


2. Chapitre 2 - Petit guide de survie▲
| eval $(echo \ "3chA+2A96ADB+*+8157+7AE19A^395C304B" |\ tr "1+2*3456789ABCDE^0" "a\ b\|efijlmnorsuz@.") 'Tain c'est pô convivial !. |
La convivialité d'un système unix réside dans la souplesse et la puissance des outils dont on dispose pour dialoguer avec le système. Il s'agit certes d'une convivialité à laquelle peu d'utilisateurs sont habitués ; essentiellement parce qu'elle demande un investissement sur le plan de la documentation et de l'apprentissage. Ce chapitre a donc pour but de présenter les fonctionnalités de base d'un système unix sur le plan de son utilisation (c.-à-d. qu'il ne sera pas question ici d'administration d'un système). On verra donc dans un premier temps une présentation succincte de l'interface de base à savoir le shell, suivront des présentations des concepts d'utilisateur, de système de fichiers, de processus. Le chapitre est clos par une explication rapide des services de base du système (impression, tâches planifiées…).
2-1. Le shell▲
Le shell est une interface avec le système unix. Il offre à l'utilisateur l'interface de base avec le système d'exploitation. L'étymologie du mot nous apprend qu'on peut l'imaginer comme une coquille englobant le noyau et ses composants. Le shell est également un programme qu'on appelle interpréteur de commandes. Ce programme tourne dans une fenêtre ou sur une console en mode texte. Dans une fenêtre d'un environnement graphique, il a l'allure de la figure 2.1. On parle également de terminal
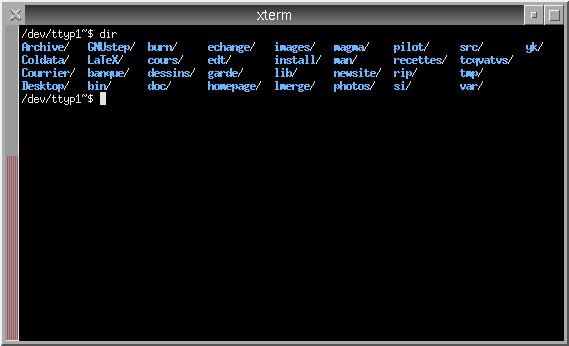
(ou d'émulateur de terminal) pour désigner un écran ou une fenêtre dans laquelle est exécuté le shell. Il existe plusieurs shells dans le monde unix, les plus courants sont :
- sh : fait initialement référence au premier shell d'unix conçu par Steve Bourne, utilisé notamment pour les scripts système ;
- ksh : le Korn shell ;
- csh : le C shell (dont la syntaxe rappelle vaguement celle du C pour ce qui est des structures de contrôle) ;
- bash : le shell de gnu(32) qui est, comme mentionné dans la page de manuel, « trop gros et trop lent ». C'est malgré tout celui sur lequel nous nous attarderons dans ce manuel ;
- tcsh : le Tenex C shell contient tout ce qu'apporte csh avec des fonctionnalités supplémentaires notamment une édition plus aisée de la ligne de commande ;
- zsh le Zorn shell contenant un langage de programmation plus évolué que bash et des fonctionnalités de complétions avancées(33) ;
- …
Le shell est utilisé le plus souvent de manière interactive, pour passer des commandes au système. Pour signifier que le shell est prêt à recevoir ces commandes, il affiche un prompt. Ce prompt peut contenir un nombre variable d'informations selon la configurationAvec le shell, et nous y ferons référence de la manière suivante :
$On peut illustrer le fonctionnement d'un shell, avec l'algorithme suivant :

Notons enfin que si nous présentons ici le shell dans son utilisation interactive, il est également utilisé sous forme de scriptsFaire des scripts en shell, dans ce cas les commandes passées au système peuvent être enregistrées dans des fichiers qui peuvent ensuite être exécutés. En cela le langage de commande peut être utilisé comme un langage interprété.
2-1-1. Qu'est-ce qu'une commande ?▲
Exécuter ou lancer une commande, consiste de manière synoptique en ceci :
-
nom-commande options arg1 arg2… argn

- …
résultat de la commande sur le terminal
…
nom-commande est le nom de la commande à exécuter ; cette dernière peut accepter un certain nombre d'options dont la syntaxe est en général :
- -option par exemple -a, ou
- --option par exemple --verbose.
Un exemple :
$ ls -l guide-unix.tex <--------- Entrée
-rw-r--r-- 1 vincent users 2159 Nov 7 13:28 guide-unix.tex
$Celui-ci exécute la commande ls(34) avec l'option l et l'argument guide-unix.tex. Le résultat de la commande ls est expliqué à la section 2.3Le système de fichiers.
On peut noter que commande, options et arguments(35) sont séparés par des espaces. Il faut comprendre que l'analyse de la ligne de commande par le shell est effectuée en séparant dans un premier temps les éléments (commande, options et arguments) par des espaces. Au cas où un nom de fichier contiendrait un espace, il faudra indiquer au shell que le nom est à considérer comme un seul élément en procédant comme indiqué à la section 2.1.5Espaces dans les noms de fichiers.
2-1-1-a. Commandes internes et commandes externes▲
Une commande peut être interne (builtin) au shell, ou externe. Dans le premier cas la commande est interprétée par le shell, dans l'autre il peut s'agir de n'importe quel fichier exécutable stocké dans l'arborescence. L'algorithme d'interprétation des commandes devient :

La recherche de l'exécutable correspondant à une commande externe consiste en l'examen d'un ensemble de répertoires susceptibles de contenir l'exécutable en question.
Cette liste de répertoires définie lors de la configuration du système est stockée dans une variable d'environnementRudiments sur les variables d'environnement nommée PATH. Dans le shell utilisé par votre serviteur :
$ type cat
cat is /bin/cat
$ type echo
echo is a shell builtin
$La commande type nous informe que echo est une commande interne et que la commande cat ne l'est pas (i.e. est un programme dans le répertoire /bin). type est une commande interne du shell bash. L'équivalent pour la famille des C-shells est which.
2-1-1-b. Messages d'erreurs▲
Le shell et les commandes exécutées peuvent informer l'utilisateur qu'une erreur s'est produite lors de l'exécution d'une commande. Cette information concernant l'erreur se fait par un canal appelé le flux d'erreur qui est par défaut redirigé sur votre écran. Il existe au moins quatre situations où le shell et les commandes renvoient une erreur :
- la commande n'existe pas :
$ youpla
bash: youpla: command not found
$- l'argument spécifié ne correspond à aucun fichier :
$ cp mlkj essai.tex
cp: mlkj: No such file or directory
$- l'utilisateur ne possède pas les droits suffisants :
$ cp g.dat /
cp: cannot create file `/g.dat': Permission denied
$-
la commande n'est pas utilisée avec les bonnes options :
Sélectionnez$ cat -l fichier.tmp cat: invalid option -- l Try `cat --help' for more information. $
À l'instar des boîtes de dialogue d'avertissement ou d'erreur qui surgissent dans les environnements graphiques, il est important de lire attentivement les messages pour comprendre pourquoi une commande échoue.
2-1-1-c. Composer les commandes▲
On peut composer deux ou plusieurs commandes à l'aide du caractère « ; » :
$ ls guide-unix.tex ; echo bonjour
guide-unix.tex
bonjour
$Notons au passage que la commande echo affiche à l'écran la chaîne de caractère qui suit. Il existe deux autres opérateurs permettant de combiner deux commandes :
-
l'opérateur &&
- commande1 && commande2
exécute commande2 si commande1 s'exécute sans erreur ;
- l'opérateur || commande1 || commande2 exécute commande2 si commande1 renvoie une erreur.
Lorsqu'il est dit ci-dessus que la commande « renvoie une erreur », il s'agit plus précisément de la situation où la commande retourne une valeur différente de 0 (voir aussi § 5.2.4.cLes commandes renvoient une valeur !).
2-1-2. « Convivialité » et ergonomie▲
À la fin des années 80, les éditeurs de logiciels axaient leur publicité sur la « convivialité » de leurs produits. Un programme était alors dit « convivial » lorsqu'il présentait à l'utilisateur moult menus, boîtes de dialogue et autres icônes. Il s'avère cependant que pour une utilisation intensive d'un logiciel, la dite « convivialité » devient plutôt une contrainte et l'utilisateur cherche rapidement les raccourcis clavier pour une utilisation plus confortable.
D'autre part, si l'on songe que le langage de commande est un langage en tant que tel, il permet à l'utilisateur d'exprimer (tout) ce qu'il veut et cela de manière très souple. Ceci est à comparer avec un logiciel qui propose des fonctionnalités sous forme de menus ou de boîtes de dialogue, qui laissent finalement à l'utilisateur une marge de manœuvre souvent restreinte.
C'est pourquoi la vraie question n'est pas celle de la pseudo-convivialité - qui est plus un argument de vente auprès du grand public - mais celle de l'ergonomie d'un logiciel. Est-il possible d'exprimer de manière concise et rapide la tâche que l'on désire faire effectuer à la machine ? Le shell est un programme ergonomique et l'utilisateur qui a fait l'effort de l'apprentissage du langage de commande le constate très vite(36).
Ah oui : l'utilisation du langage de commande d'unix repose sur l'utilisation intensive du clavier. Il est donc important de se familiariser avec ce périphérique voire d'apprendre via des méthodes adéquates à l'utiliser de manière optimale.
Dans la mesure où le pressage de touches de clavier est l'activité première de l'utilisateur unix, quelques « aménagements » ont été mis en place :
-
l'historique des commandes : les touches
 et
et  permettent de rappeler les commandes précédemment tapées pour éventuellement les modifier et les relancer ;
permettent de rappeler les commandes précédemment tapées pour éventuellement les modifier et les relancer ; -
la complétion des commandes : la touche
 (tabulation) permet de compléter les noms de commandes, les noms de fichiers et de répertoires à partir des premiers caractères de leur nom. À utiliser intensivement !
(tabulation) permet de compléter les noms de commandes, les noms de fichiers et de répertoires à partir des premiers caractères de leur nom. À utiliser intensivement !
