


VII. Notions de compilation et configuration du noyau▲
Ce chapitre présente les notions de base de compilation et de fichiers sources de programmes. Il est certain que le lecteur de ce document n'a pas forcément l'intention de programmer sous Linux, cependant, il est nécessaire de connaître les notions qui vont être décrites ici. En effet, il n'est pas rare, voire il est même courant, d'avoir à recompiler une application lorsqu'on travaille avec Linux. Cela n'est pas étonnant, quand on sait que toute bonne installation passe par la recompilation du noyau de Linux ! La raison de cet état de fait provient sans nul doute du fait que la licence GNU impose de fournir les fichiers sources aux utilisateurs d'une part, et que le langage C et Unix sont historiquement fortement liés.
Nous allons commencer par donner la définition des notions de base et les étapes intervenant dans le processus de génération des fichiers binaires des programmes. Nous verrons ensuite comment installer (et compiler !) la suite de compilateurs GCC du projet GNU, et nous présenterons les étapes intervenant dans la compilation et l'installation d'un nouveau noyau. Ces informations pourront être utiles pour la lecture du chapitre traitant de la configuration du matériel puisque, bien souvent, la prise en charge d'un périphérique nécessite la compilation de ses pilotes au niveau du noyau.
VII-A. Notions de base▲
VII-A-1. Définition des termes▲
Le langage naturel est le langage que les êtres humains utilisent pour communiquer, soit oralement, soit par écrit. Le langage naturel est très riche : il utilise des constructions grammaticales et syntaxiques complexes, et il dispose d'un vocabulaire très étendu. Il permet donc d'exprimer la plupart des idées humaines, et c'est bien sa fonction. En revanche, il n'est pas rigoureux, dans le sens où il laisse la porte ouverte à un grand nombre d'ambiguïtés. Ce qui n'est pas dit est souvent sous-entendu, et c'est donc pratiquement entre les mots que se trouve le sens du discours. Il n'est ainsi pas rare de pouvoir interpréter une même phrase différemment, selon le contexte socioculturel, géographique ou temporel dans lequel elle est dite. Les jeux de mots utilisent cette caractéristique à merveille. La conséquence est que l'on ne peut pas utiliser facilement le langage naturel pour décrire rigoureusement, voire mathématiquement, quelque chose.
Un langage formel est, au contraire, un langage restreint, qui ne dispose que de très peu de constructions syntaxiques et d'un vocabulaire très limité. La caractéristique principale des langages formels est qu'ils sont rigoureux, une expression ou une phrase donnée peut être validée selon les règles de syntaxe qui doivent être respectées. Tout texte écrit dans un langage formel est donc soit valide, soit invalide.
En définissant une association entre les constructions d'un langage formel et un jeu de concepts limité, il est possible de donner une sémantique à un langage formel. Cette sémantique donne la possibilité de qualifier de « vraies » ou de « fausses » les assertions écrites dans le langage formel (on notera qu'une expression peut être valide du point de vue de la syntaxe, mais sémantiquement fausse).
Un langage formel permet donc d'exprimer avec précision, sans aucune ambiguïté possible, une idée basée sur les concepts qu'il utilise. Les notations mathématiques constituent un langage formel par excellence.
Note : Par exemple, l'expression mathématique « x=1 » est toujours valide, c'est une simple équation. En revanche, elle n'est pas toujours vraie, cela dépend de la valeur de x. En particulier, si x représente 3, on a « 3 = 1 », ce qui est valide, mais faux. Notez bien la différence.
Un langage de programmation est un langage formel qui permet de définir les tâches qu'un ordinateur doit effectuer, et de décrire les objets informatiques sur lesquels il doit travailler. Un langage de programmation est donc un code, et tout programme doit être écrit dans un tel langage. Pratiquement, les langages de programmation sont des langages très simples, disposant de constructions du type « si … alors … » ou « pour chaque … fait … ». Les programmes étant écrits avec de tels langages, il est clair qu'un programme ne fait que ce qui a été écrit : ni plus, ni moins. Il faut donc tout dire à l'ordinateur quand on écrit un programme, ce qui en général est relativement fatigant et compliqué. C'est le prix à payer pour la rigueur de l'informatique : l'ordinateur ne se trompe jamais, parce qu'il ne fait qu'obéir aux ordres donnés dans un langage formel (donc précis). Celui qui se trompe, c'est en général le programmeur, et assez couramment l'utilisateur.
Note : Notez qu'un programme est un texte valide s'il vérifie la grammaire du langage formel dans lequel il est écrit. Cela ne l'empêchera pas de faire n'importe quoi si on l'exécute. Un programme « vrai » est donc un programme syntaxiquement correctement écrit et qui en plus fait ce que l'on désire qu'il fasse. Il n'y en a pas beaucoup… surtout que dans bien des cas, on ne s'est jamais posé clairement la question de savoir ce que doivent faire les programmes que l'on écrit !
Le C est un langage de programmation relativement simple, qui se trouve sur tous les types d'ordinateurs et de systèmes d'exploitation. Les programmes sont plus difficiles à écrire en C que dans d'autres langages de programmation, mais ils sont plus performants. Le C est très utilisé pour écrire les systèmes d'exploitation : le noyau Linux lui-même est écrit en C. Le C++ est un langage plus évolué, qui est dérivé du C. Il est beaucoup plus riche, et il permet d'écrire des programmes plus compliqués et de les faire évoluer plus facilement. Bien que plus lents que ceux écrits en C, les programmes écrits en C++ sont toujours très performants par rapport à ceux écrits dans d'autres langages.
