


IV. Présentation générale du système▲
Si vous êtes parvenu jusqu'ici, vous disposez d'un système Linux fonctionnel. Félicitations ! Un monde nouveau s'ouvre à vous, et vous allez pouvoir explorer toutes les fonctionnalités de ce nouveau système.
Toutefois, découvrir un nouveau système d'exploitation peut s'avérer moins facile qu'on ne le pense. En effet, chaque système a ses spécificités, et la manière de réaliser une tâche n'est pas forcément celle à laquelle on peut s'attendre. Ce chapitre a donc pour but de vous présenter les notions générales sur lesquelles le système se base, afin de vous mettre le pied à l'étrier et de vous donner un cadre auquel vous pourrez vous raccrocher.
Si vous avez déjà utilisé un système Unix, vous n'aurez sans doute pas de difficulté à vous adapter, et la plupart des notions qui seront présentées dans ce chapitre ne vous seront donc pas étrangères. De même, si Linux est le premier système d'exploitation que vous utilisez, vous pourrez apprendre les procédures sans trop de difficultés. En revanche, si vous êtes d'abord un utilisateur de Microsoft Windows, la transition sera sans doute difficile dans un premier temps. Les habitudes ayant la vie dure, vous devrez en effet commencer par vous débarasser d'une bonne partie d'elles avant de pouvoir utiliser correctement Linux.
Nous allons présenter l'architecture générale du système dans un premier temps. La notion d'utilisateur et les principes de base de sécurité des systèmes Unix seront ensuite abordés. Enfin, les notions relatives à la gestion des fichiers sous Linux, ainsi que les principaux systèmes de fichiers disponibles et leurs fonctionnalités seront vues. Ce chapitre se terminera par une présentation de l'arborescence standard du système de fichiers de Linux, qui vous sera sans doute très utile pour savoir le rôle de chacun des répertoires systèmes de Linux et l'emplacement des différents composants du système.
IV-A. Architecture du système▲
IV-A-1. Principe de modularité▲
Comme tout logiciel d'une certaine taille, un système d'exploitation est d'une grande complexité. Tous les systèmes d'exploitation récents sont en effets constitués d'un grand ensemble de composants qui interagissent entre eux et qui doivent fonctionner de concert afin d'assurer la bonne marche du système et répondre aux besoins de l'utilisateur.
Cette complexité implique un grand nombre d'erreurs, d'anomalies et de dysfonctionnements possibles, ainsi qu'une grande difficulté à en comprendre l'origine. En effet, pour qu'un système informatique fonctionne correctement, il faut tout prévoir pour donner une action appropriée à tous les événements possibles, et trouver la cause d'un problème est d'autant plus difficile qu'il y a de composants qui interviennent dans la fonction défaillante. Cela n'est pas humainement réalisable quand le système devient trop complexe si l'on n'est pas organisé et qu'on ne connaît pas les grandes lignes de l'architecture du système.
Pour résoudre ce problème, il est courant de subdiviser les systèmes complexes en composants indépendants, dont le mauvais fonctionnement potentiel ne peut perturber que partiellement les autres parties du système. Par ailleurs, ces composants sont regroupés en couches logicielles successives, les couches supérieures s'appuyant sur les services des couches inférieures. Ainsi, des points de synchronisation à partir desquels le système peut reprendre un fonctionnement normal après une défaillance peuvent être définis. Ces points de synchronisation permettent donc d'assurer la viabilité du système, ou du moins des couches inférieures, même en cas d'erreur inopinée d'un composant dans une couche de plus haut niveau.
Il va de soi que, lorsqu'un composant se plante, ceux qui l'utilisent risquent de se retrouver dans un état d'erreur assez difficile à gérer. Cela peut souvent provoquer leur propre perte. Par conséquent, plus un composant est utilisé, plus il doit être fiable. Autrement dit, les composants des couches inférieures doivent nécessairement être beaucoup plus fiables que ceux des couches de plus haut niveau, car ils sont utilisés par tout le reste du système.
Pour quelques systèmes, le découpage fonctionnel est trop grossier, voire inexistant. Il arrive également que les interactions entre les composants soient trop importantes et impliquent une dépendance entre eux qui annihile le bénéfice de leur isolation. Dans ces systèmes, une défaillance d'un composant peut donc entraîner un dysfonctionnement global sévère, et en pratique peut nécessiter jusqu'à un redémarrage de l'ordinateur. Les systèmes monolithiques et les systèmes dont les composants sont trop interdépendants sont donc sujets à de nombreux redémarrages, parfois même pour des raisons mineures (modification de la configuration du système, ajout d'un logiciel, ou même simple erreur d'un logiciel).
Il est d'usage de considérer que Linux est un système monolithique. En effet, toute la gestion du matériel, ainsi que la gestion de certaines fonctionnalités de haut niveau, est prise en charge au niveau du noyau (« kernel » en anglais). On pourrait donc craindre une faible fiabilité de ce système d'exploitation. Toutefois, cette vision des choses n'est pas tout à fait juste, car, comme on l'a déjà dit, le noyau n'est qu'une partie du système d'exploitation, et en réalité un système Linux est effectivement constitué de différentes couches fonctionnelles. De plus, le noyau reste d'une taille raisonnable. Pour l'essentiel, il est constitué que d'une base relativement petite et très bien testée, à laquelle beaucoup de pilotes de périphériques ont été ajoutés. La complexité du noyau reste donc limitée, car les pilotes de périphériques ne sont bien entendu pas tous utilisés en même temps sur une même machine.
Par ailleurs, le noyau Linux est d'une très, très grande fiabilité, et il n'est pas rare de voir un système Linux fonctionner plusieurs mois ou années sur des serveurs. Cette grande fiabilité provient du modèle de développement de Linux, qui est ouvert à tout le monde (chacun peut récupérer, lire, modifier, et compléter ou corriger le noyau à condition de savoir bien programmer). Ainsi, à partir d'une taille critique en terme de nombre d'utilisateurs, taille que Linux a atteinte, il existe suffisamment de développeurs pour détecter et corriger les erreurs. En pratique, dès qu'une erreur est détectée, elle est souvent corrigée dans les jours qui suivent si la fonctionnalité concernée est effectivement utilisée, ce qui assure finalement une très grande qualité.
IV-A-2. Les différentes couches logicielles sous Linux▲
Ainsi, un système Linux est constitué, outre du noyau, d'un certain nombre d'autres couches logicielles, qui s'appuient les unes sur les autres. Nous allons donc présenter brièvement ces couches ici.
Le noyau se trouve bien évidemment à la base de toutes les autres couches, puisqu'il gère quasiment tout le matériel (mémoire, disques, systèmes de fichiers, réseau, clavier, etc.). Mais comme il n'est pas exploitable tel quel (par exemple, il n'est pas capable d'offrir une interface utilisateur permettant de lui donner les commandes que l'ordinateur doit exécuter) il faut au moins une interface utilisateur.
Cette interface utilisateur, c'est ce qu'on appelle le « shell » (ce qui signifie grosso modo « environnement utilisateur »). Le shell est capable de lire des commandes saisies au clavier, de les exécuter et d'afficher leurs résultats à l'écran. En général, les programmes capables de réaliser ces opérations sont appelés des interpréteurs de commandes. Mais le shell est bien plus que cela, car il peut être programmé, et il peut gérer les processus (en arrêter un, en lancer un autre, etc.). Bien entendu, il existe plusieurs shells, mais le plus utilisé sous Linux est le shell bash, qui est développé par la Free Software Foundation et distribué sous licence GPL.
En fait, les commandes que le shell peut exécuter sont en nombre très réduit. La plupart des commandes sont donc tout simplement prises en charge par d'autres programmes. Ces programmes, que l'on peut utiliser directement dans le shell, sont ce que l'on appelle des programmes « en ligne de commande », parce qu'ils sont propres à être utilisés dans les lignes de commandes que l'on saisit au clavier dans le shell. Ces programmes sont, encore une fois, développés soit par la Free Software Foundation, soit par des bénévoles, toujours sous la licence GPL. Toutes ces commandes sont des commandes compatibles Unix, et nous apprendrons à nous en servir dans le Chapitre 5.
Bien entendu, ces commandes sont absolument essentielles pour pouvoir utiliser le système, mais elles sont assez rébarbatives et peu d'utilisateurs acceptent de s'en contenter. C'est pour cela qu'une couche graphique a été développée, pour introduire une interface graphique plus conviviale : XWindow. Encore une fois, cette couche logicielle est constituée de plusieurs composants, dont la base est le serveur X. Le serveur X est un programme capable de fournir les services graphiques (d'où le nom de serveur) aux autres applications. Plusieurs implémentations concurrentes existent. L'une d'elles est particulièrement utilisée sous Linux, puisqu'elle est libre : X.org. À vrai dire, un serveur X ne fait pas grand-chose d'autre que de réaliser des affichages sous les ordres d'autres programmes. D'autres composants permettent donc d'obtenir des fonctionnalités de plus haut niveau.
