ces mots de passe peuvent être ajoutés avec la commande lppasswd. Ce mode d'authentification est donc plus sûr, notez toutefois qu'il reste possible pour un attaquant de se connecter avec le nom de l'utilisateur et son mot de passe chiffré une fois ceux-ci capturés. |
Pour chaque méthode d'authentification, il est possible de préciser le critère utilisé pour vérifier les droits d'accès du client. Ce critère est fixé par l'option AuthClass. Celle-ci peut prendre les valeurs suivantes :
|
Valeur |
Signification |
|
Anonymous |
Aucune critère n'est utilisé, tout le monde peut accéder à la page spécifiée dans la directive Location. Il va de soi que l'utilisation de ce critère avec les autres modes d'authentification que None est absurde. |
|
User |
L'utilisateur authentifié doit être un utilisateur du système Unix sous-jacent. |
|
System |
L'utilisateur authentifié doit être membre du groupe système. Ce groupe est, par défaut, le groupe sys, mais il peut être modifié à l'aide de l'option SystemGroup du fichier de configuration cupsd.conf. |
|
Group |
L'utilisateur authentifié doit être membre du groupe spécifié par l'option AuthGroupName du fichier de configuration cupsd.conf. Ce groupe doit être un des groupes du système Unix sous-jacent, sauf si le mode d'authentification Digest est utilisé. En effet, dans ce cas, le groupe de l'utilisateur doit être celui stocké avec son mot de passe dans le fichier de mots de passe de CUPS (c'est-à-dire le fichier /etc/cups/passwd.md5). |
Les mots de passe cups utilisés pour l'authentification dans le mode d'authentification Digest peuvent être ajoutés à l'aide de la commande lppasswd. Cette commande permet également de fixer le groupe de l'utilisateur lorsque le critère d'accès utilisé est le critère Group. La syntaxe générale de cette commande est la suivante :
lppasswd [-g groupe] -a utilisateuroù groupe est le nom de groupe de l'utilisateur (uniquement utilisé pour le mode d'authentification Digest) et utilisateur est son nom d'utilisateur. À l'issue de cette commande, lppasswd demande deux fois le mot de passe de l'utilisateur et met à jour le fichier passwd.md5.
La deuxième série d'informations fournie dans les sections Location sont les droits sur les machines capables d'accéder à la page Web. L'option Order indique l'ordre d'évaluation des directives suivantes. Il est recommandé d'interdire en premier, et de regarder ensuite si la machine cliente a le droit de se connecter. C'est ce qui est fait dans l'exemple précédent, avec les options « Deny From All » et « Allow From 127.0.0.1 », qui indiquent que seule la machine locale a le droit de se connecter au serveur d'impression.
VI-K. Configuration du lancement automatique des tâches▲
Il est possible de déclencher l'exécution de certaines opérations à intervalles réguliers sous Linux. Ces opérations sont définies pour le système et pour chaque utilisateur. Elles sont enregistrées dans des fichiers de configuration indiquant le moment où elles doivent être déclenchées, et quelle action elles doivent réaliser. Les opérations définies pour le système sont stockées dans le fichier de configuration /etc/crontab. Des commandes additionnelles peuvent être définies dans les répertoires /etc/cron.d/, /etc/cron.daily/, /etc/cron.weekly/ et /etc/cron.monthly/. Par ailleurs, les fichiers de configuration des utilisateurs sont stockés dans le répertoire /var/cron/tab/, sous le nom de chaque utilisateur. Il est bien entendu possible d'éditer ces fichiers en tant que root, mais ce n'est pas recommandé. En effet, la commande crontab permet d'installer, de supprimer et de consulter les fichiers crontab de chaque utilisateur, et ce de manière sûre.
La commande crontab peut être utilisée pour afficher le contenu du fichier de configuration de l'utilisateur qui l'appelle, à l'aide de l'option -l :
crontab -lElle permet également de supprimer ce fichier, à l'aide de l'option -r :
crontab -rEnfin, l'option -e permet d'éditer le fichier crontab, à l'aide de l'éditeur spécifié dans la variable d'environnement VISUAL ou EDITOR. Par défaut, l'éditeur vi sera utilisé.