Les programmes sont en général écrits dans un certain nombre de fichiers. Ces fichiers sont appelés les fichiers sources, du fait qu'ils sont à l'origine du programme. Le texte de ces fichiers est appelé le code source, ou plus simplement le code.
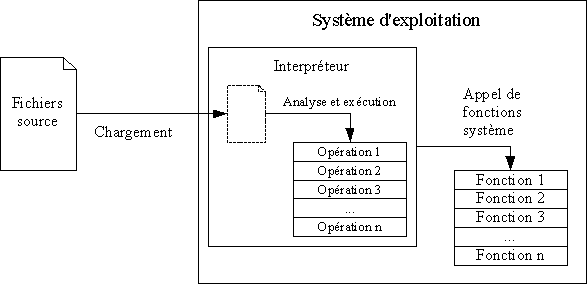
Il va de soi que le code source est écrit dans un langage de programmation, qui n'est pas compréhensible tel quel par le matériel de l'ordinateur. Pour exécuter un programme à partir de son code source, il n'y a que deux solutions :
- disposer d'un autre programme, nommé interpréteur, capable de lire le code source et d'effectuer les opérations décrites dans le code source ;
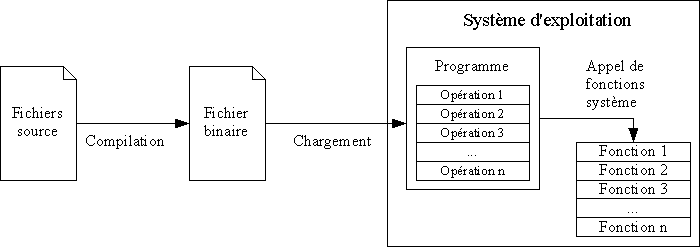
- disposer d'un autre programme, nommé compilateur, capable de traduire le code source en langage binaire, qui sera alors directement exécutable par l'ordinateur.
Les programmes interprétés sont fatalement relativement lents, puisque l'interpréteur doit analyser en permanence les fichiers sources pour le traduire en opération à exécuter à la volée.
En revanche, les programmes compilés sont beaucoup plus rapides à l'exécution, puisque la phase d'analyse du code source a été réalisée au préalable et se fait en dehors de la phase d'exécution. Ces programmes peuvent donc s'exécuter nativement, sans être ralentis par l'interpréteur.
Note : Si vous avez bien suivi, on se trouve face au problème de l'œuf et de la poule. En effet, les interpréteurs et les compilateurs sont eux-mêmes des programmes écrits dans un langage informatique. Quel est donc le premier compilateur ou interpréteur ? Ce problème a effectivement dû être résolu au début de l'informatique, de la manière la plus simple : les premiers programmeurs entraient directement le langage machine en binaire dans les ordinateurs (via les câblages ou les cartes perforées…). Quand on sait le travail que cela représentait, et le nombre d'erreurs que cela a pu générer, on comprend facilement pourquoi les compilateurs et les interpréteurs font partie des tout premiers programmes qui ont été développés…
Dans les systèmes Unix, les deux types de programmes existent. Les programmes interprétés constituent ce que l'on appelle des scripts. Le système utilise le shell pour les interpréter. La plupart des opérations d'administration du système utilisent des scripts, car il est toujours plus facile d'écrire et de tester un script que d'écrire un programme en C. Les programmes compilés sont notamment le noyau lui-même, le shell, les commandes de base et les applications. Ce sont eux qui en fin de compte effectuent le travail, et ils sont souvent appelés à partir de scripts. Nous avons déjà vu des exemples de scripts lors de la configuration du système. Pour l'instant, nous allons nous intéresser au langage C et au processus de compilation.
La compilation est l'opération qui consiste à lire un fichier source et à le traduire dans le langage binaire du processeur. Ce langage est absolument incompréhensible par les êtres humains, cependant, il existe un langage de programmation qui permet de coder directement le binaire : il s'agit de l'assembleur.
En général, le processus de compilation génère un fichier binaire pour chaque fichier source. Ces fichiers binaires sont nommés fichiers objets, et porte de ce fait l'extension « .o » (ou « .obj » dans les systèmes Microsoft). Comme un programme peut être constitué de plusieurs fichiers sources, il faut regrouper les fichiers objets pour générer le fichier exécutable du programme, fichier que l'on appelle également le fichier image en raison du fait que c'est le contenu de ce fichier qui sera chargé en mémoire par le système pour l'exécuter et qu'il contient donc l'image sur disque des instructions des programmes en cours d'exécution. L'opération de regroupement des fichiers objets pour constituer le fichier image s'appelle l'édition de liens, et elle est réalisée par un programme nommé le linker (éditeur de liens en français). Ce programme regarde dans tous les fichiers objets les références partielles aux autres fichiers objets et, pour chaque « lien » ainsi trouvé, il complète les informations nécessaires pour en faire une référence complète. Par exemple, un fichier source peut très bien utiliser une fonctionnalité d'un autre fichier source. Comme cette fonctionnalité n'est pas définie dans le fichier source courant, une référence partielle est créée dans le fichier objet lors de sa compilation, mais il faudra tout de même la terminer en indiquant exactement comment accéder à la fonctionnalité externe. C'est le travail de l'éditeur de liens, lorsqu'il regroupe les deux fichiers objet.
Certains fichiers objet sont nécessaires pour tous les programmes. Ce sont notamment les fichiers objet définissant les fonctions de base, et les fonctions permettant d'accéder au système d'exploitation. Ces fichiers objet ont donc été regroupés dans des bibliothèques (également couramment appelées « librairies »), que l'on peut ainsi utiliser directement lors de la phase d'édition de liens. Les fichiers objets nécessaires sont alors lus dans la bibliothèque et ajoutés au programme en cours d'édition de liens. Les bibliothèques portent souvent l'extension « .a » (ou « .lib » dans les systèmes Microsoft).