Le gestionnaire de fenêtres (« Window Manager » en anglais) est un de ces composants. Il se place juste au-dessus du serveur X et prend en charge, comme son nom l'indique, la gestion des fenêtres des applications graphiques sous X. C'est le gestionnaire de fenêtres qui prend en charge la gestion des décorations des fenêtres de premier niveau (c'est-à-dire des fenêtres principales des programmes). Par exemple, il s'occupe d'afficher les bords, la barre de titre, les boutons de réduction et de restauration, etc. des fenêtres. C'est également lui qui s'occupe du positionnement des fenêtres, et qui donc permet à l'utilisateur de déplacer et de réduire les fenêtres des applications graphiques. L'utilisateur est libre d'utiliser le gestionnaire de fenêtres qu'il désire, selon ses propres goûts et ses désirs, la différence est souvent une pure question de style.
Il existe également des environnements graphiques complets qui, en plus de fournir un gestionnaire de fenêtres, fournissent la plupart des outils classiques que l'on est en droit d'attendre d'un système graphique moderne. Ainsi, ces environnements comprennent des éditeurs, des outils de configuration, des navigateurs Internet, des logiciels multimédias… En plus de ces applications, ils fournissent un cadre standard pour les applications graphiques qui savent communiquer avec eux. Ce cadre permet d'améliorer l'intégration des diverses applications entre elles, et c'est la raison pour laquelle on appelle souvent ces environnements des gestionnaires de bureau. KDE et Gnome sont des exemples de tels environnements de travail.
Enfin, au-dessus de toutes ces couches logicielles, on trouve les applications X, qui sont aussi diverses que variées (traitement de texte, tableurs, logiciels de dessin…). Quelques-unes de ces applications sont simplement des « front-end » d'applications en ligne de commande, c'est-à-dire des interfaces graphiques pour des programmes non graphiques. Ce concept permet d'avoir un composant unique réalisant une action, utilisable en ligne de commande et donc scriptable, et une ou plusieurs interfaces graphiques pour ce composant. De plus, ce modèle permet de séparer clairement l'interface graphique du traitement qu'elle permet de réaliser. La stabilité en est d'autant plus accrue.
Bon nombre d'applications pour XWindow sont libres, ou utilisables librement à des fins non commerciales (dans ce cas, on a le droit de les utiliser tant que ce n'est pas pour réaliser un travail qu'on revendra). On peut donc considérer qu'il est actuellement possible, avec Linux, d'avoir un environnement logiciel complet, fiable et performant… pour un prix de revient minime.
Note : Il n'est pas évident d'établir un parallèle entre l'architecture d'un système comme Linux avec celle de MS Windows. Cependant, on peut considérer que le noyau Linux correspond aux modules KERNEL de Windows et de tous les services de type pilote de périphérique, que le shell correspond à l'interpréteur de commandes CMD.EXE, que les programmes en ligne de commande correspondent aux programmes en mode console classique (xcopy, fdisk, format…), que le serveur X correspond au couple (pilote de carte graphique, GDI), que le gestionnaire de fenêtres correspond au module USER, et que le gestionnaire de bureau correspond à l'explorateur, Internet Explorer, aux fonctionnalités OLE permettant la communication entre applications, et aux programmes fournis avec Windows lui-même.
La différence essentielle vient du fait que le shell est à peine programmable sous Windows, que le pilote de carte graphique, la GDI et le module USER sont tous intégrés dans le système au lieu d'en être séparés (ce qui multiplie les chances de crash du système complet), et que la plupart des applications Windows ne peuvent fonctionner que dans l'environnement graphique. Elles sont donc entraînées par le système lorsque les modules graphiques de Windows plantent (je n'ai d'ailleurs jamais vu un processus DOS survivre à un crash de l'interface graphique de Windows).
IV-A-3. Résumé de l'architecture de Linux▲
En résumé, un système GNU/Linux est structuré de la manière suivante :
- le noyau Linux ;
- les programmes en ligne de commande et le shell ;
- le serveur XWindow ;
- le gestionnaire de fenêtres et le gestionnaire de bureau ;
- les applications XWindow.
La figure suivante vous présente comment ces différentes couches logicielles s'agencent les unes par rapport aux autres.

Cette architecture est, comme on peut le voir, très avantageuse :
- les systèmes Unix, donc Linux, sont très structurés, donc plus simples à utiliser, à configurer, à maintenir et à développer ;
- ils sont très stables, car les composants de haut niveau n'interfèrent pas sur les composants de bas niveau ;
- ils sont faciles à personnaliser, puisque l'utilisateur a le choix des outils à chaque niveau ;
- Linux a de plus la particularité d'être parfaitement modifiable, puisque si l'on sait programmer, on peut personnaliser les composants du système ou en rajouter à tous les niveaux ;
- et il n'est pas propriétaire, c'est-à-dire que l'on n'est pas dépendant d'un éditeur de logiciel pour résoudre un problème donné.
En bref, c'est la voie de la vérité.
IV-B. Sécurité et utilisateurs▲
À l'heure où la sécurité devient un enjeu majeur en raison de l'importance des menaces virales et autres attaques contre les systèmes informatiques et leurs utilisateurs, les systèmes Unix tels que Linux, bien que de conception très ancienne, apparaissent comme avant-gardistes et parfaitement en phase avec le marché.
La sécurité est à présent considérée comme une fonctionnalité essentielle du système d'exploitation, et devient de plus en plus incontournable. De ce fait, il est nécessaire de présenter les concepts de sécurité utilisés par les systèmes Unix et Linux, afin que vous puissiez appréhender les risques et maîtriser toutes les principales fonctions de sécurité du système.
Nous verrons donc ces concepts de base dans un premier temps. Puis, nous nous intéresserons à la notion d'utilisateur, qui est à la base de la sécurité sous Unix. Enfin, nous verrons comment cette sécurité est assurée dans le système, en particulier au niveau du système de fichiers.
IV-B-1. Généralités▲
Les systèmes Unix, depuis leurs origines, ont toujours pris en compte les problèmes de sécurité. En particulier, les développeurs d'application Unix ont toujours fait attention à ce que leurs logiciels se comportent relativement bien en termes de sécurité. En pratique, bien que la sécurité des programmes soit loin d'être parfaite, surtout pour les plus anciens, des principes de base ont toujours été respectés, ce qui fait que les applications Unix ne font pas, en règle générale, n'importe quoi avec le système.
Ainsi, il est beaucoup plus facile de faire fonctionner une application Unix dans un contexte de sécurité restreint qu'une application Windows, car les développeurs de ces dernières ont longtemps été habitués à une très grande liberté et ont donc réalisé des applications qui ne peuvent pas être utilisées si elles n'ont pas les pleins pouvoirs. Les applications Unix qui se comportent mal sont donc très rares, ce qui fait que les systèmes Unix peuvent faire peu de cas d'elles et n'ont pas à maintenir une compatibilité ascendante avec elles. Les systèmes Unix ont donc un modèle de sécurité beaucoup plus simple et strict, et n'ont pas à s'embarrasser avec des techniques complexes et des circonvolutions insensées telles que la virtualisation de l'ensemble du système pour les applications afin d'assurer un semblant de sécurité tout en permettant la compatibilité ascendante.
Par ailleurs, la sécurité permet de protéger non seulement le système, mais aussi l'utilisateur de ses propres erreurs. En effet, le système est capable de se protéger contre les fausses manipulations de l'utilisateur. Cela peut être extrêmement utile avec les débutants, puisqu'ils peuvent expérimenter à loisir tout en étant sûrs qu'ils ne feront pas de bêtise irrémédiable. Ainsi, ils seront plus sereins et n'auront pas « peur de faire une bêtise ». Mais cela est très utile même pour les utilisateurs chevronnés, car tout le monde peut effectivement faire une erreur !
La sécurité permet également de protéger les données de chaque utilisateur vis-à-vis des autres. En effet, par défaut, les données d'un utilisateur ne peuvent pas être modifiées par un autre utilisateur. Vous n'aurez donc aucune crainte que vos chères têtes blondes puissent effacer ou détruire par mégarde votre correspondance professionnelle ou l'ensemble des photos de famille…
Enfin, ayant été prise en compte dès le départ, la sécurité sait se rendre très discrète sur les systèmes Unix, et bien que parfaitement fonctionnelle, elle n'ennuie pas l'utilisateur et reste facilement configurable. Ces deux aspects sont fondamentaux, car du coup, l'utilisateur n'a pas la tentation - ni le besoin - de tout désactiver pour faire fonctionner ses applications !
En résumé, la sécurité sous Linux, c'est :
- une fonctionnalité à part entière, qui est parfaitement intégrée dans le système ;
- un moyen de se protéger contre ses propres erreurs ainsi que celles des autres utilisateurs ;
- une facilité d'utilisation et une transparence qui la rendent utilisable en pratique sans perturber le travail de l'utilisateur.