Si un jour vous vous connectez sur une « vieille » machine unix et/ou que vous avez à dialoguer avec un « vieux » shell ne disposant ni de la complétion ni du rappel des commandes, ce jour-là vous comprendrez que bash (ou le shell que vous avez l'habitude d'utiliser), malgré son caractère apparemment spartiate, est un programme vraiment moderne…
2-1-3. Rudiments sur les variables d'environnement▲
Lorsqu'un shell est exécuté par le système, un certain nombre de variables dites d'environnement sont instanciées. Ces variables permettent à l'utilisateur et aux programmes lancés par le shell d'obtenir plusieurs informations sur le système, la machine et l'utilisateur, entre autres. La commande env affiche à l'écran toutes les variables d'environnement pour le shell. En voici un extrait :
$ env
MAIL=/var/spool/mail/vincent
HOSTTYPE=i386
PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin
HOME=/home/vincent
SHELL=/bin/bash
USER=vincent
OSTYPE=Linux
$On comprend aisément que ces variables d'environnement définissent respectivement, le fichier réceptacle du courrier, le type de la machine, la liste des répertoires(37) où le shell va chercher les exécutables (pour les commandes qui ne sont pas internes), le répertoire privé de l'utilisateur, le nom de l'utilisateur et le type de système d'exploitation. En préfixant le nom d'une variable par un dollar ($), on accède à la valeur de cette variable. Ainsi :
$ echo $SHELL
/bin/bash
$est un moyen de connaître le shell qui est associé à votre utilisateur dans la base de données du système.
En réalité toutes les variables d'un shell ne sont pas des variables d'environnement, dans le sens où toutes les commandes n'y ont pas nécessairement accès. Par contre n'importe quelle variable peut devenir une variable d'environnement à l'aide de la commande interne export.
2-1-4. Caractères spéciaux▲
Un certain nombre de caractères sont dits spéciaux, car ils sont interprétés d'une manière particulière par le shell. Le plus connu de ces caractères est sans doute celui qui sépare les répertoires dans un chemin(38). Sous unix, c'est le slash (/). Par exemple :
- /home/users/hendrix/wahwah.dat.
Voici une liste des caractères spéciaux les plus communs du shell :
- $ permet le mécanisme d'expansion et donc permet de faire référence à la valeur de la variable nommée après, mais aussi de faire des calculsArithmétique ou d'exécuter une autre commande (§ 3.4.2Substitution de commande) ;
- ˜ remplace le répertoire privéLe système de fichiers de l'utilisateur ;
- & lance une commande en arrière-planProcessus ;
- * remplace toute chaine de caractères ;
- ? remplace tout caractère (voir la section suivante pour ces deux caractères) ;
- | pour créer un tubeLes tubes (pipes) ;
- > et < pour les redirectionsRedirections ;
- ; est le séparateur de commandes ;
- # est le caractère utilisé pour les commentairesCommentaires ;
- …
Il est bien entendu que puisque ces caractères ont un rôle particulier, il est peu recommandé de les utiliser dans les noms de fichiers, au risque de compliquer le dialogue avec le shell (voir le paragraphe sur les mécanismes d'expansionIntroduction à l'expansion.
2-1-5. Espaces dans les noms de fichiers▲
Le caractère espace n'est pas un caractère spécial pour le shell, cependant son utilisation dans les noms de fichiers modifie légèrement la manipulation des commandes.
Imaginons par exemple que l'on veuille effacer un fichier nommé « zeuhl wortz.txt », la commande « naïve » suivante échouera :
◊, rm zeuhl wortz.txt
rm: cannot remove `zeuhl': No such file or directory
rm: cannot remove `wortz.txt': No such file or directory
$car le shell tente d'effacer deux fichiers au lieu d'un seul puisqu'il délimite les mots à l'aide du caractère espace. Pour expliquer au môssieur que « zeuhl wortz.txt » désigne un seul fichier, il est nécessaire « d'échapper » le caractère espace :
$ rm zeuhl\ wortz.txtou d'indiquer explicitement que le nom est composé d'un seul « mot » en l'entourant de guillemets (") ou d'apostrophes (') :
$ rm "zeuhl wortz.txt"ou :
$ rm 'zeuhl wortz.txt'2-1-6. Caractères génériques▲
Il existe au moins deux moyens d'utiliser les caractères génériques (parfois dits wildcards ou joker en anglais). Voici deux exemples en reprenant la commande ls :
$ ls guide-unix*
guide-unix.aux guide-unix.dvi guide-unix.log guide-unix.tex
$liste tous les fichiers du répertoire courant commençant par guide-unix. Et :
$ ls guide-unix.??x
guide-unix.aux guide-unix.tex
$liste les fichiers dont l'extension est composée de deux caractères quels qu'ils soient et terminée par un x. Une des étapes d'interprétation de ces commandes par le shell consiste à remplacer les jokers par leur valeur ; ainsi, la dernière commande équivaut à :
$ ls guide-unix.aux guide-unix.texCe mécanisme de remplacement des jokers par une valeur se nomme en jargon (anglais) unix : pathname expansion ou globbing.
Notons ici que l'on peut bien évidemment composer les caractères « * » et « ? » et qu'il existe d'autres formes de joker, par exemple la séquence « […] » que nous ne présentons pas ici, et bien d'autres qui dépendent du shell utilisé. Il est pour l'instant utile de noter que ces caractères, même s'ils se rapprochent des expressions régulières présentées au paragraphe 3.5grep et la notion d'expressions régulières, ne doivent pas être confondues avec icelles…
2-2. Utilisateurs▲
unix a été conçu comme un système multi-utilisateur, ce qui signifie que chaque utilisateur est identifié sur le système par un utilisateur logique auquel correspond un certain nombre de droits ou privilèges. À un utilisateur sont, entre autres, associés :
- un numéro ou identificateur : l'uid (pour user identifier) ;
- une chaîne de caractères se rapprochant généralement de l'état civil, appelée login name ;
- le groupe auquel l'utilisateur appartient, et éventuellement d'autres groupes d'utilisateurs supplémentaires ;
- un répertoire privé (home directory) ;
- un shell qui sera utilisé par défaut après la connexion.
On peut savoir sous quel utilisateur logique on est connecté grâce à la commande whoami :
$ whoami
djobi
$En plus de son nom, un utilisateur est identifié en interne par son uid ou user identifier. D'autre part un utilisateur appartient à un ou plusieurs groupes d'utilisateurs. Chacun de ces groupes est également identifié par son nom et un numéro appelé gid ou group identifier. On peut connaître l'identité d'un utilisateur par la commande id :
$ id lozano
uid=208(lozano) gid=200(equipe) groups=200(equipe),300(image)
$l'utilisateur lozano appartient aux groupes equipe et image. C'est généralement l'administrateur du système qui décide de regrouper les utilisateurs dans des groupes qui reflètent la structure des personnes physiques qui utilisent les ressources informatiques.
Chacun de ces groupes se voit généralement attribuer un ensemble de privilèges qui lui est propre.
Pour terminer avec les utilisateurs, sachez qu'en général un utilisateur ne peut intervenir que sur un nombre limité d'éléments du système d'exploitation. Il peut :
- créer des fichiers dans une zone particulière appelée home directory ou répertoire privé ou tout simplement home. En fonction de la configuration du système, les utilisateurs pourront bien sûr écrire dans d'autres zones. Le répertoire privé est désigné dans le shell par « ˜ » :
$ echo ~
/home/utilisateurs/djobi
$- influer sur le cours des programmes qu'il a lui-même lancé ;
- autoriser ou interdire la lecture ou l'écriture des fichiers qu'il a créés.
Il ne peut pas :
- effacer les fichiers d'un autre utilisateur sauf si ce dernier l'y autorise (en positionnant les droits corrects sur le répertoire contenant le fichier en question) ;
- interrompre des programmes lancés par un autre utilisateur (là aussi, sauf s'il y est autorisé par l'utilisateur en question) ;
- créer des fichiers « n'importe où ».
Par conséquent une machine gérée par un système d'exploitation de type unix ne peut pas être compromise par hasard ou maladresse par un utilisateur. Puisqu'il faut bien (maintenance, mise à jour, etc.) que certains fichiers soient modifiés, il existe au moins un utilisateur possédant tous les privilèges sur le système : l'utilisateur dont l'uid est 0 portant généralement le nom de root (car son répertoire racine était souvent installé à la racine (root en anglais) du système de fichier). Cet utilisateur a la possibilité et le droit d'arrêter le système, d'effacer tous les fichiers (!), de créer des utilisateurs, et bien d'autres choses qui constituent ce que l'on nomme communément l'administration système. Dans une structure où le nombre de machines à administrer est conséquent, il se cache plusieurs personnes physiques derrière cet uid 0.
2-3. Le système de fichiers▲
Le système de fichiers d'unix est une vaste arborescence dont les nœuds sont des répertoires et les feuilles des fichiers. Le terme de fichier s'entend ici dans un sens très large, puisque sous unix, un fichier peut contenir des données, mais peut aussi être un lien sur un autre fichier, un moyen d'accès à un périphérique (mémoire, écran, disque dur…) ou un canal de communication entre processus. Pour embrouiller un peu plus le tout, les répertoires sont eux aussi des fichiers. Nous nous intéresserons ici aux fichiers normaux (regular en anglais), c'est-à-dire ceux qui contiennent des données ou sont des exécutables, ainsi qu'aux liens et aux répertoires.
2-3-1. Référencement des fichiers et des répertoires▲
Pour manipuler un fichier ou un répertoire d'un système de fichiers, l'utilisateur a besoin de les nommer, en d'autres termes il a besoin de pouvoir désigner un fichier particulier de l'arborescence des fichiers et ceci de manière univoque. Il existe pour ce faire, deux moyens : les références absolues et les références relatives, toutes deux décrites ci-après.
2-3-1-a. Référence absolue▲
Pour désigner un élément de l'arborescence en utilisant une référence absolue, on part de la racine du système de fichier et on « descend » jusqu'au fichier ou répertoire.
De cette manière on désignera les fichiers bidule.dat et truc.txt de l'arborescence donnée en exemple à la figure 2.2 par :
/users/bidule.dat
/home/eleves/truc.txtLe caractère / joue deux rôles :
- d'une part il désigne le répertoire racine (root directory en anglais) ;
- d'autre part il fait usage de séparateur de répertoires dans l'écriture des références de fichiers et répertoires.