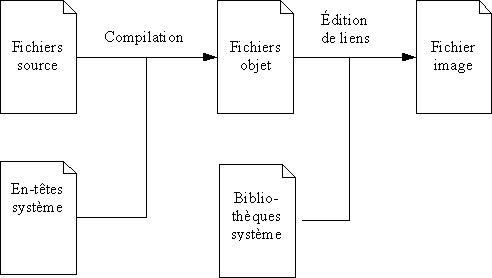
Malheureusement, la solution consistant à stocker dans des bibliothèques les fonctions les plus utilisées souffre de la duplication du code contenu dans ces bibliothèques dans tous les programmes, d'où une perte de place considérable. De plus, la mise à jour d'une bibliothèque nécessite de refaire l'édition de liens de tous les programmes qui l'utilisent, ce qui n'est pas réalisable en pratique. C'est pour cela que les bibliothèques dynamiques ont été créées : une bibliothèque dynamique n'est pas incluse dans les fichiers des exécutables qui l'utilisent, mais reste dans un fichier séparé. Les bibliothèques sont regroupées dans un répertoire bien défini du système de fichiers, ce qui permet de les partager entre différents programmes. Ainsi, la mise à jour d'une bibliothèque peut se faire sans avoir à toucher tous les programmes qui l'utilisent. Le problème est cependant que l'édition de liens reste incomplète, parce que les références aux objets des bibliothèques dynamiques sont toujours externes. Il existe donc un programme spécial, l'éditeur de liens dynamiques (« ld », pour « Link Dynamically »), qui résout les dernières références incomplètes lors du chargement de chaque programme. Les bibliothèques dynamiques portent l'extension « .so » (pour « Shared Object »), ou « .dll » dans les systèmes Microsoft (pour « Dynamic Link Library »).
Évidemment, le chargement des programmes est un peu plus lent avec les bibliothèques dynamiques, puisqu'il faut réaliser l'édition de liens dynamiques lors de leur lancement. Cependant, ce processus a été optimisé, et les formats de fichiers binaires utilisés contiennent toutes les informations précalculées pour faciliter la tâche de l'éditeur de liens dynamiques. Ainsi, la différence de performance est devenue à peine décelable.
VII-A-2. Processus de génération▲
Classiquement, les fichiers sources C et C++ se divisent en deux grandes catégories :
- les fichiers d'en-tête, qui contiennent les déclarations des symboles du programme ;
- les fichiers C (ou C++), qui contiennent leurs définitions.
Le fait de faire cette distinction entre la déclaration (qui consiste à dire : « telle chose existe ») et la définition (qui consiste à décrire la chose précédemment déclarée) permet de faire en sorte que l'on peut utiliser les fichiers objets sans avoir les fichiers sources. En effet, la déclaration permet de réaliser les références partielles dans les programmes, tandis que les fichiers objet contiennent bien entendu la définition binaire de ce qui a été déclaré.
Pour compiler un programme, on n'a donc réellement besoin que de trois types de fichiers :
- les fichiers de déclaration du système et des bibliothèques de base ;
- les fichiers des bibliothèques de base eux-mêmes ;
- les fichiers source (de déclaration et de définition) du programme à compiler.
En C et C++, les fichiers sources de déclaration portent l'extension « .h » (plus rarement « .hpp » pour les fichiers de déclaration C++), et les fichiers de définition portent l'extension « .c » pour les programmes écrits en C et « .C » (ou « .cpp », ou encore « .c++ ») pour les programmes écrits en C++.
Il va de soi que la réalisation d'un programme peut nécessiter la création d'un grand nombre de fichiers, tous plus ou moins dépendants les uns des autres. Pour pouvoir s'y retrouver plus facilement, les programmeurs utilisent un programme spécial : make. Ce programme est capable de réaliser toutes les opérations nécessaires à la création des fichiers exécutables d'un programme à partir de ses fichiers sources. Pour cela, il utilise un fichier contenant la définition des opérations à réaliser, ainsi que la description des dépendances entre les différents fichiers sources. Ce fichier est appelé le fichier makefile. Grâce à make, l'utilisateur de base que vous êtes va pouvoir compiler la plupart des programmes sans avoir la moindre notion de programmation.
En général, la compilation d'un programme passe par les étapes suivantes :
- récupération des fichiers sources du programme ;
- configuration du programme pour l'environnement courant ;
- appel à make pour la compilation ;
- appel à make pour l'installation.
La première étape est élémentaire et va de soi.
La deuxième étape se fait souvent en appelant un script dans le répertoire d'installation des fichiers sources. Ce script se nomme souvent configure, et peut être appelé avec la ligne de commande suivante :
./configureà partir du répertoire où se trouvent les fichiers sources. Ce script effectue tous les tests sur le système et l'environnement de développement, et génère le fichier makefile. Le programme configure est en général fourni avec les logiciels GNU. Il permet de déterminer l'environnement logiciel et système et de générer le fichier makefile et des fichiers d'en-têtes contenant la définition de quelques options du programme. Dans quelques cas particuliers, vous aurez à utiliser des options de configure afin de préciser certains paramètres. L'option --host permet d'indiquer le type de la machine cible, dans le cas où configure ne parvient pas à le déterminer automatiquement :
--host=machineoù machine est la description de votre machine. Pour les PC fonctionnant sous Linux, cette description est de la forme « ix86-pc-linux-gnu », où le 'x' représente le numéro de la génération du processeur du PC. Par exemple, pour un Pentium ou un AMD K6, la description sera « i586-pc-linux-gnu ». L'option --enable-shared permet de générer des bibliothèques dynamiques lors de la compilation. Cela procure un gain de place évident. Enfin, l'option --prefix permet de préciser le répertoire de base dans lequel le programme sera installé a priori. Cette option s'utilise de la manière suivante :
--prefix=répertoireoù répertoire est le répertoire de base de l'installation. La connaissance de ce répertoire est utile aux autres programmes pour localiser les composants qui vont être installés. Dans la plupart des cas, la valeur par défaut du préfixe convient, mais il est parfois nécessaire de le modifier. C'est en particulier le cas lorsque vous désirez mettre à jour un programme déjà installé et que votre distribution n'utilise pas le répertoire par défaut. Dans ce cas, il convient d'indiquer le répertoire de base dans lequel ce programme a été installé, afin de le remplacer au lieu de le dupliquer d'une part, et afin que les autres programmes puissent trouver la nouvelle version à la place de l'ancienne d'autre part.