IV-B-2. Notion d'utilisateur et d'administrateur▲
Linux dispose de plusieurs modèles de sécurité, mais, historiquement, la sécurité se base sur la notion d'utilisateur. Nous allons donc nous intéresser ici à la notion d'utilisateur, et voir comment cette notion peut être utilisée pour mettre en pratique les contrôles de sécurité du système.
Comme vous le savez sans doute déjà, Linux est un système multi-utilisateur. Cela signifie que plusieurs personnes peuvent utiliser l'ordinateur simultanément (et pas uniquement les unes à la suite des autres), et que le système se charge de faire respecter la loi entre elles. Le système protège les données de chaque utilisateur des actions que peuvent effectuer les autres utilisateurs. Il veille également à partager équitablement les ressources de la machine entre les utilisateurs, tant au niveau de la puissance de calcul qu'au niveau de la mémoire, du disque, des imprimantes, etc.
Note : Si vous vous demandez comment plusieurs personnes peuvent se partager le clavier et l'écran et ainsi utiliser l'ordinateur en même temps, la réponse est simple : ils ne le peuvent pas. Par contre, il est possible que plusieurs personnes soient connectées à l'ordinateur via le réseau, utilisant d'autres claviers et d'autres écrans (on appelle un couple clavier/écran un « terminal »). Il est de plus théoriquement possible de connecter plusieurs claviers, souris et écrans à une même unité centrale, même si ces configurations sont encore très rares et non standards. Les utilisateurs peuvent également lancer des programmes en arrière-plan, et laisser ces programmes tourner même lorsqu'ils ne sont plus connectés à l'ordinateur. Évidemment, cela nécessite que les programmes ainsi lancés ne soient pas interactifs. Autrement dit, ils doivent être capables de fonctionner sans intervention de celui qui les a lancés.
Ne croyez pas que ce dernier cas de situation est extrêmement rare. En effet, le système utilise des tâches qui tournent en arrière-plan dans des comptes dédiés et différents du vôtre, afin de prendre en charge certaines fonctionnalités ou de réaliser des opérations de maintenance.
En interne, le système affecte un numéro unique à chaque utilisateur afin de pouvoir l'identifier. Ce numéro d'utilisateur est défini lors de la création de son compte dans le système, et ne peut être modifié par la suite. Ainsi, toute action effectuée dans le système peut être rattachée à un utilisateur particulier. L'utilisation du système requiert donc que chaque utilisateur s'identifie au niveau du système avant toute autre opération. Généralement, cela se fait en indiquant son nom d'utilisateur, que l'on appelle classiquement le « login ». Bien entendu, afin d'éviter qu'un utilisateur puisse usurper l'identité d'un autre utilisateur, le système exige que l'utilisateur fournisse un mot de passe après s'être identifié pour s'authentifier.
La sécurité du système se base alors, lorsqu'une opération est exécutée, sur l'identité de l'utilisateur qui réalise cette commande et sur les droits dont cet utilisateur dispose sur les objets que cette commande doit manipuler. Par exemple, la suppression d'un fichier système ne peut pas être réalisée par un utilisateur lambda, parce que cet utilisateur n'a pas les droits de suppression (ni de modification d'ailleurs, et parfois même de lecture) sur ce fichier.
L'administration du système lui-même revient à la charge d'un utilisateur particulier. Cet utilisateur, classiquement nommé « root », a virtuellement tous les droits sur le système. C'est ce qu'on appelle l'administrateur du système, ou encore le super utilisateur. En interne, le super utilisateur est identifié par le numéro 0, qui lui est réservé. Ainsi, seul l'utilisateur dont le numéro est 0 peut modifier les fichiers de configuration du système.
Note : Bien entendu, travailler sous l'identité du super utilisateur est extrêmement dangereux, car dès lors tous les mécanismes de sécurité du système sont désactivés. Une erreur de manipulation avec cette identité peut donc être fatale et détruire complètement le système ! C'est pour cette raison que la plupart des distributions imposent de définir un compte utilisateur standard en plus du compte root, et que vous ne devriez travailler que sous ce compte. Ce n'est pas une restriction, c'est tout simplement pour votre bien. Ne vous inquiétez pas, comme il l'a déjà été dit plus haut, vous n'avez quasiment jamais besoin des droits administrateurs pour travailler sous Linux, parce que les applications sont en général conçues dès le départ pour être utilisables dans des comptes restreints. Alors n'ayez aucune crainte, et respectez les bonnes manières : ne travaillez jamais sous le compte root.
Les nouveaux utilisateurs de Linux qui ont fait leurs premiers pas en informatique sous Microsoft Windows ont souvent tendance à considérer cette recommandation comme un « faites ce que je dis, pas ce que je fais » et croient donc que les utilisateurs chevronnés ne la respectent pas. Qu'ils se détrompent, la plupart des utilisateurs de Linux respectent cette règle en permanence ! Ce n'est pas parce que ce n'est pas votre habitude que cette recommandation est un « on-dit ». D'ailleurs, elle est tellement importante que certaines distributions désactivent tout bonnement le compte administrateur. Il est donc tout simplement impossible de se connecter sous ce compte, même si l'on est la personne qui a installé le système ! Bien entendu, dans ce cas, les opérations d'administration sont toutes identifiées et nécessitent de fournir le mot de passe administrateur pour être exécutées.
En résumé, les mécanismes de sécurité basés sur la notion d'utilisateur fonctionnent selon les principes suivants :
- l'utilisateur doit s'identifier (généralement, en fournissant son identifiant d'utilisateur, ou « login ») et s'authentifier (classiquement en fournissant son mot de passe, ou « password ») lorsqu'il se connecte à l'ordinateur ;
- le noyau conserve pour chaque processus que l'utilisateur lance l'identité de cet utilisateur ;
- le noyau contrôle les droits de l'utilisateur à chaque accès d'une ressource de chaque programme de cet utilisateur (en particulier, comme nous allons le voir plus loin, au niveau des fichiers) ;
- le noyau assure une indépendance totale des processus, tant au niveau des zones de mémoire utilisées qu'au niveau de l'accès aux ressources de la machine. Un processus ne peut donc, par défaut, ni lire ni écrire dans la mémoire d'un autre processus, et les ressources de calcul ou d'entrée/sortie sont partagées entre les différents processus par les mécanismes du multitâche.
IV-B-3. La sécurité au niveau du système de fichiers▲
Nous avons vu que le noyau contrôlait les droits de l'utilisateur vis-à-vis des ressources qu'il manipulait pour chaque processus qu'il exécute. En particulier, l'accès à chaque fichier est contrôlé lors de l'ouverture de ce fichier par les processus de l'utilisateur. Ainsi, les données de chaque utilisateur sont protégées par le système, ainsi que les fichiers du système lui-même. De plus, comme l'accès aux périphériques se fait généralement par l'intermédiaire de fichiers spéciaux, les accès aux ressources matérielles sont également contrôlés via les mécanismes de sécurité du système de fichiers. Il est donc important de comprendre comment les systèmes de fichiers gèrent la sécurité.
IV-B-3-a. Les droits sur les fichiers▲
Les systèmes de fichiers définissent, pour chaque fichier, les droits auxquels un utilisateur peut prétendre. Ces droits comprennent la possibilité de lire ou écrire un fichier, d'accéder ou non à une ressource ou d'exécuter un programme. En pratique, chaque utilisateur peut définir les droits qu'il veut se donner sur ses propres fichiers, et surtout les droits qu'il veut donner aux autres utilisateurs du système sur ses fichiers. Par exemple, il peut protéger un fichier auquel il tient particulièrement en lecture seule, afin d'éviter de le détruire par inadvertance.
L'administrateur peut également créer un ou plusieurs « groupes » d'utilisateurs, afin que les utilisateurs puissent donner des droits spécifiques aux utilisateurs de ces groupes sur leurs fichiers. En pratique, cela se fait en fixant le groupe propriétaire du fichier, et en fixant les droits spécifiques à ce groupe sur le fichier.
Il est donc possible de définir les droits sur un fichier à trois niveaux différents :
- au niveau du propriétaire du fichier (par défaut, l'utilisateur qui l'a créé) ;
- au niveau du groupe propriétaire du fichier (par défaut, les fichiers créés par les utilisateurs appartiennent au groupe « users ») ;
- au niveau de tous les autres utilisateurs (c'est-à-dire les utilsateurs qui ne sont ni le propriétaire du fichier ni les utilisateurs du groupe du fichier).
En pratique, les droits des fichiers sont représentés par une série de lettres indiquant les droits de chacun des niveaux que l'on vient de voir. Le droit de lecture est représenté par la lettre 'r' (pour « Read only »), le droit d'écriture par la lettre 'w' (pour « Writeable »), et le droit d'exécution par la lettre 'x' (pour « eXecutable »). Le droit de lecture correspond à la possibilité d'ouvrir et de consulter un fichier, ou de lister le contenu d'un répertoire. Le droit d'écriture correspond à la possibilité de modifier un fichier, ou de créer ou supprimer un fichier d'un répertoire. Enfin, le droit d'exécution correspond à la possibilité d'exécuter un fichier contenant un programme, ou d'entrer dans un répertoire.