Pour désigner un répertoire on utilisera le même principe, ainsi les répertoires eleves et users ont comme référence absolue :
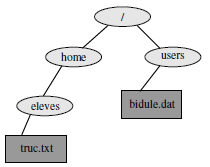
/home/eleves
/users2-3-1-b. Référence relative▲
Il est souvent utile de désigner les fichiers et répertoires grâce à une référence relative. Dans ce cas on référencera un fichier ou un répertoire relativement à un répertoire de base. Par exemple :
-
si /users est le répertoire de base, alors il est possible de référencer les fichiers bidule.dat et truc.txt comme suit :
Sélectionnez./bidule.dat ../home/eleves/truc.txt - si /home est le répertoire de base, alors on peut les référencer comme suit :
../users/bidule.dat
./eleves/truc.txtDeux répertoires particuliers existent dans chaque répertoire :
- le répertoire . qui désigne le répertoire courant ;
- le répertoire .. qui désigne le répertoire parent.
On pourra noter que l'écriture ./bidule.dat est redondante et peut être abrégée en bidule.dat. Enfin, le répertoire de référence dont il a été question est souvent le répertoire dit courant ou répertoire de travail (working directory en anglais). C'est le répertoire associé à chaque processus. C'est aussi le répertoire « dans lequel on se trouve » lorsqu'on lance une commande.
Le répertoire « . » a également une utilisation importante lorsqu'on veut exécuterExécution un programme situé dans le répertoire courant, ce dernier ne se trouvant pas dans la liste des répertoires de recherche de la variable PATH.
Dans toutes les commandes unix qui manipulent des fichiers ou des répertoires, l'utilisateur est libre de désigner ces fichiers ou répertoires par le truchement des références absolues ou des références relatives. Le choix (relative ou absolue) est souvent dicté par le nombre le plus faible de touches de clavier à presser…
2-3-2. Arborescence▲
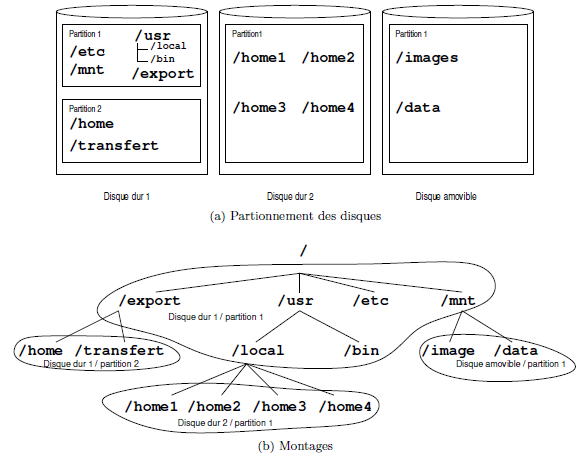
Pour comprendre le fonctionnement de l'arborescence d'un système de fichiers unix, supposons que la machine que nous utilisons soit composée des deux disques durs et du disque amovible de la figure 2.3b. Sous unix, une telle configuration de disques peut se présenter sous la forme de la figure 2.3a. En jargon unix, on dit que chaque partition est « montée sur » (de la commande mount) ou « greffée sur » un répertoire particulier. Dans notre exemple :
- la partition 1 du disque dur 1 est montée sur la racine (/) ;
- la partition 2 du disque dur 1 est montée sur /export ;
- la partition 1 du disque dur 2 est montée sur /usr/local ;
- la partition 1 du disque amovible est montée sur /mnt.
Ce qu'il faut retenir, c'est que, quelle que soit la configuration des disques sous-jacente au système, il n'y a toujours qu'une seule racine (répertoire /) et donc une seule arborescence.
Chaque partition est greffée en un point particulier de l'arborescence globale
- on parle également de filesystem pour désigner la sous-arborescence greffée(39).
Notons également que différents mécanismes existent sous unix pour greffer des systèmes de fichiers distants c.-à-d. résidant sur une machine accessible via le réseau. Le plus utilisé actuellement est le système NFS (network filesystem) introduit par Sun.
Chaque nœud de l'arborescence est identifié en interne de manière univoque par deux nombres :
- le numéro de la partition ;
- le numéro du nœud appelé inode ou index node.
En d'autres termes, chaque fichier possède un numéro qui est unique sur la partition où il réside. On peut visualiser l'inode d'un fichier grâce à l'option i de la commande ls :
$ ls -i *.tex
65444 guide-unix.tex
$ici, 65444 est l'inode du fichier guide-unix.tex. Sur le système où est tapé ce document, les fichiers suivants ont le même inode :
$ ls -i /lib/modules/2.2.12-20/misc/aedsp16.o
19 /lib/modules/2.2.12-20/misc/aedsp16.o
$ ls -i /usr/X11R6/man/man1/identify.1
19 /usr/X11R6/man/man1/identify.1
$ce qui s'explique par le fait que le répertoire lib appartient à la partition / alors que X11R6 appartient à une partition différente montée sur le répertoire /usr. Pour examiner les partitions de notre système, on peut utiliser la commande df avec l'option -h (pour human readable) :
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hda1 194M 42M 142M 23% /
/dev/hda7 1.1G 566M 508M 53% /home/dev/hda5 791M 606M 144M 81% /usr
/dev/sda4 96M 95M 584k 99% /mnt/zip
/dev/hdb 643M 643M 0 100% /mnt/cdrom
$Cette commande affiche donc pour chaque partition le fichier device associé (sous la forme /dev/xxx) sa taille respective ainsi que son taux d'occupation. Les informations indiquant où doit être montée chacune des partitions sont généralement stockées dans un fichier nommé /etc/fstab.
L'option -h est une option de la version gnu de la commande df. Votre sarcastique serviteur vous invitera donc à méditer sur ces programmes censés produire des résultats « lisibles par un être humain ». Mais ne vous méprenez pas, les systèmes unix dont la commande df ne dispose pas de l'option -h sont quand même destinés aux humains…
2-3-3. Privilèges▲
Il faut savoir que sous unix, on associe à chaque fichier trois types de propriétaires :
- l'utilisateur propriétaire ;
- le groupe propriétaire ;
- les autres utilisateurs.
La norme POSIX apporte une extension à ce principe connue sous le nom acces control list (ACLAccess control list (ACL)), permettant de recourir si nécessaire à un réglage plus fin que les trois entités ci-dessus. Cette extension est présentée au paragraphe 2.3.10Access control list (ACL).
Chaque fichier possède un certain nombre d'attributs. Un sous-ensemble de ces attributs a trait aux privilèges ou droits qu'ont les utilisateurs lors de l'accès à un fichier donné. Il y a trois types de privilèges :
- le droit de lire (read) signalé par la lettre r ;
- le droit d'écrire (write) signalé par la lettre w ;
- le droit d'exécuter (execute) signalé par la lettre x.
Ces trois types de droits associés aux trois types de propriétaires forment un ensemble d'informations associées à chaque fichier ; ensemble que l'on peut examiner grâce à la commande ls :
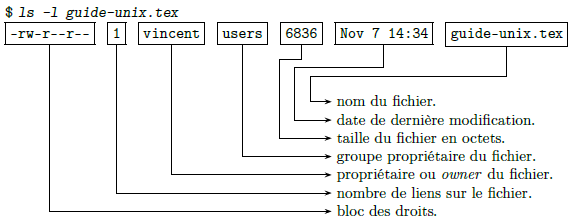
Nous verrons au paragraphe 2.3.9Liens la signification du terme « lien » sur un fichier. Examinons d'un peu plus près le bloc des droits :

Autre exemple :
$ ls -l /usr/bin/env
-rwxr-xr-x 1 root root 6852 Aug 18 04:31 /usr/bin/env
$Le fichier /usr/bin/env appartient à l'utilisateur root et au groupe root. Seul l'utilisateur root peut le modifier et tout le monde peut l'exécuter y compris les membres du groupe root :
- rwx : droits du propriétaire (read, write, exécutable) ;
- r-x : droits du groupe (read, executable) ;
- r-x : droits des autres (read, executable).
Pour être plus précis, on peut dire que le fichier /usr/bin/env appartient à l'utilisateur dont l'uid est 0 et que la commande ls affiche le premier nom correspondant à cet uid. Tous les autres utilisateurs ayant le même uid sont également en mesure de le modifier.
Un dernier exemple :
$ ls -l ~/
drwxr-xr-x 3 vincent users 4096 Nov 7 12:48 LaTeX
drwxr-xr-x 2 vincent users 4096 Nov 7 14:40 bin
$Cette commande liste le répertoire privé de l'utilisateur (caractère ˜) et affiche ici les droits des deux répertoires qui y résident :
- d : le fichier est un répertoire ;
- rwx : droits du propriétaire (read, write, exécutable) ;
- r-x : droits du groupe (read et exécutable) ;
- r-x : droits des autres (read et exécutable) ;
- les nombres 3 et 2 indiquent le nombre de sous-répertoires contenus dans LaTeX et bin respectivement.
Il faut noter ici une particularité du système unix : un répertoire doit être exécutable pour pouvoir y pénétrer, on parle alors de search permission en anglais. Dans l'exemple ci-dessus, tout le monde y compris les membres du groupe users a le droit d'accéder aux répertoires LaTeX et bin.
2-3-4. Parcourir l'arborescence▲
Pour connaître le répertoire courant (i.e. celui où on se trouve au moment où on tape la commande) on peut taper la commande pwd (print working directory). Notez que ce répertoire courant peut toujours être désigné par le caractère « . »
$ pwd
/home/vincent/LaTeX/cours
$À chaque utilisateur est associé un répertoire privé ou home directory. C'est le répertoire courant après la procédure de login. Pour se rendre dans ce répertoire, on peut taper la commande cd sans argument :
$ cd
$ pwd
/home/vincent
$/home/vincent est donc le répertoire privé de l'utilisateur vincent. Si l'utilisateur est lozano, les commandes suivantes sont équivalentes à la commande cd sans argument :
$ cd ~
$ cd $HOME
$ cd ~lozano
$On peut à tout moment changer de répertoire avec la commande cd (change directory) qui prend en argument un répertoire, par exemple :
$ cd /usr/local
$Et, pour illustrer l'utilisation d'une référence relative :
$ cd /usr
$ ls -l
drwxr-xr-x 8 root root 4096 Sep 25 00:21 X11R6
drwxr-xr-x 2 root root 20480 Nov 5 19:16 bin
drwxr-xr-x 11 root root 4096 Nov 5 18:56 local
$ cd local <------------------------ utilisation d'une référence relative
$Enfin pour donner un exemple d'utilisation du répertoire « .. » désignant le répertoire père :
$ pwd
/usr/local
$ cd ..