La troisième étape est très simple aussi. Il suffit de taper la commande suivante :
maketoujours dans le répertoire où se trouvent les fichiers sources.
Enfin, la dernière étape se fait en tapant la commande suivante :
make installBien entendu, ces différentes étapes varient parfois avec le logiciel à installer. Cependant, il existe quasiment toujours un fichier texte indiquant comment effectuer ces opérations dans le répertoire des fichiers sources. Ce fichier porte souvent le nom de « readme », « install », ou quelque chose de similaire.
Avec les notions que vous venez de voir, vous devriez pouvoir compiler quasiment tous les programmes que vous pourrez récupérer sous la forme de fichiers sources. Un dernier détail cependant : la compilation est une opération très gourmande en ressources. Cela signifie qu'elle peut consommer beaucoup de ressources processeur, de mémoire, de disque et de temps. Pour des gros programmes, il n'est pas rare de passer jusqu'à une heure de compilation, même sur une machine récente. Notez également que les facteurs limitants dans les compilations sont souvent la rapidité du processeur et du disque dur, ainsi que la quantité de mémoire vive disponible.
VII-B. Compilation de GCC▲
La clef de voûte du processus de compilation est bien entendu la suite de compilateurs GCC du projet GNU. Cette suite comprend un compilateur pour les langages C, C++, Objective C, Fortran, Java et Ada. La plupart des distributions fournissent ces outils sur leur CD d'installation, mais ne les installent pas par défaut. Il est toutefois recommandé d'installer au moins le compilateur C/C++ et les outils de développement associés, ainsi que les fichiers d'en-tête des bibliothèques de base du système (bibliothèque C, en-têtes de XWindow, des bibliothèques utilitaires et des bibliothèques de base des environnements graphiques Gnome et KDE).
Le choix de la version de GCC utilisée est extrêmement important, car la stabilité et les performances du système en dépendront directement. De plus, certains programmes exigeront une version spécifique du compilateur pour être compilés, soit parce qu'ils n'ont été testés qu'avec cette version par les développeurs, soit parce qu'ils utilisent une fonctionnalité qui n'est disponible que dans les versions récentes de GCC.
Les versions de GCC les plus utilisées sont actuellement les versions issues des branches 3.4 et 4.1. Il est déconseillé d'utiliser les versions les plus récentes (typiquement la version de la branche courante), car elles peuvent souffrir de bogues de jeunesse et elles peuvent être trop strictes pour compiler des programmes qui ne sont pas tout à fait à la norme (en particulier au niveau du langage C++, qui peut avoir des constructions d'usage courant et néanmoins extrêmement compliquées). Ce document suppose que votre distribution utilise la version 4.1.2 de GCC, qui offre les avantages suivants :
- elle permet de compiler de programmes pour les processeurs les plus récents, tels que les IA-64 d'Intel, les x86-64 d'AMD et les PowerPC d'IBM ;
- elle permet d'utiliser les instructions spécifiques des processeurs les plus récents, même d'architecture x86 ;
- elle génère un code bien plus optimisé que les versions précédentes ;
- elle permet de réduire la visibilité des fonctions, variables et types non publics des bibliothèques, et donc de réduire l'empreinte des binaires aussi bien en mémoire que sur disque et de réduire le temps de chargement des programmes récents ;
- la bibliothèque standard C++ fournie avec cette version respecte nettement mieux la norme C++ que les versions antérieures, et elle permet d'utiliser les caractères Unicode dans les programmes C++.
On prendra garde au fait que certaines distributions utilisent régulièrement des versions non stabilisées des programmes de base tels que GCC, la bibliothèque C ou le noyau. C'est en particulier le cas de la Redhat et de toutes ses dérivées, telle la Mandrake par exemple. Tout cela est fort dommageable, car les paquetages binaires de ces distributions sont systématiquement incompatibles avec ceux des autres d'une part, et il est quasiment impossible d'envisager une compilation correcte d'un programme avec ces distributions d'autre part. En pratique, les possesseurs de distributions Redhat et dérivées s'abstiendront donc de faire une mise à jour manuelle de GCC, de la bibliothèque C ou même du noyau, car les programmes installés sur leur machine risqueraient de ne plus fonctionner. Les utilisateurs de ces distributions devraient faire une mise à jour complète de leur distribution dans ce cas.