Par exemple, la liste des droits sur un fichier lisezmoi.txt appartenant à un hypothétique utilisateur Jean Dupont (dont le login serait jean) se présente comme suit dans la sortie de la commande ls -l lisezmoi.txt (qui, comme on le verra plus loin, permet d'afficher les informations de ce fichier) :
-rw-r--r-- 1 jean users 444 2006-12-10 08:42 lisezmoi.txtCe fichier appartient bien à l'utilisateur jean et au groupe users et a une taille de 444 octets. Les droits sont affichés au début de la ligne. Le premier groupe de droit (rw-) indique que l'utilisateur peut lire et écrire le fichier, mais pas l'exécuter. En effet, le tiret (-) indique que le droit d'exécution n'est pas donné. Les deuxième et troisième groupes de droits (r-- tous les deux) indiquent respectivement que les utilisateurs du groupe users et tous les autres utilisateurs n'ont que le droit de lecture. Le premier tiret au début de la ligne signifie que le fichier n'est pas un répertoire, dans le cas contraire il serait remplacé par la lettre 'd' (pour « Directory »).
Note : On notera que le fait d'avoir le droit d'écriture sur un fichier ne donne pas le droit de le supprimer (cependant, on peut le vider !). Pour cela, il faut avoir le droit d'écriture sur le répertoire contenant ce fichier. De même, il est possible d'obtenir la liste des fichiers d'un répertoire sans pouvoir s'y déplacer, ou encore de modifier un fichier sans pouvoir le lire. Comme on le voit, les droits d'accès aux fichiers et aux répertoires sont très souples.
Par défaut, lors de la création d'un fichier par un utilisateur, les droits de lecture et d'écriture sont donnés à cet utilisateur, et seuls les droits de lecture sont donnés au groupe du fichier et aux autres utilisateurs. Ainsi, tout le monde peut lire le fichier, mais seul son propriétaire peut le modifier. Cela correspond à l'usage classique sur un système multiutilisateur où les utilisateurs se connaissent et n'ont pas de fichiers confidentiels. Dans le cas contraire, l'utilisateur devra retirer les droits de lecture pour les autres utilisateurs (nous verrons comment faire cela plus loin).
Note : Comme vous pouvez le constater, les droits d'exécution ne sont pas donnés par défaut, même pour les fichiers binaires. Ainsi, le système ne se base pas sur le contenu du fichier, et, comme on l'a vu, encore moins sur son extension, pour déterminer si un fichier est exécutable ou non. Pour qu'un fichier soit exécutable, il faut lui donner explicitement les droits d'exécution !
Cela n'a l'air de rien, mais cette contrainte est un facteur de sécurité extrêmement important de nos jours. En effet, la plupart des virus de mail ne sont en fait rien d'autre que des chevaux de Troie transférés en pièce jointe, et qui ne peuvent s'exécuter que si l'utilisateur les lance explicitement. Sous Windows, le simple fait de double-cliquer sur une pièce jointe dont l'extension est exécutable lance effectivement le programme (c'est pour cela que les pièces jointes de ce type sont souvent filtrées maintenant). Sous Unix et Linux, cela ne fait strictement rien, même si c'est un programme, car pour l'exécuter, il faut d'abord l'enregistrer, modifier ses droits d'exécution explicitement, et l'exécuter. Ainsi, un utilisateur non averti n'a quasiment aucune chance de lancer un tel cheval de Troie par mégarde…
IV-B-3-b. Notion d'ACL▲
La notion de groupe d'utilisateurs que l'on vient de voir est généralement utilisée pour définir des classes d'utilisateurs, et attribuer un peu plus de privilèges que les utilisateurs normaux n'en disposent aux utilisateurs de ces classes, selon les nécessités.
Par exemple, l'administrateur peut n'autoriser l'accès au lecteur de CD-ROM qu'à quelques utilisateurs, en modifiant les droits sur le fichier spécial de périphérique permettant d'accéder au lecteur de CD-ROM. Premièrement, il crée un groupe d'utilisateurs « CD-ROM » et affecte le fichier spécial de périphérique du CD-ROM à ce groupe. Ensuite, il restreint les droits d'accès à ce fichier pour que seuls les membres de ce groupe puissent y accéder. Enfin, il place les utilisateurs autorisés à accéder au CD-ROM dans le groupe en question.
Toutefois, cette technique est relativement contraignante pour les utilisateurs, parce que la création d'un nouveau groupe d'utilisateurs est une opération privilégiée que seul l'administrateur du système peut réaliser d'une part, et parce qu'un utilisateur ne peut changer le groupe propriétaire d'un fichier que vers un groupe dont il fait lui-même partie, d'autre part. Enfin, un même fichier ne peut appartenir qu'à un seul groupe, et créer un groupe pour rassembler tous les utilisateurs de deux groupes n'est pas une solution très élégante. C'est pour cette raison que les systèmes de fichiers modernes intègrent la notion d'ACL (abréviation de l'anglais « Access Control List », c'est-à-dire les listes de contrôle d'accès).
Les ACL sont des listes d'informations décrivant les droits d'accès aux fichiers. Avec les ACLs, les droits ne sont pas définis pour chaque catégorie d'utilisateurs (propriétaire, groupe et autres), mais de manière plus fine, fichier par fichier, pour des utilisateurs et des groupes variés. De plus, les ACLs peuvent être manipulées par le propriétaire du fichier, donc sans avoir recours aux droits administrateur, ce qui résout le problème des groupes.
Note : La contrepartie de cette facilité est qu'il n'est pas toujours évident de contrôler la sécurité de manière globale avec les ACLs, puisqu'on ne peut plus retirer les droits d'un utilisateur sur tout un jeu de fichiers appartenant à un même groupe simplement en le supprimant de la liste des utilisateurs de ce groupe. Il n'est donc pas recommandé d'utiliser les ACLs pour définir les droits sur les fichiers systèmes, et de ne conserver cette fonctionnalité que pour que les utilisateurs puissent définir des droits plus fins sur leurs propres fichiers.
IV-B-3-c. Les attributs spéciaux des fichiers▲
Nous avons vu dans les sections précédentes que la notion d'utilisateur, couplée avec les droits sur les fichiers, permettait au noyau de fournir une sécurité sur les fichiers des utilisateurs et du système. En particulier, les processus lancés par l'utilisateur s'exécutent en son nom, et sont soumis aux mêmes restrictions que l'utilisateur qui les a lancés.
Il existe toutefois quelques programmes qui doivent faire exceptions à cette règle. Il s'agit généralement de programmes qui ont besoin des droits administrateurs pour réaliser une opération de reconfiguration sur le compte de l'utilisateur. C'est en particulier le cas de quelques commandes systèmes (comme passwd, qui permet de changer de mot de passe), qui peuvent être lancées par les utilisateurs, mais qui doivent s'exécuter au nom du système (dans le compte root).
Ces programmes sont bien entendu réalisés avec un grand soin, de telle sorte que l'on peut être sûr que l'utilisateur ne peut pas les utiliser dans le but de réaliser une opération à laquelle il n'a pas droit dans le compte administrateur. De ce fait, il est impossible à un utilisateur de violer les règles de sécurité du système.
Pour parvenir à ce comportement, les systèmes de fichiers utilisent des attributs spéciaux sur les fichiers exécutables de ces programmes. Ces attributs viennent en complément des droits d'accès que l'on a présentés dans les sections précédentes.
Le premier de ces attributs est le bit « setuid » (qui est l'abréviation de l'anglais « SET User IDentifier »). Il ne peut être placé qu'au niveau des droits du propriétaire sur le fichier. Il permet d'indiquer que le fichier est exécutable, et que lorsque le programme qu'il contient est lancé par un utilisateur, le processus correspondant s'exécute avec les droits du propriétaire du fichier et non pas avec ceux de l'utilisateur qui l'a lancé. Cependant, le système conserve tout de même le numéro de l'utilisateur réel qui a lancé le processus en interne, ce qui fait que le programme peut savoir par qui il a été lancé et au nom de qui il s'exécute effectivement.
Finalement, un processus dispose donc toujours de deux numéros d'utilisateur :
- le numéro de l'utilisateur réel (« real user id » en anglais), qui est le numéro de l'utilisateur qui a lancé le programme ;
- le numéro de l'utilisateur effectif (« effective user id » en anglais), qui est le numéro de l'utilisateur avec les droits duquel le processus fonctionne.
Le bit setuid permet donc simplement d'affecter le numéro du propriétaire du fichier au numéro d'utilisateur effectif du processus lorsqu'il est lancé. Le fait de conserver le numéro de l'utilisateur réel permet au programme de réaliser des vérifications de sécurité additionnelles. Par exemple, la commande passwd, qui permet de changer le mot de passe d'un utilisateur, a besoin des droits de l'utilisateur root pour enregistrer le nouveau mot de passe. Il dispose donc du bit setuid pour que tous les utilisateurs puissent l'utiliser. Cependant, même s'il s'exécute au nom de l'utilisateur root, il ne doit pas permettre à n'importe qui de changer le mot de passe des autres utilisateurs : seul l'utilisateur root a le droit de faire cette opération. Il utilise donc le numéro de l'utilisateur réel qui a lancé la commande pour savoir si c'est bien l'utilisateur root qui l'a lancé.