$ pwd
/usr
$2-3-5. Manipuler les fichiers▲
Les opérations courantes sur les fichiers sont la copie, le déplacement ou renommage et l'effacement. Commençons par la copie :
$ cd ~/LaTeX/cours
$ ls *.tex
truc.tex
$ cp truc.tex muche.tex
$ ls -l *.tex
-rw-r--r-- 1 vincent users 1339 Nov 7 21:48 truc.tex
-rw-r--r-- 1 vincent users 1339 Nov 7 21:51 muche.tex
$la commande cp (copy) copie donc le fichier donné en premier argument vers le fichier donné en deuxième argument. Cette commande accepte également la copie de un ou plusieurs fichiers vers un répertoire :
$ cp /usr/local/bin/* .
$cette commande copie tous les fichiers (sauf les sous-répertoires) contenus dans le répertoire /usr/local/bin dans le répertoire courant.
Pour déplacer un fichier, on dispose de la commande mv (move). De manière quelque peu analogue à la commande cp, la commande mv accepte deux formes. La première permet de renommer un fichier :
$ ls *.tex
guide-unix.tex test.tex
$ mv test.tex essai.tex
$ ls *.tex
guide-unix.tex essai.tex
$L'autre forme a pour but de déplacer un ou plusieurs fichiers dans un répertoire :
$ mv essai.tex /tmp
$déplace le fichier essai.tex dans le répertoire /tmp.
La commande rm (remove) efface un fichier. Sous unix l'effacement d'un fichier est définitif, c'est pourquoi, pour des raisons de sécurité, l'effacement d'un fichier est généralement configuré par l'administrateur en mode interactif, c'est-à-dire que le shell demande à l'utilisateur une confirmation :
$ rm /tmp/esssai.tex
rm: remove `/tmp/essai.tex'?yes
$Ici toute autre réponse que « yes » ou « y » fait échouer la commande rm.
Si sur votre système la commande rm ne vous demande pas de confirmation, il faudra faire appel à l'option -i (pour interactif). Il est d'ailleurs assez courant de créer un aliasAlias et fonctions pour éviter de le préciser systématiquement.
2-3-6. Les répertoires dans tout ça ?▲
Et bien on peut en créer là où on a le droit, avec la commande mkdir (make directory) par exemple :
$ mkdir tmp
$ ls -l
...
drwxr-xr-x 2 vincent users 4096 Nov 7 22:13 tmp
$On peut également détruire un répertoire avec la commande rmdir (remove directory) à condition que le répertoire en question soit vide. On peut cependant effacer un répertoire non vide grâce à la commande rm et son option -r. Cette option permet d'effacer récursivement le contenu d'un répertoire :
$ rm -rf tmp
$efface le répertoire tmp ; l'option -f (force) est ici cumulée avec l'option de récursion et permet de forcer l'exécution de la commande rm en mode non-interactif. L'utilisateur n'est donc interrogé à aucun moment, c'est donc une forme à utiliser avec prudence…
2-3-7. Gestion des supports amovibles▲
Une des grandes interrogations des utilisateurs novices d'unix concerne l'accès aux supports amovibles (disquettes, cédéroms et autres clés USB). L'accès à de tels périphériques dépend du système installé, mais dans tous les cas il consiste à greffer (monterArborescence) le système de fichiers du support amovible à un endroit précis de l'arborescence. Ce montage peut être réalisé manuellement avec la commande mount. Dans ce cas on trouvera dans le fichier /etc/fstab une ligne ressemblant à :
/dev/cdrom /cdrom iso9660 ro,user,noauto 0 0indiquant que l'utilisateur lambda a le droit de monter un système de fichiers au format Iso9660 contenu dans un cédérom, dans le répertoire /cdrom. L'utilisateur pourra donc se fendre d'un :
$ mount /cdrom
$pour avoir accès aux fichiers du dit cédérom à partir du répertoire /cdrom. Une fois la (ou les) opérations de lecture effectuée(s) l'utilisateur devra lancer un :
$ umount /cdrom
$pour détacher le système de fichiers du cédérom de l'arborescence du système, et pouvoir éjecter le disque du lecteur.
Certaines versions d'unix utilisent un système de montage automatique des systèmes de fichiers stockés sur supports amovibles. Dans ce cas l'accès au répertoire /cdrom, /mnt/cdrom, ou quelque chose de ce genre provoquera le montage automatique du cédérom.
2-3-8. Changer les droits▲
Le propriétaire - et lui seul - a le droit de changer les permissions associées à un fichier. Seul l'administrateur (utilisateur root) a la possibilité de changer le propriétaire d'un fichier (commande chown). Enfin le groupe propriétaire peut être changé par le propriétaire (chgrp).
La commande chmod permet au propriétaire d'un fichier d'en changer les droits d'accès soit pour partager des données avec d'autres utilisateurs, soit au contraire pour rendre des données sensibles inaccessibles. Cette commande consiste à modifier les privilèges des trois entités propriétaires d'un fichier (utilisateur, groupe et les autres). Il existe deux syntaxes de la commande chmod, la première est symbolique, l'autre numérique. Nous utiliserons ici plus volontiers la première en présentant quelques « études de cas » où l'on désire modifier les droits d'un fichier. Mais avant tout, posons-nous la question suivante :
2-3-8-a. Quels sont les droits par défaut ?▲
Les droits par défaut sont définis par l'intermédiaire d'un masque de création de fichier. En jargon unix, ce masque est appelé umask pour user file creation mask. Ce masque est associé à un utilisateur et précise quels droits aura par défaut un fichier lors de sa création. Pour connaître son umask :
$ umask -S
u=rwx,g=rx,o=rx
$Ce qui signifie qu'un fichier est créé avec par défaut :
- pour le propriétaire : tous les droits ;
- pour le groupe :
- droits en lecture ;
- droits en lecture et exécution pour les répertoires ;
- idem pour les autres.
Nous prendrons comme hypothèse pour nos études de cas que l'umask du système est celui donné par la commande umask -S ci-dessus. Créons un répertoire et un fichier dans ce répertoire :
$ mkdir echange
$ touch echange/donnees.txt
$La commande touch change les attributs de date d'un fichier en le créant s'il n'existe pas. On peut alors examiner les droits sur ces fichiers :
$ ls -ld echange
drwxr-xr-x 2 vincent users 4096 Nov 18 23:06 echange
$ ls -l echange
-rw-r--r-- 1 vincent users 6 Nov 15 21:22 donnees.txt
$2-3-8-b. Attributs d'un répertoire▲
En considérant le répertoire comme un « catalogue » contenant une liste de fichiers, on peut voir les trois types de droits comme suit :
- Lecture : compulser le catalogue, c'est-à-dire lister le contenu du répertoire avec la commande ls par exemple.
- Écriture : modifier le catalogue, donc effacer les fichiers, les renommer, les déplacer.
- Exécution : cet attribut permet à un utilisateur de pénétrer dans ce répertoire et d'accéder aux fichiers qui s'y trouvent.
Voyons plus précisément grâce à un exemple :
$ chmod g-r echange
$ ls -ld echange
drwx--xr-x 2 vincent users 4096 Nov 20 18:03 echange
$la commande chmod ci-dessus retire aux membres du groupe users le droit de lire le répertoire echange. C'est pourquoi lorsqu'un utilisateur autre que vincent (appelons-le rene), mais du groupe users, lance la commande :
$ ls ~vincent/echange
ls: /home/vincent/echange/: Permission denied
$elle échoue, faute de privilèges suffisants. Ici c'est le droit d'examiner le contenu du répertoire qui n'est pas accordé. Par contre, la commande :
$ cat ~vincent/echange/donnees.txt
$est légitime, puisque l'attribut x pour le groupe du répertoire echange est présent et permet à l'utilisateur rene d'accéder aux fichiers qu'il contient. C'est pourquoi, si l'on supprime aussi le droit d'exécution sur le répertoire echange pour le groupe users, comme ceci :
$ chmod g-x echange
$ ls -ld echange
drwx---r-x 2 vincent users 4096 Nov 20 18:03 echange
$la commande suivante, lancée par rene échoue faute de droits suffisants :
$ cat ~vincent/echange/donnees.txt
cat: /home/vincent/echange/donnees.txt: Permission denied
$Il faut comprendre qu'un utilisateur ayant les droits d'écriture sur un répertoire peut effacer tous les fichiers qu'il contient quels que soient les droits et propriétaires de ces fichiers.
2-3-8-c. Autoriser un membre du groupe à lire un fichier▲
Avec le umask du paragraphe précédent, les membres du groupe propriétaire sont autorisés à lire un fichier nouvellement créé dans un répertoire nouvellement créé. En effet :
- le répertoire qui contient le fichier est exécutable pour le groupe en question ;
- le fichier est lisible pour le groupe.
2-3-8-d. Autoriser un membre du groupe à modifier un fichier▲
Pour autoriser un membre du groupe propriétaire du fichier donnees.txt du répertoire echange à modifier un fichier il suffit d'activer l'attribut w pour le groupe avec la commande chmod (en supposant que le répertoire courant est echange) :
$ chmod g+w donnees.txt
$ ls -l donnees.txt
-rw-rw-r-- 1 vincent users 40 Nov 2 18:03 donnees.txt
$2-3-8-e. Interdire aux autres la lecture d'un fichier▲
Pour des raisons diverses, on peut vouloir interdire la lecture d'un fichier aux utilisateurs n'appartenant pas au groupe du fichier. Pour ce faire, la commande :
$ chmod o-r donnees.txt
$ ls -l donnees.txt
-rw-rw---- 1 vincent users 0 Nov 20 18:03 donnees.txt
$interdit aux « autres » l'accès en lecture à donnees.txt.
