


5. Chapitre 5 - Développer !▲
| % Les 5 premières lignes du source TeX \chapter{Développer !} \label{chap-developper} \begin{epigraphe}{\recursion} \verb&\verb@\verb|\verb#\verb°\verb/\verb+% Les 5 premières+\\/°#|@& \recursion. |
Développer de to develop, « mettre au point » en anglais, est peut-être l'activité qu'il est idéal de réaliser sous un système unix. Il dispose en effet d'une palette impressionnante d'outilsChapitre 2 - Petit guide de survie - dédiés à une tâche spécifique - qu'on peut voir comme des composants logiciels pouvant communiquer entre eux de manière élégante et homogène. Nous verrons en ouverture de ce chapitre une présentation détaillée des concepts fondamentaux de la programmation en shell ; la partie suivante est consacrée à l'étude de l'utilitaire make, outil puissant permettant de gérer un projet de développement. Ce chapitre est clos par la présentation de l'utilisation d'un compilateur C sur un système unix. Pour développer sous unix, il faut en outre savoir comment éditer un fichier, ce prérequis fait l'objet de la première section de ce chapitre.
Certaines sections de ce chapitre exigent que vous ayez quelques notions de programmation ou d'algorithmique : savoir ce qu'est une variable et une boucle ne seront pas inutile pour comprendre la section 5.2Faire des scripts en shell sur les scripts en shell. La section 5.4Faire des projets en langage C sur les projets en langage C présuppose que vous connaissez ce langage, sa lecture est donc très certainement inutile si ça n'est pas le cas.
5-1. Éditer un fichier▲
Vous entendrez sans doute un jour quelqu'un vous dire : « sous unix, tout est fichier(73) ». En outre, comme nous avons vu que les commandes communiquent entre elles à l'aide de flots de texte, la tâche qui consiste à éditer (c'est-à-dire créer/modifier) un fichier contenant du texte est une tâche extrêmement courante sous unix.
5-1-1. Sans éditeur▲
Même si cela reste rare, il peut arriver d'avoir à créer un fichier contenant du texte sans éditeur de texte. Dans ce cas on peut utiliser les redirectionsRedirections, par exemple :
$ echo bonjour > fichier.txt
$stocke la chaîne « bonjour » dans le fichier fichier.txt. On peut même, éventuellement ajouter des sauts de lignes (caractère « \n »), ou des tabulations (caractères « \t ») en utilisant l'option -e de echo :
$ echo -e "a\nb\nc\td" > bonjour.txt
$ cat bonjour.txt
a
b
c d
$Pour être sûr d'arriver à ses fins dans ce genre de situation il est souvent préférable d'utiliser la commande printf plutôt que la commande echo, en écrivant :
$ printf "a\nb\nc\td\n" > bonjour.txt
$Ceci parce que la commande echo de votre système peut ne pas réagir à l'option -e.
Une autre manière de faire est d'utiliser la commande cat avec une redirection :
$ cat > bonjour.txt <-------- attente de données destinées à bonjour.txt
a Entrée
b Entrée
Ctrl d <------------------------------- caractère de fin de fichier
$Ces méthodes ne permettent évidemment pas de modifier le contenu du fichier créé, autrement qu'en l'écrasant avec de nouvelles données.
5-1-2. Avec un éditeur▲
Deux éditeurs sont très répandus sur les systèmes unix, il s'agit de vi (prononcer « vi aïe ») et Emacs (prononcer « et max » ou « i max »). Les paragraphes 6.2Avec vi et 6.3Avec Emacs présentent respectivement ces deux éditeurs. Dans l'immédiat voici ce qu'il faut savoir pour éditer un fichier avec Emacs :
$ emacs bonjour.txttapez alors tranquillement votre texte, puis pour le sauvegarder, appuyez sur les touches Ctrl x s (c'est-à-dire x puis s tout en maintenant Ctrl enfoncée).
Pour charger un fichier existant, utilisez la commande Ctrl x f Les menus Files/Save Buffer et Files/Open File… vous permettront d'effectuer également ces opérations.
5-2. Faire des scripts en shell▲
Cette section a pour but d'exposer les rudiments de la programmation en shell.
Le shell utilisé est bash. C'est le shell développé par le projet gnu. Il incorpore les fonctionnalités du shell sh ainsi que certaines tirées des shells csh et ksh. La modeste expérience de l'auteur a montré qu'il est nécessaire d'expérimenter pour parvenir à ses fins avec le shell ; il permet cependant, une fois la phase d'apprentissage passée(74), d'automatiser certaines des tâches quotidiennes d'un utilisateur de système unix et pour cette raison il est très utile d'en connaître les principes de base. La lecture des chapitres 2Chapitre 2 - Petit guide de survie et 3Chapitre 3 - La boîte à outils est un prérequis indispensable à la lecture de cette section.
Si vous utilisez un shell de connexion de type tcsh ou csh, rien ne vous empêche de programmer avec sh ou bash. C'est pourquoi nous focaliserons ici notre attention sur le shell bash de la famille sh qui, encore une fois, ne vous engage pas à changer vos habitudes « interactives » si vous utilisez un autre shell de connexion.
Enfin, pour vous donner une idée de la complexité du programme bash, la commande :
$ PAGER=cat man bash | wc -lw
Reformatting bash(1), please wait...
4522 33934
$que vous êtes pratiquement capable de comprendre si vous avez lu jusqu'ici, nous indique que la page de manuel de bash sur le système de votre serviteur, contient 33934 mots soit environ 4500 lignes sur un terminal d'environ 90 caractères de large.
Pour info :
$ pdftotext guide-unix.pdf - | wc -w
68837
$guide-unix.pdf est le document que vous avez sous les yeux…
5-2-1. Commentaires▲
Tout langage de programmation dispose de symboles particuliers pour insérer des commentaires dans le code ; c'est-à-dire des portions de texte qui seront ignorées par l'interpréteur ou le compilateur le cas échéant. Ce caractère en langage de commande d'unix est le caractère #. Tout le texte suivant ce caractère jusqu'à la fin de la ligne sera ignoré. Notons toutefois que s'il est suivi du caractères !, ce qui suit est interprété d'une manière particulière par le système comme expliqué au paragraphe suivant.
5-2-2. Choisir l'interpréteur▲
Un script en shell n'est qu'un fichier texte contenant une liste de commandes. Par exemple, un fichier bidule contenant la commande :
echo bonjourest un script shell ! Pour exécuter ce script on lance l'interpréteur de commande avec le fichier comme argument :
$ bash bidule
bonjour
$De manière à simplifier l'utilisation du script bidule on peut préciser quel sera l'interpréteur du programme contenu dans le fichier. Pour cela on place en tête du fichier les deux caractères #! suivis de la référence absolue de l'interpréteur utilisé :
#!/bin/bash
echo bonjouril faudra ensuite rendre exécutable le script :
$ chmod +x bidule
$Ces deux opérations permettent d'utiliser le script en l'appelant directement comme une commande :
$ ./bidule
bonjour
$Notons, qu'on peut généraliser cette idée à n'importe quel interpréteur, par exemple, le fichier test.awk :
#!/usr/bin/awk -f
/^Jim/{print $1,$3}Une fois rendu exécutable, il donne bien ce qu'on attend du premier exemple de la section 3.6awk :
$ ./test.awk fichier.dat
Jimi 1970
Jim 1971
$ici c'est donc la commande awk -f qui est chargée d'interpréter les commandes contenues dans test.awk.
5-2-3. Variables▲
Les variables du shell sont des symboles auxquels on affecte des valeurs. Ces variables ne sont pas ou très faiblement typées comme nous le verrons un peu plus bas. L'affectation et la lecture des variables se fait grâce à la syntaxe suivante (voir aussi 2.1.3Rudiments sur les variables d'environnement) :
#!/bin/bash
N=4
NOM=trucmuche
echo "le nom est $NOM et la variable N vaut $N"qui donne à l'exécution :
$ ./testvar.sh
le nom est trucmuche et la variable N vaut 4
$Dans certaines situations il est nécessaire d'utiliser les accolades en plus du dollar pour lire le contenu de la variable. La syntaxe est alors ${N}.