Note : En ce qui concerne les numéros de version, il faut savoir que le dernier chiffre caractérise souvent le numéro de correctif. Plus ce chiffre est élevé, moins le programme a de chances de comporter de bogues. En pratique, on évitera généralement d'installer systématiquement les dernières versions des logiciels lorsque ces versions sont les premières d'une nouvelle série. Ainsi, un programme de version x.y.0 est certainement peu fiable. Il faudra attendre au moins la version x.y.1 ou mieux la x.y.2, pour pouvoir l'utiliser sereinement. Sachez également que le numéro intermédiaire sert, pour certains logiciels, à indiquer les versions de développement. C'est par exemple le cas du noyau Linux, pour lequel les numéros de version impairs correspondent aux versions de développement et les numéros pairs aux versions stables. Ce n'est pas le cas pour la bibliothèque C ou GCC. De plus, certains logiciels utilisent un schéma de version à quatre chiffres, le dernier chiffre correspondant généralement aux correctifs mineurs n'entraînant théoriquement aucune régression. C'est également le cas du noyau Linux depuis la version 2.6.8. Ainsi, dans un numéro de version x.y.z.t, x représente généralement la version majeure du logiciel (et n'est changée qu'en cas d'incompatibilité majeure ou de refonte complète), y est le numéro de la branche (une convention permettant de distinguer les branches de développement des branches stables y est parfois appliquée), z est le numéro de version dans la branche, et t le numéro du patch regroupant les corrections de sécurité ou de petite taille.
VII-B-1. Prérequis▲
À moins que vous ne réussissiez à mettre la main sur une version de GCC déjà compilée pour Linux, vous ne disposerez que des sources. Les sources de GCC peuvent être récupérées sur Internet sur le site de GCC. Ces sources sont fournies sous la forme d'une archive au format tar-gzip. Le nom de cette archive est « gcc-3.4.4.tar.gz ».
Un autre prérequis est bien entendu que vous disposiez également d'un compilateur C sur votre système. Ce compilateur peut très bien être une ancienne version de GCC, mais il est impératif de disposer d'un compilateur C correct. Le code de GCC a été écrit pour pouvoir être compilé de manière minimale avec la plupart des compilateurs C existants. Il faut également que ce compilateur porte le nom de « cc » ou « gcc » et soit dans l'un des répertoires de la variable d'environnement PATH, ou que la variable CC ait été définie avec le chemin absolu du compilateur.
VII-B-2. Installation des sources▲
Lorsque vous aurez installé le compilateur C natif de votre système, vous devrez décompresser les sources de GCC. Cela doit se faire avec la commande suivante :
tar xvfz archiveoù archive est le nom de l'archive compressée contenant ces sources. Dans notre cas, ce doit être gcc-4.1.2.tar.gz. Cette commande a pour conséquence de créer l'arborescence des répertoires des sources de GCC dans le répertoire où elle a été exécutée.
Une fois cette opération effectuée, il est conseillé de créer un autre répertoire, ailleurs que dans le répertoire des sources de GCC, dans lequel la compilation aura lieu. Dans toute la suite, nous supposerons que le répertoire des sources se nomme srcdir, et que le répertoire de compilation se nomme objdir.
VII-B-3. Configuration▲
L'étape suivante est d'aller dans le répertoire de compilation et de lancer le programme de configuration de GCC dans ce répertoire. Cela peut être réalisé avec les commandes suivantes :
cd objdir
srcdir/configure [options]Comme on l'a vu ci-dessus, le programme de configuration configure peut recevoir des options en ligne de commande. Il est recommandé de fournir l'option --enable-__cxa_atexit, qui permet de rendre GCC compatible avec la version 3 de la norme intervendeurs spécifiant le format des interfaces binaires pour les compilateurs C++, et donc de garantir la compatibilité binaire ascendante avec les versions futures de GCC. Cela vous permettra d'éviter d'avoir à recompiler toutes les bibliothèques C++ lors des mises à jour ultérieures de GCC. Il est également recommandé d'utiliser l'option --enable-long-long, qui ajoute le support du type de données « long long, » qui permet de manipuler des données 64 bits sur les machines 32 bits comme les PC, ainsi que l'option --enable-threads, qui permet d'ajouter le support des threads aux langages.
Normalement, le programme de configuration détecte le type de machine et le système utilisé. Cependant, cette détection peut échouer si les types de machines indiqués pour les différents composants du système ne sont pas identiques. Dans ce cas, il vous faudra spécifier la machine hôte à l'aide de l'option --host. La ligne de commande pour la configuration sera alors la suivante :
srcdir/configure --enable-__cxa_atexit \
--enable-long-long --enable-threads --host=configurationoù configuration est un triplet de la forme i686-pc-linux-gnu.
Le nombre de compilateurs fournis avec la suite de compilateurs GCC est impressionnant. Cependant, seuls les compilateurs C et C++ sont réellement essentiels. Aussi est-il possible de ne prendre en charge que certains langages à l'aide de l'option --enable-languages. Cette option doit être suivie des noms des langages pour lesquels le compilateur doit être créé, séparés par des virgules. Ainsi, on peut n'installer que les compilateurs C/C++ et Java en ajoutant l'option suivante à la ligne de commande :
--enable-languages=c,c++,javaEnfin, si votre distribution utilise le compilateur GCC comme compilateur de base du système, et que vous désirez remplacer la version de votre distribution par la version que vous allez compiler, il faut changer le répertoire d'installation de GCC. Normalement, GCC s'installe dans le répertoire /usr/local/ ce qui fait qu'il ne remplace pas la version de votre distribution. Vous devez donc spécifier les répertoires de base pour l'installation. Pour cela, il suffit d'ajouter les options suivantes :
--prefix=/usrà la ligne de commande de configure.