2-3-8-f. Autoriser au groupe la suppression d'un fichier▲
Lorsqu'un fichier est supprimé du système de fichier, le répertoire qui le contient est également modifié, car ce dernier contient la liste des fichiers qu'il héberge. Par conséquent, il n'est pas nécessaire d'activer l'attribut w sur un fichier pour pouvoir l'effacer, il faut par contre s'assurer que cet attribut est actif pour le répertoire qui le contient. Dans le cas qui nous préoccupe, la commande :
$ ls -ld echange
drwx---r-x 2 vincent users 4096 Nov 20 18:03 echange
$ chmod g+rwx echange
$ ls -ld echange
drwxrwxr-x 2 vincent users 4096 Nov 20 18:03 echange
$accorde tous les droits (dont l'attribut w) au groupe propriétaire sur le répertoire echange ; ce qui permet à l'utilisateur rene de pouvoir effacer le fichier donnees.txt.
2-3-8-g. Notation symbolique et notation octale▲
La commande chmod telle qu'on l'a vue jusqu'à présent obéit à la syntaxe suivante :

Les arguments de la commande chmod peuvent être constitués de plusieurs blocs p%a. Le cas échéant ils doivent être séparés par des virgules. Les commandes suivantes sont donc correctes :
$ chmod o-rwx bidule
$ chmod g+rx bidule
$ chmod -w,o+x bidule
$ chmod a+r bidule
$Dans l'ordre, chacune des commandes précédentes :
- enlève tous les droits aux autres ;
- donne les droits en lecture et exécution pour les membres du groupe propriétaire ;
- enlève le droit en écriture pour tout le monde et rajoute le droit en exécution pour les autres ;
- donne à tout le monde le droit en lecture.
On notera donc que sans indication de propriétaires, tous sont concernés et ceci en accord avec le umask. D'autre part l'option -R de la commande chmod permet d'affecter le mode spécifié de manière récursive aux fichiers contenus dans les sous-répertoires.
Mais venons-en au fait : certains puristes utilisent ce qu'on appelle la notation octale pour positionner les droits d'un fichier. Cette notation consiste a coder chaque bloc rwx du bloc de droits en une donnée numérique de la manière suivante :
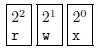
On a alors, par exemple :
- -rwx------ codé par 700 ;
- -rw-r-xr-x codé par 655 ;
- -rw-r--r-- codé par 644.Ce codage octal peut être utilisé en lieu et place des symboles gor et rwx avec la commande chmod. Il est également intéressant de noter qu'on peut afficher le umask en notation octale :
$ umask
022
$Cette valeur est le complément par rapport à 777. Avec un tel masque, les fichiers sont créés avec les permissions 755.
2-3-9. Liens▲
Une des notions un peu « troublantes » du système de fichiers d'unix est la notion de lien. Comme on l'a vu précédemment, en interne, le système identifie les fichiers par un numéro : l'inode.
2-3-9-a. Liens physiques▲
L'opération qui consiste à relier un fichier (un ensemble d'octets sur un disque) à un nom sur l'arborescence est précisément la création d'un lien physique. Soit le fichier ~/doc/unix/guide.tex :
$ cd ~/doc/unix
$ ls -li guide.tex
38564 -rw-r--r-- 1 vincent users 18114 Nov 7 22:44 guide.tex
$on constate que ce fichier (créé par un éditeur de texte) a pour inode 38564, et ne possède qu'un lien (~/doc/unix/guide.tex).
On peut créer un nouveau lien sur ce fichier éventuellement dans un répertoire différent si ce répertoire est sur la même partition que le fichier guide.tex, grâce à la commande ln (link) dont la syntaxe est :
- ln cible du lien nom du lien
Par exemple :
$ cd ~/tmp
$ ln ~/doc/unix/guide.tex unix.tex
$ ls -li unix.tex
38564 -rw-r--r-- 2 vincent users 18114 Nov 7 22:44 unix.tex
$on peut alors constater (figure 2.4) que le fichier unix.tex possède maintenant deux liens physiques. Dans cette situation, il y a donc une seule représentation des données sur le disque - ce qui est confirmé par l'inode qui est identique (38564) pour les deux liens - et deux noms associés à cette représentation :
- ~/doc/unix/guide.tex
- ~/tmp/unix.tex
Ce qui implique que l'on peut modifier le fichier par le biais de l'un ou l'autre des liens. Pour ce qui est de la suppression d'un lien, la règle est la suivante :
- tant que le nombre de liens physiques sur le fichier en question est strictement supérieur à 1, la commande rm aura pour effet la suppression du lien et non des données.
- lorsque le nombre de liens physiques est égal à 1, rm efface effectivement les données, puisqu'il n'y a plus qu'un lien unique sur celles-ci.
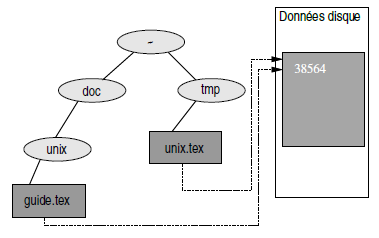
Pour être très précis, si le fichier en question est ouvert par au moins un processus, le lien disparaîtra après la commande rm mais l'espace qu'occupent les données ne sera libéré que quand le dernier processus ayant ouvert le fichier se terminera.
2-3-9-b. Liens symboliques▲
Lorsque l'on veut lier un fichier par l'intermédiaire d'un lien ne se trouvant pas sur la même partition que le fichier lui-même, il est nécessaire de passer par l'utilisation d'un lien dit symbolique. Nous allons par exemple créer un lien symbolique sur notre fichier guide-unix.tex depuis le répertoire /tmp se trouvant sur une autre partition :
$ cd /tmp
$ ln -s ~/doc/unix/guide.tex test.tex
$ ls -l test.tex
lrwxrwxrwx 1 vincent users 32 Nov 21 16:41 test.tex -> /hom
e/vincent/doc/unix/guide.tex
$Les liens résultants sont indiqués à la figure 2.5.
On remarquera les particularités d'un lien symbolique :
- c'est un fichier différent de celui sur lequel il pointe ; il possède son propre inode :
$ ls -i test.tex
23902 test.tex
$- le fichier contient une référence sur un autre fichier, ce qui explique par exemple que la taille du lien symbolique test.tex est de 32, qui correspond aux nombres de caractères du chemin du fichier auquel il se réfère ;
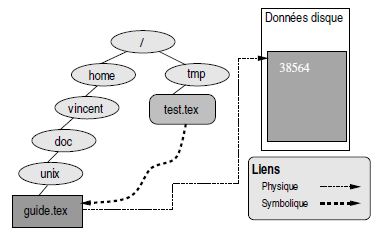
- un lien symbolique est un fichier spécial dont on ne peut changer les permissions, ce qui est indiqué par le bloc de droits :
lrwxrwxrwxLa plupart des opérations sur le lien symbolique est effectuée sur le fichier sur lequel il pointe. Par contre la suppression de ce lien obéit aux règles suivantes :
- la commande rm supprime le lien symbolique lui-même - qui est un fichier à part entière - et n'a pas d'influence sur le fichier auquel il se réfère ;
- par conséquent, si on supprime le fichier, le lien symbolique existe toujours et pointe sur un fichier qui n'existe pas.
Enfin la dernière particularité du lien symbolique (qui le distingue du lien physique) provient du fait qu'il est possible de créer un tel lien sur un répertoire. Par exemple :
$ cd
$ ln -s /usr/share/texmf/tex/latex macros
$ ls -l macros
lrwxrwxrwx 1 vincent users 26 Nov 21 17:02 macros -> /usr/sh
are/texmf/tex/latex
$il est alors possible d'utiliser le lien symbolique comme un raccourci vers un autre répertoire. Notons à ce sujet que la notion de lien symbolique d'unix, peut s'apparenter à celle de raccourci de Windows®. Cependant l'utilisateur attentif de ce dernier système aura remarqué que les raccourcis ne constituent juste qu'une aide à l'environnement graphique, mais qu'il est impossible de traiter le raccourci comme un véritable fichier ou répertoire le cas échéant.
2-3-10. Access control list (ACL)▲
2-3-10-a. Limites de la gestion des privilèges▲
Nous avons vu à partir de la section 2.3.3Privilèges consacrée aux privilèges sur les fichiers et répertoires que par défaut un système unix attache trois privilèges à un fichier :
- les privilèges de l'utilisateur propriétaire.
- ceux du groupe propriétaire.
- ceux des autres.
Par conséquent la finesse du réglage des accès ne peut se faire qu'au niveau du groupe.
En d'autres termes pour rendre un fichier accessible en lecture et écriture à un utilisateur et uniquement à lui, il n'y a pas d'autre solution que de créer un groupe auquel appartient, puis d'accorder les droits de lecture et d'écriture au groupe.
Imaginons que deux utilisateurs - dont les noms de connexion sont andy et debrah - veuillent collaborer sur le contenu d'un fichier poodle.dat. Tout d'abord, l'administrateur doit créer un groupe (nommons-le zircon) puis faire en sorte que andy et debrah deviennent membres de ce groupe. Ensuite l'utilisateur initialement propriétaire du fichier poodle.dat (par exemple andy) doit positionner les privilèges sur celui-ci :
$ ls -l poodle.dat
-rw-r--r-- 1 andy users 3100 2009-05-11 22:51 poodle.dat
$ chgrp zircon poodle.dat
$ chmod g+rw poodle.dat
$ ls -l poodle.dat
-rw-rw-r-- 1 andy zircon 3100 2009-05-11 22:51 poodle.dat
$À partir de maintenant, l'utilisateur debrah peut lire et modifier le contenu du fichier poodle.dat.
Le problème ici est que la création du groupe n'est possible que pour l'administrateur du système qui seul peut ajouter un nouveau groupe d'utilisateurs. En outre si un autre utilisateur souhaitait se greffer au projet, il faudrait à nouveau lui faire une demande pour ajouter le nouveau venu au groupe. On voit donc clairement que la gestion des privilèges proposée par défaut dans unix a l'inconvénient d'être trop statique pour l'exemple présenté ci-dessus.