#!/bin/bash
BOF=loz
echo mon nom est ${BOF}anoSans les accolades, le shell aurait cherché la valeur de la variable $BOFano, variable qui n'existe pas. En shell, les variables ne sont pas déclarées au sens d'un langage de programmation compilé. En fait toutes les variables existent potentiellement. Par conséquent, le shell n'émet pas de message d'erreur lorsqu'on tente d'accéder à une variable à laquelle on n'a jamais affecté de valeur. Cette variable est considérée comme étant « vide » à l'expansion :
#!/bin/bash
BOF=loz
echo mon nom est $BOFanodonne à l'exécution :
$ ./varvide.sh
mon nom est
$ceci rend le débogage de scripts parfois délicat. Pour pallier ce problème on peut utiliser la commande :
$ set -u
$pour demander au shell de générer une erreur lorsqu'on veut faire référence à une variable non initialisée :
$ set -u
$ echo $variablenonintialisee
-bash: variablenonintialisee: unbound variable
$5-2-3-a. Arguments de la ligne de commande▲
Les arguments passés en ligne de commande - c'est-à-dire lors de l'appel de la commande que constitue le script - sont stockés dans les variables $0, $1, $2, etc.
Ainsi :
#!/bin/sh
echo Arguments "[$0] [$1] [$2] [$3] [$4]"donne :
$ ./testarg.sh -t bonjour "les amis" 34
Arguments [./testarg.sh] [-t] [bonjour] [les amis] [34]
$On peut noter qu'à l'instar du langage C, l'argument numéro 0 est le programme à exécuter, ici ./testarg.sh.
Notez en outre l'utilisation des guillemets en ligne de commande. Lors de l'exécution de testarg.sh on utilise ces guillemets pour regrouper les mots les et amis en une seule chaîne de caractères, on peut alors les considérer comme un seul argument.
Pour le traitement des paramètres de la ligne de commande, on dispose également de quelques variables prédéfinies :
- la variable $# contient le nombre d'arguments de la ligne de commande sans compter la commande elle-même - les arguments sont donc comptés à partir de $1;
- les variables $* et $@ contiennent toutes les deux l'ensemble des arguments à partir de $1 mais ont une signification différente lorsqu'elles sont utilisées entre guillemets :
#!/bin/sh
for ARG in "$*" ; do echo $ARG ; donedonne :
$ ./testarg2.sh a b c
a b c
$dans ce cas l'ensemble des arguments est considéré comme une seule chaîne de caractères et :
#!/bin/sh
for ARG in "$@" ; do echo $ARG ; donedonne :
$ ./testarg3.sh a b c
a
b
c
$Ici chaque argument est considéré comme une chaîne de caractères à part entière.
5-2-3-b. Modifications▲
Il existe plusieurs mécanismes permettant d'agir sur les variables :
- l'aide à l'instanciation de variables ;
- le traitement du contenu.
Chacun de ces mécanismes suit une syntaxe particulière (la plupart du temps assez difficilement mémorisable !). Voici donc à titre d'exemple quelques-uns des outils(75) correspondants :
- ${N:-4} renvoie la valeur de N si on lui en a affecté une, 4 sinon ; ce qui permet d'utiliser une valeur par défaut ;
- ${N:?msg} renvoie le message d'erreur msg si N n'a pas été instancié et quitte le script ; ceci peut être utile pour tester les arguments de la ligne de commande.
Voici un exemple d'utilisation de ces outils :
#!/bin/sh
NOM=${1:?"vous devez fournir un nom"}
PRENOM=${2:-"djobi"}
echo Qui : $PRENOM $NOMce qui peut donner à l'exécution :
$ ./varmod.sh
./varmod.sh: 1: vous devez fournir un nom
$Le texte ./varmod.sh: 1: doit se comprendre comme : « l'argument n°1 du script varmod.sh est manquant »
$ ./varmod.sh djoba
Qui : djobi djoba
$ ./varmod.sh goulbi goulba
Qui : goulba goulbi
$Pour ce qui est des outils de traitement de contenu la syntaxe est :
- ${N%motif} et ${N%%motif} suppriment respectivement la plus petite et la plus longue chaîne répondant à l'expression régulière motif, à la fin du contenu de la variable N ;
- ${N#motif} et ${N##motif} suppriment respectivement la plus petite et la plus longue chaîne répondant à l'expression régulière motif, au début du contenu de la variable N.
et voici un exemple très instructif inspiré par Newham et Rosenblatt (1998) :
$ P=/home/local/etc/crashrc.conf.old
$ echo ${P%%.*} <------- supprime la plus grande chaîne commençant par ‘.'
/home/local/etc/crashrc
$ echo ${P%.*} <-------- supprime la plus petite chaîne commençant par ‘.'
/home/local/etc/crashrc.conf
$ echo ${P##/*/} <--------- supprime la plus grande chaîne entourée de ‘/'
crashrc.conf.old
$ echo ${P#/*/} <---------- supprime la plus petite chaîne entourée de ‘/'
local/etc/crashrc.conf.old
$Une application de ce type d'outils serait, par exemple, la conversion en salve, de plusieurs fichiers JPEG en TIFF. En supposant que :
- les fichiers portent l'extension .jpg ;
- sont dans le répertoire courant ;
- on dispose d'un utilitaire que l'on nommera convert qui est capable d'effectuer cette conversion ;
on peut alors écrire le script (voir § 3.4.3La structure for de bash pour l'utilisation de la boucle for) :
#!/bin/sh
for F in *.jpg ; do
convert "$F" "${F%.jpg}.tif"
doneDans ce script, si la variable F vaut à une itération bidule.1.jpg alors :
- ${F%.jpg} vaut bidule.1, c'est-à-dire le nom du fichier auquel on a supprimé la chaîne .jpg à la fin ;
- {F%.jpg}.tif vaut bidule.1.tif, c'est-à-dire, bidule.1 concaténé avec la chaîne .tif.
Finalement, à cette itération on exécute la commande :
convert bidule.1.jpg bidule.1.tifCe principe est très utile dans beaucoup de situations où l'on veut traiter plusieurs fichiers. Par exemple le très classique cas où l'on veut renommer un ensemble de fichiers :
$ ls *.wav
audio1.wav audio2.wav audio3.wav
audio4.wav audio5.wav audio6.wav
audio7.wav audio8.wav audio9.wav
$Imaginons que l'on veuille renommer ces fichiers sous la forme suivante :
- crescent_x.wav
On peut alors écrire :
#!/bin/sh
for F in audio*.wav ; do
mv $F crescent_${F#audio}
doneUn moyen mnémotechnique de se souvenir de la syntaxe de ces opérateurs est la suivante : # désigne en anglais le numéro (number) et on dit généralement « numéro 5 »; # supprime donc en début de chaîne ; inversement on dit généralement « 5 % » , % supprime donc en fin de chaîne. Le nombre de caractères # ou % rappelle si on supprime la plus petite (1 caractère) ou la plus longue (2 caractères) chaîne correspondant au motif.
'Tain c'est pô convivial ce bazar !
5-2-3-c. Arithmétique▲
Bien que les variables du shell ne soient pas typées, on peut cependant évaluer des expressions arithmétiques ; ces expressions n'auront un sens que si les contenus des variables sont des valeurs numériques, bien entendu. La syntaxe pour évaluer une expression arithmétique est :
- $[expression_arithmétique]
ou
- $((expression_arithmétique)) (à préférer)
Par exemple :
$ N=3
$ echo $((N+1))
4
$ N=$[N+4]
$ echo $N
7
$Pour illustrer l'utilisation de l'arithmétique sur les variables, considérons par exemple que l'on dispose d'un ensemble de fichiers dont les noms ont la forme suivante :
$ ls *.dat
2002-qsdfff.dat 2002-sdhjlk.dat 2002-yuiqso.dat
2003-azerzz.dat 2003-sddfg.dat 2003-qsdfrtuy.dat
2003-ertyf.dat 2004-ersssty.dat 2004-sdf.dat
...