VII-B-4. Compilation▲
La compilation de GCC peut ensuite être réalisée. Autant vous prévenir tout de suite : c'est une opération très longue, qui de plus demande beaucoup d'espace disque. Il faut au moins prévoir 800 Mo d'espace disque, et presque trois heures sur une machine à 500 Mhz. Cela est dû au nombre de langages supportés par les versions récentes de GCC, à la technique employée lors de sa compilation. La plupart des compilateurs C ne sont en effet pas capables de compiler GCC avec toutes ses fonctionnalités, aussi la compilation se déroule-t-elle en trois étapes :
- une version allégée de GCC est compilée avec le compilateur natif du système dans une première passe ;
- cette version est utilisée pour compiler la version complète de GCC ;
- la version complète est utilisée pour se recompiler, afin de tester les différences entre les deux versions complètes.
Ainsi, GCC se compile lui-même !
Ces trois opérations peuvent être exécutées à l'aide d'une seule commande :
make bootstrapCette commande doit être exécutée à partir du répertoire de compilation objdir.
VII-B-5. Installation de GCC▲
Lorsque la compilation s'est terminée, vous pouvez installer GCC. Il est recommandé de supprimer le compilateur que vous avec utilisé pour compiler GCC, sauf si, bien entendu, il s'agissait déjà de GCC. En effet, il n'est pas nécessaire de le conserver, puisque vous utiliserez désormais GCC. L'installation de GCC est, encore une fois, très simple :
make installCette commande installe GCC ainsi que la bibliothèque standard C++.
VII-C. Compilation du noyau Linux▲
La compilation du noyau est une spécificité des systèmes libres, qui n'est possible que parce que l'on dispose des sources du noyau. Cependant, même pour certains Unix commerciaux, il est possible d'effectuer une édition de liens, les modules du noyau étant fournis sous la forme de fichiers objet. La compilation ou l'édition de liens du noyau est une opération technique qui peut surprendre un habitué des systèmes fermés que sont par exemple Windows ou OS/2. Cependant, elle permet d'obtenir un noyau très petit, optimisé pour la machine sur laquelle il tourne, et donc à la fois économe en mémoire et performant. Il est donc recommandé d'effectuer cette compilation : pourquoi conserver un monstre capable de gérer des périphériques qui ne sont pas et ne seront jamais installés sur votre système ?
La compilation du noyau de Linux nécessite de disposer des sources du noyau fourni par votre distribution. En effet, la plupart des distributions modifient ces sources pour y ajouter des fonctionnalités ou des correctifs de sécurité, ce qui permet de ne pas prendre le risque d'utiliser la dernière version officielle du noyau, qui peut ne pas être considérée comme stable, car trop récente. Parfois même, ce sont des fonctionnalités non encore incluses dans le noyau officiel qui sont utilisées par les distributions, ce qui rend l'utilisation du noyau générique impossible. Rien ne vous empêche d'utiliser pour autant la dernière version officielle du noyau, mais vous vous exposerez au risque d'avoir un système non fonctionnel, ou au moins à diagnostiquer des problèmes encore inconnus ou d'avoir à mettre à jour d'autres composants de votre distribution manuellement en raison des évolutions que ce noyau peut avoir subi.
Le noyau utilise des constructions spécifiques à gcc et ne peut donc être compilé de manière fiable que par ce compilateur (même si d'autres compilateurs compatibles avec GCC sont utilisables moyennant quelques efforts).
Note : La documentation du noyau indique que la version de gcc à utiliser pour le compiler est la version 3.2. La raison en est que les développeurs du noyau eux-mêmes changent rarement de compilateur, afin de ne pas avoir à se préoccuper d'éventuels bogues de celui-ci et ainsi de pouvoir se concentrer sur leur travail. La version 3.2 n'ayant pas de bogues majeurs, elle a été retenue, et les développeurs principaux sont supposés utiliser cette version. Ainsi, le noyau est théoriquement testé avec cette version, c'est la raison pour laquelle elle est recommandée. Toutefois, les versions plus récentes de GCC sont également tout à fait valables de manière générale, et parfois même elles sont nécessaires pour les architectures les plus récentes. Ainsi, les architectures 64 bits requièrent au minimum GCC 3.4… Quoi qu'il en soit, il n'y a généralement aucun problème à compiler le noyau avec les versions récentes de GCC, et en pratique on pourra utiliser la version installée dans le système sans inquiétude.
La compilation du noyau n'est pas très difficile. Elle nécessite cependant de répondre correctement aux questions de configuration. Les erreurs peuvent être multiples, et souvent fatales. Il est donc fortement conseillé de disposer d'une disquette de démarrage afin de réparer le système en cas d'erreur. Par ailleurs, il faut toujours conserver le dernier noyau utilisable en sauvegarde dans le répertoire /boot/. Il faut également ajouter une entrée spécifiant ce noyau dans le programme de démarrage (lilo), afin de pouvoir sélectionner l'ancien noyau en cas d'erreur. Ces opérations seront décrites en détail plus loin.
La compilation du noyau se passe en quatre étapes :
- installation des fichiers sources ;
- réponse aux questions de configuration ;
- compilation et installation du noyau ;
- compilation et installation des modules.
VII-C-1. Installation des sources de Linux▲
Les sources du noyau sont normalement fournies par votre distribution. Vous pouvez toutefois trouver les sources génériques du noyau « officiel » sur le site kernel.org. Il est possible de récupérer les sources complètes, sous la forme d'une archive compressée d'environ 43 Mo. Toutefois, si l'on dispose déjà d'une version complète des fichiers sources, il est envisageable de ne télécharger que les fichiers différentiels de cette version à la version courante (ce que l'on appelle classiquement des « patches »).
Note : Les utilisateurs des distributions Redhat dérivées (telle que la Mandrake par exemple) doivent impérativement utiliser les sources fournies par leur distribution. En effet, les noyaux de ces distributions sont patchés à mort pour utiliser des fonctionnalités non stabilisées de la version de développement du noyau de Linux, et sans lesquelles la plupart des programmes et la bibliothèque C elle-même ne fonctionneraient plus. Je déconseille aux utilisateurs de ces distributions de se lancer dans l'aventure d'une quelconque compilation d'un des composants système.