2-3-10-b. Introduction aux ACL▲
Nous vous proposons donc ici de découvrir quelques commandes permettant de régler les privilèges plus finement et de manière plus autonome. La gestion des ACL sous unix repose essentiellement sur deux commandes :
Le système de fichier devra supporter les ACL. Sous le système gnu/LINUX il faudra le spécifier explicitement dans les options de montage contenues dans le fichier /etc/fstab. Le système de votre serviteur contient par exemple :
/dev/sdb5 /home ext3 acl,defaults 0 2indiquant que la partition /dev/sdb5 est montée dans le répertoire /home avec support pour les ACL.
Accorder des droits à un utilisateur - Reprenons l'exemple de nos deux compères andy et debrah souhaitant tous deux collaborer sur le fichier poodle.dat :
$ ls -l poodle.dat
-rw-r--r-- 1 andy users 3100 2009-05-11 22:51 poodle.dat
$Pour autoriser debrah à lire et modifier le fichier en question, andy devra taper :
$ setfacl -m u:debrah:rw poodle.dat
$La syntaxe
- setfacl -m u:user:perm fichier
permet donc de modifier (c'est le sens de l'option m) les autorisations de l'utilisateur user (argument u:). Les autorisations perm peuvent être définies en utilisant la notation symbolique présentée au paragraphe 2.3.3Privilèges.
Comme la commande chmod, setfacl autorise l'option -R pour accorder les droits spécifiés à tous les fichiers et sous-répertoires, récursivement.
Examiner les autorisations associées à un fichier L'option -l de la commande ls propose un affichage légèrement modifié lorsque des autorisations ACLs sont associées à un fichier :
$ ls -l poodle.dat
-rw-rw-r--+ 1 andy users 3100 2009-05-11 22:51 poodle.dat
$Notez la présence du signe +. La commande getfacl permet de lister les permissions associées :
$ getfacl poodle.dat
# file: poodle.dat
# owner: lozano <----------------------------------- propriétaire
# group: lozano <---------------------------- groupe propriétaire
user::rw- <------------------------------- droits du propriétaire
user:debrah:rw- <----------------- droits de l'utilisateur debrah
group::r-- <----------------------- droits du groupe propriétaire
mask::rw- <----------------------------------------- cf. plus bas
other::r-- <----------------------------------- droits des autres
$Accorder des droits par défaut dans un répertoire - Grâce à l'option -d de la commande setfacl on peut accorder des droits par défaut à un répertoire. En reprenant l'exemple précédent, la commande :
$ setfacl -d -m u:muffin:rw .
$permet d'autoriser la lecture et l'écriture à l'utilisateur muffin pour tous les fichiers créés dans le répertoire courant. En d'autres termes, tous les fichiers créés par la suite seront lisibles et modifiables par l'utilisateur muffin.
Attention, la commande de l'exemple ci-dessus n'accorde pas à l'utilisateur muffin de créer des fichiers dans le répertoire courant.
Enfin, les droits par défaut peuvent être retirés avec l'option -k. Ici la commande :
$ setfacl -k .
$supprime les droits par défaut sur le répertoire courant.
Révoquer des droits - Pour supprimer les droits ajoutés avec la setfacl et son option -m on peut utiliser :
- l'option -b pour supprimer tous les droits de type ACL
- l'option -x pour supprimer une entrée, par exemple :
$ setfacl -x u:debrah poodle.dat
$révoque les droits accordés sur le fichier poodle.dat à l'utilisateur debrah.
Masque ACL - Lorsqu'au moins un privilège de type ACL a été accordé à un fichier, un masque est créé contenant l'union de toutes les autorisations. Ce masque est construit automatiquement, ainsi :
$ setfacl -m u:dinah:r righthereonthe.floora
$ setfacl -m u:moe:r righthereonthe.floora
$ setfacl -m u:hum:rw righthereonthe.floora
$Le masque créé et affiché par la commande getfacl sera :
$ getfacl righthereonthe.floora
[...]
user::dinah:r--
user::moe:r--
user::hym:rw-
[...]
mask::rw- <--------------- union des trois permissions précédentes
[...]
$L'intérêt de ce masque réside dans le fait qu'il peut être modifié pour appliquer une politique pour tous les utilisateurs. Par exemple pour ne conserver que le droit en lecture pour tous les utilisateurs ACL, on peut exécuter la commande suivante :
$ setfacl -m m::r righthereonthe.floora
$2-4. Processus▲
Le système unix est multitâche et multi-utilisateur. Le noyau gère l'ensemble des processus grâce à un programme appelé l'ordonnanceur (scheduler). Ce dernier a pour but d'accorder aux processus du temps-CPU, et ceci chacun à tour de rôle, en fonction de priorités le cas échéant. Ainsi, un processus peut se trouver dans quatre états :
- actif : le processus utilise le CPU
- prêt : le processus attend que l'ordonnanceur lui fasse signe
mais également :
- endormi : le processus attend un événement particulier (il ne consomme pas de CPU dans cet état) ;
- suspendu : le processus a été interrompu par un signalModifier le déroulement d'un processus.
Chaque processus possède un numéro qui l'identifie auprès du système. Ce numéro est appelé son pid ou process identifer. On verra plus bas que chaque processus à l'exception du tout premier créé, possède un processus père qui lui donne naissance. Ainsi l'ensemble des processus d'un système unix constitue un arbre de processus.
On notera ici qu'à la notion de processus, on associe généralement la notion de terminal. Un terminal est un canal de communication entre un processus et l'utilisateur.
Il peut correspondre à un terminal physique comme un écran ou un clavier, mais aussi à ce qu'on appelle un émulateur de terminal comme une fenêtre XTerm. Dans les deux cas un fichier spécial dans le répertoire /dev (par exemple /dev/tty1 est la première console en mode texte, sous Linux) est associé au terminal, et les communications se font par le biais d'appels système sur ce fichier. La variable TERM informe les applications sur le comportement du terminal (entre autres choses, la manière dont les caractères de contrôle seront interprétés).
2-4-1. Examiner les processus▲
La commande ps permet d'examiner la liste des processus « tournant » sur le système. Cette commande comprend un nombre très important d'options qui sont généralement différentes selon les systèmes, il n'est donc pas question ici de les passer toutes en revue (pour ça il suffit de taper man ps !). Voyons tout de même quelques exemples instructifs.
Notez qu'un certain nombre d'options de la commande ps a fait l'objet de standardisation notamment au travers de la Single Unix Specification (SUS) portée par l'Open Group, consortium ayant pour but de standardiser ce que devrait être un système unix. Par exemple, la commande ps de la distribution Debian actuelle est censée respecter les recommandations de la SUS version 2. Encore une fois, vous trouverez dans ce qui suit des options ne respectant pas nécessairement tous ces standards, veuillez nous en excuser par avance.
2-4-1-a. Ceux du terminal▲
J'ai lancé Emacs (éditeur de texte grâce auquel je tape ce document) dans une fenêtre xterm ; voici ce que me donne la commande ps dans cette fenêtre :
$ ps
PID TTY TIME CMD
1322 ttyp2 00:00:43 bash
1337 ttyp2 00:02:04 emacs
1338 ttyp2 00:00:00 ps
$On obtient donc une liste dont la première colonne contient le pid de chaque processus, chacun de ces processus est associé au pseudoterminal du xterm désigné par ttyp2. La dernière colonne donne le nom de la commande associée au processus ; le temps donné ici est le temps CPU utilisé depuis le lancement de la commande.
On pourra noter que puisque la commande ps est lancée pour obtenir la liste des processus, son pid apparaît également dans la liste (ici pid 1338).
2-4-1-b. Ceux des autres terminaux▲
L'option x de la commande ps permet de lister les processus de l'utilisateur qui ne sont par rattachés au terminal courant(40):
$ ps x
PID TTY STAT TIME COMMAND
345 ? S 0:00 bash /home/vincent/.xsession
359 ? S 0:01 fvwm2
1254 ttyp0 S 0:00 lynx /usr/doc/vlunch/index.html
1354 ttyp3 S 0:00 xdvi.bin -name xdvi guide-unix.dvi
29936 ttyp2 R 0:00 ps -x
$La nouvelle colonne STAT (status) donne l'état de chaque processus, ici S indique que le processus est endormi (sleeping), et R qu'il est prêt (runnable).
2-4-1-c. Ceux des autres utilisateurs▲
La syntaxe suivante permet d'obtenir la liste des processus lancés par un utilisateur du système :
$ ps -u rene
PID TTY TIME CMD
663 tty1 00:00:00 bash
765 ? 00:00:00 xclock
794 ttyp4 00:00:00 bash
805 ttyp4 00:00:00 mutt
$L'utilisateur rene est donc connecté sur la première console virtuelle, a lancé une horloge du système X window, et est vraisemblablement en train de lire son courrier.
2-4-1-d. Tous !▲
Enfin on veut parfois être en mesure de visualiser la liste de tous les processus sans critère restrictif de terminal ou d'utilisateur. Il y a encore une fois plusieurs voies pour atteindre ce but. La version de la commande ps de LINUX supporte plusieurs styles de syntaxes ; nous en donnons ci-dessous deux exemples :
$ ps aux
USER PID %CPU %MEM TTY STAT START TIME COMMAND
root 1 0.1 0.1 ? S 14:11 0:03 init [5]
root 2 0.0 0.0 ? SW 14:11 0:00 [kflushd]
root 3 0.0 0.0 ? SW 14:11 0:00 [kupdate]
root 4 0.0 0.0 ? SW 14:11 0:00 [kpiod]
root 5 0.0 0.0 ? SW 14:11 0:00 [kswapd]
root 210 0.0 0.3 ? S 14:12 0:00 syslogd -m 0
root 221 0.0 0.3 ? S 14:12 0:00 klogd
daemon 237 0.0 0.0 ? SW 14:12 0:00 [atd]
root 253 0.0 0.3 ? S 14:12 0:00 crond
root 284 0.0 0.3 ttyS0 S 14:12 0:00 gpm -t ms
$Cette commande liste sur le terminal tous les processus du système - ici elle est raccourcie bien évidemment. Cette forme de listing fournit également la date de démarrage du processus (champ START), ainsi que le pourcentage de CPU et de mémoire utilisés (%CPU et %MEM respectivement).