$c'est-à-dire :
- année sur 4 chiffres-n caractères.dat
suite à une erreur de manipulation, on désire remplacer toutes les années a par a - 1 (donc 2002 par 2001, 2003 par 2002, etc.). Si l'on suppose qu'une variable F prenne comme valeur le nom d'un de ces fichiers :
- 2002-ertyf.dat
alors on peut extraire l'année (2002) comme suit :
- annee=${F%-*}
maintenant la variable annee contient le nom du fichier sans ce qui se trouve à partir du caractère -. On peut alors décrémenter cette variable :
- annee=$((annee-1))
le nouveau nom du fichier sera composé de cette variable annee concaténée avec ce qui se trouve après le caractère -, soit :
- $annee-${F#*-}
D'où le script de conversion utilisant une boucle forLa structure for de bash
#!/bin/sh
for F in ????-*.dat ; do
annee=${F%-*}
annee=$((annee-1))
mv "$F" $annee-${F#*-}
doneOn aurait également pu extraire les deux parties du nom de fichier (année et le reste) à l'aide de sedsed comme le montre le programme suivant :
#!/bin/sh
for F in ????-*.dat ; do
annee=$(echo "$F" | sed -r 's/([0-9]{4})-.*/\1/')
reste=$(echo "$F" | sed -r 's/[0-9]{4}-(.*)/\1/')
annee=$((annee-1))
echo mv "$F" $annee-$reste
donePour information l'expression régulière :
[0-9]{4}-.*reconnaîtra une chaîne de caractères commençant par 4 chiffres, suivis d'un tiret, suivi de ce qui vous passe par la tête. On notera également l'utilisation de la substitution de commandeSubstitution de commande et d'un tube pour stocker dans une variable l'application de la commande sed à la valeur $F.
5-2-4. Structure de contrôle et tests▲
Les scripts en shell prennent leur intérêt lorsque l'on peut y insérer des boucles et autres structures conditionnelles et itératives. Chacune de ces structures de contrôle inclut généralement l'évaluation d'une expression booléenne.
On verra un peu plus loin qu'en réalité les valeurs des expressions booléennes correspondent toujours à un code de retourLes commandes renvoient une valeur ! d'une commande. Et que la valeur de ce code est interprétée comme « vrai » ou « faux ».
5-2-4-a. Tests▲
La syntaxe pour effectuer un test - que nous reprendrons plus loin avec les structures de contrôle - est la suivante :
- test expression_booléenne
ou
- [ expression_booléenne ]
Plusieurs tests sont disponibles, ayant trait au contrôle de caractéristiques de fichiers (existence, exécutabilité, etc.) et à la comparaison de chaine de caractères, ou d'expressions arithmétiques. Parmi celles-ci :
| test | renvoie « vrai » si… |
| -f fichier | fichier existe(76) |
| test-x fichier | fichier est exécutable(77) |
| -d fichier | fichier est un répertoire(78) |
| chaîne1 = chaîne2 | chaîne1et chaîne2 sont identiques |
| chaîne1 !=chaîne2 | chaîne1et chaîne2 sont différentes |
| -z chaîne | chaîne est vide |
Les expressions booléennes effectuant des tests arithmétiques peuvent quant à elles, être réalisées sous la forme :
- expr1 opérateur expr2
où opérateur peut prendre les valeurs du tableau ci-dessous :
| -eq | égal (equal) |
| -ne | différent (not equal) |
| -lt | inférieur (less than) |
| -gt | supérieur (greater than) |
| test-le | inférieur ou égal (less than or equal) |
| -ge | supérieur ou égal (greater than or equal) |
On peut également combiner les expressions booléennes :
| test | renvoie « vrai » si… |
| ! expr | expr renvoie « faux » |
| expr1-a expr2 | expr1et (and) expr2renvoient « vrai » |
| expr1-o expr2 | expr1ou (or) expr2renvoient « vrai » |
Le shell - notamment bash - dispose de bien d'autres outils de tests et nous vous invitons vivement à compulser la page de manuel ou vous procurer l'ouvrage de Newham et Rosenblatt (1998) pour de plus amples informations.
5-2-4-b. Structures de contrôle▲
Voici trois structures de contrôle disponibles dans bash. Ce sont les trois structures classiques d'un langage de programmation :
- le « if then else » pour faire un choix à partir d'une expression booléenne ;
- le « case » permettant de faire un choix multiple en fonction d'une expression ;
- le « tant que » dont le but est de réitérer des commandes tant qu'une expression est vraie.
Le shell dispose de quelques autres structures que nous passerons sous silence. On peut également se référer au paragraphe 3.4.3La structure for de bash pour la structure de contrôle de type « for ». Toujours dans un souci de pragmatisme nous illustrons ici l'usage de ces trois structures de contrôle grâce à des exemples. Examinons tout d'abord le if :
#!/bin/sh
A=$1
B=$2
if [ $A -lt $B ]; then
echo "l'argument 1 est plus petit que l'argument 2"
else
echo "l'argument 1 est plus grand que l'argument 2"
fiOn peut noter l'utilisation du test […] et du mot-clef fi qui termine la clause if then else. Il ne faut pas omettre le point-virgule qui clôt l'expression test. À l'exécution :
$ ./testif.sh 4 6
l'argument 1 est plus petit que l'argument 2
$ ./testif.sh 45 6
l'argument 1 est plus grand que l'argument 2
$Pour illustrer l'utilisation du while écrivons une petite boucle qui compte de 1 à n (un nombre donné par l'utilisateur) :
#!/bin/sh
LAST=$1
n=1
while [ "$n" -le "$LAST" ]; do
echo -n "$n"
n=$((n+1))
done
echo et voilouqui donne par exemple :
$ ./testwhile.sh 10
1 2 3 4 5 6 7 8 9 10 et voilou
$Notez le mot-clef done qui clôt la clause while. Ici l'option -n de la commande echo ne crée pas de saut de ligne à la fin de l'affichage. Histoire de confirmer l'assertion de Larry Wall(79), on peut utiliser une boucle « pour » pour générer et afficher une séquence. On fera appel à la commande seq dont voici un exemple d'utilisation :
$ seq 1 5
1
2
3
4
5
$ce petit utilitaire a donc pour tâche d'afficher les entiers de 1 à 5. Si vous êtes curieux, la page de manuel vous indiquera que l'on peut également changer l'incrément et deux ou trois autres choses. On peut donc écrire le script suivant :
#!/bin/sh
for I in $(seq 1 10); do
printf "%d " "$I"
done
echo et voilou.qui donne le même résultat que le script précédent.
Les puristes auront noté que la commande seq n'est disponible que pour les utilisateurs travaillant sur des systèmes où le paquet coreutils de chez M. gnu est installé.
Pour ce qui est du case, on peut imaginer que l'on veuille écrire un script permettant d'identifier l'origine des fichiers en fonction de leur extension(80).
#!/bin/sh
NOM=${1:?"Donnez un nom de fichier svp"}
EXT=${NOM##*.}
case $EXT in
tex) echo on dirait un fichier TeX ;;
dvi) echo on dirait un fichier device independant ;;
ps) echo on dirait un fichier Postscript ;;
*) echo chai pô ;;
esacOn utilise ici le modificateur de variable ## pour supprimer la plus grande chaîne finissant par le caractère « . » et ainsi obtenir l'extension. Le mot-clef esac (case à l'envers) clôt la clause case. Le choix par défaut est indiqué par « * » (n'importe quelle chaîne de caractères). À chaque choix correspond une série de commandes à exécuter (ici une seule) ; série qui doit être terminée par deux points-virgules « ;; ».
On teste :
$ ./testcase-I.sh ~/LaTeX/guide/guide-unix.tex
on dirait un fichier TeX
$ ./testcase-I.sh /etc/lpd.conf
chai p^o
$La chaîne de caractères précédant la parenthèse dans chaque clause de case peut être un jokerCaractères génériques (wildcard), comme le montre la dernière clause qui utilise le caractère * pour indiquer « toute (autre) chaîne de caractère ».
Une limitation du script précédent est que les fichiers :
tex
.texseront pris pour un fichier TEX. Ceci est dû au fait que si :
$ NOM=tex
$alors l'expression ${NOM##*.} renvoie tex car aucune substitution n'a pu être réalisée.
On peut imaginer la solution suivante qui utilise les caractères génériques du shell :
#!/bin/bash
NOM=${1:?"Donnez un nom de fichier svp"}
case $NOM in
*[^/].tex) echo on dirait un fichier TeX ;;
*[^/].dvi) echo on dirait un fichier device independant ;;
*[^/].ps) echo on dirait un fichier Postscript ;;
*) echo chai pô ;;
esacDans ce script, l'expression *[^/].tex veut dire toute chaîne de caractères composée de :
- * : toute chaîne même vide ;
- [^/] : un caractère différent de / ;
- .tex
5-2-4-c. Les commandes renvoient une valeur !▲
Les expressions booléennes utilisées par exemple dans la structure if sont en réalité la valeur de retour d'une commande. En effet toute commande unix renvoie une valeur en fonction du succès de son exécution. Il existe en outre une variable particulière contenant le code retour de la dernière commande exécutée : la variable $?. Voici un exemple avec la commande id qui donne des informations sur un utilisateur particulier :
$ id lozano
uid=1135(lozano) gid=200(users) groups=200(users)
$ echo $?