Il est recommandé d'installer les sources du noyau dans un autre répertoire que celui où se trouvent les fichiers sources de votre distribution, car ceux-ci contiennent les fichiers d'en-tête C qui ont été utilisés pour générer la bibliothèque C du système et sont donc nécessaires à la compilation des programmes. Le remplacement des fichiers sources du noyau imposerait donc, en toute rigueur, de recompiler la bibliothèque C du système. Cette opération est extrêmement technique, risquée et longue, de plus, les fichiers d'en-tête du noyau évoluent souvent et provoquent des incompatibilités avec les programmes qui les utilisent. Les plus motivés trouveront toutefois en annexe la manière de procéder pour recompiler la bibliothèque C.
Généralement, les fichiers sources de Linux sont installés dans le répertoire /usr/src/linux/. Certaines distributions font une copie des fichiers d'en-tête du noyau qui ont servi pour la génération de la bibliothèque C dans les répertoires /usr/include/linux/, /usr/include/asm/ /usr/include/asm-generic. Si ce n'est pas le cas, il faudra éviter d'écraser le contenu du répertoire /usr/src/linux/ lors de l'installation des sources du nouveau noyau. Une solution est par exemple d'installer les fichiers du noyau dans le répertoire /usr/src/linux<version>/ et de ne pas toucher au répertoire des sources originel /usr/src/linux/. Les commandes suivantes permettront d'extraire les sources dans le répertoire dédié aux sources de Linux :
cd /usr/src
tar xvfz linux-2.6.13.2.tar.gzSi l'on dispose déjà d'une version complète des fichiers sources, et que l'on désire appliquer un patch, il faut décompresser le fichier de patch avec la commande suivante :
gunzip fichier.gzoù fichier.gz représente le fichier de patch compressé (en supposant qu'il ait été compressé à l'aide de gzip). L'application du patch se fait de la manière suivante :
patch -p1 < fichierCette commande doit être lancée à partir du répertoire des sources du noyau (par exemple /usr/src/linux-2.6.13.2/). Dans cette ligne de commande, fichier représente le nom du fichier de patch précédemment décompressé, et l'option -p1 indique au programme patch d'utiliser les noms de répertoires relatifs au répertoire parent (à savoir le répertoire contenant le répertoire des sources du noyau, donc /usr/src/ dans notre cas). Si le patch doit être appliqué depuis un autre répertoire, il faudra éventuellement modifier l'option -px passée en paramètre au programme patch, où x est le nombre de niveaux de répertoires à ignorer pour l'application du patch. Consultez la page de manuel patch pour plus de détails sur cette option.
VII-C-2. Choix des options de configuration du noyau▲
La configuration du noyau peut se faire à l'ancienne avec la commande suivante :
make configCette commande pose une série de questions auxquelles il faut pouvoir répondre correctement du premier coup. On n'a pas le droit à l'erreur ici, faute de quoi il faut tout reprendre à zéro.
Il est nettement préférable d'utiliser la version texte, qui fournit les options de configuration sous la forme de menus. Cela peut être réalisé avec la commande suivante :
make menuconfigCertains préféreront l'une des versions X11 du programme de configuration, que l'on peut obtenir avec les commandes
make xconfigou
make gconfigSachez cependant que certaines options ne sont toutefois pas correctement proposées dans ce mode, et que la version textuelle du programme de configuration reste recommandée.
Quelle que soit la méthode utilisée, il faut répondre par 'Y' (pour « Yes »), 'N' (pour « No ») ou 'M' (pour « Module ») lorsque c'est possible. 'Y' et 'M' incluent la fonctionnalité courante dans le noyau, 'N' la supprime. 'M' permet d'utiliser la fonctionnalité en tant que module du noyau. En général, l'utilisation des modules permet d'alléger le noyau, car les fonctionnalités sont chargées et déchargées dynamiquement. Cependant, les fonctionnalités nécessaires au démarrage de Linux, comme les gestionnaires de disques et systèmes de fichiers par exemple, ne doivent en aucun cas être placées dans des modules, car le système ne pourrait alors pas démarrer.
Le choix des options de configuration est réellement très large, car celles-ci couvrent un ensemble de fonctionnalités très large. La description exhaustive de ces options est à la fois fastidieuse et inutile, car vous n'utiliserez pas tous les gestionnaires de périphériques et toutes les fonctionnalités de Linux avec un même ordinateur. Il s'agit donc de répondre aux questions appropriées pour votre configuration, mais de le faire avec rigueur : la moindre erreur de configuration peut empêcher votre système de fonctionner correctement, voire l'empêcher de démarrer tout simplement. Vous trouverez une description rapide des principales options de configuration dans l'Annexe A. Les options les plus utiles seront également décrites lorsque cela sera nécessaire dans le chapitre de configuration du matériel.
VII-C-3. Compilation et installation du noyau▲
Une fois la configuration du noyau réalisée, la compilation peut être lancée. Pour cela, il suffit de lancer la simple commande make dans le répertoire /usr/src/linux.
Une fois la compilation achevée, il faut installer le nouveau noyau. Cette opération nécessite beaucoup de prudence, car si le noyau nouvellement créé n'est pas bon, le système ne redémarrera pas. C'est pour cela qu'il est conseillé de conserver toujours deux versions du noyau, dont on est sûr que l'une d'entre elles fonctionne parfaitement. En pratique, cela revient à conserver la version originale du noyau installé par votre distribution. Pour cela, il faut en faire une copie de sauvegarde.