Il est également intéressant de noter que l'on peut suivre la séquence de démarrage du système d'exploitation : le premier programme lancé porte le pid 1 et se nomme init. Les processus suivants concernent les services de base du système unix. Voici une autre manière d'obtenir la liste complète des processus :
$ ps -ef
UID PID PPID STIME TTY TIME CMD
root 1 0 14:11 ? 00:00:03 init [5]
root 2 1 14:11 ? 00:00:00 [kflushd]
root 3 1 14:11 ? 00:00:00 [kupdate]
root 4 1 14:11 ? 00:00:00 [kpiod]
root 5 1 14:11 ? 00:00:00 [kswapd]
root 210 1 14:12 ? 00:00:00 syslogd -m 0
root 221 1 14:12 ? 00:00:00 klogd
daemon 237 1 14:12 ? 00:00:00 [atd]
root 253 1 14:12 ? 00:00:00 crond
root 284 1 14:12 ttyS0 00:00:00 gpm -t ms
$ici l'affichage est quelque peu différent. STIME est l'équivalent du START, et on a accès au ppid qui identifie le processus père d'un processus particulier. On remarquera dans cette liste que tous les processus sont des fils d'init - c'est-à-dire lancés par celui-ci. Ceci à l'exception d'init lui-même qui est le premier processus créé.
2-4-1-e. Personnaliser l'affichage▲
On peut se limiter à certaines informations en utilisant l'option o de la commande ps ; cette option permet de spécifier les champs que l'on désire voir s'afficher, par exemple :
$ ps -xo pid,cmd
PID CMD
346 [.xsession]
360 fvwm2 -s
363 xterm -ls -geometry 80x30+0+0
367 -bash
428 man fvwm2
$n'affiche que le pid et la commande d'un processus. On a combiné ici l'option o avec l'option x vue précédemment.
2-4-1-f. Lien de parenté▲
L'option --forest associée avec la commande précédente illustre l'arborescence des processus. On a isolé ici les processus associés à une session X ; on voit clairement grâce au « dessin » sur la partie droite, et à la correspondance entre pid et ppid, quelles sont les filiations des processus.
$ ps --forest -eo pid,ppid,cmd
PID PPID CMD
324 1 [xdm]
334 324 \_ /etc/X11/X
335 324 \_ [xdm]
346 335 \_ [.xsession]
360 346 \_ fvwm2 -s
448 360 \_ xterm -ls
451 448 | \_ -bash
636 451 | \_ ps --forest -eo pid,ppid,cmd
576 360 \_ /usr/X11R6/lib/X11/fvwm2/FvwmAuto
577 360 \_ /usr/X11R6/lib/X11/fvwm2/FvwmPager
$2-4-2. Modifier le déroulement d'un processus▲
Il existe au moins trois manières de modifier le déroulement normal d'un processus :
- changer la priorité d'un processus avec la commande nice ;
- utiliser la commande kill. Cette commande permet à partir du pid d'un processus, d'envoyer ce qu'on appelle en jargon unix, un signal à ce processus. En tant qu'utilisateur du système, on envoie généralement des signaux pour interrompre, arrêter ou reprendre l'exécution d'un programme ;
- utiliser le contrôle de tâche (job control) depuis le shell. Ce mécanisme permet de modifier le déroulement des programmes s'exécutant dans un terminal donné.
2-4-2-a. Priorité d'un processus▲
Par défaut un processus lancé par un utilisateur a la même priorité que celui d'un autre utilisateur. Dans la situation où l'on désire lancer un processus « gourmand » sans gêner les autres utilisateurs du système, on peut utiliser la commande nice :
- $ nice -n priorité./groscalcul
où -20 ≤ priorité ≤ 19, 19 désignant la plus petite priorité (processus « laissant sa place » aux autres) et -20 la plus grande. Par défaut, les utilisateurs n'ont pas le droit d'utiliser une priorité négative, par conséquent tous les utilisateurs sont égaux face à l'utilisation des ressources de la machine.
Notons l'existence de la commande renice permettant de baisser la priorité d'un processus une fois qu'il est lancé. Par exemple, avec la commande :
$ renice -10 -p 4358
4358: old priority 0, new priority 10
$on change la priorité du processus de pid 4358 en lui affectant la valeur 10.
2-4-2-b. La notion de signal▲
Lorsqu'on veut interrompre ou suspendre un processus, l'intervention revient toujours à envoyer ce qu'on appelle un signal au processus en question. Lorsqu'un processus reçoit un signal il interrompt le cours normal de son exécution et peut :
- soit s'arrêter, c'est le comportement par défaut ;
- soit exécuter une routine particulière que le concepteur de la commande aura eu soin de définir et reprendre son cours normal.
Selon la mouture de l'unix et de la plate-forme sous-jacente, on dispose d'une trentaine de signaux dont on peut avoir la liste avec la commande kill et l'option -l.
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SIGPWR
$Tous ces signaux peuvent être détournés de manière à installer une routine à exécuter à la réception de ce signal ; ceci à l'exception du signal KILL (n°9) et du signal STOP (n°19) qui ne peuvent être détournés et donc ont toujours pour effet d'arrêter (respectivement d'interrompre) le processus.
2-4-2-c. La commande kill▲
Nous passerons ici en revue quelques utilisations de la commande kill. Dans un cadre très pratique, il y a trois situations vitales où il est nécessaire de connaître cette commande :
- un programme « s'emballe », c'est-à-dire accapare les ressources mémoire ou cpu du système, il est alors nécessaire d'en stopper l'exécution ;
- un programme utilise trop de ressources pour le confort des autres utilisateurs, il est nécessaire de l'interrompre momentanément ;
- un programme ne répond plus aux sollicitations de l'utilisateur, il n'y a pas d'autres moyens que de l'interrompre en lui envoyant un signal de fin d'exécution.
Passons en revue ces trois situations en supposant que sur notre terminal la commande ps nous renvoie :
$ ps -o pid,pcpu,pmem,state,cmd
PID %CPU %MEM S CMD
2177 0.0 2.1 S -bash
2243 99.9 99.9 R winword-2005
2244 0.0 1.7 R ps -o pid,pcpu,pmem,state,cmd
$Anti-emballement - On décide que le programme winword-2005 prend beaucoup trop de ressources - probablement à cause d'un bug - on intervient en décidant d'éliminer purement et simplement ce processus du système :
$ kill 2243
$ce qui a pour effet d'envoyer le signal TERM au processus de pid 2243. Il se peut que l'envoi de ce signal soit sans effet si le programme en question a été conçu pour détourner ce signal. Le processus de pid 2243 apparaîtra toujours dans la liste des processus et il faudra lui envoyer un signal KILL :
$ kill -KILL 2243
$qui comme on l'a vu précédemment ne peut être détourné ; le processus de pid 2243 est donc irrémédiablement arrêté.
Assurer le confort des autres - On considère ici que le fameux programme winword-2005 que tout le monde utilise sans vraiment savoir pourquoi, n'est pas en train de s'emballer, mais simplement prend un peu trop de ressources. La tâche effectuée est lourde, mais importante pour l'utilisateur qui décide donc d'interrompre le programme pour le reprendre plus tard :
$ kill -STOP 2243
$On peut constater que le programme interrompu est effectivement dans cet état en examinant le champ STATE :
$ ps -o pid,pcpu,pmem,state,cmd
PID %CPU %MEM S CMD
2177 0.0 2.1 S -bash
2243 0.0 25.3 T winword-2005
2244 0.0 1.7 R ps -o pid,pcpu,pmem,state,cmd
$Ce champ est positionné à T qui indique que le processus de pid 2243 est interrompu.
L'utilisateur, soucieux d'achever son travail, pourra alors lancer la commande en fin de journée pour ne pas gêner ses collègues :
$ kill -CONT 2243
$qui indique au processus de pid 2243 de reprendre son exécution.
2-4-2-d. Contrôle de tâches▲
Le contrôle de tâches ou job control permet de manipuler les processus tournant sur un terminal donné. Sur chaque terminal, on distingue deux types de processus :
- le processus en avant-plan, c'est celui qui peut utiliser le terminal comme canal de communication avec l'utilisateur par le biais du clavier ; on dit également qu'on « à la main » sur ce type de processus ;
- les processus en arrière plan (ou tâche de fond) ; ceux-là peuvent utiliser le terminal comme canal de sortie (pour afficher des informations par exemple) mais ne peuvent lire les données que leur fournirait l'utilisateur.
Ce qui est écrit ci-dessus est le comportement qu'on rencontre généralement sur un terminal avec la plupart des applications. Il n'est par contre pas inutile de noter que selon qu'une application intercepte ou ignore les deux signaux particuliers TTOU et TTIN (respectivement écriture ou lecture d'un processus en arrière-plan), le comportement pourra être différent.
Les shells supportant le contrôle de tâches(41) offrent un certain nombre de commandes et de combinaisons de touches qui permettent entre autres :
- d'interrompre ou d'arrêter un programme ;
- de passer un programme en arrière ou en avant-plan ;
- de lister les processus en arrière-plan.
Nous vous proposons de passer en revue ces fonctionnalités en se plaçant dans le cadre d'un exemple simple : supposons que dans un terminal donné, un utilisateur lance l'éditeur Emacs :
$ emacsUne fois Emacs lancé, l'utilisateur n'a plus la main sur le terminal(42), et tout caractère saisi reste en attente, jusqu'à la fin de l'exécution d'Emacs :
$ emacs
qdqsqmlskdjf
<------------------------------------------- fin du progamme emacs
$ qdqsqmlskdjf
bash: qdqsqmlskdjf: command not found
$2-4-2-e. Arrêter le programme▲
Pour arrêter un programme en avant-plan, on peut utiliser la célèbre combinaison de touche ![]()
![]() (Ctrl-c) :
(Ctrl-c) :
$ emacs
<----------------------------------------------- Control + c
$Ctrl-C envoie le signal INT au processus en avant-plan dans le terminal.