Le bit setuid est l'attribut le plus couramment utilisé, essentiellement pour certaines commandes systèmes. Il est représenté par la lettre 's' (comme « Setuid »), et il remplace le droit d'exécution ('x') des fichiers pour le propriétaire des fichiers (rappelons que le bit setuid implique que le fichier est exécutable). Il n'a aucune signification pour les répertoires.
Le deuxième attribut spécial est le bit « setgid » (qui est l'abréviation de l'anglais « SET Group IDentifier »). Ce bit fonctionne un peu de la même manière que le bit setuid, à ceci près qu'il fixe le numéro de groupe effectif du processus lancé à celui de son fichier exécutable. Cet attribut est également représenté par la lettre 's', et remplace le droit d'exécution ('x') pour les utilisateurs du groupe auquel appartient le fichier exécutable. De plus, et contrairement au bit setuid, ce bit a une signification pour les répertoires. Un répertoire disposant du bit setgid permet de faire en sorte que tous les fichiers qui sont créés dans ce répertoire se voient automatiquement attribués le même groupe que le répertoire. Ce bit est relativement peu utilisé.
Enfin, il existe un troisième attribut, le bit « sticky ». Cet attribut remplace l'attribut exécutable pour les autres utilisateurs que le propriétaire du fichier ou du répertoire et les membres du groupe auquel il appartient. Contrairement aux bits setuid et setgid, il est représenté par la lettre 't' (pour « sTickky »). Sa signification est assez spéciale : elle permet de faire en sorte que les programmes restent chargés en mémoire après leur terminaison, ce qui permet de les relancer plus rapidement. Afin de ne pas consommer la mémoire de manière permanente, le code du programme est placé automatiquement dans le swap s'il n'est toujours pas relancé après un certain temps, mais même dans ce cas, tous les calculs de chargement sont déjà effectués. Le lancement des programmes marqués de ce bit sera donc toujours accéléré. Sachez cependant ne pas abuser du bit sticky car la mémoire (même virtuelle) est encore une ressource rare. Pour les répertoires, sa signification est totalement différente : elle permet de restreindre les droits des utilisateurs sur les répertoires ayant ce bit positionné. Ce bit fait en sorte que même si un utilisateur dispose des droits d'écriture sur le répertoire, il ne peut pas supprimer tous les fichiers de ce répertoire. Les seuls fichiers qu'il est autorisé à supprimer sont ses propres fichiers. Bien entendu, il est toujours possible d'ajouter des fichiers dans le répertoire en question.
Les questions qui se posent évidemment sont les suivantes. Est-ce qu'un particulier a besoin de tout cela ? Ces fonctionnalités ne sont-elles pas réservées aux serveurs ? Est-ce qu'on ne risque pas de perdre beaucoup de temps pour définir les droits pour chaque utilisateur et pour chaque ressource du système ? La gestion de la sécurité ne consomme-t-elle pas trop de ressources ? Ces questions sont légitimes. Heureusement, les réponses sont simples. Rappelons pour commencer qu'il est très intéressant, même pour un particulier, de disposer de ces fonctionnalités. En effet, la sécurité permet tout simplement de protéger le système contre les erreurs des utilisateurs, voire l'utilisateur lui-même de ses propres erreurs. Ainsi, avec Linux, on peut faire n'importe quoi, on est certain que le système restera intact. Cette sécurité est telle que, finalement, Linux est justement le système d'exploitation idéal pour apprendre l'informatique à quelqu'un : savoir que le système protège tout ce qui est important permet aux débutants de prendre des initiatives sans crainte. Quant aux éventuels revers de médaille, ils sont absents : la gestion de la sécurité ne consomme quasiment aucune ressource, et sa configuration est élémentaire. Toutes les distributions s'installent de telle sorte que le système se protège des utilisateurs, et que ceux-ci soient indépendants les uns des autres. En pratique, les utilisateurs n'ont tout simplement pas à se soucier de tous ces attributs de fichiers. Même l'administrateur laisse souvent les attributs par défaut définis par les distributions, car ils correspondent à la majorité des besoins de sécurité.
IV-C. Fonctionnalités des systèmes de fichiers▲
Les systèmes de fichiers Unix sont des systèmes de fichiers extrêmement évolués, qui fournissent à la fois d'excellentes performances, une grande sécurité, et des fonctionnalités puissantes. Peu d'utilisateurs savent exactement quels sont les services qu'ils peuvent fournir en général, et beaucoup croient que les systèmes de fichiers savent juste stocker des données dans des fichiers organisés dans une hiérarchie de répertoires. Mais nous allons voir qu'ils permettent de faire beaucoup mieux que cela !
IV-C-1. Le système de fichiers virtuel▲
Pour commencer, il faut préciser que Linux ne travaille pas directement avec les systèmes de fichiers physiques. En effet, il interpose systématiquement un système de fichiers intermédiaire, nommé « Virtual File System » (« VFS » en abrégé), qui permet aux applications d'accéder à différents systèmes de fichiers de manière indépendante de leur nature et de leur structure interne. Le système de fichiers virtuel ne fait pas grand-chose en soi : il se contente de transférer les requêtes des applications vers les systèmes de fichiers réels. Il fournit donc une interface bien définie pour les applications, que celles-ci doivent utiliser. Les systèmes de fichiers réels, quant à eux, doivent simplement fournir les services dont le système de fichiers virtuel a besoin. Tous les systèmes de fichiers réels ne disposent toutefois pas forcément de toutes les fonctionnalités demandées par le système de fichiers virtuel. Dans ce cas de configuration, la requête de l'application désirant effectuer l'opération manquante échouera tout simplement.
Comme on peut le constater, cette architecture est modulaire. Et comme on l'a vu pour l'architecture du système en général, cela apporte beaucoup de bénéfices. Les plus évidents sont indiqués ci-dessous :
- Linux est capable de gérer plusieurs systèmes de fichiers réels. La seule condition est qu'ils doivent tous fournir les services de base exigés par le système de fichiers virtuel ;
- les applications peuvent utiliser plusieurs de ces systèmes de fichiers réels de manière uniforme, puisqu'elles n'utilisent que le système de fichiers virtuel. Cela simplifie leur programmation, et permet d'éviter autant de bogues potentiels ;
- chaque système de fichiers réel étant indépendant des autres, il ne perturbe pas leur fonctionnement. En particulier, un système de fichiers corrompu ne corrompt pas les autres.
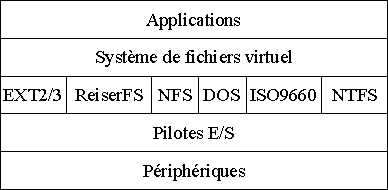
Avec cette architecture, un grand nombre de systèmes de fichiers ont été développés pour Linux. Parmi ces systèmes de fichiers, on retrouve les plus connus, à savoir :
- le système de fichiers EXT2, qui est le système de fichiers natif de Linux ;
- le système de fichiers EXT3, qui est une évolution du système de fichiers EXT2 capable de prendre en charge également les mécanismes de journalisation (voir la note ci-dessous pour savoir ce qu'est la journalisation d'un système de fichiers) ainsi que les blocs défectueux sur le support physique ;
- le système de fichiers ReiserFS, qui supprime la notion de bloc disque et qui est également journalisé ;
- les systèmes de fichiers FAT, FAT32 et FAT32X (utilisés par les systèmes DOS et Windows, ainsi que par les clefs USB et les cartes mémoire) ;
- le système de fichiers NTFS (utilisé par Windows NT, Windows 2000 et XP), en lecture et partiellement en écriture (seul l'écrasement des données existantes dans un fichier, sans redimensionnement, est autorisé à l'heure actuelle) ;
- le système de fichiers ISO9660, qui est utilisé par tous les CD-ROM. Les extensions permettant de gérer les noms longs sont également gérées. Ces extensions comprennent en particulier le système de fichiers Joliet (extensions de Microsoft pour Windows 95) et Rock Ridge (extensions utilisées par tous les systèmes Unix) ;
- le système de fichiers NFS (utilisé pour distribuer sur un réseau un système de fichiers).
Note : La journalisation consiste à écrire sur le disque toutes les opérations en cours à chaque instant. Ainsi, lorsqu'un redémarrage intempestif se produit, le système peut ramener rapidement la structure de données du système de fichiers dans un état cohérent. La journalisation accroît donc encore à la fiabilité du système de fichiers.
Linux gère également d'autres systèmes de fichiers natifs ou utilisés par d'autres systèmes d'exploitation (Unix ou non). Il permet même d'intégrer des pseudo systèmes de fichiers générés par le noyau. Ces systèmes de fichiers sont complètement fictifs : leur structure et leurs fichiers sont générés dynamiquement par le noyau lorsqu'une application y accède. Ils sont principalement utilisés pour fournir aux applications des informations que le noyau met à leur disposition, pour réaliser des systèmes de fichiers en mémoire, et pour gérer l'ensemble des fichiers spéciaux de périphériques installés sur l'ordinateur.