En tant qu'administrateur du système, il est possible de modifier les paramètres pour n'importe quel utilisateur. Pour cela, il faut préciser le login de l'utilisateur avec l'option -u. Il est recommandé d'utiliser également l'option -u si l'on a effectué un su, car la commande crontab peut ne pas pouvoir déterminer l'utilisateur qui l'a appelé dans ce cas.
Le format des fichiers crontab est suffisamment riche pour permettre de spécifier avec finesse les conditions d'exécution des opérations programmées. En général, le début du fichier contient la définition de variables d'environnement utilisées par crontab. La suite du fichier est réservée aux commandes programmées. Chaque programmation est réalisée sur une ligne du fichier crontab. Les lignes contiennent 5 champs spécifiant la date et l'heure à laquelle la commande doit être exécutée, un nom d'utilisateur éventuel et la commande elle-même. Le nom d'utilisateur ne doit être spécifié que dans le fichier /etc/crontab, qui définit les commandes du système. Il spécifie alors au nom de quel utilisateur la commande doit être exécutée. Pour les fichiers crontab propres à chaque utilisateur, il n'est bien entendu pas nécessaire d'indiquer ce nom.
Les 5 champs de la partie décrivant la date d'exécution de la commande fournissent respectivement les informations suivantes :
- les minutes (comprises entre 0 et 59) ;
- les heures (comprises entre 0 et 23) ;
- le jour dans le mois (compris entre 0 et 31) ;
- le mois (compris entre 0 et 12, ou indiqué par les trois premières lettres du nom du mois en anglais) ;
- le jour dans la semaine (compris entre 0 et 7, ou indiqué par les trois premières lettres du nom du jour en anglais).
Les numéros de mois 0 et 12 correspondent à Janvier, et les numéros de jours 0 et 7 correspondent au Dimanche.
La commande sera exécutée à chaque fois que le jour, le mois, l'heure et les minutes du système correspondront avec ces 5 champs. Il suffit que l'une des spécifications du jour corresponde pour que la commande soit exécutée (c'est-à-dire qu'elle est exécutée une fois pour le jour du mois et une fois pour le jour de la semaine si ces deux champs sont spécifiés).
Il est possible d'utiliser un intervalle de valeurs pour chacun de ces champs, en indiquant la première et la deuxième valeur, séparées d'un tiret. Il est également possible de faire une liste de valeurs et d'intervalles, en séparant chaque donnée par une virgule. Si l'on veut spécifier toutes les valeurs possibles pour un champ, on peut utiliser le caractère '*'. Enfin, il est possible d'indiquer que la commande doit être exécutée toutes les n valeurs pour chaque champ. Pour cela, il suffit de faire suivre le champ d'une barre oblique de division ('/') et du nombre n. Ainsi, si l'on trouve l'expression « */3 » pour les heures, la commande sera exécutée toutes les trois heures.
La spécification de la commande doit être faite sur une seule ligne. Le caractère de pourcentage ('%') a une signification spéciale, sauf s'il est précédé d'un antislash ('\'). Les données qui suivent le premier pourcentage sont passées telles quelles dans l'entrée standard de la commande. Les caractères pourcentages suivants sont interprétés comme des sauts de lignes (donc une validation). Ainsi, la commande suivante :
rm -i file.txt%y%permet de supprimer le fichier file.txt et de répondre 'y' à la commande rm. Le caractère 'y' est passé ici dans le flux d'entrée standard de rm.
Comme vous pouvez le voir, le fichier /etc/crontab du système permet de programmer des opérations périodiques, comme les sauvegardes, la destruction des fichiers temporaires, ou toute autre tâche de maintenance. Ne vous étonnez donc pas si votre ordinateur semble s'activer tout seul régulièrement, à heure fixe (par exemple, sur le coup de 11 heures ou minuit). C'est le fonctionnement normal de votre système, qui s'occupe de toutes les tâches ménagères qu'il s'est réservées pour une heure où normalement tout le monde dort…
Les utilisateurs peuvent également définir leur propre crontab pour effectuer les opérations périodiques qu'ils désirent. Par exemple, ils peuvent programmer une commande qui leur rappellera un rendez-vous.