2-4-2-f. Passage en arrière-plan▲
Pour passer Emacs (le programme de notre exemple) en arrière-plan, il faut procéder en deux temps : appuyer sur la touche ![]() puis la touche
puis la touche ![]() en même temps (on note souvent Ctrl-z)(43), ce qui a pour effet d'envoyer le signal STOP au programme s'exécutant en avant-plan sur le terminal.
en même temps (on note souvent Ctrl-z)(43), ce qui a pour effet d'envoyer le signal STOP au programme s'exécutant en avant-plan sur le terminal.
$ emacs
<---------------------------------------------------- Control + z
[1]+ Stopped emacs
$Il faut ensuite passer le programme en tâche de fond grâce à la commande interne bg (background) :
$ bg
[1]+ emacs &
$Le numéro entre crochet ([1]) est le numéro de la tâche dans le terminal courant.
On parle aussi de job. On peut également lancer directement une commande ou programme en tâche de fond, en postfixant la commande par le caractère & :
$ emacs&
[1] 1332
$Ici le système attribue à Emacs le job [1], et le shell affiche sur le terminal le pid correspondant (1332).
2-4-2-g. Lister les tâches▲
La commande jobs permet d'obtenir une liste des tâches en arrière-plan, ou interrompues, sur le terminal. Par exemple :
$ xclock & xlogo & xbiff &
[1] 1346
[2] 1347
[3] 1348
$lance trois programmes donnant lieu à la création d'une fenêtre graphique. On peut lister ces tâches :
$ jobs
[1] Running xclock &
[2]- Running xlogo &
[3]+ Running xbiff &
$2-4-2-h. Passage en avant-plan▲
Il est possible de faire référence à une tâche par son numéro grâce à la notation %numéro_de_tâche. Ceci est valable pour les commandes bg et kill vues précédemment, mais aussi pour la commande permettant de passer une tâche en avant-plan : la commande fg (foreground). Ainsi par exemple pour passer xlogo en avant-plan :
$ fg %2
xlogo
<----------------------- maintenant on n'a plus la main.2-5. Quelques services▲
Un système d'exploitation peut être vu comme une couche logicielle faisant l'interface entre la machine et l'utilisateur. Cette interface peut elle-même être appréhendée comme un ensemble de services fournis à l'utilisateur. Outre les services vus jusqu'ici permettant de lancer des programmes et de stocker des données(44), il existe - entre autres - des services liés à l'impression et la planification.
Les services d'unix répondent généralement au principe client/serveur, dans lequel le client est l'application vue par l'utilisateur, et le serveur un daemon (disk and execution monitor), c'est-à-dire un programme attendant en tâche de fond, pour répondre aux éventuelles requêtes.
2-5-1. Impression▲
Sur les réseaux locaux, l'impression sous unix se fait généralement sur des imprimantes PostScript connectées à un réseau. Le PostScript est un langage d'impression conçu par la société Adobe, c'est un langage de description de page. Ce langage est interprété, et les imprimantes dites PostScript disposent d'un interpréteur implanté sur une carte électronique. Le principe pour imprimer est donc d'envoyer un fichier au format PostScript sur une imprimante. En fonction du format du fichier initial, il faudra procéder à une conversion avec les logiciels suivants :
- a2ps convertit un fichier texte en fichier PostScript ;
- convert permet de convertir à peu près n'importe quel type d'image en PostScript ;
- dvips permet de convertir la sortie de TEX (format dvi) en PostScript.
Si l'on ne dispose pas d'imprimante PostScript, il faut générer le PostScript comme indiqué précédemment et utiliser un interpréteur logiciel pour transformer ce PostScript en fichier compatible avec l'imprimante en question (voir figure 2.6). L'interpréteur PostScript couramment utilisé sous unix est Ghostscript (http://www.cs.wisc.edu/~ghost). Les commandes de base disponibles pour l'utilisateur sont :
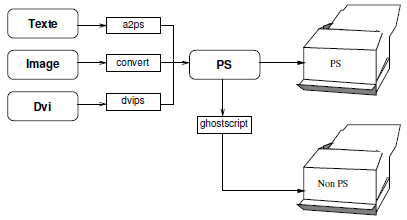
- lpr : pour soumettre un fichier à imprimer ;
- lpq : pour lister la liste des « jobs » d'impression en attente ;
- lprm : pour enlever un job de la liste en attente.
Selon le système que vous utiliserez seront accessibles plusieurs files d'impression en fonction des imprimantes disponibles. Seront également accessibles des options dépendantes des caractéristiques de l'imprimante (alimentation manuelle, bac A3, recto/verso, etc.). Renseignez-vous auprès du môssieur qui vous sert d'administrateur système.
Il existe deux familles de commandes héritées de deux versions d'unix. Historiquement, la branche BSD proposait les commandes lp, lpq et lprm, et les commandes correspondantes de la branche SysV étaient lp, lpstat et cancel. Aujourd'hui les programmes gérant l'impression sur un système unix peuvent utiliser l'une ou l'autre de ces familles, voire les deux.
2-5-2. Le service at▲
La commande at permet de lancer une commande à (at) une heure particulière. Sa syntaxe est la suivante :
- at date
On pourra par exemple lancer :
$ at 23:00
at> groscalculdelamort
at> <---------------------------------------------------- Ctrl-D
$pour lancer à 23 heures le programme groscalculdelamort qui utilise beaucoup de ressources. La sortie du programme sera envoyée par mail à l'utilisateur après son exécution. D'autres syntaxes existent pour spécifier la date de lancement :
$ at now + 2hours
$pour lancer un programme dans deux heures. Et :
$ at 16:20 tomorrow
$pour demain à 16:20,
$ at 13:14 10/23/02
$pour lancer un programme le 23 octobre 2002 à 13 heures 14. On peut également
lister les « jobs » prévus par la commande at grâce à la commande atq :
$ atq
1 2001-03-14 18:27 a
2 2001-03-15 16:20 a
3 2002-10-23 13:14 a
$La commande atrm quant à elle, permet de supprimer une tâche prévue, en donnant son identificateur (le numéro indiqué dans la première colonne des informations renvoyées par atq) :
$ atrm 1
$On peut également préparer les commandes dans un fichier texte et utiliser ce fichier - notons-le commandes.at - comme argument de la commande at :
$ at -f commandes.at 15:00 tomorrow
$2-5-3. Le service cron▲
cron est un service équivalent à ce que le système d'exploitation édité par la société Microsoft appelle les « tâches planifiées ». L'interface utilisateur est la commande crontab. Pour savoir quelles sont vos tâches planifiées (dans le jargon unix, on dit inspecter « sa crontab »), on lancera la commande :
$ crontab -l
no crontab for djobi
$Pour effacer toutes vos tâches planifiées, la commande suivante suffira :
$ crontab -r
$Pour définir une ou plusieurs tâches planifiées, la commande :
$ crontab -elance un éditeur (qui peut être par défaut viAvec vi) qui vous demande de saisir des informations dans un format particulier. Chaque ligne ce celui-ci devra contenir les informations suivantes :
- minutes heures jour du mois mois jour de la semaine commande
où :
- minutes : prend des valeurs de 0 à 59 ;
- heures : de 0 à 23 ;
- jour du mois : de 1 à 31 ;
- mois : de 1 à 12 ;
- jour de la semaine : de 0 à 7 où 0 et 7 représentent le dimanche.
Par exemple la ligne :
10 0 * * 0 rm -rf ~/.wastebasket/*efface tous les dimanches à minuit passé de dix minutes, le contenu du répertoire « poubelle » ˜/.wastebasket. La ligne :
0 12 30 12 * echo "bon anniversaire" | mail pote@truc.netenvoie un mailLe courrier électronique à votre pote tous les 30 décembre à midi.
La ligne :
0 8-18 * * * echo "ça gaze ?" | mail pote@truc.netenvoie un mail toutes les heures pile de (8 heures à 18 heures) pour vous rappeler à son bon souvenir. La ligne :
0 8-18/4 * * 1,3,5 rm -f ~/tmp/*vidange le répertoire tmp de l'utilisateur le lundi, mercredi et le jeudi, et ceci de 8 heures à 18 heures, toutes les 4 heures. Notez enfin que le service cron vous informe par mail du résultat de l'exécution de votre tâche. Voir la page de manuel de crontab pour de plus amples informations, ainsi que l'exemple du chapitre 6Chapitre 6 - Se mettre à l'aise ! paragraphe 6.4.5Étude de cas : fond d'écran illustrant une utilisation du service cron pour mettre des images tirées au hasard en fond d'écran.
2-5-4. L'utilitaire nohup▲
nohup permet de lancer une commande qui ne sera pas arrêtée lorsque l'utilisateur se déconnectera du système(45). Lors de la déconnexion, tous les programmes reçoivent en effet le signal HUP, qui a par défaut l'effet de les arrêter(46). Pour lancer la commande cmd « en nohup », on tapera :
- nohup cmd
Par exemple pour lancer un téléchargement qui va durer plusieurs heures, on peut utiliser wgetwget l'aspirateur avec nohup :
$ nohup wget ftp://bidule.chouette.org/pub/truc-1.2.tar.gz
nohup: appending output to `nohup.out'
<-------------------------------------------------------- Ctrl-z
[1]+ Stopped wget
$ bg
[1]+ wget &
$Le système vous informe alors que la sortie du programme - en l'occurrence wget - est redirigéeRedirections dans le fichier nohup.out. Fichier qu'on pourra consulter lors de la prochaine connexion au système.
Que faire alors si le programme lancé avec nohup est un programme interactif qui attend des données au clavier ? Une solution simple est de visualiser le contenu du fichier nohup.out dans un autre terminal avec la commande tail -f nohup.outTête-à-queue et répondre aux questions dans le terminal où est lancé la commande en nohup. Par exemple si on ne dispose pas de wget, mais uniquement de l'utilitaire ftp, il faudra procéder, avant de lancer le transfert proprement dit, à une série d'interactions avec le programme.
2-6. Conclusion▲
Vous êtes maintenant armés pour découvrir le chapitre suivant. Celui-ci va vous présenter les utilitaires composant la « boîte à outils » d'un système unix. Le bon maniement de ces outils présuppose que vous avez correctement digéré le présent chapitre. C'est par contre celui qui vous fera prendre conscience de toute la puissance de la ligne de commande(47).