Les systèmes de fichiers natifs de Linux sont de loin les systèmes de fichiers les plus fonctionnels, les plus fiables et les plus courants. Le choix du système de fichiers dépend donc généralement de l'usage que l'on en fera, certains systèmes de fichiers étant plus appropriés pour certains types d'utilisation. Si l'on recherche essentiellement la stabilité, je recommande le système de fichiers EXT3, car c'est pour l'instant le seul système de fichiers capable de prendre en compte les blocs défectueux sur le support physique.
Quoi qu'il en soit, on ne pourra installer Linux que sur un système de fichiers de type Unix. Ces systèmes de fichiers sont tous plus fonctionnels et plus performants que les systèmes de fichiers FAT. Leurs principales fonctionnalités sont les suivantes :
- les accès aux fichiers sont rapides, même plus rapides que les systèmes de fichiers basés sur la FAT sous Windows, qui pourtant ne gèrent pas les droits des utilisateurs ni les autres fonctionnalités avancées des systèmes de fichiers Unix ;
- la fragmentation des fichiers est quasiment inexistante. En fait, la fragmentation des fichiers existe effectivement, mais les algorithmes utilisés par les systèmes de fichiers pour allouer les blocs du disque dur lors de l'écriture dans un fichier sont suffisamment évolués pour éviter qu'elle ne se produise de manière trop importante. De plus, les algorithmes de lecture anticipée des blocs et de mise en mémoire cache des données lues du sous-système d'entrée/sortie masquent complètement les latences dues à la fragmentation. De ce fait, en pratique, la fragmentation n'a pas d'impact sur les performances du système, et peut être tout simplement ignorée. Pour donner un ordre de grandeur, après installation, suppression, manipulation d'un grand nombre d'applications et de petits fichiers sur une partition EXT2 de 800 Mo, le tout réalisé par plusieurs processus fonctionnant en même temps, la fragmentation reste inférieure à 1% sur 57571 fichiers (sur un total de 249856 fichiers que le système de fichiers pourrait contenir) ;
- quant à la fiabilité, elle est gérée grâce à un stockage redondant des principales structures de données internes. Ainsi, si une erreur apparaît dans le système de fichiers, les parties défectueuses peuvent être reconstituées à partir des informations sauvegardées. Cette réparation est réalisée automatiquement à chaque redémarrage de la machine si nécessaire.
IV-C-2. Liens symboliques et liens physiques▲
Une fonctionnalité intéressante fournie par les systèmes de fichiers Unix est la possibilité de réaliser des liens sur des fichiers ou des répertoires.
Un lien est une référence à un fichier ou un répertoire existant, qui peut être manipulé exactement comme sa cible. Il existe deux sortes de liens : les liens physiques, qui sont réellement une référence sur les données du fichier au niveau de la structure même du système de fichiers, et les liens symboliques, qui ne sont rien d'autre qu'un fichier additionnel contenant les informations nécessaires pour retrouver la cible.
Les liens physiques présentent les inconvénients de ne pas pouvoir référencer des répertoires, et de ne pouvoir référencer que des objets du même système de fichiers que celui dans lequel ils sont créés. La limitation sur les répertoires permet d'éviter de construire des cycles dans la structure du système de fichiers. Quant à la limitation à la frontière des systèmes de fichiers, elle est obligatoire puisque les liens physiques sont gérés directement au niveau de la structure du système de fichiers. En revanche, ils présentent des avantages certains :
- le déplacement des cibles ne les perturbe pas si celles-ci restent dans le même système de fichiers, parce que dans ce cas les données ne sont pas déplacées sur le disque ;
- la suppression de la cible ne détruit pas le lien physique. Tous les liens physiques sur un fichier partagent la même structure de données du système de fichiers, et celle-ci n'est réellement détruite qu'à la destruction du dernier lien physique.
En fait, toute entrée de répertoire est un lien physique sur le contenu du fichier. Le fait d'avoir plusieurs liens physiques sur les mêmes données correspond à disposer de plusieurs entrées de répertoire donnant accès aux mêmes données dans le système de fichiers. Il serait possible de créer des liens physiques dans un système de fichiers FAT, mais ils seraient interprétés comme des références croisées par les outils de vérification de disque. Le système de fichiers FAT de Linux interdit donc la création des liens physiques, tout comme le font DOS et Windows.
Les liens symboliques, quant à eux, permettent de référencer des fichiers ou des répertoires se trouvant dans d'autres systèmes de fichiers que le leur. C'est pour cette raison qu'ils sont très couramment utilisés (en fait, les liens physiques ne sont quasiment pas utilisés, parce qu'il est très courant de faire un lien sur un répertoire, ce que seuls les liens symboliques savent faire). En revanche, ils sont extrêmement dépendants de leur cible : si elle est supprimée ou déplacée, tous les liens symboliques qui s'y réfèrent deviennent invalides.
La référence sur le fichier ou le répertoire cible contenue dans les liens symboliques peut être soit relative à l'emplacement de leur cible, soit absolue dans le système de fichiers. Chacune de ces méthodes a ses avantages et ses inconvénients : les liens symboliques qui contiennent des références relatives ne sont pas brisés lors d'un déplacement de la cible, pourvu qu'ils soient déplacés également et restent à la même position relative par rapport à celle-ci dans la hiérarchie du système de fichiers. En revanche, ils sont brisés s'ils sont déplacés et que la cible ne l'est pas. Les liens symboliques utilisant des références absolues sont systématiquement brisés lorsque la cible est déplacée, mais ils restent valides lorsqu'ils sont eux-mêmes déplacés. Comme en général c'est le comportement que l'on recherche, les liens symboliques sont toujours créés avec des références absolues, mais vous êtes libre de faire autrement si vous en ressentez le besoin. Sachez cependant que déplacer une source de données n'est jamais une bonne idée. Le tableau suivant récapitule les avantages et les inconvénients des différents types de liens :
Tableau 4-1. Caractéristiques des liens physiques et symboliques
|
Fonctionnalité |
Liens physiques |
Liens symboliques |
|
|
Référence relative |
Référence absolue |
||
|---|---|---|---|
|
Peuvent être déplacés |
Oui |
Avec la cible |
Oui |
|
Suivent la cible |
Oui |
Si déplacés avec elle |
Non |
|
Gèrent la suppression de la cible |
Oui |
Non |
Non |
|
Peuvent référencer des cibles sur un autre système de fichiers |
Non |
Oui |
Oui |
|
Peuvent référencer des répertoires |
Non |
Oui |
Oui |
IV-C-3. Autres fonctionnalités▲
Les systèmes de fichiers de Linux fournissent également des fonctionnalités qui peuvent être intéressantes, mais que l'on utilise généralement moins souvent.
La première de ces fonctionnalités est les quotas. Ceux-ci permettent de définir la proportion d'espace disque que chaque utilisateur peut consommer dans le système de fichiers. Ainsi, il est possible de restreindre les utilisateurs et d'éviter qu'un seul d'entre eux ne consomme l'ensemble des ressources disque. En pratique, cette fonctionnalité n'est pas d'une grande utilité pour un particulier, qui souvent est le seul utilisateur de sa machine.
Note : Sachez toutefois que les systèmes de fichiers réservent généralement une petite partie (environ 5%) de l'espace disque pour l'administrateur du système, afin de s'assurer que celui-ci pourra toujours effectuer les opérations de maintenance en cas de saturation du système de fichiers. Cet espace libre est également utilisé pour les mécanismes de défragmentation automatique des systèmes de fichiers.
Les systèmes de fichiers permettent également d'enregistrer des informations complémentaires sur les fichiers, afin par exemple de pouvoir les marquer pour un traitement spécifique. Ces informations complémentaires sont stockées sous la forme « d'attributs », pouvant contenir virtuellement n'importe quel type d'information. Certains systèmes de fichiers utilisent cette fonctionnalité pour implémenter les mécanismes de sécurité basés sur les ACL.
Enfin, les systèmes de fichiers Unix sont également capables de prendre en charge ce que l'on appelle les fichiers « troués » (« sparse files » en anglais). Ces fichiers sont des fichiers contenant des données séparées par de grands espaces vides. On peut donc dire qu'ils sont « presque vides ». Pour ces fichiers, il est évident qu'il est inutile de stocker les espaces vides sur le disque. Les systèmes de fichiers mémorisent donc tout simplement qu'ils contiennent des trous, et ils ne stockent que les données réelles et la position des trous avec leurs tailles. Cela constitue une économie de place non négligeable. Les applications classiques des fichiers presque vides sont les bases de données, qui utilisent souvent des fichiers structurés contenant relativement peu de données effectives, et les images disque pour installer des systèmes d'exploitation dans des machines virtuelles.