VI-L. Gestion de l'énergie▲
VI-L-1. Généralités sur la gestion de l'énergie▲
La gestion de l'énergie sur les ordinateurs se fait classiquement via l'une des interfaces APM ou ACPI. APM (abréviation de « Advanced Power Management ») est la plus vieille, et s'appuyait essentiellement sur le BIOS pour prendre en charge la gestion de l'énergie. Elle peut encore n'être que la seule possibilité fonctionnelle sur la plupart des vieilles machines, mais est destinée à être remplacé par l'interface ACPI (abréviation de « Advanced Configuration and Power Interface »), développée par Intel. Cette nouvelle interface, bien que souffrant manifestement encore de quelques défauts de jeunesse, est nettement plus souple. En effet, elle se base sur un tout autre principe qu'APM, puisqu'elle permet cette fois de laisser le système prendre en charge la gestion de l'énergie. Étant donné que l'interface APM est vouée à disparaître, et sachant qu'on ne peut utiliser qu'une seule de ces interfaces, seule l'interface ACPI sera présentée dans ce document.
Le principe de fonctionnement de l'ACPI est le suivant. Le BIOS contient une table définie par le fabricant de l'ordinateur qui décrit le matériel fourni, et définit les opérations de base permettant de gérer l'énergie. Ces opérations sont définies dans un langage standard spécifié par Intel. Le système d'exploitation est en charge de lire ces informations et d'interpréter les opérations définies dans la table ACPI. Ainsi, c'est bien le système d'exploitation qui se charge de la gestion de l'ordinateur.
L'implémentation de l'interpréteur ACPI de Linux est l'implémentation de référence réalisée par Intel. Dans le meilleur des mondes, il ne devrait donc y avoir aucun problème pour utiliser l'ACPI sous Linux. Malheureusement, bon nombre de BIOS fournis par les fabricants sont bogués et ne respectent pas la norme ACPI. En effet, l'implémentation ACPI de Microsoft est incorrecte et son interpréteur accepte des erreurs de syntaxe que leur compilateur ACPI laisse passer (ce qui somme toute est cohérent, ils ne pouvaient pas faire moins sans que le résultat ne cesse de fonctionner). Ce n'est pas le cas de l'interpréteur ACPI de Linux puisque, par définition, elle ne peut se conformer à celle de Microsoft et être compatible bogue à bogue.
Le résultat est, hélas, catastrophique, puisque les fonctionnalités ACPI de ces machines ne peuvent pas être utilisées totalement sous Linux. Microsoft aurait voulu exploiter sa position dominante et corrompre le standard d'Intel pour isoler les concurrents qu'il n'aurait pas fait mieux (avis personnel). La seule solution est de récupérer la table ACPI du BIOS, de la désassembler pour en obtenir le code source, et de tenter de la recompiler avec le compilateur d'Intel (pas celui de Microsoft). Les erreurs apparaissent donc et peuvent ainsi être corrigées. Une fois la table ACPI corrigée, il faut soit convaincre le fabricant de l'ordinateur de mettre un nouveau BIOS à disposition, soit paramétrer le noyau pour qu'il charge cette table au lieu de prendre celle du BIOS pour argent comptant. Corriger une table ACPI boguée est une opération extrêmement technique et absolument hors sujet, et faire en sorte que le noyau l'utilise nécessitait de patcher les sources du noyau jusqu'à la version 2.6.9. À présent, cela est faisable directement à partir du programme de configuration du noyau, mais je n'en parlerais pas plus ici. Vous pouvez consulter le site web de l'ACPI pour plus de détails à ce sujet. Si vous rencontrez des problèmes de ce type, je vous suggère de trouver un Linuxien confirmé, ou de faire une croix sur les fonctionnalités ACPI qui ne sont pas opérationnelles sous Linux.
VI-L-2. Configuration de la gestion de l'énergie▲
La prise en charge des fonctionnalités de gestion d'énergie au niveau du noyau se fait simplement en activant les options correspondantes dans la configuration du noyau. Elles sont regroupées dans le menu « Power management options (ACPI, APM) ». Seules les plus intéressantes sont listées ci-dessous :
- l'option « Power Management support » permet d'activer les fonctionnalités de mise en veille du système sur disque. Il est possible ainsi de sauvegarder l'ensemble du système sur la partition d'échange du système, et de le redémarrer et le restaurer (options « Suspend-to-Disk Support » et « Default resume partition »). Cette option permet également d'activer le menu de gestion de l'énergie par APM.