0 <------------------------------------------ tout s'est bien passé.
$ id djobi
id: djobi: No such user
$ id $?
1 <------------------------------------------ Il y a eu un problème.
$On peut alors utiliser cette valeur directement dans une structure de type if comme suit :
#!/bin/bash
if id $1 2> /dev/null 1>&2; then
echo c\'est un utilisateur
else
echo ce n\'est pas un utilisateur
fiIl est important de noter que dans la construction :
-
if commande test ; then
commandes
fi
commandes seront exécutées si et seulement si commande test renvoie la valeur 0 (indépendamment de ce qu'elle peut afficher). Dans notre exemple on a donc :
$ ./testtest.sh lozanoc'est un utilisateur
$ ./testtest.sh djobi
ce n'est pas un utilisateur
$On peut noter l'utilisation de redirectionsRedirections et tubes 2> pour rediriger le flux d'erreur (2) et 1>&2 pour rediriger le flux de sortie (1) sur le flux d'erreur (2).
Un script renvoie la valeur retournée par la dernière commande exécutée. On peut cependant forcer le renvoi d'une valeur particulière en utilisant la commande exit suivie d'une valeur.
Pour finir ce paragraphe et boucler la boucle des « expressions booléennes », supposons qu'il existe dans le répertoire courant un fichier guide-unix.tex et tapons :
$ [ -f guide-unix.tex ]
$ echo $?
0 <----------------------------------------------- le fichier existe
$
Puis :
$ [ -f guide-unix.texitoi ]
$ echo $?
1 <-------------------------------------- le fichier n'existe de pas
$Où l'on apprend donc que [ est une commande qui, comme beaucoup de ses copines, renvoie 0 si tout est ok, et 1 sinon…
5-2-5. Fonctions▲
Une des caractéristiques des shells de la famille sh est la possibilité de créer des fonctions. Voici un exemple succinct qui illustre les syntaxes de déclaration et d'appel, ainsi que la visibilité des variables :
#!/bin/sh
N=4
function mafunc()
{
I=7
echo $1 $2 $N
}
mafunc a b # appel à la fonction avec 2 arguments
echo et : $Iqui donne à l'exécution :
$ ./testfunc.sh
a b 4
et : 7
$on notera donc qu'à l'intérieur du corps de la fonction, les arguments de celle-ci sont notés $1, $2, etc. En outre :
- les variables instanciées dans la fonction sont visibles en dehors (c'est le cas de $I dans notre exemple) ;
- les variables instanciées avant la définition de la fonction sont visibles dans celle-ci (c'est le cas de $N dans notre exemple).
Enfin, à l'instar d'un script, on peut faire renvoyer une valeur à une fonction avec la commande return suivie d'une valeur. Voici un exemple d'utilisation de fonction : on reprend le script arithmetique.sh du paragraphe 5.2.3Arithmétique et on utilise une fonction pour faire le changement de nom :
#!/bin/sh
function changernom()
{
annee=${1%-*}
annee=$[annee-1]
mv "$1" "$annee-${1#*-}"
}
for F in ????-????.dat ; do
changernom $F
done5-2-6. Input field separator▲
Un jour ou l'autre le développeur de script shell est confronté au problème suivant.
Avec notre fichier :
Jimi Hendrix 1970
Jim Morrison 1971
Janis Joplin 1969on écrit naïvement le script ayant pour but d'effectuer un traitement par ligne des fichiers passés en paramètre :
#!/bin/sh
for ligne in $(cat "$@") ; do
echo "Une ligne : $ligne"
doneOn aura une certaine déception à l'exécution :
$ ./naif.sh fichier.dat
Une ligne : Jimi
Une ligne : Hendrix
Une ligne : 1970
Une ligne : Jim
Une ligne : Morrison
Une ligne : 1971
Une ligne : Janis
Une ligne : Joplin
Une ligne : 1969
$Ceci vient du fait que les éléments constituant la liste ` de :
for ligne in ` ; do ...sont délimités par les caractères contenus dans la variable IFS. Cette variable contient par défaut :
- le caractère espace,
- la tabulation,
- le saut de ligne.
Or nous souhaiterions ici clairement que les éléments de la liste soient délimités par le saut de ligne. Il suffit pour cela de modifier le script :
#!/bin/sh
# c'est le saut de ligne qui fait office de séparateur pour
# chaque élément d'une liste
IFS="
"
for ligne in $(cat "$@") ; do
echo "Une ligne : $ligne"
donequi donnera ce qu'on attend, c'est-à-dire :
$ ./naif.sh fichier.dat
Une ligne : Jimi Hendrix 1970
Une ligne : Jim Morrison 1971
Une ligne : Janis Joplin 1969
$5-2-7. Fiabilité des scripts▲
Pour rendre fiables les scripts que vous écrirez, il faudra qu'ils puissent traiter correctement les fichiers aux noms « bizarroïdes ». Le premier cas est le cas des noms de fichiers contenant des espaces. Supposons que dans un répertoire :
$ ls -1
bidule.dat
le machin.dat
truc.dat
$et que l'on écrive le script suivant(81) :
for f in *.dat ; do
echo "je vais effacer $f..."
rm $f
doneCelui-ci affichera, au moment de traiter le fichier le machin.dat :
Je vais effacer le machin.dat
rm: cannot lstat ‘le': No such file or directory
rm: cannot lstat ‘machin.dat': No such file or directoryC'est-à-dire que la commande rm tente d'effacer deux fichiers :
- le fichier le
- et le fichier machin.dat
Pour faire comprendre à la commande rm que le nom du fichier est composé des deux mots, on doit écrire :
for f in *.dat ; do
echo "je vais effacer $f..."
rm "$f" <-------------------------------- on quote la variable
doneAutre situation « tordue » : lorsque le nom d'un fichier commence par le caractère tiret (-) par exemple -biduletruc.txt. Dans ce cas :
$ ls -biduletruc.txt
ls: invalid option -- e
Try `ls --help' for more information.
$ rm -biduletruc.txt
rm: invalid option -- b
Try `rm --help' for more information.
$ici e est la première option inconnue à la commande ls. Pour rm c'est l'option b. La solution(82) pour contourner ce problème est d'insérer dans la ligne de commande le couple -- pour indiquer que ce qui suit ne contiendra plus d'option. Ainsi :
$ ls -- -biduletruc.txt
-biduletruc.txt
$On pourra faire de même pour la commande rm.
5-3. Makefile▲
L'utilitaire make est un outil destiné, au départ, à gérer la compilation d'un projet incluant plusieurs fichiers. Grâce à un fichier - le makefile - on précise quels sont les fichiers à recompiler lorsqu'on apporte une modification à un ou plusieurs fichiers composant le projet. Dans la pratique, make peut être utilisé dans le cadre d'un projet dont la gestion ne nécessite pas nécessairement de compilation ; en fait tout projet dans lequel on a besoin à un moment donné de construire (ou faire) un fichier à partir d'un ou plusieurs autres, peut faire appel à make. On distinguera donc deux concepts :
- l'utilitaire make lui-même qui est un programme, dont les versions varient selon le système ; nous utiliserons ici le make de gnu ;
-
le fichier makefile, qui peut porter n'importe quel nom, et qui contient un ensemble de règles pour définir :
- à partir de quels fichiers on construit le projet ;
- quels sont les fichiers à « refaire » en fonction des modifications apportées au projet.
Ce fichier est interprété par l'utilitaire make.
5-3-1. Principes de base▲
Nous exposons ici les concepts de base de l'utilisation de make en nous basant sur un exemple simple : supposons que nous utilisions le logiciel xfig(83) pour créer des dessins et que nous ayons besoin de les insérer dans un document sous la forme d'un fichier au format PostScript encapsulé(84). Une fois le fichier test.fig sauvé au format de xfig, on désire automatiser l'exportation en PostScript, avec la commande(85) :
$ fig2dev -L eps test.fig > test.eps
$5-3-1-a. Notion de cible▲
Comme nous le notions un peu plus haut, make permet de fabriquer des fichiers. Le fichier que l'on veut construire s'appelle en jargon make, la cible. Supposons que le fichier à exporter s'appelle test.fig, le fichier à fabriquer se nommera test.eps. On crée alors un fichier que l'on nomme Makefile contenant :
test.eps :
↦ fig2dev -L eps test.fig > test.epsle caractère ↦ indique l'insertion d'une tabulation. Sa présence est indispensable pour que l'utilitaire make analyse les règles du fichier makefile.