IV-D. Structure du système de fichiers▲
Nous allons à présent nous intéresser à l'organisation du système de fichiers de Linux. Ce système de fichiers contient un certain nombre de répertoires et de fichiers standards, qui ont chacun une fonction bien définie. Cette structure standard permet de gérer tous les systèmes Linux de manière homogène : les programmes savent où trouver ce dont ils ont besoin. Ils sont donc portables d'un système à un autre, et les utilisateurs ne sont pas dépaysés lorsqu'ils changent de machine (en fait, cette structure est à peu près la même pour tous les systèmes Unix, ce qui donne encore plus de poids à l'argument précédent).
Cette organisation standard du système de fichiers a été conçue de telle manière que les données et les programmes sont placés chacun à leur place, et qu'ils puissent être facilement intégrés dans un réseau. L'intégration dans un réseau sous-entend que les fichiers des programmes peuvent être partagés par les différentes machines de ce réseau, ce qui permet d'économiser beaucoup de place. De plus, il est possible d'accéder à la plupart des ressources du système grâce à une interface uniforme. En particulier, il est possible d'accéder à tous les périphériques installés sur l'ordinateur par l'intermédiaire de fichiers spéciaux, et on peut récupérer des informations sur le système mises à disposition par le noyau simplement en lisant des fichiers générés par un pseudo système de fichiers. Le tableau suivant décrit les principaux éléments de l'arborescence du système de fichiers de Linux.
Tableau 4-2. Hiérarchie standard du système de fichiers
|
Répertoire |
Signification |
|
/ |
Répertoire racine. Point de départ de toute la hiérarchie du système de fichiers. Le système de fichiers contenant ce répertoire est monté automatiquement par le noyau pendant l'amorçage du système. Ce système de fichiers est appelé système de fichiers racine (« root » en anglais). |
|
/boot/ |
Répertoire contenant le noyau de Linux et ses informations de symboles. Ce répertoire est parfois le point de montage d'un système de fichiers de très petite taille, dédié au noyau. Dans ce cas, il est recommandé que le système de fichiers correspondant soit monté en lecture seule. On notera que sur certains systèmes, le noyau reste placé dans le répertoire racine. Cette technique n'est pas recommandée, car on ne peut pas monter en lecture seule la partition racine en utilisation normale du système. |
|
/boot/vmlinuz |
Noyau compressé de Linux. Les noyaux compressés se décompressent automatiquement lors de l'amorçage du système. Sur certains systèmes, le noyau est encore placé dans le répertoire racine du système de fichiers. |
|
/boot/System.map |
Fichier système contenant la liste des symboles du noyau. Ce fichier est utilisé par certains programmes donnant des renseignements sur le système. En particulier, il est utilisé par le programme « top » (programme qui indique la liste des principaux processus actifs) afin de donner le nom de la fonction du noyau dans lequel un processus se trouve bloqué lorsqu'il est en attente de la fin d'une opération que le noyau doit exécuter pour lui. |
|
/dev/ |
Répertoire contenant tous les fichiers spéciaux permettant d'accéder aux périphériques. Comme on l'a vu, hormis les interfaces réseau, les périphériques sont généralement accessibles au travers de fichiers spéciaux. Ces fichiers permettent l'envoi et la réception des données vers les périphériques associés, et ce de manière uniforme. Tous ces fichiers spéciaux sont tous placés dans le répertoire /dev/. Généralement, le répertoire /dev/ est un système de fichiers virtuel (c'est-à-dire un système de fichiers qui est complètement géré en mémoire par le noyau), qui est rempli dynamiquement par le système en fonction du matériel installé. Le répertoire /dev/ ne contient donc que les fichiers spéciaux des périphériques pour lesquels le noyau dispose effectivement d'un pilote de périphérique chargé. Toutefois, il est également possible que ce répertoire soit effectivement prérempli avec les fichiers spéciaux de la plupart des périphériques existants sur le marché, même ceux qui ne sont pas physiquement présents dans la machine. Dans ce cas, les opérations sur les fichiers spéciaux des périphériques non installés seront tout simplement refusées par le noyau. Ce type de configuration se rencontre encore assez souvent sur des installations assez anciennes. Quoi qu'il en soit, quelle que soit la technique utilisée, ce répertoire doit être impérativement placé dans le système de fichiers racine. |
|
/sbin/ |
Répertoire contenant les commandes systèmes nécessaires à l'amorçage et réservées à l'administrateur. Ce répertoire doit être impérativement placé dans le système de fichiers racine. En général, seul l'administrateur utilise ces commandes. |
|
/bin/ |
Répertoire contenant les commandes systèmes générales nécessaires à l'amorçage. Ce répertoire doit être impérativement placé dans le système de fichiers racine. Tous les utilisateurs peuvent utiliser les commandes de ce répertoire. |
|
/lib/ |
Répertoire contenant les bibliothèques partagées (« DLL » en anglais, pour « Dynamic Link Library ») utilisées par les commandes du système des répertoires /bin/ et /sbin/. Ce répertoire doit être impérativement placé dans le système de fichiers racine. |
|
/lib64/ |
Sur les systèmes 64 bits basés sur une architecture x86_64 (processeurs AMD Athlon64 ou ultérieurs, ou processeurs Intel avec jeu d'instruction EMT64), répertoire équivalent au répertoire /lib/ pour les bibliothèques 64 bits natives. Ces machines étant capables d'exécuter des programmes 32 bits en plus des programmes natifs 64 bits, il est nécessaire de fournir deux jeux de bibliothèques pour les deux modes de fonctionnement. Normalement, le répertoire /lib/ devrait être utilisé pour les bibliothèques natives, mais il est d'usage de continuer à y placer les bibliothèques 32 bits pour des raisons de compatibilité ascendante, les programmes 32 bits cherchant naturellement leurs bibliothèques dans ce répertoire. |
|
/lib32/ |
Sur les systèmes 64 bits natifs basés sur une architecture x86_64 (processeurs AMD Athlon64 ou ultérieurs, ou processeurs Intel avec jeu d'instruction EMT64), répertoire des bibliothèques 32 bits si les bibliothèques 64 bits natives sont placées dans le répertoire /lib/. Attention, sur les systèmes qui utilisent ce type d'organisation, les paquetages 32 bits natifs ne peuvent pas être installés sans modification, car ils placeraient leurs bibliothèques 32 bits dans le répertoire /lib/, qui contient dans ce cas des bibliothèques 64 bits. Réaliser une installation de paquetages non modifiés dans ces conditions peut écraser les bibliothèques 64 bits natives et donc provoquer de graves dysfonctionnements. |
|
/lib/modules/ |
Ce répertoire contient les modules additionnels du noyau. Les modules sont des composants logiciels du noyau, mais qui ne sont pas chargés immédiatement pendant la phase d'amorçage du système. Ils peuvent en revanche être chargés et déchargés dynamiquement, lorsque le système est en fonctionnement. Il est fortement recommandé que ce répertoire soit placé dans le système de fichiers racine. |
|
/etc/ |
Répertoire contenant tous les fichiers de configuration du système. Ce répertoire doit être impérativement placé dans le système de fichiers racine. |
|
/etc/X11/ |
Répertoire contenant les fichiers de configuration de l'environnement graphique XWindow. |
|
/etc/rc.d/ |
Répertoire contenant les scripts de démarrage du système. Ces scripts sont exécutés lorsque le système démarre ou s'arrête, ainsi que lorsqu'il change de mode de fonctionnement. Il est également possible de les exécuter pour démarrer ou arrêter un service particulier. Dans certaines distributions, ces fichiers sont placés dans le répertoire /sbin/init.d/. |
|
/etc/opt/ |
Répertoire contenant les fichiers de configuration des applications. |
|
/tmp/ |
Répertoire permettant de stocker des données temporaires. En général, /tmp/ ne contient que des données très éphémères. Il est préférable d'utiliser le répertoire /var/tmp/. En effet, le répertoire /tmp/ ne dispose pas nécessairement de beaucoup de place disponible. |
|
/usr/ |
Répertoire contenant les fichiers du système partageables en réseau et en lecture seule. |
|
/usr/bin/ |
Répertoire contenant la plupart des commandes des utilisateurs et des logiciels installés. |
|
/usr/sbin/ |
Répertoire contenant les commandes systèmes non nécessaires à l'amorçage. Ces commandes ne sont normalement utilisées que par l'administrateur système. |
|
/usr/lib/ |
Répertoire contenant les bibliothèques partagées de tous les programmes de /usr/bin/ et /usr/sbin/ et les bibliothèques statiques pour la création de programmes. |
|
/usr/lib64/ |
Sur les systèmes 64 bits basés sur une architecture x86_64 (processeurs AMD Athlon64 ou ultérieurs, ou processeurs Intel avec jeu d'instruction EMT64), répertoire équivalent au répertoire /usr/lib/ pour les bibliothèques 64 bits natives. La raison pour laquelle les bibliothèques 64 bits natives de ces systèmes n'est pas placée dans le répertoire /usr/lib/ est la même que pour les bibliothèques du répertoire /lib64/. |
|
/usr/lib32/ |
Sur les systèmes 64 bits natifs basés sur une architecture x86_64 et utilisant le répertoire /usr/lib/ pour les bibliothèques 64 bits natives, répertoire contenant les bibliothèques 32 bits. Les mêmes précautions d'usage que celles indiquées pour le répertoire /lib32/ s'appliquent ici. |