En général, le noyau est installé dans le répertoire /boot/ (ou dans le répertoire racine pour les anciennes versions de Linux). Il porte souvent le nom de vmlinuz. Pour le sauvegarder, il suffit donc de taper par exemple la commande suivante :
cp vmlinuz vmlinuz.oldIl faut également indiquer au gestionnaire d'amorçage qu'il faut qu'il donne maintenant la possibilité de démarrer l'ancienne version du noyau sous ce nouveau nom. Pour LILO, il suffit d'éditer le fichier /etc/lilo.conf et d'y ajouter une nouvelle configuration. En pratique, cela revient à dupliquer la configuration du noyau actuel et à changer simplement le nom du noyau à charger (paramètre « image » de la configuration dans /etc/lilo.conf) et le nom de la configuration (paramètre « label »). Vous devrez aussi rajouter l'option « prompt » si elle n'y est pas déjà, afin que LILO vous demande la configuration à lancer à chaque démarrage. Dans notre exemple, le nom du noyau à utiliser pour la configuration de sauvegarde sera vmlinuz.old. De même, si la configuration initiale de Linux porte le nom « linux », vous pouvez utiliser le nom « oldlinux » pour la configuration de sauvegarde.
Une fois le fichier lilo.conf mis à jour, il faut vérifier que l'on peut bien charger l'ancien système. Pour cela, il faut réinstaller LILO et redémarrer la machine. La réinstallation de LILO se fait exactement de la même manière que son installation, simplement en l'invoquant en ligne de commande :
liloSi LILO signale une erreur, vous devez corriger immédiatement votre fichier lilo.conf et le réinstaller.
Pour le GRUB, la définition d'une nouvelle configuration se fait également en dupliquant la configuration initiale et en changeant le nom de l'option de menu du GRUB et le chemin sur le fichier du noyau sauvegardé. Veillez également à bien ajouter une option timeout pour avoir la moindre chance de sélectionner la configuration à lancer. Tout cela doit être effectué dans le fichier de configuration /boot/grub/menu.lst. Contrairement à LILO, il n'est pas nécessaire de réinstaller le GRUB pour que les modifications de ce fichier soient prises en compte au démarrage suivant.
Vous pourrez alors redémarrer la machine avec la commande suivante :
rebootLe gestionnaire d'amorçage utilisé vous propose alors de choisir le système d'exploitation à lancer. Il faut ici sélectionner la configuration de sauvegarde pour vérifier qu'elle est accessible et fonctionne bien. Le système doit alors démarrer en utilisant la copie sauvegardée du noyau. Si cela ne fonctionne pas, on peut toujours utiliser le noyau actuel en sélectionnant le noyau initial et en corrigeant la configuration du gestionnaire d'amorçage.
Lorsque vous vous serez assuré que le système peut démarrer avec la sauvegarde du noyau, vous pourrez installer le nouveau noyau. Son image a été créée par make dans le répertoire /usr/src/linux/arch/i386/boot/, sous le nom bzImage. L'installation se fait donc simplement par une copie dans /boot/ en écrasant le noyau actuel vmlinuz :
cp /usr/src/linux/arch/i386/boot/bzImage /boot/vmlinuzIl faut également copier le fichier System.map du répertoire /usr/src/linux/ dans le répertoire /boot/ :
cp System.map /bootCe fichier contient la liste de tous les symboles du nouveau noyau, il est utilisé par quelques utilitaires systèmes.
Si vous utilisez LILO, il vous faudra le réinstaller à nouveau pour qu'il prenne en compte le nouveau noyau. Cela se fait avec la même commande que celle utilisée précédemment :
liloCette opération n'est en revanche pas nécessaire avec le GRUB.
Encore une fois, il faut redémarrer la machine avec la commande suivante :
rebootet vérifier que le nouveau noyau fonctionne bien. S'il ne se charge pas correctement, c'est que les options de configuration choisies ne sont pas correctes. Il faut donc utiliser le noyau sauvegardé, vérifier ses choix et tout recommencer. Attention cependant, cette fois, il ne faut pas recommencer la sauvegarde du noyau puisque cette opération écraserait le bon noyau avec un noyau défectueux.
Si le nouveau noyau démarre correctement, il ne reste plus qu'à installer les modules.
VII-C-4. Compilation et installation des modules▲
Si le système a redémarré correctement, on peut installer les modules. Il n'est pas nécessaire de prendre les mêmes précautions pour les modules que pour le noyau. Il suffit donc ici de lancer la commande suivante dans le répertoire /usr/src/linux/ :
make modules_installAu préalable, il est recommandé de décharger tous les modules présents en mémoire. Cela peut être réalisé à l'aide de la commande modprobe et de son option -r.
Les modules sont installés dans le répertoire /lib/module/version/, où version est le numéro de version du noyau courant. Il est possible que des modules d'autres versions du noyau existent dans leurs répertoires respectifs. Si vous n'en avez plus besoin, vous pouvez les effacer. Attention cependant si vous avez installé des modules additionnels non fournis avec le noyau dans ces répertoires, vous pourriez encore en avoir besoin.
Comme on l'a déjà vu, les modules sont utilisés par le chargeur de module du noyau, grâce à la commande modprobe. Cette commande a besoin de connaître les dépendances entre les modules afin de les charger dans le bon ordre. Il faut donc impérativement mettre à jour le fichier /lib/modules/version/modules.dep à chaque fois que l'on installe les modules, à l'aide de la commande suivante :
depmod -aNote : La commande depmod -a est exécutée automatiquement lors de l'installation des modules du noyau. Toutefois, elle devra être exécutée manuellement si l'on installe des modules non fournis avec le noyau.