Par défaut, make cherche à exécuter la première cible qu'il rencontre. Par convention, on définit une cible all pour « tout faire » :
all : test.eps
test.eps :
↦ fig2dev -L eps test.fig > test.epsPour construire le fichier test.eps on peut alors au choix lancer :
$ make
fig2dev -L eps test.fig > test.eps
$ou :
$ make test.eps
fig2dev -L eps test.fig > test.eps
$On peut d'ores et déjà remarquer que la commande à exécuter est préalablement affichée à l'écran ; ceci peut être désactivé (voir 5.3.5Options et fonctionnalités diverses).
5-3-1-b. Notion de dépendance▲
À chaque modification du fichier test.fig, il est nécessaire d'exporter à nouveau en eps. C'est typiquement le genre de tâche que l'on peut confier à make. On insère donc dans le fichier Makefile une dépendance qui spécifie que la construction du fichier test.eps dépend de la date du fichier test.fig :
test.eps : test.fig
↦ fig2dev -L eps test.fig > test.epsLa signification de cette dépendance est la suivante :
- si le fichier test.fig est plus récent que le fichier test.eps la prochaine invocation de make construira à nouveau test.eps ;
- sinon une invocation de make donnera :
$ make
make: `test.eps' is up to date.
$qui est tout simplement la traduction de « est à jour ».
L'utilitaire make gère les dépendances en utilisant les dates associées aux fichiers ; il est donc impératif que l'horloge du système fonctionne correctement et en particulier, dans le cas d'un système en réseau, que l'heure du système stockant les fichiers soit synchrone avec l'heure du système exécutant l'utilitaire lui-même.
5-3-1-c. Notion de règle▲
L'ensemble formé par une cible, une ou des dépendances, et les commandes s'appelle une règle. La syntaxe générale est la suivante :
- cible : dépendances
↦ commande1
↦ commande2
↦ …
↦ commanden
Nous verrons par la suite que l'on peut définir des règles relativement subtiles permettant d'automatiser la gestion de fichiers de projets complexes.
5-3-2. Variables▲
Dans un fichier Makefile on peut utiliser des variables, par exemple :
FICHIER = test
FIGOPTS=-Leps
all : $(FICHIER).eps
$(FICHIER).eps : $(FICHIER).fig
↦ fig2dev $(FIGOPTS) $(FICHIER).fig > $(FICHIER).epsLa syntaxe s'apparente donc à celle du shell :
- affectation avec l'opérateur = ;
- accès avec l'opérateur $ et les parenthèses.
5-3-3. Règles implicites et variables prédéfinies▲
La règle que l'on a construite jusqu'ici est adaptée au fichier test.fig et à lui seul. Un moyen de généraliser cette règle à d'autres fichiers est d'utiliser ce qu'on nomme une règle implicite, permettant de définir de manière générale, comment construire un fichier .eps à partir d'un fichier .fig. Un fichier Makefile répondant à ce problème peut être le suivant :
2.
3.
4.
EPSFILE = test.eps
all : $(EPSFILE)
%.eps : %.fig
↦ fig2dev -L eps $< > $@
On peut expliquer ce Makefile quelque peu cryptique de la manière suivante :
-
la ligne 3 contient :
- la cible %.eps : c.-à-d. n'importe quel fichier dont l'extension est eps ;
- la dépendance %.fig : un fichier de même nom sauf l'extension qui est remplacée par .fig ;
-
la ligne 4 contient la commande proprement dite qui utilise des variables prédéfinies du gnu make :
- la variable $< pour le premier fichier de la liste des dépendances (le fichier test.fig dans notre exemple);
- la variable $@ qui désigne le fichier cible (test.eps).
Le mécanisme de création du fichier test.eps est donc le suivant :
- on doit faire test.eps (cible all) ;
- pour ce faire, on dispose d'une règle permettant de faire un .eps à partir d'un .fig ;
- il existe un fichier test.fig dans le répertoire ;
- on peut donc faire test.eps.
Il existe bien entendu d'autres variables automatiques, parmi celles-ci : $^ qui contient toutes les dépendances de la cible séparées par des espaces. Voir le manuel info de gnu make pour plus de précisions.
5-3-4. Outils sur les variables▲
On peut également, grâce à certaines des fonctionnalités du gnu make, automatiser l'instanciation des variables. Dans l'exemple qui nous concerne, on peut dans un premier temps mettre dans une variable FIGFILE tous les fichiers du répertoire de travail portant l'extension .fig :
FIGFILE=$(wildcard *.fig)le mot-clef wildcard que l'on peut traduire par joker ou caractère générique permet donc ici d'arriver à nos fins. Une deuxième étape consiste à créer la variable EPSFILE à partir de FIGFILE en remplaçant dans le contenu de cette dernière, la chaîne .fig par la chaîne .eps :
EPSFILE=$(patsubst %.fig, %eps,$(FIGFILE))Le mot-clef patsubst signifie ici pattern substitution. Notre Makefile permettant de gérer l'exportation de nos dessins est maintenant capable de générer les .eps à partir de tous les fichiers .fig du répertoire courant. On peut également y rajouter une cible de « nettoyage » permettant d'effacer les fichiers .eps lorsqu'ils ne sont plus nécessaires :
FIGFILE=$(wildcard *.fig)
EPSFILE=$(patsubst %.fig, %eps,$(FIGFILE))
all : $(EPSFILE)
clean :
↦ rm -f $(EPSFILE)
%.eps : %.fig
↦ fig2dev -L eps $< > $@Un raccourci de patsubst pour la substitution précédente est :
EPSFILE=$(FIGFILE:.fig=.eps)qui remplace la chaîne .fig par la chaîne .eps, à la fin des mots. La forme patsubst est donc en quelque sorte une généralisation de la précédente.
Plus généralement, on peut instancier une variable en utilisant le mot clef shell suivi d'une ou plusieurs commandes interprétées par le shell. Un exemple d'une telle construction peut être :
# récupère le dernier fichier TeX sauvé
TMP=$(shell ls -1tr *.tex | tail -1)
# enlève l'extension
LASTTEXFILE=$(shell echo $(TMP) | sed s/\.tex$$// )Il existe bien d'autres outils de traitement sur les chaînes de caractères dans les variables, parmi ceux-ci de nombreux opérateurs de type « rechercher/remplacer », des opérateurs propres aux noms de fichiers (suppression d'extension, du répertoire, etc.), des boucles de type « pour chaque », voir à ce sujet le manuel au format info du gnu make.
5-3-5. Options et fonctionnalités diverses▲
5-3-5-a. Options de make▲
Comme toute commande unix, make peut prendre quelques options et paramètres :
-
les paramètres doivent correspondre au nom d'une cible du Makefile. Dans notre exemple, elle peut être :
Sélectionnez$ make bidule.eps ... $ou :
Sélectionnez$ make clean rm -f arborescence.eps disques.eps flux.eps pipes.eps $si le fichier bidule.fig existe. Si make ne trouve pas de règle pour fabriquer la cible, un message d'erreur est renvoyé :
Sélectionnez$ make djobi make: Nothing to be done for `djobi'. $Si aucun paramètre n'est précisé, c'est la première cible rencontrée qui est exécutée.
-
par défaut make cherche les règles et les cibles parmi quelques fichiers dont les noms sont prédéfinis (Makefile, makefile, etc.), l'option -f permet d'utiliser un autre nom pour le fichier :
Sélectionnez$ make -f bidule.mak ... $ - l'option -n demande à make d'afficher les commandes prévues pour la cible en question, sans les exécuter ; ce qui peut être utile pour déboguer les Makefile ;
-
notez enfin que si la commande d'une règle est préfixée par le caractère @, cette commande n'est pas affichée avant d'être exécutée comme elle l'est par défaut :
Sélectionnezcible1 : ↦ echo six bleus 1 cible2 : ↦ @echo six bleus 2Sélectionnez$ make cible1 cible2 echo six bleus 1 <------------------------ echo de la commande six bleus 1 six bleus 2 <-------------------------- pas d'echo pour cible2 $
5-3-5-b. Règles prédéfinies▲
Comme nous aurons l'occasion de le voir au paragraphe 5.4Faire des projets en langage C les utilitaires make, et notamment le gnu make, définissent certaines règles dites implicites pour fabriquer des fichiers « standards ». À titre d'information, le gnu make dispose d'un catalogue de règles pour, entre autres :
- compiler du C, du C++, du Pascal ;
- faire des éditions de liens ;
- créer des fichiers dvi à partir des sources TEX;
- …
Nous exploiterons ces règles prédéfinies dans la section suivante dédiée à la compilation d'un programme en langage C.