- le menu « ACPI (Advanced Configuration and Power Interface) Support » permet d'activer les fonctionnalités ACPI. Il donne accès à l'option « ACPI Support », qui elle-même donne accès à de nombreuses options pour les différents composants gérant l'ACPI.
- le menu « CPU Frequency scaling » donne accès à l'option « CPU Frequency scaling ». Cette option permet d'activer la gestion des fonctions d'économie d'énergie des processeurs pour les portables. Ces processeurs sont en effet capables de changer de fréquence d'exécution pour, lorsque l'ordinateur est utilisé pour des tâches peu consommatrices de ressources, abaisser la consommation de l'ordinateur et augmenter l'autonomie du système lorsqu'il fonctionne sur batterie. Les sous-options permettent de spécifier les politiques de gestion de l'énergie ainsi que le type de processeur utilisé.
Les fonctionnalités ACPI prises en charge par le noyau sont exposées à l'utilisateur au travers des systèmes de fichiers virtuels /proc/ et /sys/.
Le répertoire /proc/acpi/ contient essentiellement un sous-répertoire pour chaque composant ACPI pris en charge par le noyau. Dans chacun de ces sous-répertoires, vous trouverez des fichiers contenant les informations courantes sur ces différents sous-systèmes.
Le sous-répertoire /sys/power/ vous permettra quant à lui de modifier le niveau d'économie d'énergie utilisé par votre ordinateur. En particulier, le fichier state vous permettra de le suspendre ou de le mettre en veille. Pour cela, il vous faut simplement écrire le mode désiré dans ce fichier avec la commande echo :
echo -n mode > /sys/power/stateoù mode est le mode désiré. Vous obtiendrez la liste des modes acceptés par Linux en lisant ce fichier avec la commande cat :
cat /sys/power/stateEn général, les modes standby, mem et disk sont disponibles. standby correspond à la mise en veille simple de l'ordinateur. mem permet de réaliser une suspension du système en mémoire, et correspond donc à un niveau d'économie d'énergie supérieur. Enfin, disk permet d'éteindre complètement l'ordinateur après avoir stocké son état dans la partition d'échange. Cette commande correspond au niveau maximum d'économie d'énergie.
Note : Ces fonctionnalités sont relativement expérimentales et peuvent ne pas toutes fonctionner. Généralement, seule la suspension sur disque semble fonctionner, souvent sous condition que certains gestionnaires de périphériques soient déchargés avant la mise en veille.
Si vous disposez d'un portable, il est probable que votre processeur soit capable de fonctionner à différentes fréquences. Il est possible de lire la fréquence courante et de la modifier par l'intermédiaire des fichiers du répertoire /sys/devices/system/cpu/cpu0/cpufreq/. La fréquence courante peut être lue via le fichier cpuinfo_cur_freq. Il n'est pas possible de modifier directement cette valeur. Toutefois, le noyau donne la possibilité de la modifier via la politique de gestion d'énergie via le fichier scaling_governor. Les valeurs possibles pour ce fichier peuvent être lues dans le fichier scaling_available_governors.
Généralement, les politiques disponibles sont powersave et performance. Ces politiques permettent respectivement de changer la fréquence du processeur vers les fréquences indiquées dans les fichiers scaling_min_freq et scaling_max_freq. Ce sont donc dans ces fichiers que l'on pourra définir les fréquences utilisables. La liste des fréquences accessibles est fournie par le fichier scaling_available_frequencies.
VI-L-3. Le démon ACPI▲
Le noyau expose les fonctionnalités de surveillance de l'ordinateur de l'interface ACPI via le fichier spécial de périphérique /proc/acpi/event. Dès qu'un événement se produit (passage de l'alimentation sur batterie pour un portable, hausse anormale de la température du processeur, appui sur le bouton de mise en marche / arrêt, etc.), une ligne signalant cet événement est ajoutée à ce fichier virtuel.