|
/usr/include/ |
Répertoire contenant les fichiers d'en-têtes du système pour le compilateur C/C++. Les fichiers de ce répertoire sont utilisés pour réaliser des programmes dans les langages de programmation C et C++. |
|
/usr/X11/ |
Répertoire historique qui contenait l'environnement graphique X11 et ses applications sur les anciennes distributions. Dans les distributions récentes (environnement X11 basé sur X.org de version 7.0 ou plus), X11 est à présent directement installé dans le répertoire /usr/, et ce répertoire n'est plus conservé qu'à titre de compatibilité sous la forme de liens symboliques. Ce répertoire contient des sous-répertoires bin/, lib/ et include/, où se trouvent les exécutables de XWindow, les bibliothèques et les fichiers d'en-têtes pour créer des programmes pour XWindow en C et C++. |
|
/usr/share/ |
Répertoire contenant l'ensemble des données et des fichiers partagés par les applications du système. C'est ici que sont par exemple stockées les polices de caractères, les sons et les images utilisés par les environnements de bureau, les fonds d'écran, les fichiers d'aide ou encore les associations de fichiers avec leurs extensions. |
|
/usr/src/ |
Répertoire contenant les fichiers sources du noyau et des applications de la distribution. Normalement, ce répertoire ne doit contenir que le code source des applications dépendantes de la distribution que vous utilisez. |
|
/usr/src/linux/ |
Sources du noyau de Linux. Il est vivement recommandé de conserver les sources du noyau de Linux sur son disque, afin de pouvoir changer la configuration du système à tout moment. |
|
/usr/local/ |
Répertoire contenant les programmes d'extension du système indépendants de la distribution. Ce n'est toutefois pas le répertoire d'installation des applications, que l'on installera en général dans le répertoire /opt/. « local » ne signifie pas ici que les programmes qui se trouvent dans ce répertoire ne peuvent pas être partagés sur le réseau, mais plutôt que ce sont des extensions du système qu'on ne trouve donc que localement sur un site donné. Ce sont donc les extensions qui ne font pas partie de la distribution de Linux utilisée, et qui doivent être conservées lors des mises à jour ultérieures de cette distribution. Ce répertoire contient les sous-répertoires bin/, lib/, include/ et src/, qui ont la même signification que les répertoires du même nom de /usr/, à ceci près qu'ils ne concernent que les extensions locales du système, donc indépendantes de la distribution. |
|
/var/ |
Répertoire contenant toutes les données variables du système. Ce répertoire contient les données variables qui ne pouvaient pas être placées dans le répertoire /usr/, puisque celui-ci est normalement accessible en lecture seule. |
|
/var/tmp/ |
Répertoire contenant les fichiers temporaires. Il est préférable d'utiliser ce répertoire plutôt que le répertoire /tmp/. |
|
/var/opt/ |
Répertoire contenant les données variables des applications. |
|
/var/log/ |
Répertoire contenant les traces de tous les messages système. C'est dans ce répertoire que l'on peut consulter les messages d'erreurs du système et des applications. |
|
/var/spool/ |
Répertoire contenant les données en attente de traitement. Les travaux d'impression en cours, les mails et les fax en attente d'émission, les travaux programmés en attente d'exécution sont tous stockés dans ce répertoire. |
|
/var/locks/ |
Répertoire contenant les verrous sur les ressources système. Certaines ressources ne peuvent être utilisées que par une seule application (par exemple, un modem). Les applications qui utilisent de telles ressources le signalent en créant un fichier de verrou dans ce répertoire. |
|
/var/cache/ |
Répertoire contenant les données de résultats intermédiaires des applications. Les applications qui doivent stocker des résultats intermédiaires doivent les placer dans ce répertoire. |
|
/opt/ |
Répertoire historique contenant les applications qui ne font pas réellement partie du système d'exploitation. En particulier, sur les anciennes distributions, le gestionnaire de bureau KDE était installé dans le sous-répertoire /opt/kde/, mais à présent il est considéré comme partie intégrante du système et est donc installé directement dans le répertoire /usr/ sur les distributions récentes. |
|
/home/ |
Répertoire contenant les répertoires personnels des utilisateurs. Il est fortement recommandé de placer ce répertoire dans un système de fichiers indépendant de ceux utilisés par le système. Cela permet de faire des sauvegardes plus facilement, et de faire les mises à jour du système de manière sûre, sans craindre de perdre les données des utilisateurs. |
|
/root/ |
Répertoire contenant le répertoire personnel de l'administrateur. Il est donc recommandé que le répertoire personnel de l'administrateur soit placé en dehors de /home/ pour éviter qu'un problème sur le système de fichiers des utilisateurs ne l'empêche de travailler. Toutefois, il est important que l'administrateur puisse travailler même si les répertoires /root/ et /home/root/ ne sont pas présents. Dans ce cas, son répertoire personnel sera le répertoire racine. |
|
/media/ |
Répertoire réservé au montage des systèmes de fichiers sur périphériques amovibles (CD-ROM, disquettes, etc.). Ce répertoire peut contenir plusieurs sous-répertoires pour chaque périphérique amovible, afin de permettre d'en monter plusieurs simultanément. Notez qu'il est assez courant de disposer de liens symboliques dans la racine référençant les principaux systèmes de fichiers, afin d'en simplifier l'accès. Par exemple, il est courant d'avoir un répertoire /floppy/ référençant le lecteur de disquette et un répertoire /cdrom/ référençant le lecteur de CD-ROM. |
|
/mnt/ |
Répertoire réservé à l'administrateur pour le montage temporaire des systèmes de fichiers lors de leur maintenance (disques d'installation, disques durs externes qui ne doivent pas être manipulables par les utilisateurs, etc.). Ce répertoire peut contenir plusieurs sous-répertoires pour chaque périphérique hébergeant les systèmes de fichiers en question, afin de permettre d'en monter plusieurs simultanément. Notez que ce répertoire contenait historiquement les mêmes entrées que le répertoire /media/, qui a été introduit récemment afin de séparer les opérations de montage réalisées dans un but purement administratif des opérations de montage réalisées dans un contexte d'utilisation normale des systèmes de fichiers sur périphériques amovibles. |
|
/lost+found/ |
Répertoire contenant les données récupérées lors de la réparation d'un système de fichiers endommagé. Ces données sont écrites par les utilitaires de vérification et de réparation des systèmes de fichiers lorsqu'ils trouvent des informations qui ne peuvent être rattachées à aucun fichier existant, ainsi, il est possible de récupérer ces informations si elles ne sont pas dans un état de détérioration trop avancé. |
|
/proc/ |
Répertoire contenant le pseudo système de fichiers du noyau. Ce pseudo système de fichiers contient des fichiers permettant d'accéder aux informations sur le matériel, la configuration du noyau et sur les processus en cours d'exécution. |
|
/sys/ |
Répertoire contenant le pseudo système de fichiers des gestionnaires de périphériques. Ce pseudo système de fichiers contient des fichiers permettant d'obtenir des informations sur l'ensemble des objets du noyau, en en particulier sur l'ensemble des périphériques de l'ordinateur. Ce système de fichiers est appelé à recevoir une bonne partie des informations exposées par le système de fichiers /proc/, dont le rôle se restreindra sans doute à fournir des informations plus générales et à réaliser la configuration des fonctions générales du système. |
Note : Les informations données ici peuvent ne pas être correctes pour votre distribution. En effet, certaines distributions utilisent une structure légèrement différente. Les informations données ici sont conformes à la norme de hiérarchie de systèmes de fichiers version 2.3 (« FHS » en anglais). Vous pouvez consulter ce document pour une description exhaustive du système de fichiers de Linux.
Vous avez pu constater que les répertoires bin/, lib/, include/ et src/ apparaissent régulièrement dans la hiérarchie du système de fichiers. Cela est normal : les répertoires sont classés par catégorie d'applications et par importance. Les répertoires bin/ contiennent en général les programmes, et les répertoires lib/ les bibliothèques partagées par ces binaires. Cependant, les répertoires lib/ peuvent aussi contenir des bibliothèques statiques, qui sont utilisées lors de la création de programmes. En général, tous les systèmes Unix fournissent en standard un compilateur pour générer ces programmes. Dans le cas de Linux, ce compilateur est « gcc » (pour « GNU C Compiler »). La création d'un programme nécessite que l'on dispose des fichiers source, qui contiennent le programme écrit dans un langage de programmation, des fichiers d'en-têtes, qui contiennent les déclarations de toutes les fonctions utilisables, et des fichiers de bibliothèques statiques, contenant ces fonctions. Ces différents fichiers sont stockés respectivement dans les répertoires src/, include/ et lib/. Les notions de sources et de compilation seront décrites en détail dans le Chapitre 7.