5-4. Faire des projets en langage C▲
Nous supposons ici que le lecteur connaît le langage C, et présentons les mécanismes de la création d'un exécutable unix à partir d'un source écrit en C. La création d'un programme passe par différentes phases d'analyse dont on peut trouver des « méthodes » dans les livres de génie logiciel et d'algorithmique. Nous nous attarderons ici sur la phase « technique » et supposons que le lecteur a un niveau correct en langage C.
5-4-1. Remarques préliminaires▲
Voici un petit glossaire qui permettra de clarifier notre vocabulaire. Les différents types de fichiers que nous rencontrerons seront :
- Source : c'est le fichier texte qui contient le programme en langage C;
- Exécutable : c'est le fichier binaire qui contient des instructions destinées au processeur (code machine) et qui peut être chargé en mémoire par le système d'exploitation ;
- Objet : c'est un fichier binaire résultant de la compilation. Ce fichier contient le code machine de certaines fonctions définies par le programmeur et des appels à des fonctions définies autre part (dans un autre fichier objet ou dans une bibliothèque) ;
- Bibliothèque : c'est un fichier binaire s'apparentant à un fichier objet et contenant le code d'un certain nombre de fonctions rendues publiques ;
- Bibliothèque dynamique : il s'agit d'une bibliothèque dont le code machine n'est pas inséré dans l'exécutable, mais qui est chargé à la demande lors de l'exécution.
- Les actions que nous serons amenés à effectuer pour la gestion de notre projet seront :
- Compilation : c'est la phase permettant de faire une analyse syntaxique, grammaticale et sémantique du fichier source et de créer, si cette première phase se déroule sans heurt, un fichier objet ; elle se décompose en preprocessing, compilation et assemblage ;
- Édition de liens : c'est la phase qui regroupe les fichiers objets et les bibliothèques, et qui après avoir vérifié que toutes les fonctions appelées dans les fichiers objets pointent bien vers un code objet, crée un exécutable. L'édition de liens en anglais se dit to link, et l'utilitaire permettant de l'effectuer est le linker.
5-4-2. Étude du cas simple : un seul fichier source▲
Supposons que l'on ait à créer un exécutable à partir du fichier suivant (voir aussi figure 5.1) :
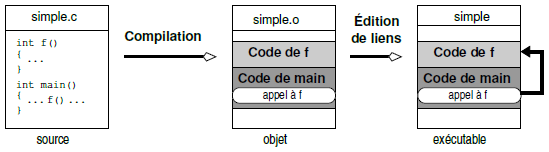
int f()
{
return 4;
}
int main()
{
int i=f();
printf("Bonjour tout le monde.\n");
return 0;
}5-4-2-a. Création de l'exécutable▲
On peut dans le cas simple d'un projet se réduisant à un seul fichier source, lancer une commande qui crée directement l'exécutable :
$ gcc -o simple simple.c
$C'est l'option -o nom qui permet de créer un exécutable dont le nom est nom(86). Ce nom peut être choisi librement, aucune extension particulière n'est nécessaire. Ce sont les attributs du fichier qui le rendent exécutable et non son nom.
Ici les phases de compilation et d'édition de liens sont réalisées automatiquement sans que l'utilisateur n'ait à le demander explicitement. Dans ce cas, l'éditeur de liens trouve le code de la fonction f dans le fichier simple.c compilé.
5-4-2-b. Exécution▲
On exécute le fichier résultant de l'édition de liens en l'appelant par son nom :
$ ./simple
Bonjour tout le monde.
$Tant que le répertoire où réside l'exécutable n'est pas listé dans le contenu de la variable PATH, il est nécessaire de préfixer l'exécutable par le chemin pour pouvoir l'exécuter : c'est ici la signification du « ./ » dans ./test. Dans le cas contraire, deux cas peuvent se produire :
-
le système ne trouve pas votre programme, par exemple si votre programme s'appelle bidule et que vous tentez de l'exécuter comme suit :
Sélectionnez$ bidule bash: bidule: command not found $ - le système n'appelle pas votre programme. Par exemple si vous avez la mauvaise idée de nommer votre exécutable test :
$ test <------------------------------ Il semble ne rien se passer
$ type test
test is a shell builtin
$il existe donc une autre commande nommée test et c'est elle qui est exécutée à la place de la vôtre.
Certains objecteront à la lecture de ce paragraphe : « Mais pourquoi ne pas rajouter le répertoire courant dans la variable PATH(87) ? » La réponse est que pour des raisons de sécurité il n'est pas conseillé de rajouter « . » (le répertoire courant) dans cette variable (lire à ce sujet Garfinkel et Spafford (1996)). Il est donc bon de prendre d'ores et déjà l'habitude d'utiliser le fameux « ./ ». On pourra également lire le paragraphe 6.1.4Environnement de développement qui propose une autre solution.
5-4-2-c. Préprocesseur▲
Avant d'être compilé, un source en langage C est passé à la moulinette du préprocesseur. Ce programme va traiter toutes les directives de type #… et les remplacer par du code source. Il supprimera également tous les commentaires. Le résultat de ce « traitement de texte » sera présenté au compilateur. Sous unix, le préprocesseur porte le doux nom de cpp (C preprocessor). On peut voir cpp en action en utilisant l'option -E de gcc, sur un fichier exemple :
#define N 4
#define carre(a) ((a)*(a))
int main(int argc, char** argv)
{
int i=N,j,k;
j=2*N;
k=carre(i+j);
return 0;
}puis :
$ gcc -E testcpp.c
int main(int argc, char** argv)
{
int i= 4 ,j,k;
j=2* 4 ;
k= (( i+j )*( i+j ));
return 0;
}
$On peut également noter que le préprocesseur de gcc définit plusieurs symboles qui identifient le système sous-jacent. On peut utiliser ces symboles lorsqu'on veut créer du code C portable d'un système (unix) à un autre :
$ cpp -dM testcpp.c
...
#define __linux__ 1
#define __gnu_linux__ 1
#define __unix__ 1
#define __i386__ 1
#define __INT_MAX__ 2147483647
#define __LONG_LONG_MAX__ 9223372036854775807LL
#define __DBL_MIN__ 2.2250738585072014e-308
#define N 4
$Ces symboles peuvent ensuite être exploités par des directives de type #ifdef :
#if defined __linux__ && defined __i386__
int fonction_de_la_mort(int,int)
#else
int fonction_de_la_mort(double,double)
#endif5-4-2-d. Répertoires de recherche▲
Lorsque cpp se met en branle, et qu'il rencontre une directive #include, il va chercher dans une liste de répertoires le fichier spécifié. On peut voir la liste de recherche par défaut en utilisant à nouveau l'option -v de gcc :
$ gcc -v -E fantome.c
...
gcc version 3.3.5 (Debian 1:3.3.5-13)
/usr/lib/gcc-lib/i486-linux/3.3.5/cc1 -E -quiet -v src/testcpp.c
#include "..." search starts here:
#include <...> search starts here:
/usr/local/include
/usr/i386-redhat-linux/include
/usr/lib/gcc-lib/i486-linux/3.3.5/include
/usr/include
End of search list.
$On notera que :
- les fichiers inclus par une directive du type #include "fichier" sont recherchés à partir du répertoire courant ;
-
on peut influer sur la liste des répertoires dans lesquels une directive #include recherche les fichiers, grâce à l'option -I de gcc. Si par exemple, on désire inclure le fichier bidule.h se trouvant dans ~/mes_includes, on spécifiera en ligne de commande :
Sélectionnez$ gcc -I ~/mes_includes -c monfichier.c -
avec :
monfichier.cSélectionnez#include <bidule.h> /* ou "bidule.h" */...