Les applications ne doivent pas lire ce fichier directement, cette tâche étant normalement attribuée au démon acpid. Ce démon surveille le fichier d'événement du noyau et fournit un mécanisme de notification plus générique (c'est-à-dire moins spécifique à Linux) aux applications. Ainsi, les applications peuvent se connecter au démon ACPI et être prévenues des événements que le noyau émet.
Le démon ACPI permet aussi de programmer des actions en réponse aux événements ACPI. Pour cela, il consulte les fichiers de configuration placés dans le répertoire /etc/acpi/events/ et exécute les actions qui y sont enregistrées.
Ces actions sont définies par des paires de lignes événement / action permettant de renseigner, pour chaque type d'événement, l'action à effectuer. Les lignes de définition des événements utilisent des expressions rationnelles pour sélectionner les événements ou les groupes d'événements associés à l'action. Les lignes d'action quant à elles permettent d'indiquer la ligne de commande à exécuter en cas d'apparition de ces événements.
Par exemple, le fichier de configuration par défaut capte l'ensemble des événements ACPI et les passe aux script /etc/acpi/acpi_handler.sh à l'aide de ces deux simples lignes :
event=.*
action=/etc/acpi/acpi_handler.sh %eL'expression rationnelle utilisée dans la ligne de définition des événements signale que toute chaîne de caractères doit correspondre. L'action en réponse est l'exécution du script acpi_handler.sh. La chaîne de caractères complète définissant l'événement est passée en premier paramètre et est représentée par le symbole %e.
Si les événements intéressants étaient tous les événements concernant le bouton d'alimentation de l'ordinateur, l'expression rationnelle utilisée aurait été la suivante :
event=button power.*Comme vous pouvez le constater, le format utilisé pour les descriptions des événements envoyés par le noyau doit être connu pour pouvoir écrire les expressions rationnelles devant les sélectionner. Ces descriptions sont envoyées par le script par défaut acpi_handler.sh dans les fichiers de traces du système. Vous pourrez donc les y trouver après avoir généré les événements ACPI correspondants.
Pour donner un exemple, voici comment ce script peut être modifié afin de faire en sorte que la fermeture du couvercle d'un portable le mette en veille immédiatement sur disque :
#!/bin/sh
# Ajoute / à la liste des séparateurs pour le découpage de la ligne de commande :
IFS=${IFS}/
set $@
case "$1" in
button)
case "$2" in
power) /sbin/init 0
;;
# Traite l'événement de fermeture du couvercle :
lid)
# Vérifie que le couvercle est fermé :
grep -q "close" /proc/acpi/button/lid/LID/state
if [ $? -eq 0 ] ; then
# Met en veille prolongée l'ordinateur :
/usr/sbin/suspend.sh disk
fi
;;
# Trace les événements de type "bouton" non traités :
*) logger "ACPI action $2 is not defined"
;;
esac
;;
# Trace tous les autres événements non traités :
*)
logger "ACPI group $1 / action $2 is not defined"
;;
esacCe script capte l'événement lid (« couvercle » en anglais) et vérifie l'état du capteur de fermeture du couvercle, accessible via le fichier d'état /proc/acpi/button/lid/LID/state (l'emplacement de ce fichier peut varier selon les ordinateurs). Si ce fichier indique que le couvercle est fermé, le script utilitaire suspend.sh est appelé pour mettre en veille l'ordinateur.
Ce dernier script utilise le fichier /sys/power/state pour effectuer cette mise en veille :
#!/bin/sh
# Stocke l'heure système (pour mise à jour de /etc/adjtime) :
hwclock --systohc
# Suspend le système et sur disque (méthode sûre) :
echo -n $1 > /sys/power/state
# Rétablit l'heure système :
hwclock --hctosysComme vous pouvez le constater, il est nécessaire de prendre en compte l'horloge système avant et après une suspension. En effet, sans cela, l'horloge système reprendrait exactement à la date de la suspension lors du réveil. Le stockage de l'heure courante avant suspension est également nécessaire, afin de maintenir le fichier de configuration /etc/adjtime cohérent.
Note : Une autre solution aurait été de faire le test sur l'état du bouton dans le script de suspension et d'appeler celui-ci directement en réponse à l'événement « button lid ».