5-4-2-e. Voir le code assembleur▲
Sur les systèmes unix utilisant l'environnement de développement de chez gnu, la plupart des langages de programmation compilés (C, C++, Pascal, Prolog) sont d'abord traduits en langage d'assemblage, on fait ensuite appel à l'outil assembleur pour produire le fichier objet. Par simple curiosité on peut voir le code assembleur produit pour le fichier suivant :
int mafonction(double d)
{
return 2.3*d-7.4;
}On peut demander à gcc de s'arrêter à la phase d'assemblage (c'est-à-dire ne pas produire le fichier objet) avec la commande suivante :
$ gcc -S testas.c
$ ls -l testas.*
-rw-r--r-- 1 lozano lozano 57 Nov 11 18:30 testas.c
-rw-r--r-- 1 lozano lozano 640 Nov 11 18:31 testas.s
$On peut alors - toujours dans le cadre d'une curiosité malsaine - examiner le contenant du code assembleur généré, avec la commande cat :
$ cat testas.s
...
mafonction:
pushl ?p
movl %esp, ?p
subl $16, %esp
...
$On peut ensuite traduire ce code en appelant explicitement l'outil assembleur :
$ as testas.s -o testas.o
$5-4-2-f. Autres options intéressantes▲
gcc dispose de moult options que nous ne détaillerons bien évidemment pas ici.
Voici cependant quelques options utiles à connaître pour mener à bien vos projets :
- l'option -Onombre (88) met en route différentes méthodes d'optimisation pour produire du code plus rapide ou utilisant moins de mémoire. En ce qui concerne nombre, il peut prendre des valeurs de 0 à 3 (0 : pas d'optimisation, 3 : optimisation max) ;
- l'option -Wall affiche tous les warnings de compilation ; c'est une option incontournable qui permet d'attirer l'attention du programmeur sur des portions de programmes « douteuses » (variables non initialisées, problème de transtypage…) ;
- -Dmacro est une option passée au préprocesseur qui produit le même résultat que l'inclusion dans le source d'une ligne #define macro 1 ;
5-4-3. Compilation séparée▲
Dans le contexte de la compilation séparée on a à compiler plusieurs modules source. Examinons, en guise d'exemple, la situation (figure 5.2) dans
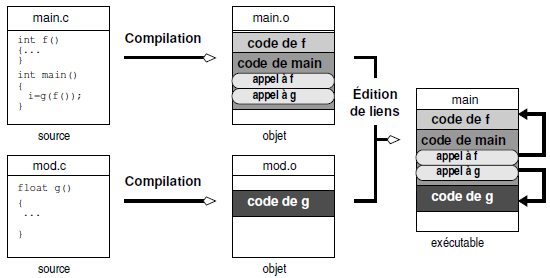
laquelle un fichier contient le main :
#include <stdio.h>
#include "mod.h"
int f() { return 4; }
int main(int argc, char** argv)
{
int i=g(f());
return 0;
}qui fait appel à une fonction g dont la déclaration se trouve dans mod.h et la définition dans mod.c :
float g(float);float g(float f)
{
return 2*f;
}Pour compiler ce projet :
- On doit compiler séparément main.c et mod.c ;
- Faire l'édition de liens à partir des fichiers objets créés.
5-4-3-a. Compilation en ligne de commande▲
Pour créer un fichier objet à partir d'une source en langage C - c'est-à-dire procéder à la phase de compilation - on peut lancer la commande :
$ gcc -c main.c -o main.o <------------- compilation du premier module
$ gcc -c mod.c -o mod.o <-------------- compilation du deuxième module
$Il faut noter ici l'option -c du compilateur qui précise qu'on n'effectue que la compilation et l'option -o (output) précise que les fichiers objet doivent être stockés dans les fichiers main.o et mod.o.
5-4-3-b. Édition de liens en ligne de commande▲
Pour passer à la phase suivante qui est la création de l'exécutable par le biais de l'édition de liens, on utilise la commande suivante :
$ gcc -o main main.o mod.o
$Pour effectuer l'édition de liens, on précise donc le nom de l'exécutable avec l'option -o, et on spécifie quels sont les fichiers objet à lier.
5-4-4. Bibliothèques▲
5-4-4-a. Lier un exécutable avec une bibliothèque▲
Pour ce qui concerne Linux - et c'est le cas de la plupart des systèmes unix - les exécutables créés sont des exécutables dynamiques, c'est-à-dire que le code qu'ils contiennent fait appel à des bibliothèques dynamiques. Soit le source suivant :
#include <stdio.h>
int main()
{
printf("bonjour tout le monde\n");
return 0;
}et la commande suivante pour créer un exécutable :
$ gcc -o bonjour bonjour.c
$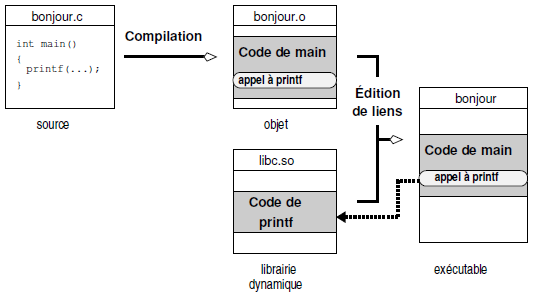
On peut examiner l'exécutable créé avec la commande ldd pour obtenir les bibliothèques dont il dépend :
$ ldd bonjour
libc.so.6 => /lib/libc.so.6 (0x4001a000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
$On voit donc ici que l'exécutable bonjour est lié dynamiquement avec la bibliothèque standard, dite « libC » (voir figure 5.3). Ces deux bibliothèques sont automatiquement ajoutées à l'édition de liens, sur le système Linux de l'auteur. La première contient le code de la bibliothèque standard du C (et donc celui de la fonction printf), la deuxième contient les instructions permettant de charger dynamiquement les bibliothèques.
Dans certaines situations, il faut préciser explicitement que le code fait appel à des fonctions définies dans une bibliothèque spécifique. Par exemple pour compiler le fichier en langage C suivant faisant appel à une routine de la bibliothèque mathématique :
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main(int argc, char** argv)
{
if (argc==2)
/* renvoie la racine de l'argument 1 */
printf("%f\n",sqrt(atof(argv[1])));
return 0;
}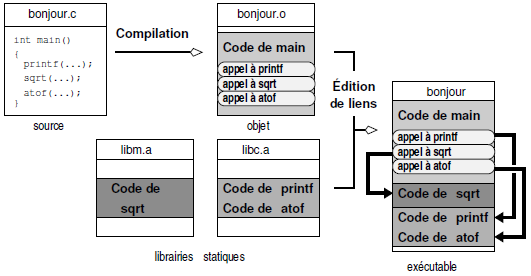
on procédera comme suit :
$ gcc -c testmath.c -o testmath.o
$ gcc -o testmath testmath.o -lm
$L'option -l précise que l'on veut ajouter la bibliothèque mathématique du C à l'édition de liens. On a alors :
$ ldd testmath
libm.so.6 => /lib/libm.so.6 (0x40021000)
libc.so.6 => /lib/libc.so.6 (0x40043000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
$on constate donc que l'exécutable testmath est lié dynamiquement avec la bibliothèque mathématique stockée dans le fichier /lib/libm.so.6. Il est possible de forcer la création d'un exécutable statique. Pour cela on impose alors au linker d'insérer dans l'exécutable le code des fonctions provenant de ou des bibliothèques nécessaires :
$ gcc -static -o testmath.stat testmath.o -lm
$ ls -lh testmath*
-rwxr-xr-x 1 lozano lozano 12K Nov 11 17:54 testmath
-rw-r--r-- 1 lozano lozano 223 Nov 11 17:54 testmath.c
-rw-r--r-- 1 lozano lozano 948 Nov 11 17:54 testmath.o
-rwxr-xr-x 1 lozano lozano 471K Nov 11 17:58 testmath.stat
$On pourra noter la différence de taille des exécutables créés. Ceci confirme que dans le cas « statique » le code des fonctions issu des bibliothèques est inséré dans l'exécutable (voir figure 5.4).
5-4-4-b. Où sont les bibliothèques ?▲
Lorsqu'on précise, lors de l'édition de liens, l'option -l suivie de m, le linker cherche dans une série de répertoires prédéterminée, un fichier nommé libm.so pour la bibliothèque dynamique et libm.a pour la bibliothèque statique. Dans le cas où la bibliothèque à inclure n'est pas dans la liste de répertoires standard, il est nécessaire d'utiliser l'option -L suivie du répertoire où se trouve la bibliothèque en question. Par exemple, on écrira :
$ gcc -L ~/lib -o djobi djobi.o -lmabib
$si la bibliothèque libmabib.so ou libmabib.a se trouve dans le répertoire ~/lib. S'il s'agit d'une bibliothèque dynamique (libmabib.so), pour pouvoir exécuter le fichier djobi, il faudra impérativement indiquer au programme qui charge les bibliothèques dynamiques où se trouve libmabib.so. On peut réaliser cela en positionnant la variable d'environnement LD_LIBRARY_PATH avec la liste des répertoires susceptibles de contenir des bibliothèques dynamiques :
export LD_LIBRARY_PATH=dir1 :dir2 : $LD_LIBRARY_PATHDans notre exemple on écrira :
$ export LD_LIBRARY_PATH=~/lib:$LD_LIBRARY_PATH
$À titre indicatif, sous le système HPUX (l'unix de Hewlett Packard) cette variable se nomme SHLIB_PATH.
5-4-4-c. Créer une bibliothèque▲
On peut créer des bibliothèques qui seront liées statiquement ou dynamiquement lors de l'édition de liens. La création d'une bibliothèque consiste à rassembler un certain nombre de fichiers objets dans un seul fichier. On supposera, à titre d'exemple, que l'on dispose de trois fichiers : mod1.o mod2.o et mod3.o résultant de la compilation de trois fichiers écrits en langage C.
Statique - Pour créer une bibliothèque statique, on pourra utiliser la commande :
$ ar ruv libbidule.a mod1.o mod2.o mod3.o
ar: creation de libbidule.a
a - mod1.o
a - mod2.o
a - mod3.o
$La commande ar crée un fichier bibliothèque libbidule.a. L'option ru permet d'insérer en remplaçant chaque objet dans l'archive, l'option v permet de rendre la commande ar plus bavarde qu'elle ne l'est par défaut. On se reportera à la page de manuel pour plus de détail. Une fois la bibliothèque statique créée on peut l'utiliser lors d'une édition de liens comme suit :
$ gcc -L. -o monappli monmain.o -lbidule
$On notera :
- l'option -L pour indiquer qu'il faut chercher la bibliothèque dans le répertoire courant ;
- la syntaxe -lbidule qui cherche une bibliothèque nommée libbidule.a
L'option -s de la commande ar ou l'utilisation de la commande ranlib en lieu et place de ar permet de créer un index des symboles et ainsi d'accélérer les éditions de liens que l'on réalisera avec la bibliothèque.
Dynamique - Pour créer une bibliothèque dynamique on utilisera la syntaxe suivante :
$ gcc -shared -o libbidule.so mod1.o mod2.o mod3.o
$Pour utiliser une telle bibliothèque à l'édition de liens :
$ gcc -L. -o monappli monmain.o -lbidule
$Il faudra s'assurer que la variable d'environnement LD_LIBRARY_PATH contienne le répertoire où se trouve libbidule.so pour que cette dernière puisse être chargée au moment de l'exécution de monappli (cf. § 5.4.4Bibliothèques).
5-4-5. Se simplifier la vie avec make▲
Encore une fois, nous supposons que le lecteur a à sa disposition le gnu make. Ce dernier définit deux règles liées à la gestion de projet en C et C++. La première règle est la suivante :
%.o : %.c
↦$(CC) -c $(CPPFLAGS) $(CFLAGS) $<qui indique comment construire le fichier objet à partir du fichier C. Les variables CPPFLAGS et CFLAGS permettent respectivement de passer des options au préprocesseur et au compilateur(89). On pourra donc utiliser par exemple le makefile suivant :
CFLAGS=-Wall
CPPFLAGS=-I/usr/local/machin-chose
test.o : test.cce qui donnera :
$ make -f makefile.test.1
cc -Wall -I/usr/local/machin-chose -c test.c -o test.o
$Le gnu make positionne par défaut la variable $(CC) à la valeur cc. En outre, il définit un ensemble de règles pour l'édition de liens :
-
s'il n'y a qu'un seul fichier objet, la règle est la suivante :
Sélectionnez%:%.o ↦$(CC)$(LDFLAGS)$<$(LOADLIBES) - LDFLAGS permet de passer des options au linker, et LOADLIBES permet d'indiquer quelles sont les bibliothèques nécessaires à l'édition de liens.
-
s'il s'agit d'une compilation séparée, une règle du type :
Sélectionnezmain:main.o fichier1.o fichier2.o - lancera la compilation des fichiers main.c, fichier1.c et fichier2.c, puis l'édition de liens avec les trois fichiers objets générés pour créer l'exécutable main. Dans le cas de la compilation séparée, il est nécessaire qu'un des fichiers source porte le nom de la cible (ici c'est main.c).
Voyons deux exemples, le premier pour le cas d'un seul fichier objet :
CFLAGS=-Wall
CPPFLAGS=-I/usr/local/machin-chose
LDFLAGS=-L/usr/local/bidule-truc
LOADLIBES=-lbidule
test : test.oqui donne :
$ make -f makefile.test.2 test
cc -Wall -I/usr/local/machin-chose -c test.c -o test.o
cc -L/usr/local/bidule-truc test.o -lbidule -o test
$Dans le cas de la compilation séparée, on pourra écrire le makefile suivant qui permet de créer l'exécutable de l'exemple du paragraphe 5.4.3Compilation séparée :
CFLAGS=-Wall
CPPFLAGS=-I/usr/local/machin-chose
LDFLAGS=-L/usr/local/bidule-truc
LOADLIBES=-lbidule
main : main.o mod.oqui donne :
$ make -f makefile.test.3
cc -Wall -I/usr/local/machin-chose -c main.c -o main.o
cc -Wall -I/usr/local/machin-chose -c mod.c -o mod.o
cc -L/usr/local/bidule-truc main.o mod.o -lbidule -o main
$Pour finir cette section sur l'utilisation de make dans le cadre d'un projet en langage C, nous allons voir comment on peut demander à gcc de générer pour nous les dépendances du projet. Dans notre exemple de compilation séparée, ces dépendances sont les suivantes :
- mod.o dépend uniquement de mod.c : on doit reconstruire le premier si le dernier a été modifié ;
- main.o dépend de main.c et de mod.h à cause de la présence de la directive #include "mod.h" : si mod.h ou main.c a été modifié il faut reconstruire main.o.
Cette liste peut être générée automatiquement par gcc grâce à l'option -MM qui affiche les dépendances liées aux fichiers inclus avec la directive du préprocesseur #include"fichier". Ainsi :
$ gcc -MM main.c mod.c
main.o: main.c mod.h
mod.o: mod.c
$On peut utiliser cette option de -MM directement dans le makefile lui-même :
CFLAGS=-Wall
CPPFLAGS=-I/usr/local/machin-chose
LDFLAGS=-L/usr/local/bidule-chouette
LOADLIBES=-lbidule
OBJFILES=main.o est_f.o
CFILES=$(OBJFILES:.o=.c)
main : $(OBJFILES)
depend.dat :
↦ $(CC) -MM $(CPPFLAGS) $(CFLAGS) $(CFILES) > depend.dat
-include depend.datDans ce makefile, on a défini une cible nommée depend.dat dont le but est de construire le fichier de dépendances depend.dat. La directive -include permet ensuite d'inclure le fichier depend.dat même si celui-ci n'existe pas (c'est la signification du tiret qui préfixe include). On pourra également remarquer l'utilisation des variables $(OBJFILES) et $(CFILES), créées ici pour « rationaliser » le makefile (cf. § 5.3.4Outils sur les variables).
5-5. Conclusion▲
La « digestion » des informations fournies dans ce chapitre devrait vous donner les bases nécessaires pour créer des scripts divers et variés, lesquels, à l'instar de ceux de l'auteur, iront en se complexifiant et s'améliorant. La connaissance des outils « standard » d'unix (awk, sed, etc.), couplée avec celles des scripts shell et du fonctionnement de make, est un atout majeur pour entamer un projet de développement ambitieux. C'est également un atout pour se lancer dans les tâches d'administration système. La connaissance des principes de base de la compilation sous unix est quant à elle importante, car elle permet de comprendre les mécanismes qui entrent en jeu dans la création d'un exécutable.